1、python语言
from scipy.cluster import hierarchy # 导入层次聚类算法
import matplotlib.pylab as plt
import numpy as np
# 生成示例数据
np.random.seed(0)
data = np.random.random((20,1))
# 使用树状图找到最佳聚类数
Z = hierarchy.linkage(data,method='weighted',metric='euclidean')
re = hierarchy.dendrogram(Z,color_threshold=0.2,above_threshold_color='#bcbddc')
# 输出节点标签
print(re["ivl"])
# 画图
plt.title('Dendrogram') # 标题
plt.xlabel('Customers') # 横标签
plt.ylabel('Euclidean distances') # 纵标签
plt.show()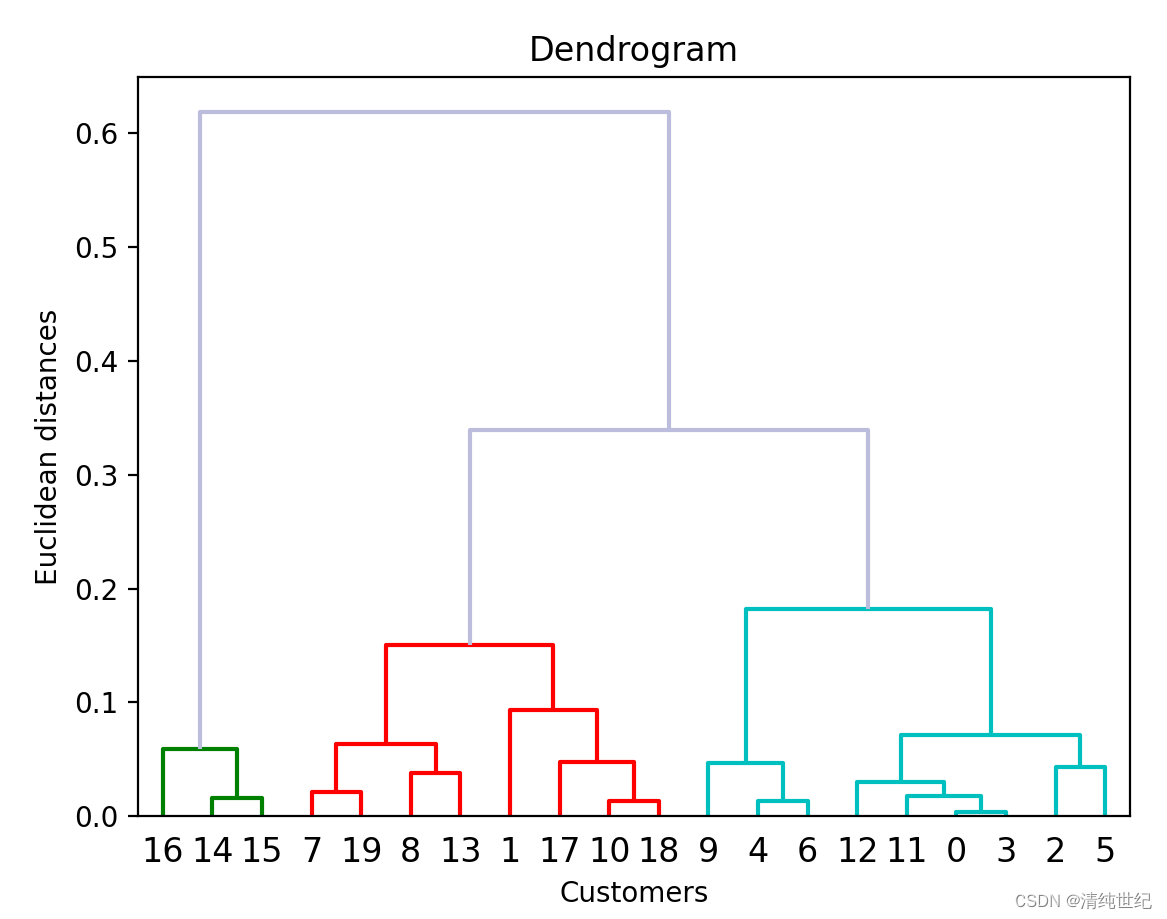
dendrogram函数参数:
Z:层次聚类的结果,即通过scipy.cluster.hierarchy.linkage()函数计算得到的链接矩阵。
p:要显示的截取高度(y轴的阈值),可以用于确定划分群集的横线位置。
truncate_mode:指定截取模式。默认为None,表示不截取,可以选择 'lastp' 或 'mlab' 来截取显示。
labels:数据点的标签,以列表形式提供。
leaf_font_size:叶节点的字体大小。
leaf_rotation:叶节点的旋转角度。
show_leaf_counts:是否显示叶节点的数量。
show_contracted:是否显示合并的群集。
color_threshold:显示不同颜色的阈值,用于将不同群集算法聚类为不同颜色。
above_threshold_color:超过阈值的线段颜色。
orientation:图形的方向,可以选择 'top'、'bottom'、'left' 或 'right'。假设我们输出Z值,获得以下结果:
from scipy.cluster import hierarchy # 导入层次聚类算法
import numpy as np
import pandas as pd
# 生成示例数据
np.random.seed(0)
data = np.random.random((8,1))
# 使用树状图找到最佳聚类数
Z = hierarchy.linkage(data,method='weighted',metric='euclidean')
row_dist_linkage = pd.DataFrame(Z,
columns=['Row Label 1','Row Label 2','Distance','Item Number in Cluster'],
index=['Cluster %d' % (i+1) for i in range(Z.shape[0])])
print("\nData Distance via Linkage: \n",row_dist_linkage)
其中,第一列和第二列代表节点标签,包含叶子和枝子;第三列代表叶叶(或叶枝,枝枝)之间的距离;第四列代表该层次类中含有的样本数(记录数)。注:因此,我们可以第三列距离结合图来确定不同簇的样本数量。这里的数量为(n-1),即样本总数减1。
2、R语言
setwd("D:/Desktop/0000/R") #更改路径
df <- read.csv("iris.csv",header = T, row.names = 1) #读取工作路径文件
head(df) #查看前6行
hc <- hclust(dist(df))
library(ggtree)
ggtree(hc,layout="circular",branch.length = "daylight")+
xlim(NA,3)+
geom_tiplab2(offset=0.1,
size=2)+
#geom_text(aes(label=node))+
geom_highlight(node = 152,fill="red")+
geom_highlight(node=154,fill="steelblue")+
geom_highlight(node=155,fill="green")+
geom_cladelabel(node=152,label="virginica",
offset=1.2,barsize = 2,
vjust=-0.5,color="red")+
geom_cladelabel(node=154,label="versicolor",
offset=1.2,barsize = 2,
hjust=1.2,color="steelblue")+
geom_cladelabel(node=155,label="setosa",
offset=1.2,barsize = 2,
hjust=-1,color="green")如果没有安装ggtree则先安装
install.packages("BiocManager")
BiocManager::install('ggtree')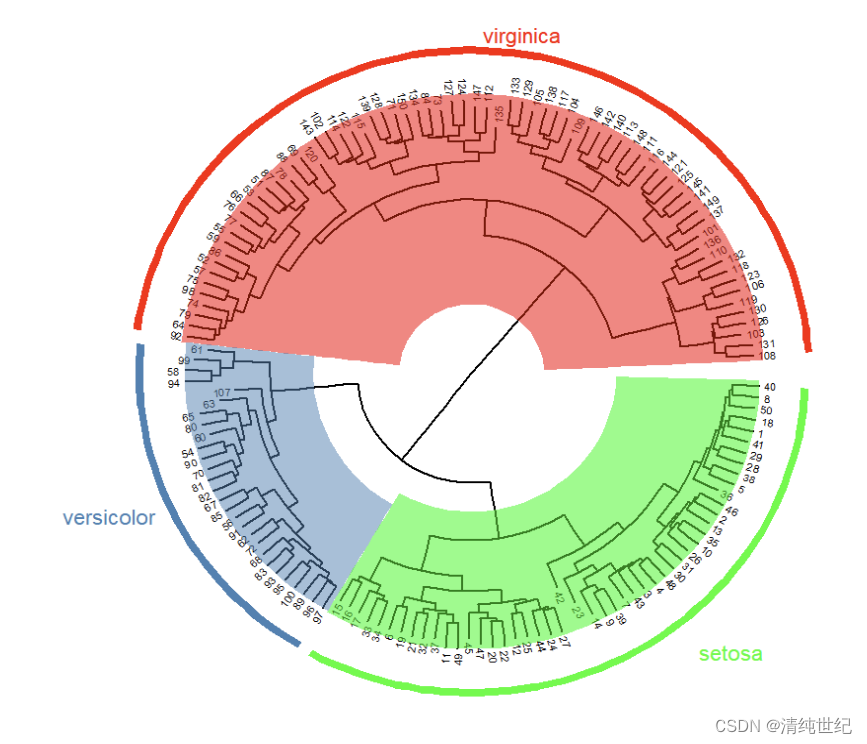
除了上面这种方式外,我们还可以使用下面的方式获取(节点对齐):
setwd("D:/Desktop/0000/R") #更改路径
library(dendextend) #install.packages("dendextend")
library(circlize) #install.packages("circlize")
df <- read.csv("iris.csv",header = T, row.names = 1) #读取工作路径文件
head(df) #查看前6行
aa <- hclust(dist(df))
# 设置画布大小为4英寸宽,4英寸高
par(mar = c(4, 4, 2, 2) + 0.1)
png("output.png", width = 4, height = 4, units = "in", res = 600)
hc <- as.dendrogram(aa) %>%
set("branches_lwd", c(1.5)) %>% # 线条粗细
set("labels_cex", c(.9)) # 字体大小
# 颜色
hc <- hc %>%
color_branches(k = 10) %>% #树状分支线条颜色
color_labels(k = 10) #文字标签颜色
# Fan tree plot with colored labels
circlize_dendrogram(hc,
labels_track_height = NA,
dend_track_height = 0.7)
# 结束绘图并关闭设备
dev.off()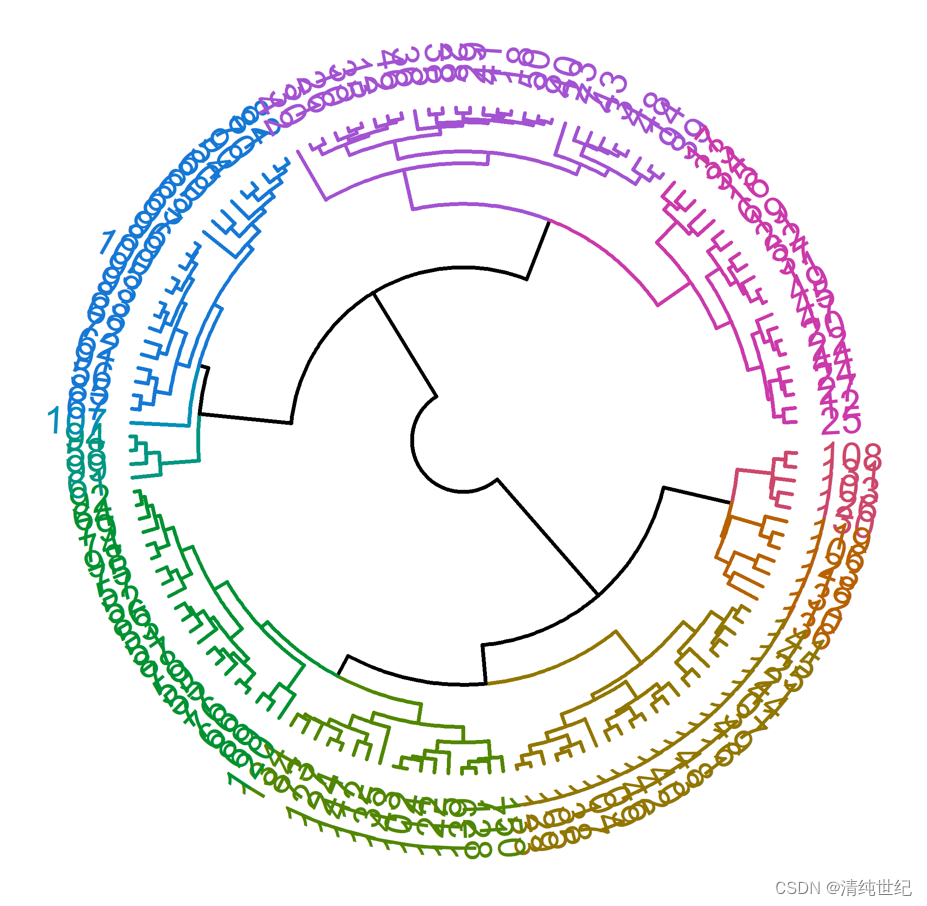
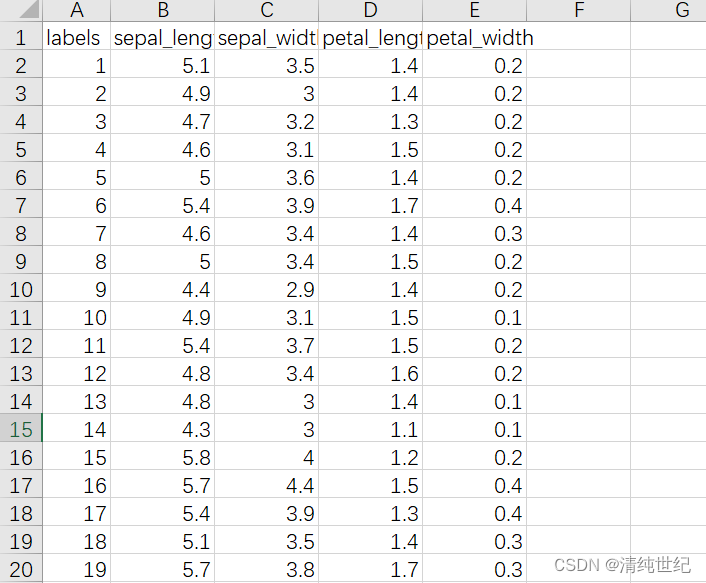
文件数据样式:
更多学习视频:【R包使用】ggtree美化树状图_哔哩哔哩_bilibili、树状图展示聚类分析的结果_哔哩哔哩_bilibili