这篇文章主要介绍了在科学问题中如何实现不变性或等变性,其中介绍了实现等变性的数学和物理基础,包括离散和连续对称变换的示例,并描述了在实践中如何使用张量积。文章还讨论了如何处理数据中的对称性,以及如何开发适应对称性约束的机器学习模型。最后,文章指出了几个值得在该领域探索的开放研究方向。
2 对称性、等变性和理论
在许多科学问题中,感兴趣的对象通常存在于三维物理空间中。对这些对象的任何数学表示都不可避免地依赖于参考坐标系,使表示具有坐标依赖性。然而,自然界没有坐标系统,因此需要坐标无关的表示。因此,科学中人工智能的关键挑战之一是如何实现不变性或等变性。在本节中,我们详细介绍了实现等变性的数学和物理基础。为了使内容对读者友好,我们按照复杂性逐步增加的方式组织本节内容,其逻辑流程在第2.1节中显示。首先,在第2.2节、第2.3节和第2.4节中,我们提供了等变性对离散和连续对称变换的示例,并描述了在实践中如何使用张量积。之后,在第2.5节中,通过具体而直观的例子,我们试图阐明潜在理论的物理和数学基础,例如对称群、不可约表示、张量积、球面谐波等。然后,在第2.6节和第2.7节中,我们进一步阐述了详细而正式的理论,某些读者可以跳过这部分。我们在第2.8节中提供了更一般形式的等变网络。最后,在第2.9节中,我们指出了几个值得在该领域探索的开放研究方向。
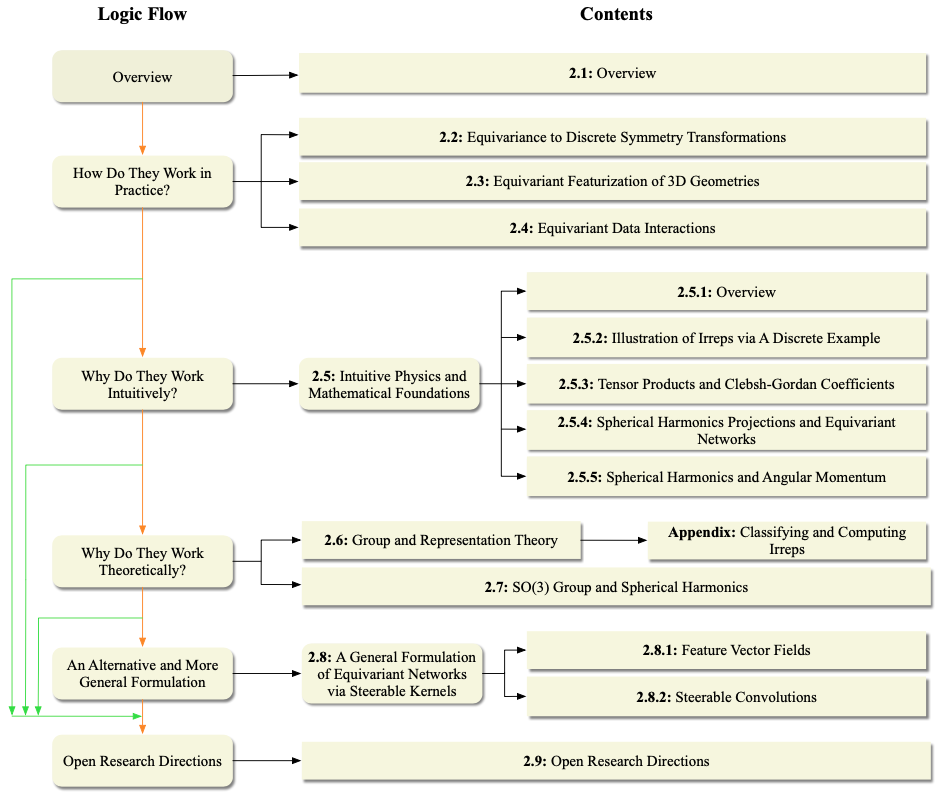
图4:第2节的总体逻辑流程和相关子节。注意逻辑流程中的箭头显示了不同子节之间的依赖关系,特别是绿色的跳转连接表示可以跳过某些子节。黑色箭头显示了逻辑流程与子节之间的关联,以及每个子节与子节的子节之间的关系。请注意,该图的目的是为了读者能够根据背景和兴趣快速导航到特定内容,例如,某些读者可能会跳过与“为什么理论上有效?”相关的子节。
2.1回顾
对物理数据进行描述需要进行一些选择,比如建立一个参考框架。虽然这些选择有助于对数据中的物理现象进行数值表示,但结果数据同时反映了研究对象以及这些选择。由于描述选择(如参考框架)本质上是任意的,所以所表示的现象不应受到这些选择的影响。这个概念被称为对称性。对称性指的是在诸如参考框架变换之类的变换下保持不变或不变的物理现象的特征。因此,如果我们希望获得对物理世界内在客观属性的洞察,独立于我们的观察或表示偏见,就必须了解如何处理数据中的对称性。如果系统中存在某些对称性,预测的目标自然上是对应对称变换不变或等变的。例如,在预测三维分子结构的能量时,即使在输入的三维分子被平移或旋转时,预测的目标仍然保持不变。实现对称感知学习的一种可能策略是在训练监督学习模型时采用数据增强。具体而言,对输入数据样本和标签应用随机的对称性变换,以迫使模型生成近似等变的预测。然而,数据增强存在几个缺点。首先,为了考虑到选择参考框架带来的额外自由度,需要更多的模型容量来表示在固定参考框架下相对简单的模式。其次,许多对称性变换(如平移)可产生无限数量的等价数据样本,使有限的数据增强操作难以完全反映数据中的对称性。第三,在某些情况下,我们需要通过叠加多个层来构建非常深的模型以实现良好的预测性能。然而,如果模型在每一层都不保持等变性,通过数据增强来迫使深层模型生成近似等变的预测将面临更大的挑战。最后但并非最不重要的是,在某些科学问题(如分子建模)中,提供关于对称性和等变性自然信息的解释是重要的。
为了使用户能够在可靠的方式下使用机器学习模型,需要在这些变换下提供可证明鲁棒的预测。鉴于使用数据增强的缺点,越来越多的研究着眼于开发适应对称性约束的机器学习模型。通过对称性适应架构,无需进行对称感知学习的数据增强,模型可以专注于学习目标预测任务。最近,这种适应于对称性的模型在各种不同系统的科学问题中取得了显著的成功,包括分子(见第5节)、蛋白质(见第6节)和晶体材料(见第7节)。在接下来的章节中,我们将详细介绍本文讨论的科学问题中考虑到的对称变换以及为这些对称变换设计对称性适应模型时的等变操作。
2.2 对离散对称变换的等变性
作者:Youzhi Luo,Xuan Zhang,Jerry Kurtin,Erik Bekkers,Shuiwang Ji 在某些科学问题中,预测目标在内部对有限集合的离散对称变换是等变的。为了明确和简单起见,我们考虑输入为2D标量场的情况,对称变换包括90度、180度和270度的旋转[Cohen and Welling 2016]。一个例子是在2D平面上模拟流场(如标量涡度或密度)的动力学,我们学习一个将当前时间步的流场映射到下一个时间步的流场的映射。在某些情况下,如果输入的2D流场旋转了90度、180度或270度,则模拟的流场应该相应地旋转(详见第9节)。具体地,设𝑋 ∈ R𝑠 ×𝑠为定义在𝑠 × 𝑠网格上的输入信号,函数𝑓:R𝑠×𝑠 → R𝑠×𝑠将𝑋映射到预测场。我们将角度为𝛼的旋转定义为𝑅𝛼:R𝑠×𝑠 → R𝑠×𝑠。所有离散对称变换的集合为{𝑅𝛼}𝛼∈A,其中A={0度,90度,180度,270度}。具体而言,𝑅0度是恒等映射,𝑅90度将输入矩阵旋转90度,即𝐴′ =𝑅90度(𝐴)满足𝐴′ =𝐴𝑗,𝑛−𝑖,对于任何𝐴∈R𝑛×𝑛和0≤𝑖,𝑗 ≤𝑛−1 𝑖,𝑗(从0开始计数)。𝑅180度和𝑅270度分别由两个和三个90度旋转组成。换句话说,𝑅180度 = 𝑅90度 ◦ 𝑅90度,𝑅270度 = 𝑅90度 ◦ 𝑅90度 ◦ 𝑅90度。等变于离散对称变换要求𝑓满足
𝑓𝑅𝛽 (𝑋) = 𝑅𝛽 (𝑓 (𝑋)),对于所有𝛽 ∈ A。 (1)
为了激发在{𝑅𝛼}𝛼 ∈ A中实现等变于离散对称变换的想法,我们首先考虑一个等变群卷积神经网络(G- CNNs)的最简单例子[Cohen and Welling 2016]。我们的例子包括所谓的升降卷积[Bekkers et al. 2018],它对旋转了A中的每个角度的卷积核进行卷积,然后在新引入的旋转轴上应用池化操作。首先,让我们重新考虑标准卷积。给定输入特征图𝑋 ∈ R𝑠 ×𝑠和可学习的卷积核𝑊 ∈ R𝑘 ×𝑘,标准卷积𝑋 ∗ 𝑊计算出一个𝑠 × 𝑠的特征图,其中第𝑖行、第𝑗列的特征值计算如下:
(𝑋∗𝑊)𝑖𝑗 =∑︁∑︁𝑊𝑝𝑞𝑋𝑖+𝑝,𝑗+𝑞,0≤𝑖,𝑗≤𝑠−𝑘。 (𝑝=0,𝑞=0) (2)
为了简化起见,这里我们省略了填充(方程(2)中的实际输出大小为(𝑠 − 𝑘 + 1) × (𝑠 − 𝑘 + 1))。现在考虑等变群的升降卷积,它由四个带有旋转角度𝛼的标准卷积组成。这样创建了特征图集合{𝐹𝛼 }𝛼 ∈ A,其中𝐹𝛼 = 𝑋 ∗ 𝑅𝛼 (𝑊 ),新的𝛼轴用于索引每个旋转𝛼的滤波器响应。因此,输出可以被认为是一个“旋转响应向量”的场,它是旋转群的正则表示的一个特例。关于特征场的讨论超出了本节的范围,但将在第2.8节中继续。这里的主要观点是输出不是我们在建模标量涡度或密度时希望的标准标量场。因此,我们的简单网络在升降卷积之后添加了沿𝛼轴的最大池化,即我们在旋转响应上进行池化。简单的架构可以描述为 GCNN(𝑋;𝑊)=Pool({𝐹𝛼}𝛼∈A)=Pool({𝑋∗𝑅𝛼 (𝑊)}𝛼∈A), (3)
注意Pool(·)在旋转轴上进行池化。
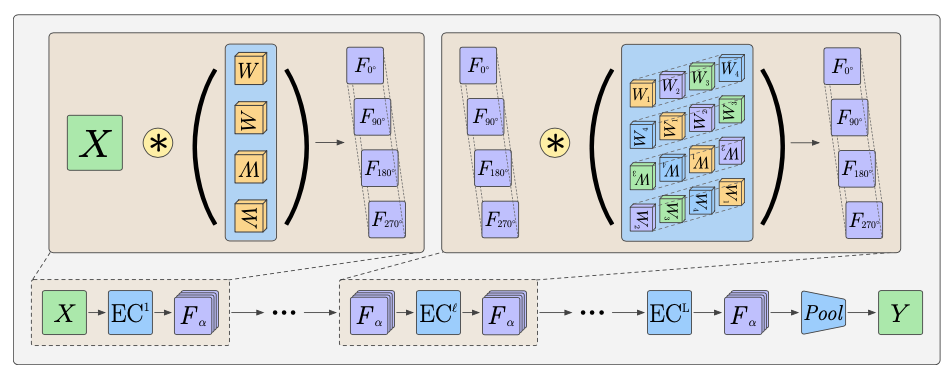
图5. 对G-CNNs(Cohen and Welling 2016)中等变卷积神经网络进行了说明。网络通过等变卷积层(EC)传递输入,得到四个输出特征图。如果输入𝑋旋转了90°、180°或270°,这些特征图将旋转𝛽,并且它们的顺序会改变。在此之后,应用了𝐿组卷积层,并添加一个最终的池化层以考虑特征图的排列组合。该网络对于90°、180°或270°的旋转是等变的。
通过同时使用旋转核的四个卷积操作以及池化操作,确保整个G-CNN具有等变性,即
GCNN𝑅𝛽(𝑋);𝑊=𝑅𝛽(GCNN(𝑋;𝑊)), ∀𝛽∈A。 (4)
首先,如方程(3)所示,四个卷积操作分别将核𝑊旋转0°、90°、180°和270°,并用这四个核对𝑋进行卷积操作,生成四个特征图𝐹0°,𝐹90°,𝐹180°,𝐹270°。从方程(2)中的卷积计算过程,我们可以证明如果输入𝑋按任意𝛽 ∈ A进行旋转,四个输出特征图𝐹0°,𝐹90°,𝐹180°,𝐹270°将会旋转相同的角度𝛽并对其排列顺序进行改变,即
{𝑅𝛽 (𝑋)∗𝑅𝛼(𝑊)}𝛼∈A ={𝑅𝛽(𝑋∗𝑅−1(𝑅𝛼(𝑊)))}𝛼∈A (5)
= {𝑅𝛽(𝑋 ∗ 𝑅𝛼−𝛽(𝑊))}𝛼∈A (6)
={𝑅𝛽 𝐹(𝛼−𝛽)mod360◦}𝛼∈A。 (7)
其次,沿旋转轴的池化操作对于轴内的排列是不变的,且在空间轴上保持了旋转等变性,因此我们有
Pool𝑅𝛽(𝐹𝛼)𝛼∈A=𝑅𝛽(Pool({𝐹𝛼}𝛼∈A)), ∀𝛽∈A。 (8)
当方程(7)和(8)成立时,方程(4)中的等变性属性始终成立。上述简单的G-CNN创建了局部旋转不变的特征场,可以用于构建具有等变性的深度网络。然而,由于旋转轴的池化操作,其中间特征不携带任何方向信息。相反,全群等变卷积网络(G-CNNs)通常以抬升卷积开始,该卷积在上述已解释的基础上为特征图添加了额外的旋转轴(因此通常称为抬升卷积),然后是保持特征图中额外旋转轴的群卷积层,以便能够检测特征的相对位置和方向的复杂模式,由此核表示部分-整体层次结构。典型的架构以抬升卷积开始,然后是多个等变群卷积层,最后以𝛼轴上的池化层结束(请参见图5以获取模型说明)。在这些中间层中,使用四个卷积核𝑊1,𝑊2,𝑊3,𝑊4共同将四个输入特征图𝐹0°,𝐹90°,𝐹180°,𝐹270°映射到四个输出特征图𝐹0° out out out , 𝐹90°, 𝐹180°, 𝐹270°,如方程(9)所示:
𝐹out=∑︁𝐹in ◦ ◦∗𝑅 (𝑊), 𝛼∈A. 𝛼 𝑖=1 (9)
可以证明,如果模型在第一层使用抬升卷积,并在中间层使用方程(9)中的全群卷积,那么每层的输出特征图始终对旋转具有等变性。此外,由于在模型输出终端处使用了旋转轴上的池化,模型的预测输出保证具有方程(1)中的等变性。还可以证明,线性算子是等变的当且仅当它是一个群卷积。这说明了群卷积作为构建等变G-CNNs的基本建模块的重要性。因此,在[Cohen et al. 2019, Thm. 3.1]中,该定理被陈述为(群)卷积就是你所需的!
2.3 三维几何结构的等变特征化
作者:罗友智,纪水旺
在其他科学问题中,需要考虑的对称变换不是离散的,而是连续的。特别地,在本文中讨论的许多科学问题中,我们关注的是化合物的3D结构中连续的𝑆𝐸(3)变换,包括平移和三维旋转,其中𝑆𝐸(3)代表着三维空间中的特殊欧几里德群。在这些问题中,我们的目标是从化合物中预测出特定的属性。我们使用3D点云来表示化合物,其中化合物的每个基本单元(例如分子中的每个原子)对应于3D点云中的一个点,每个点对应一个三维笛卡尔坐标。目标属性通常需要满足𝑆𝐸(3)变换等变性,即旋转和平移的等变性。需要注意的是,与第2.2节讨论的离散旋转不同,𝑆𝐸(3)变换中的旋转是连续的,意味着3D点云可以在三维空间中旋转任意角度。形式上,设𝐶 = [𝒄1, ..., 𝒄𝑛 ] ∈ R3×𝑛为3D点云的坐标矩阵,其中𝑛表示节点数量,𝒄𝑖是第𝑖个点的坐标,𝒇:R3×𝑛 → R2l+1是一个将坐标矩阵映射为(2l + 1)-维属性向量的函数,该函数在𝑆𝐸(3)变换的作用下具有阶数为l的等变性。函数𝒇的奇数维度2l + 1与不可约表示有关,详细内容将在第2.5节中介绍。这里,阶数为l的等变性要求𝒇满足以下条件:
𝒇 𝑅𝐶+𝒕1𝑇 =𝐷l(𝑅)𝒇(𝐶), (10)
其中𝒕 ∈ R3是平移向量,1 ∈ R𝑛是一个元素都为1的向量,它将向量𝒕广播到所有的𝑛个输入坐标上,使得𝒕1𝑇 ∈R3×𝑛。𝑅∈R3×3是旋转矩阵,满足𝑅𝑇 𝑅 = 𝐼和|𝑅| = 1。𝐷l (𝑅) ∈ R(2l+1)×(2l+1)是𝑅的(实)Wigner-D矩阵。这里我们假设𝒇是平移不变的,因为一个系统的大多数物理属性只依赖于其组成部分的相对位置而不是绝对位置。例如,一个分子的能量可以完全由其原子间的距离确定。Wigner-D矩阵是物理中用于3D旋转变换的高阶旋转矩阵。当l = 0时,𝐷l (𝑅) = [1],𝒇对应于对𝑆𝐸(3)变换不变的属性,如总能量、哈密顿本征值、带隙等。当l = 1时,𝐷l (𝑅) = 𝑅,𝒇对应于如果𝐶被旋转,相应地在三维空间中旋转的属性,如力场。当l > 1,l ∈ N+,𝐷l(𝑅) ∈ R(2l+1)×(2l+1),𝒇对应于如果𝐶被旋转,将在高于三维空间的更高维度中旋转的属性,如度数大于1的球谐函数和哈密顿矩阵块。 为了开发用于预测此类𝑆𝐸(3)等变性属性的机器学习模型,我们需要先进的方法将几何信息从𝐶编码为𝑆𝐸(3)等变性特征。在物理学和许多现有的机器学习方法中,常用的𝑆𝐸(3)等变几何特征编码方法是球谐函数。一般来说,(实)球谐函数𝒀l (·) : R3 → R2l+1将输入的3D向量映射为一个(2l + 1)-维向量,表示阶数为l的球谐函数基函数的系数(关于球谐函数基函数的物理含义,请参见第2.5节)。球谐函数的一个很好的性质是它对阶数为l的旋转,即所谓的阶数为l的𝑆𝑂(3)变换具有等变性:
![]()
(11)
对于3D点云中的点𝑖,𝑗,可以使用球谐函数将它们的相对位置𝒄𝑖 − 𝒄𝑗编码为一个阶数为l的𝑆𝐸(3)等变特征向量。
2.4 等变数据交互
作者:Youzhi Luo,Haiyang Yu,Hongyi Ling,Zhao Xu,Shuiwang Ji 最近,基于球谐函数的很多 𝑆𝐸(3)-等变操作被提出并应用于机器学习模型,其中球谐函数被用来将3D几何形状特征化为更高的维度,以便能够直接与几何形状上的高维特征进行交互(例如,图中的节点特征)。在本节中,我们回顾保持等变性的数据交互和操作的方法。
2.4.1 通过张量积实现等变数据交互
通过球谐函数相关操作,有很多不同的方式将局部几何特征化为特征。一种广泛使用的操作是基于张量积(TP)操作的消息传递[Gilmer et al. 2017][Thomasetal.2018]。对于具有坐标𝐶 = [𝒄1,...,𝒄𝑛]的𝑛节点点云,假设每个节点𝑖具有阶为𝑙1的𝑆𝐸(3)-等变节点特征𝒉𝑙1 ∈ R2𝑙1+1. 𝑖。基于张量积的消息传递首先计算一个消息𝒎𝑙3 ∈ R2𝑙3+1,然后更新节点𝑖的特征𝒉𝑙1为新节点𝑖′的特征𝒉𝑙1。
𝒀𝑙 (𝑅𝒄) = 𝐷𝑙 (𝑅)𝒀𝑙 (𝒄),其中𝐷𝑙(𝑅)与方程式(10)中的Wigner-D矩阵相同。给定坐标𝒄,𝒄的两个节点特征𝒉′𝑙1,此过程可以形式化描述为
𝒎𝑖 = ∑︁ 𝒎𝑗→𝑖 = ∑︁ 𝑗∈N(𝑖) TPl1,l2(𝒄𝑖−𝒄𝑗,𝒉𝑗),(12)
𝒉′𝑙1 = 𝑼(𝒉𝑙1,𝒎𝑙3),
其中(·, ·)是张量积操作,N(𝑖)是节点𝑖的邻居节点集合,𝑼(·, ·)是节点特征更新函数。N(𝑖)通常被定义为与节点𝑖距离小于半径截断𝑟的节点集合,即N(𝑖)={𝑗:∥𝒄𝑖−𝒄𝑗∥2 ≤𝑟}。方程式(12)中的张量积操作使用阶为𝑙2的球谐函数作为核来计算从节点𝑗到节点𝑖的消息𝒎𝑗→𝑖的传播。详细的计算过程可以描述为
TP(𝒄−𝒄,𝒉) = 𝐶vec𝐹𝑑𝒀2𝑟 ⊗𝒉,(13)
这里,𝐹(𝑑𝑖𝑗)是一个多层感知机(MLP)模型,它将距离𝑑𝑖𝑗 =∥𝒄𝑖−𝒄𝑗∥2作为输入,𝒓= 𝒄𝑖−𝒄𝑗,⊗是矢量外积操作,即𝒂⊗𝒃 = 𝒂𝒃𝑇,vec(·)是将矩阵展平为向量的操作,𝐶𝑙1,l2是具有2𝑙3 + 1行和(2𝑙1 + 1)(2𝑙2 + 1)列的Clebsch-Gordan(CG)矩阵。特别地,CG矩阵在物理学中被广泛应用,以确保对于|𝑙1 − 𝑙2| ≤ 𝑙3 ≤ 𝑙1 + 𝑙2,TPl3(·, ·)操作始终是𝑆𝐸(3)-等变的,
TP ( 𝑅𝒄 −𝑅𝒄 ,𝑑1(𝑅)𝒉 =𝑑3(𝑅)TP 𝒄 −𝒄 ,𝒉 如方程式(14)所示。

图6. 张量积运算的示意图[Thomas等人,2018]。我们展示了如何计算从节点𝑗到节点𝑖的消息𝒎𝑗→𝑖,假设旋转顺序最多为2。给定三维点云中节点𝑖和节点𝑗的坐标𝒄𝑖和𝒄𝑗,首先使用球谐函数将它们的相对位置𝒄𝑖 - 𝒄𝑗 编码成一个𝑆𝐸(3)等变特征向量。然后在计算得到的特征向量和节点𝑗的𝑆𝐸(3)等变节点特征𝒉𝑗之间进行张量积运算,以计算出消息𝒎𝑗→𝑖。得到的消息𝒎𝑗→𝑖是𝑆𝐸(3)等变的,通过相应的Wigner-D矩阵与三维点云一起旋转。
因此,消息𝒎𝑙3自然地是𝑆𝐸(3)-等变的。我们将Brandstetter等人的附录A.5[2022a]和第2.5.3节作为示例进行归纳和直观说明。另外,对于方程式(12)中的节点特征更新函数𝑼(·, ·),可以使用线性操作或另一个张量积操作来保持新节点特征𝒉′𝑙1的𝑆𝐸(3)-等变性。由于基于张量积的消息传递的所有计算都是𝑆𝐸(3)-等变的,我们可以通过堆叠多个这样的消息传递层来开发一个强大的𝑆𝐸(3)-等变模型。请注意,在讨论的消息传递操作中,输入节点特征和输出消息都具有单个旋转阶数。实际上,完整的节点特征𝒉𝑖由具有多个旋转阶数的𝑆𝐸(3)-等变特征组成。通过张量积操作计算具有不同旋转阶数的多个消息,并将它们与来自节点𝑗到节点𝑖的消息𝒎𝑗→𝑖和聚合的消息𝒎𝑖合并。然后,𝒎𝑖用于更新节点𝑖的特征𝒉𝑖为新的节点特征𝒉𝑖′。我们在图6中说明了计算具有旋转阶数最高为2的𝒎𝑗→𝑖的张量积操作。
2.4.2 通过球形信道网络实现近似等变数据交互
除了线性或TP运算,节点特征𝒉𝑖还可以通过球形信道网络(SCNs)[Zitnick等,2022;Passaro和Zitnick,2023]以非线性方式在球面上进行更新,以实现等变性。SCN将𝒉𝑖中的所有特征值视为球谐函数基函数的系数,𝒉𝑖表示将球面上的单位向量映射到实数值的球形函数。这个球形函数可以被描述为球谐函数基函数𝑓(𝜃, 𝜑) = Σ 𝑙 𝑌𝑙(𝜃, 𝜑)的线性组合,其中𝑙遍历𝒉𝑖中不同旋转阶次的𝑚, 𝑙𝑖,𝑚 𝑚特征向量,且−𝑙 ≤ 𝑚 ≤ 𝑙遍历𝒉𝑖中一个𝑙阶等变特征向量的元素。这里,𝑌𝑙是在第2.3节中定义的相同球谐函数,但其输入向量由球坐标系中的极角𝜃和方位角𝜑定义。通过𝑓(𝜃, 𝜑),操作𝑮(𝒉𝑖)在球面上采样多个(𝜃, 𝜑)对,并根据相应的函数值𝑓(𝜃, 𝜑)生成一个特征图。这个特征图可以被用作球形函数的表示。在SCNs中,通过𝑮从消息𝒎𝑖构建了一个类似的特征图,节点特征𝒉𝑖由点对点卷积𝑭𝑐作用于𝑮(𝒎𝑖) ,𝑮(𝒉𝑖)和𝑮的逆操作来更新为𝒉𝑖'。
𝒉𝑖' = 𝒉𝑖 + 𝑮^{-1}(𝑭𝑐(𝑮(𝒎𝑖), 𝑮(𝒉𝑖)))。(15)
这里,逆操作𝑮^{-1}通过特征图的值和球谐函数基函数进行点积来将特征图的值转化为球谐函数基函数的系数。 在eSCN中,根据旋转某个特定边𝒓的旋转矩阵𝑅来使主轴旋转,从而将𝑦轴与边的方向对齐,即𝑅 · 𝒓 = (0, 1, 0)。因此,球谐函数基函数𝑌𝑚𝑙(𝑅 · 𝒓)在𝑚 = 0时等于1,否则等于0。因此,在张量积中可以忽略𝑚 ≠ 0的计算,从而实现了显著的计算复杂性降低。随后,对消息应用Wigner-D矩阵的逆操作,将其转换回原始的坐标系统,保持了等变性。为了进一步提高张量积的效率,eSCN只考虑大而稀疏的Clebsch-Gordan矩阵中的非零条目,实施由两个线性层组成的𝑆𝑂(2)卷积。然后,在球面上进行逐点非线性操作,得到每个边的消息。最后,eSCN采用与SCN相同的消息聚合方式来更新节点特征𝒉𝑖。 需要注意的是,在SCN和eSCN中,聚合操作并不严格等变。只有在输入节点特征被精确采样以构建球形网格时,等变性才能保持。但是,由于旋转的连续性,实现这种理想条件并不总是可行的。
2.5 直观物理学和数学基础
作者:张璇,林宇超,徐胜龙,Tess Smidt,刘怡,钱晓峰,纪水旺
在上述第2.2节、第2.3节和第2.4节中,我们提供了在最近的研究中将等变性应用于离散和连续对称性变换的应用,并描述了在实践中如何使用张量积。在本节中,我们希望通过一些简单而直观的示例,使读者在相对较短的时间内理解潜在的理论。具体而言,在第2.5.1节中,我们提供了群和表示论的概要,即介绍了不可约表示(irreps)以及等变神经网络如何通过张量积产生不可约表示;我们试图通过第2.5.2节中的一个简单而离散的案例,即一个具有四个节点的正方形,解释对称群和不可约表示的直观性;在第2.5.3节中,我们提供了一个轻松的例子,让读者理解张量积和Clebsh-Gordan系数;在第2.5.4节中,我们介绍了球谐投影,这是球谐的一个具体应用;在第2.5.5节中,我们从角动量的角度进一步阐明了球谐函数的思想。
2.5.1 概述
在本节中,我们给出具体的示例来阐明群表示论的基础。考虑由(𝑥2,𝑥𝑦,𝑥𝑧,𝑦2,𝑦𝑧,𝑧2)所张成的多项式向量空间𝑍,该向量空间是由直积(𝑥,𝑦,𝑧)×(𝑥,𝑦,𝑧)得到的。当原始空间(𝑥,𝑦,𝑧)通过一个3×3旋转矩阵进行变换时,向量空间𝑍将通过一个6×6矩阵进行变换。如果我们随机看𝑆𝑂(3)在此向量空间上的旋转,6×6旋转矩阵是密集的;它们看起来不像是独立的向量空间。然而,如果我们进行一个基底变换到(𝑥2+𝑦2+𝑧2,𝑥𝑦,𝑦𝑧,2𝑧2−𝑥2−𝑦2,𝑥𝑧,𝑥2−𝑦2),则旋转矩阵呈现出一个引人注目的模式。事实上,原始空间可以分解为两个独立的子空间𝐿0 = (𝑥2 + 𝑦2 + 𝑧2),该子空间是不变的(所有元素的群表示形式为𝐼 = [1]),和𝐿2 = (𝑥𝑦,𝑦𝑧,2𝑧2−𝑥2−𝑦2,𝑥𝑧,𝑥2−𝑦2)。这实际上描述了如何将一个可约表示分解为不可约表示(irreps)。为了进一步阐明这一点,我们在第2.5.2节中给出了一个离散案例的例子,对于初学者来说可能更容易理解。
这种变换是重要的,因为它意味着任何向量空间都可以描述为这些基本向量空间的串联。在原则上,当使用机器学习进行“表示”学习时,如果我们所学习的向量空间在群作用下发生可预测的变化,例如旋转,那么我们所“学到”的向量空间必须由不可约表示组成,无论它有多么复杂。在等变神经网络的文献中,张量积一词用于定义张量积加分解运算,即将两个表示(可约或不可约)直接叠加以产生(一般)可约表示,然后将可约表示分解为不可约表示。在第2.5.3节中提供了对张量积及其分解的更详细描述,我们在其中展示了两个不同3D向量的张量积的更一般设置。
此外,从多项式中抽象的结构可以直接扩展到几何概念。实际上,对于一些读者来说,向量空间𝐿2可能看起来很熟悉,因为实际上,这是由角频率l = 2的实球谐函数(模规范化因子)所张成的向量空间,它们构成了一个函数向量空间,其在𝑆𝑂(3)的群表示下变换为不可约表示。类似地,向量空间𝐿0与l = 0的球谐函数成正比,对于球面𝑠 ∈ S2上的所有点,它是一个常数。我们将在第2.5.4节中介绍一个易于理解的应用来展示球谐函数,并在第2.7节中提供详细描述。简而言之,球谐函数构成了球面上函数的正交基。这意味着在3D旋转下,由于这些自由度在角度上是正交的,任何具有唯一原点的3D空间中的函数都可以分解为径向和角度自由度。事实上,球谐函数是对球面进行傅里叶变换的基函数,由于周期性边界条件(类似于周期空间域上的傅里叶变换),它必须具有整数频率。因此,球谐函数具有广泛的应用,从计算机图形学中的照明,声波信号处理,到物理系统的描述,例如分析宇宙微波背景并描述原子轨道。
2.5.2 通过离散的例子来说明不可约表示的例子。
在2.5.1节中,我们提供了群和表示理论的概述,即介绍不可约表示以及等变神经网络如何通过张量积产生不可约表示。在本节中,我们通过一个简单的例子解释对称群和不可约表示。我们进一步阐明了等变神经网络融合这些对称性以实现有效学习的动机。请注意,2.5.1节给出了一个连续的形式,可能更具普适性。然而,我们相信通过离散的群变换更容易理解概念,如下所示。
考虑一个正方形,其中每个节点都有一个标量特征𝑎1∼4。正方形的对称群称为𝐶4𝑣,包括90°旋转、沿垂直和水平轴的镜像以及沿两条对角线的镜像。在这些对称变换下,四个标量特征相互转化,形成𝐶4𝑣群的四维表示。这个表示是可约的,可以分解为三个不可约表示:𝑎1 + 𝑎2 + 𝑎3 + 𝑎4,𝑎1 - 𝑎2 + 𝑎3 - 𝑎4和(𝑎1 - 𝑎3, 𝑎2 - 𝑎4)。前两个是一维的不可约表示,第三个是二维的不可约表示。我们可以验证每个不可约表示在𝐶4𝑣变换下都保持不变。第一个不可约表示在所有对称变换下是不变的。第二个不可约表示在90°旋转以及沿垂直和水平轴的镜像下改变符号。第三个不可约表示以2D向量的方式进行变换。
为了确保等变性,学习结果也必须被分类为相应地在群变换下进行变换的不可约表示。因此,等变神经网络是一个将不可约表示映射到不可约表示的函数,其受到底层对称群的严格限制。根据群论,𝐶4𝑣群有五个不同的不可约表示,四个1D的不可约表示标记为𝐴1,𝐴2,𝐵1,𝐵2,一个2D的不可约表示标记为𝐸。𝐴1不可约表示对应于不变不可约表示,例如之前提到的𝑎1 + 𝑎2 + 𝑎3 + 𝑎4。𝐴2不可约表示在旋转下保持不变,但在两个反射下改变符号。最简单的𝐴2表示是(𝑎1 - 𝑎2 + 𝑎3 - 𝑎4)(𝑎1 - 𝑎3)(𝑎2 - 𝑎4),它对𝑎𝑖具有三次方的阶数。𝐵1不可约表示在90°旋转和水平/垂直反射下改变符号,例如𝑎1 - 𝑎2 + 𝑎3 - 𝑎4。𝐵2不可约表示在90°旋转和对角线反射下改变符号,例如(𝑎1 - 𝑎3)(𝑎2 - 𝑎4)。𝐶4𝑣群只有一个2D不可约表示,标记为𝐸,它以2D向量的方式进行变换,例如(𝑎1 - 𝑎3, 𝑎2 - 𝑎4)。
不可约表示对于等变学习结果𝑓从四个标量特征𝑎1∼4的形式施加了强烈限制。为了简单起见,让𝑓是输入特征𝑎𝑖的线性函数。在对称变换下不变的学习结果必须与𝑎1 + 𝑎2 + 𝑎3 + 𝑎4成比例。另一方面,如果期望𝑓作为一个2D向量具有等变性,它必须与(𝑎1 - 𝑎3, 𝑎2 - 𝑎4)成比例,但可能有一个常数旋转。
将二次和高阶学习结果划分为涉及不可约表示的乘积的不同不可约表示。在𝐶4𝑣的情况下,任何1D不可约表示与2D不可约表示的乘积变为2D不可约表示。例如,一个2D的二次项𝑓必须是(𝑎1 + 𝑎2 + 𝑎3 + 𝑎4)(𝑎1 - 𝑎3, 𝑎2 - 𝑎4)或者(𝑎1 - 𝑎2 + 𝑎3 - 𝑎4)(𝑎1 - 𝑎3, 𝑎4 - 𝑎2)。另一方面,两个2D不可约表示的乘积分解为三个1D不可约表示:(𝑎1 - 𝑎3)2 + (𝑎2 - 𝑎4)2,(𝑎1 - 𝑎3)2 - (𝑎2 - 𝑎4)2,(𝑎1 - 𝑎3)(𝑎2 - 𝑎4)。第一个是不变的,就是𝐴1不可约表示,与𝑎1 + 𝑎2 + 𝑎3 + 𝑎4相同。第二个在旋转和水平/垂直反射下改变符号,就是𝐵1不可约表示,与𝑎1 - 𝑎2 + 𝑎3 - 𝑎4相同。第三个,在对角线反射下改变符号,是𝐵2不可约表示。如果期望学习结果以𝐴2不可约表示的方式变换,即在旋转下保持不变,在反射下改变符号,它必须至少是输入特征的三次方形式,其中最简单的形式是(𝑎1 - 𝑎2 + 𝑎3 - 𝑎4)(𝑎1 - 𝑎3)(𝑎2 - 𝑎4)。注意,到目前为止,我们描述了𝐶4𝑣的一个理想情况,即两个不可约表示的乘积可能产生一个不可约表示。然而,在更一般的情况下,例如等变神经网络,张量积会产生一个可约表示,它会进一步分解成作为下一层输入的不可约表示,如2.5.1节所述。从本质上讲,这奠定了现代等变神经网络实现等变性的基础。
这个例子说明了群结构对将输入数据映射到期望的学习结果的函数施加了重要的约束,这是通过它们的不可约表示来实现的。等变神经网络旨在将这些约束明确地融入到网络架构中。通过这样做,等变神经网络可以利用数据中固有的对称性和变换,实现更有效、更高效的学习。
2.5.3 张量积和克莱布斯-戈登系数。
在数学上,张量积被定义为表示双线性映射的方法,可以将标量乘法推广到向量(张量)。让我们考虑两个3D向量 𝑥,𝑦 ∈ R3。𝑓: R3 × R3 → R 是一个以两个3D向量为输入的映射,双线性意味着固定一个输入时,限制映射 𝑓 (·, 𝑦) 或 𝑓 (𝑥, ·) 针对另一个输入是线性的。所有这样的双线性映射都可以写成 𝑓 (𝑥,𝑦) = Σ𝑖𝑗 𝑐𝑖𝑗𝑥𝑖𝑦𝑗 的形式,其中 𝑥𝑖 和 𝑦𝑗 是 𝑥 和 𝑦 中的元素,𝑐𝑖𝑗 是定义不同映射的系数。𝑥 和 𝑦 的张量积被定义为 𝑥 ⊗ 𝑦 = [𝑥1𝑦1, 𝑥1𝑦2, 𝑥1𝑦3, 𝑥2𝑦1, 𝑥2𝑦2, 𝑥2𝑦3, 𝑥3𝑦1, 𝑥3𝑦2, 𝑥3𝑦3]𝑇 ∈ R9。如果我们定义一个系数向量 𝑐 = [𝑐11,𝑐12,𝑐13,𝑐21,𝑐22,𝑐23,𝑐31,𝑐32,𝑐33]𝑇 ∈ R9,那么任何双线性映射可以表示为 𝑓 (𝑥,𝑦) = 𝑐𝑇 (𝑥 ⊗ 𝑦)。因此,𝑓 存在于一个9维向量空间中,它的基可以通过张量积来定义。具体来说,基可以定义为 {𝑒𝑖 ⊗𝑒𝑗}𝑖,𝑗∈{1,2,3},其中 𝑒𝑖 和 𝑒𝑗 是原始3D空间的标准正交基向量,例如 𝑒 = [1, 0, 0]𝑇。因为 𝑒 ⊗ 𝑒 是向量,在第(3𝑖 + 𝑗)个位置上为1,在其他地方为0,所以它们彼此正交。 张量积的一个重要性质是其等变性。当 𝑥 和 𝑦 经历一个由旋转矩阵 𝑅 ∈ R3×3 定义的全局旋转时,张量积中的每个元素 𝑅𝑥 ⊗ 𝑅𝑦 的形式都是 Σ𝑖𝑗 𝑐𝑖𝑗𝑥𝑖𝑦𝑗,其中 𝑐𝑖𝑗 是从𝑅的元素计算得到的。因此,张量积 𝑥 ⊗ 𝑦 也被一个矩阵变换。设该矩阵为 𝑅⊗,我们有 𝑅⊗ (𝑥 ⊗ 𝑦) = 𝑅𝑥 ⊗ 𝑅𝑦。𝑅⊗ 定义了旋转如何在张量积空间中进行变换。注意 𝑅⊗ 是一个9×9的矩阵,维度随输入空间的维度快速扩展。因此,我们希望找到更小的构建块来高效地描述 𝑥 ⊗ 𝑦 在旋转下的变换。幸运的是,对于3D旋转,我们可以做到这一点。例如,我们知道在应用全局旋转时,两个向量的点积不变。点积是一个双线性映射,定义为 𝑓dot(𝑥,𝑦) = 𝑥1𝑦1 +𝑥2𝑦2 +𝑥3𝑦3。用张量积基表示,点积可以用系数向量 𝑐dot = [1, 0, 0, 0, 1, 0, 0, 0, 1]𝑇 定义。点积的旋转不变性给出了 𝑐𝑇dot (𝑅𝑥 ⊗ 𝑅𝑦) = 𝑐𝑇dot𝑅⊗ (𝑥 ⊗ 𝑦) = 𝑐𝑇dot (𝑥 ⊗ 𝑦)。由于这对于所有的 𝑥 和 𝑦 都成立(例如 𝑥 ⊗ 𝑦 可以是任意基向量 𝑒𝑖 ⊗ 𝑒𝑗 ),我们有 𝑐𝑇dot𝑅⊗ = 𝑐𝑇dot。因此,由点积张成的空间(即 𝜆𝑐dot,其中 𝜆 ∈ R)定义了𝑅⊗ 的一个1维稳定子空间。 另一个稳定子空间是叉积张成的空间。从几何角度来看,我们知道叉积对旋转时具有等变性。叉积可以表示为3个双线性映射的叠加结果(向量输出),如下所示:
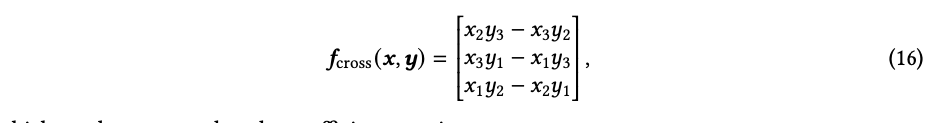
它可以表示为系数矩阵:
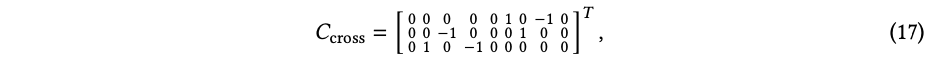
它是一个 9 × 3 的矩阵,用来表示 3 个输出维度。叉积的等变性给出了 𝑓cross (𝑅𝒙, 𝑅𝒚) = 𝑅𝑓cross(𝒙,𝒚),在张量积基下可以写作 𝐶𝑇cross(𝑅𝒙 ⊗ 𝑅𝒚) = 𝐶𝑇cross𝑅⊗(𝒙 ⊗ 𝒚) = 𝑅𝐶𝑇cross (𝒙 ⊗ 𝒚),对于所有的 𝒙 和 𝒚 都成立。因此我们有: 𝐶𝑇cross𝑅⊗ = 𝑅𝐶𝑇cross。 (18)
我们可以证明叉积张成的空间对于 𝑅 ⊗ 而言定义了一个 3 维稳定子空间。为了证明这一点,假设 𝒗 = 𝐶cross𝝀𝑇 是一个在张量积基上的向量,定义为 𝐶cross 列的线性组合,其中 𝝀 ∈ R3,𝒗 ∈ R9。我们有 𝒗𝑇 𝑅⊗ = 𝝀𝐶𝑇cross𝑅⊗ = 𝝀𝑅𝐶𝑇cross := 𝒖𝑇,其中 𝒖 = 𝐶𝑇cross (𝑅𝑇 𝝀𝑇 ) ∈ R9 仍然是 𝐶cross 列的线性组合。因此,我们已经证明了由 𝐶cross 列张成的 3 维空间对于 𝑅⊗ 是稳定的。 为了完整地描述这个分解,我们可以将双线性映射的系数向量 𝒄 包装成一个矩阵,如下所示:
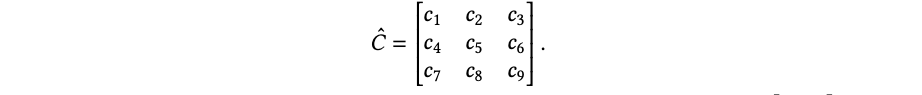
那么由点积张成的系数空间可以写成 𝜆1𝐶dot = 𝜆1
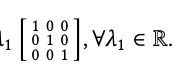
。由叉积张成的系数空间可以写成:
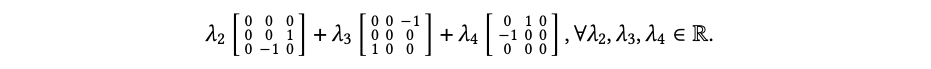
当将任意系数 𝐶ˆ 投影到由点积张成的空间时,提取出 𝐶ˆ 的迹。可以验证,由叉积张成的空间表示所有反对称矩阵的空间,即 𝐴𝑇 =−𝐴。在𝐶ˆ 的9维空间中剩余的自由度导致了所有迹为0的对称矩阵的空间,即 𝐴𝑇 = 𝐴, 𝐼 𝐴 = 0,𝑖 𝑖𝑖,这是一个5维空间。总结一下,我们将任意的 𝐶ˆ 表示为以下求和形式:

为了证明对称无迹部分的确是5维的,我们可以扩展基础并将其写成:
![]()
使用张量积基础进行转换,我们可以推导出函数𝑓5𝐷的表达式为:
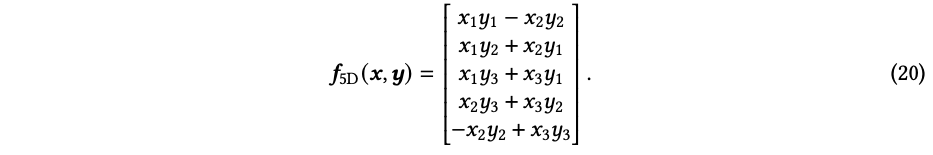
重要的是,方程式(19)意味着9维系数空间可以被视为1维、3维和5维向量空间的直和,而且每个向量空间都对任意全局旋转都是稳定的。这种分解可以概念化地写成3 ⊗ 3 = 1 ⊕ 3 ⊕ 5。 值得注意的是,通常这种分解依赖于变换的选择。在这里,变换是3维旋转(𝑆𝑂(3)群)。如果我们选择另一种变换,分解将会不同。例如,对于平凡变换(群𝐺 = {𝑒}),分解将导致9个一维平凡子空间。 这些子空间的一个重要特性是它们不能进一步分解,并且对全局旋转保持稳定(即它们是不可约的)。由点积张成的1维子空间在旋转下作为标量进行变换,并且根据定义是不可约的。由叉积张成的3维子空间作为向量进行变换,我们可以证明它也是不可约的。具体来说,根据方程式(18),由𝐶cross张成的3维空间在旋转下由相同的旋转矩阵𝑅进行变换。由于任何3维向量(在任何基底下)都可以通过一些3维旋转变换为与任何其他3维向量共线,因此在叉积空间中不存在较小的子空间在任意旋转下都保持稳定。对于5维子空间,直观地证明其不可约性需要更高级的理论,比如物理学中的角动量或数学中的特征理论。然而,我们可以通过注意到其分量𝑥1𝑦1 −𝑥2𝑦2在围绕𝑧轴90度旋转时改变符号(即,(𝑥1,𝑥2)←(−𝑥2,𝑥1)和(𝑦1,𝑦2)←(−𝑦2,𝑦1)),来对𝑓5D的行为获得一些直观的理解。更一般地说,𝑓5D对应于l = 2的表示。直观地说,l = 2的对象是在180度旋转后回到自身的对象。 通常,对于任何输入维度,我们可以确定所有这些稳定子空间,以便当输入经过全局旋转时,张量积空间中的子空间不会相互混合。通过转换为这些稳定子空间的直和基,可以高效地将𝑅⊗表示为一个块对角形式。执行这种基变换的矩阵是克莱布什-戈登(CG)系数。总之,张量积定义了两个向量空间之间所有的双线性映射的基础,这在研究在应用全局变换时的等变性时特别合适,因为等变性本质上描述了输入无关的变换之间的映射关系。
2.5.4 球谐函数投影和等变网络。
(实数)球谐函数 Yml: S2 → R 是定义在单位球面 S2 上的特殊函数。它们构成了在 S2 上定义的函数的一个完备正交基。因此,每个在 S2 上的函数都可以展开为这些球谐函数的线性组合。这种展开类似于基于向量空间 V 的一个完备正交基 {u1,...,un} 对向量 v 的傅里叶展开式:
v = ∑︁〈ui,v〉ui. (21)
i=1 类似地,一个球面函数 f(·) : S2 → R 可以通过球谐函数展开来表示:
f(Ω) = ∑︁al,mYml(Ω), (22)
l,m 其中 a〈Yl,f〉=∫Yl(Ω)f(Ω)dΩ. l,m m
我们以 Dirac δ 函数作为示例来说明球谐函数展开的思想。
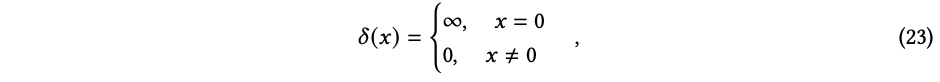
设 Ω, Ω′ ∈ S2 并且 f = δ(Ω - Ω′),那么我们可以得到:
∫ Yml(Ω)δ(Ω - Ω′)dΩ = Yml(Ω′). (24)
因此,Dirac δ 函数的球谐函数展开为:
f = δ(Ω - Ω′) = ∑︁al,mYml(Ω) = ∑︁Yml(Ω′)Yml(Ω). (25) l,m l,m
上述的 δ 函数展开是球谐函数投影的基础,它在等变神经网络中的局部等变描述符和卷积操作中被广泛使用。具体来说,将一个几何向量投影到球谐函数中包含了两个部分:一个径向基函数用于嵌入向量的长度;球谐函数展开中的 δ 函数用于嵌入向量的方向。设一组几何向量 {ri ∈ R3}𝑛𝑖=1 和球谐函数的输入𝑥 ∈ R3,∥𝑥 ∥2 = 1。球谐函数投影的表达式为:
∑︁∑︁lil 𝜙(∥ri∥2) Ym ∥r ∥ Ym(x), (26)
𝑛 𝑖=1 l,m i2 这里 𝜙 (·) : R → [0, ∞) 是径向基函数,用于提供投影的缩放。由于出于计算的效率考虑,l 通常在半径上定义,而不是在整个非负整数范围上,所以这个求和近似代表了 Dirac δ 函数,而不是精确计算。假设 l ≤ 6 且 ∥r ∥2 = 1,球谐函数投影在向量 r 周围形成了一个斑点,如图 7 (a) 所示。当 x 接近 r 时,投影值较大且距离球心的距离较长。通过将每个单独的投影相加,可以嵌入多个向量,从而在球面上形成多个斑点,如图 7 (b) 所示。
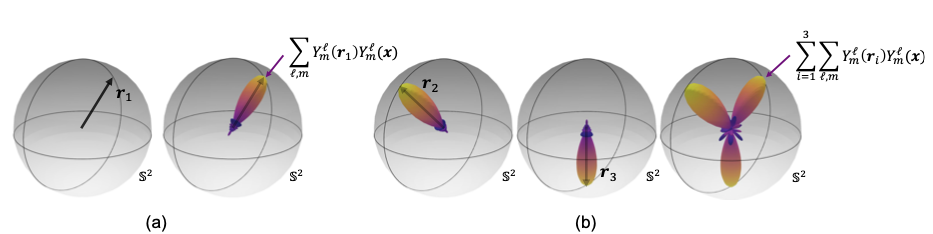
图 7. 球谐函数投影的示意图:(a) 单个单位向量和 (b) 多个单位向量。 (a) 绘制了一个单位向量 𝒓1 及其从球谐函数投影中重构的结果。单位向量在数学上被建模为单位球面 S2 上的一个 Dirac δ 函数,其值只在指向的方向上非零。球谐函数定义了 S2 上的函数的一组基函数,而δ函数可以被重构为球谐函数的线性组合,其中线性系数表示函数的嵌入。球谐函数投影包含无限多项,而在绘制的重构中仅使用了 l ≤ 6 的项。为了清楚地可视化球面上的函数,重构被绘制成一个三维斑点,其中到原点的距离表示球面上沿该方向的函数幅度。此外,重构中的最大幅值被缩放为一便于可视化。
(b) 通过求和单独的投影,可以使用球谐函数投影嵌入多个向量。这里,我们展示了一个示例,其中包括两个额外的向量 𝒓2 和 𝒓3,𝒓1, 𝒓2, 𝒓3 首先通过球谐函数投影进行单独的嵌入,然后将它们的嵌入结果相加以形成一个整体的嵌入,即在球面上形成三个斑点。该示例经过 Tess Smidt 授予授权后进行了调整。
2.5.5 球谐函数与角动量。 前述的基于球谐函数的特征编码和TP操作实际上与物理科学密切相关,特别是量子力学。在物理学中,球谐函数常用于解决偏微分方程。具体而言,对于类似氢原子的单电子氢离子,电子的本征波函数是薛定谔方程的一组解析解,由径向部分𝑅𝑛𝑙 (𝑟 )和复球谐函数的乘积给出。球谐函数的更多细节可见于第2.7节。后者可以转化为常用于第一性原理DFT、量子化学和近期深度学习模型的实球谐函数𝑌𝑚l (𝜃,𝜑)。实球谐函数的集合,表示为𝑌𝑚l (𝜃 , 𝜑 ) : S2 → R,其中l ∈ N是轨道角动量量子数,𝑚 ∈ Z,−l ≤ 𝑚 ≤ l是磁量子数,形成了一组完备正交基函数,可用于展开任意球面函数。此外,在物理系统中,TP操作通常用于角动量耦合。具体而言,在考虑具有库仑相互作用的系统中的两个电子时,耦合波函数的角动量可以从分离角动量的TP中推导出来。除了用于特征表示外,球谐函数还在第4节中用于量子张量学习,如量子哈密顿学习。
2.6 群和表示论
作者:Maurice Weiler, YuQing Xie, Tess Smidt, Erik Bekkers 通过群和表示论的语言,提出了等变神经网络的概念,这个部分简要介绍了相关基础知识。在第2.6.1节中,对一些基本概念进行了解释,然后在第2.6.2节中解释了群作用于其他对象的方式,并定义了关于这些作用的不变和等变函数。在深度学习中,对称群作用于数据和特征,网络层被限制为不变或等变的。网络的特征空间通常是向量空间。群作用于向量空间可以通过群表示论来描述,该理论在第2.6.3节中进行了讨论。
2.6.1 对称群 群是代数对象,形式化了诸如平移、旋转或置换等对称变换。为了激发其正式定义,首先注意到我们总是可以将任意两个变换组合成一个变换。这些变换的组合自然地符合一定的性质,这些性质刻画了群的代数结构。例如,考虑平面旋转的情况。每个旋转可以用一个旋转角度来表示,任意两个旋转𝛼和𝛽可以组合成一个旋转𝛼 + 𝛽(模2𝜋)。注意到,任意角度为𝛼的旋转可以通过相反的角度−𝛼的旋转来撤销。此外,存在一个平凡的“恒等”变换,即旋转角度为0度的变换,它并不起任何作用。最后,给定三个旋转角度𝛼,𝛽和𝛾,旋转的组合顺序是无关紧要的,也就是(𝛼 + 𝛽) + 𝛾 = 𝛼 + (𝛽 + 𝛾)。群的定义恰为由满足这三个性质的变换集合组成。
定义1(群)。设𝐺是一个集合,•:𝐺 × 𝐺 → 𝐺是一个从𝐺中取两个元素并映射到另一个元素的二元运算。如果(𝐺, •)满足以下三个公理,则它们构成一个群:
(1)逆元:对于任意𝑔 ∈ 𝐺,都存在一个逆元素𝑔−1 ∈ 𝐺,满足𝑔 • 𝑔−1 = 𝑔−1 • 𝑔 = 𝑒;
(2)单位元:存在一个单位元素𝑒 ∈ 𝐺,满足𝑒 • 𝑔 = 𝑔 • 𝑒 = 𝑔,对于任意𝑔 ∈ 𝐺;
(3)结合性:(𝑔 • 𝑘) • 𝑙 = 𝑔 • (𝑘 • 𝑙),对于任意𝑔,𝑘,𝑙 ∈ 𝐺。
为了简洁起见,我们通常称集合𝐺而不是(𝐺, •)为群,并省略符号中的运算,将𝑔 • 𝑘写成𝑔𝑘。在没有歧义的情况下,我们将使用这些缩写。
实际上,平面旋转的组合还满足一个性质:对于任意两个角度𝛼和𝛽,组合的顺序是无关紧要的,因为𝛼 + 𝛽 = 𝛽 + 𝛼。这种群元素的可交换性并没有包含在上述定义中,因为它不适用于所有的对称群。例如,在三维空间中的非平面旋转互相不可交换,旋转与平移或反射不可交换,一般而言置换也不可交换。像平面旋转这样的群,其元素可交换,被称为可交换群。
定义2(可交换群)。设𝐺是一个群。如果群中的所有元素都可交换,即对于任意𝑔、h ∈ 𝐺,都有𝑔h=h𝑔,则该群称为可交换群。
矩阵群是一类重要的群,它们由通过矩阵乘法组成的方阵集合,满足三个群公理。结合性在矩阵乘法的定义下成立;单位元由单位矩阵给出;并且这个集合要求在矩阵逆运算下封闭。举个例子,考虑所有可逆的𝑛 × 𝑛矩阵的集合𝐺𝐿(R𝑛) := {𝑔 ∈ R𝑛×𝑛 | det(𝑔) ≠ 0},它被称为一般线性群,并在几何上解释为R𝑛的所有可能的基变换的群。由于矩阵乘法一般不可交换,因此该群不是可交换群。
群可能包含自身形成的子集,这些子集被称为子群。
定义3(子群)。设𝐺是一个群,𝐻是𝐺的一个变换的子集。如果𝐻仍然形成一个群,则称其为𝐺的一个子群。
可以证明,只需检查𝐻在组合运算下封闭,即对于任意𝑔,h ∈ 𝐻,都有𝑔h ∈ 𝐻,并且在取逆运算下封闭,即对于任意𝑔 ∈ 𝐻,都有𝑔−1 ∈ 𝐻。
例如,我们考虑矩阵群𝑆𝑂(𝑛) := {𝑔 ∈ R𝑛×𝑛 | det(𝑔) = 1}是𝐺𝐿(R𝑛)的一个子群。它不包含所有行列式非零的𝑛 × 𝑛矩阵,而只包含行列式为1的子集。很明显,它是𝐺𝐿(R𝑛)的子群,因为它在组合运算下封闭,对于任意𝑔、h ∈ 𝑆𝑂(𝑛),det(𝑔h) = det(𝑔) det(h) = 1,且在取逆运算下封闭,det(𝑔−1) = det(𝑔)−1 = 1。𝑆𝑂(𝑛)群被称为特殊正交群,因为它由旋转矩阵组成,用于在R𝑛的正交基之间进行变换。𝐺𝐿(R𝑛)中还有更大的(非特殊)正交子群𝑂(𝑛) := {𝑔 ∈ R𝑛×𝑛 | det(𝑔) = ±1},它包含了旋转和反射。
2.6.2 群作用和等变映射。
上述对对称群的抽象定义捕捉到了它们在组合运算下的代数性质,但尚未描述出对其他对象的转换。同一个群可以在不同的对象上进行作用,例如不同的特征空间。例如,在二维空间中,旋转群𝑆𝑂 (2)通过矩阵乘法自然地作用于二维向量在R2中,但二维旋转也可以围绕不同的轴在R3中进行,甚至可以通过在空间中旋转它们来对图像或点云进行变换。 因此,除了具有对称群𝐺之外,我们还需要考虑一个集合或空间𝑋,并且需要指定群在其上的作用方式。这个作用应满足连续应用两个群元素𝑔和h的变换应等于通过组合的群元素𝑔h的单个变换。此外,希望单位群元素𝑒保持作用对象不变。这些观察结果引发了如下定义。
定义4(群作用)。假设有一个群𝐺,并且用𝑋表示将被作用于集合。那么,(左)群作用被定义为一个映射 ▷:𝐺×𝑋→𝑋, (𝑔,𝑥)↦→𝑔▷𝑥 (27)
它满足以下两个条件: (
1)结合性:对于任意𝑔,h ∈ 𝐺和𝑥 ∈ 𝑋,组合作用可以分解为(𝑔h) ▷ 𝑥 = 𝑔 ▷ (h ▷ 𝑥);
(2)单位元:对于任意𝑥 ∈ 𝑋,单位元素𝑒 ∈ 𝐺的作用是平凡的,即,𝑒 ▷ 𝑥 = 𝑥。
一个配备有𝐺-作用的集合(或空间)𝑋被称为𝐺-集(或𝐺-空间)。 一般而言,函数𝑓 : 𝑋 → 𝑌映射从集合𝑋到集合𝑌。不变函数和等变函数更具体地映射在𝐺-集之间,并在遵守它们的群作用方面与之共享。对于不变函数,当输入发生变换时,输出根本不变。
定义5(不变映射)。设𝑓 : 𝑋 → 𝑌为一个函数,其定义域𝑋受到𝐺-作用▷𝑋的影响。如果这个函数在输入变换下输出不变,即当
𝑓(𝑔▷ 𝑥)=𝑓(𝑥)对于任意𝑔∈𝐺,𝑥∈𝑋,那么这个函数被称为𝐺-不变的。(28)
这个定义可以用图形方式表达,要求对于任意𝑔 ∈ 𝐺,以下示意图都是可交换的,这意味着沿着顶部箭头进行的操作产生的结果与沿着底部路径进行的操作产生的结果相同:

深度学习中的许多对象应具有群不变性。例如,图像分类应该通常是平移不变的,或者分子的电离能应该在分子的旋转和反射下保持不变。
等变性通过允许输出与输入共同变换来推广这一定义:函数输入的任何𝐺-变换都会导致输出的相应𝐺-变换。
定义6(等变映射)。设𝑓 : 𝑋 → 𝑌为一个函数,其定义域𝑋和值域𝑌分别受到𝐺-作用▷𝑋和▷𝑌的影响。如果它的输出根据输入的变换而变换,即当 𝑓(𝑔▷ 𝑥)=𝑔▷ 𝑓(𝑥) 对于任意𝑔∈𝐺,𝑥∈𝑋,那么这个函数被称为𝐺-等变的。(30) 𝑋𝑌 相应的交换图示如下:

作为深度学习中的等变映射示例,考虑一个预测分子磁矩的神经网络。由于物理的基本规律是旋转不变的,分子的旋转应导致预测的磁矩相应地旋转,也就是说,映射需要是旋转等变的。等变网络层的标准示例是卷积层:可以很容易地验证,它们的输入特征图的平移会导致相应输出特征图的平移。𝐺可旋转卷积将这种行为推广到更一般的对称群 [Weiler et al. 2018a; Thomas et al. 2018; Weiler and Cesa 2019a]。
2.6.3 群表示。
群表示理论具体描述了对称群在向量空间上的作用方式。群表示𝜌𝑋(𝑔)可以被看作是由群元素𝑔 ∈ 𝐺参数化的一组矩阵,通过矩阵乘法对向量空间𝑋进行作用,𝜌𝑋(𝑔): 𝑋 → 𝑋。例如,对于一个单个三维笛卡尔向量空间(𝑥,𝑦,𝑧),常称为(𝑥,𝑦,𝑧),三维旋转𝑆𝑂(3)的表示采用熟悉的3×3矩阵形式,这些矩阵本身可以通过许多方式参数化,例如轴角、欧拉角或四元数都是𝑔 ∈ 𝑆𝑂(3)的有效参数化方式。令人困惑的是,群表示在口语中可以指群𝐺对特定向量空间𝜌𝑋(𝑔)的矩阵表示,群作用的向量空间𝑋,或者是对(𝜌𝑋 , 𝑋)这对的称呼。
群的定义对这些矩阵表示施加了特定的约束:它们必须是可逆的,即𝜌𝑋(𝑔−1) = 𝜌𝑋(𝑔)−1,该表示的任意两个元素的乘积也必须是群𝐺的表示,而群表示总是包含单位矩阵I,这是群论文献中常称的群元素𝑒的表示。
定义7(群表示)。考虑一个群𝐺和一个向量空间𝑋。𝐺在𝑋上的群表示是一个(𝜌𝑋 , 𝑋)的二元组,其中 𝜌𝑋: 𝐺→𝐺𝐿(𝑋) (32)
是从𝐺到𝑋的通用线性群𝐺𝐿(𝑋)的群同态映射,即从𝑋到自身的可逆线性映射组成的群。𝜌𝑋是同态映射意味着
𝜌𝑋(𝑔h) = 𝜌𝑋(𝑔)𝜌𝑋(h) ∀𝑔,h∈𝐺 (33),
这确保了左边的群组合与右边的矩阵乘积相容。
容易证明,从该定义可以得出𝜌𝑋(𝑔−1) = 𝜌𝑋(𝑔)−1和𝜌𝑋(𝑒) = I。
2.6.4 不可约表示。
群表示并不是唯一的,我们有以下定义:
定义8(同构表示)。
设𝜌𝑋和𝜌𝑌是作用于向量空间𝑋和𝑌上的群𝐺的表示。如果存在一个向量空间同构映射𝑄:𝑋→𝑌,使得对于所有𝑔∈𝐺都满足
𝑄𝜌𝑋 (𝑔) = 𝜌𝑌 (𝑔)𝑄. (34)
如果𝑄是可逆的,使得𝜌𝑌 (𝑔) = 𝑄−1𝜌𝑋 (𝑔)𝑄,那么可以将其看作是一种基础的变换。如果𝑄是幺正的,那么它只是对向量空间基础的“旋转”。 群表示论中最有力的结果之一是存在可约表示和不可约表示(irrep)。可约表示包含多个独立的不可约表示。不同的不可约表示所张成的向量空间在群作用下不会混合,即它们是独立的。
定义9(可约和不可约表示)。
群𝐺的表示𝜌𝑋被称为可约表示,如果它含有一个非平凡的𝐺不变子空间。换句话说,存在𝑉⊂𝑋,其中𝑉≠0,使得对于所有𝑔∈𝐺都满足𝜌𝑋 (𝑔)𝑉 = 𝑉。 如果不存在这样的子空间,则该表示被称为不可约(通常简称为irrep)。 在大多数情况下,如果一个表示𝜌𝑋 (𝑔)是可约的,那么存在相似变换𝑄𝜌𝑌 (𝑔) = 𝜌𝑋 (𝑔)𝑄,使得𝜌𝑌 (𝑔)是块对角的。 在等变神经网络中,考虑的对称群通常以某种明确定义的方式对我们的数据进行作用。例如,分子上原子的坐标会在旋转矩阵下进行变换。因此,我们的输入数据处于某些表示的向量空间中。由于表示可以被分解为不可约表示的直和,我们可以将我们的数据变换指定为这些不可约表示的列表。换句话说,不可约表示是等变神经网络中的自然数据类型。 然而,同一个群可能会有多个等同的表示。因此,在指定表示的不可约表示时,我们必须做出选择。此外,我们希望一种方式来标记我们的不可约表示,而这种方式与矩阵的具体选择无关。对于有限群,可以使用特征来进行标记。这本质上是我们的不可约表示中矩阵的迹,这也是特征表广泛使用的原因(虽然对于点群的不可约表示通常有其他命名约定)。关于特征和有限群不可约表示的更多细节可以在附录的有限群分类和计算不可约表示的部分找到。 对于无穷群,使用特征是不可行的,因为群元素是无穷的。相反,我们可以使用对半单列群的不可约表达式的理论。对于𝑆𝑂 (3)(和𝑆𝑈 (2))的情况,这本质上给出了高次数或角动量量子数l。一般来说,不可约表示由所谓的主积分权标记。这是一个被称为最高权定理的非常重要的定理的结果。关于半单列群表示论的简要介绍可以在附录的半单列群分类和计算不可约表示的部分找到。
2.7 𝑆𝑂 (3) 群和球谐函数
作者: 徐胜龙 离散群𝐶4𝑣是最简单的非阿贝尔点群之一,具有有限个不可约表示。另一方面,与许多科学领域相关的三维旋转群𝑆𝑂 (3) 是连续的。它具有无限个通过正整数l = 0, 1, 2, 3,...标记的不可约表示,称为角动量,每个不可约表示的维数为2l + 1。 𝑆𝑂(3)的不可约表示使用球谐函数表示,记为𝑌l (𝜃,𝜙)或𝑌l (𝑟ˆ), 𝑚𝑚,其中−l ≤ 𝑚 ≤ l。对于固定的角动量l,2l + 1个球谐函数形成𝑆𝑂 (3)群的对应不可约表示。通过求解球坐标下的三维拉普拉斯方程得到这些球谐函数。拉普拉斯方程可以写成: ∇®2𝑓 (𝑟®) = 0. (35) 在球坐标下,它变为:
1𝜕2𝜕𝑓 12 2 𝑟 − 2lˆ𝑓=0, (36)
𝑟𝜕𝑟 𝜕𝑟 𝑟 其中𝑙ˆ2表示角度部分:
1𝜕 𝜕𝑓 1𝜕2𝑓 𝑙ˆ𝑓=− sin𝜃−22. (37)
由于拉普拉斯方程在𝑆𝑂 (3)的旋转以及径向变量𝑟下是不变的,仅依赖于角度变量的算符𝑙ˆ2也是旋转不变的。通过分离变量的方法,我们可以将解𝑓 (𝑟®)分离成径向部分𝐺(𝑟)和角度部分𝑌(𝜃,𝜙),使得𝑓 (𝑟®) = 𝐺(𝑟)𝑌(𝜃,𝜙)。将其代入拉普拉斯方程,我们得到两个方程:
1 𝜕 2𝜕𝐺(𝑟) 1 2 2 𝑟 − 2𝜆𝐺(𝑟)=0, ℓˆ𝑌(𝜃,𝜙)=𝜆𝑌(𝜃,𝜙). (38)
𝑟𝜕𝑟 𝜕𝑟 𝑟 让我们关注第二个方程,它仅依赖于角度变量。它表示𝑙ˆ2的特征值方程。由于边界条件的限制,特征值只能是l(l + 1),其中l取值l = 0,1,2,3,...等。对于给定的l,存在2l + 1个线性无关解,即球谐函数,记为𝑌𝑚l (𝑟ˆ),其中𝑚是从 -l到l的整数,标记了这2l + 1个解。 𝑙ˆ2的特征值方程是旋转不变的。因此,解在旋转下变换保持不变。如果𝑌𝑚l (𝑟ˆ)是特征值为l(l+1)的解,旋转后的函数𝑌𝑚l (𝑅𝑟ˆ)也是特征值相同的解。因此,旋转后的函数可以表示为不同𝑚值的线性组合,同时保持相同的l值。换句话说,我们有:
l 𝑌l(𝑅𝑟ˆ)=∑︁𝐷 ′(𝑅)𝑌l′(𝑟ˆ), (39)
𝑚 𝑚𝑚𝑚 𝑚′=−l 其中𝐷𝑚𝑚′ (𝑅)是一个依赖于旋转𝑅的矩阵。该矩阵表示2l + 1个解所张成的向量空间在三维旋转下的变换。因此,这2l + 1个解,它们具有相同的l但不同的𝑚值,形成了一个在三维旋转下闭合的向量空间。这个向量空间对应𝑆𝑂 (3)群的一个不可约表示。 球谐函数在许多科学领域中非常重要,因为它们是任意旋转不变偏微分方程解的角度部分。例如,在拉普拉斯方程中添加一个势能项𝑉(𝑟),只会影响径向方程而不会影响角度特征方程。球谐函数也是原子的薛定谔方程的解,提供了电子波函数的量子力学描述。在这个背景下,角动量量子数l的值对应于不同类型的原子轨道: 𝑠(w = 0), 𝑝(w = 1), 𝑑(w = 2), 和 𝑓(w = 3)轨道。
传统上,球谐函数是复函数,采用以下形式:
√(2l + 1) (l - 𝑚)! 𝑌l (𝜃,𝜙) = 𝑃𝑚(cos𝜃)𝑒^(𝑖𝑚𝜙) (40)
𝑚 4𝜋 (l+𝑚)!l 其中𝑃𝑙𝑚是一个称为关联勒让德函数的多项式函数。它满足以下关系: 𝑃−𝑚(cos𝜃) = (−1)𝑚(l −𝑚)!/(l +𝑚)!𝑃𝑚(cos𝜃)。球谐函数在球上定义的函数中形成一个完备的正交基,任何球形函数都可以用这个基展开:
𝑓 (𝜃,𝜙) = ∑︁𝑎𝑙,𝑚𝑌𝑚𝑙 (𝜃,𝜙) (41)
𝑙,𝑚 类似于傅立叶级数。根据正交归一条件,系数𝑎𝑙,𝑚为: 𝑎𝑙,𝑚 = ∫ 𝑌𝑚𝑙 ∗(𝜃,𝜙)𝑓 (𝜃,𝜙)𝑑 cos𝜃𝑑𝜙。更高阶的球谐函数捕捉了𝑓 (𝜃,𝜙)的更精细细节。 𝑙 = 0, 1, 2的球谐函数如下所示:
0√︂1 𝑌0= 4𝜋 l︀ l′ 𝑌𝑚 (𝜃,𝜙)𝑌𝑚′ (𝜃,𝜙)𝑑 cos𝜃𝑑𝜙 = 𝛿l,l′𝛿𝑚,𝑚′ (42)
1√︂4 −𝑖𝜙 1√︂4 1√︂4 𝑖𝜙 𝑌−1 = sin𝜃𝑒 , 𝑌0 = 8𝜋 cos𝜃, 𝑌1 =− sin𝜃𝑒 8𝜋 (43)
8𝜋 𝑌−22 = 1√︂15 sin^2𝜃𝑒^(−2𝑖𝜙), 𝑌−21 = 1√︂15 sin𝜃cos𝜃𝑒^(−𝑖𝜙), 𝑌02 = 1√︂5(3cos^2𝜃 −1), 𝑌2=−𝑌2 ∗,𝑌2=𝑌2 ∗ 1 −1 2 −2
复数的球谐函数在使用上很方便,因为它在绕𝑧轴旋转时仅获得一个相位,即𝑌l(𝜃,𝜙+𝛾)=𝑒𝑖𝑚𝛾𝑌l(𝜃,𝜙)。在笛卡尔坐标中,有时更直观地考虑复数𝑚球谐函数的实部球谐函数𝑌l。注意到𝑌l(𝜃,𝜙) = (−1)𝑚𝑌l ∗(𝜃,𝜙),这是根据相关的勒让德函数的性质。实部球谐函数的构造方式如下:
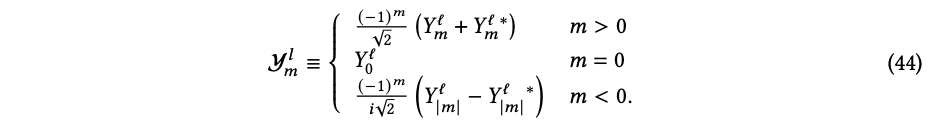
,实部球谐函数与复数球谐函数相同,即
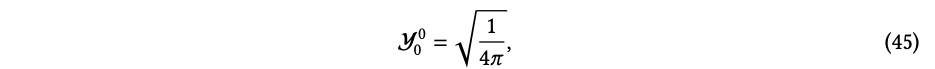
, 它在球面上是一个均匀函数,也被称为原子物理中的𝑠轨道。l = 1的实部球谐函数为:
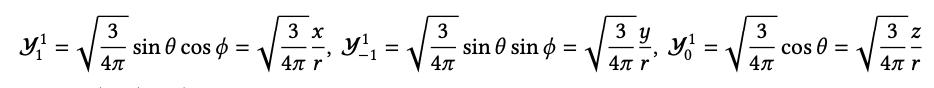
,很明显l = 1的实部球谐函数在旋转下表现为一个三维矢量。这是使用实部球谐函数而不是复数球谐函数的优势之一。在原子物理中,它们被称为𝑝轨道。为了完整起见,下面提供了l = 2的实部球谐函数:
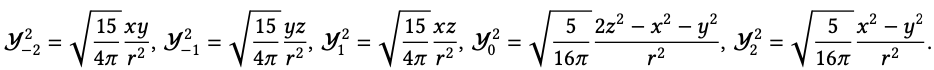
在原子物理中,它们也被称为𝑑轨道。在本文的其余部分中,我们主要使用实部球谐函数,并以𝑌l的形式简化地引用,以方便起见。
2.8基于可控卷积核的等变网络的一般形式
作者:Maurice Weiler,Alexandra Saxton 上述所有等变卷积操作都可以统一在广义表示论语言中,即可控卷积神经网络的理论中[Cohen and Welling 2017a;Weiler et al. 2018b;Weiler and Cesa 2019b;Cohen et al. 2019;Lang and Weiler 2020;Jenner and Weiler 2022;Cesa et al. 2022b;Weiler et al. 2021]。在该理论中,特征空间被解释为特征向量场空间,其变换规律由某个群表示𝜌的选择来确定。核心结果是,这种特征映射之间的等变线性映射由常规卷积给出,但受到对称约束的"可控卷积核"。这种可控卷积的在二维和三维等距群上的实现可在[ Cesa et al. 2022a]中找到。
2.8.1特征向量场。
可控CNN不仅关注单一对称群,例如𝐸(3) = (R3,+)⋊𝑂(3),而是考虑任意仿射变换𝐺的群元Aff(𝐺) = (R𝑑,+)⋊𝐺,其中R𝑑是d维欧几里得空间。它们始终包含平移变换(R𝑑,+),可以证明需要卷积操作。𝐺 ≤𝐺𝐿(R𝑑)是𝑑×𝑑矩阵的子群,包括旋转、反射、缩放或剪切等操作。仿射群元可以表示为𝑡𝑔,其中𝑡 ∈ (R𝑑,+)是平移,𝑔 ∈ 𝐺是矩阵群元素。 如上所述,可控CNN在特征向量场空间中进行操作,这些场由函数表示 𝑓 : R𝑑 → R𝑐 (46) 它将欧几里得空间上的任何点𝑥∈R𝑑指派为维度为𝑐的特征向量𝑓(𝑥)∈R𝑐。这个定义是在连续空间中进行的,但最终可以离散化,例如在像素网格或点云上。 请记住,等变网络层的定义是与群作用相交换的-因此特征场还没有通过方程(46)完全确定,而是还额外配备了Aff(𝐺)的作用,其实例如Figure 8中所示。这些作用的细节由场类型的选择来确定。在给出这些作用的一般定义之前,让我们看一些简单的例子:
• 标量场 𝑠:𝑅𝑑 → 𝑅 由维度𝑐= 1的特征组成,即标量。在纯平移𝑡 ∈ (R𝑑,+)下,它们的变换规律为𝑡 ▷ 𝑠 := 𝑠(𝑡−1𝑥) = 𝑠(𝑥 − 𝑡),即标量值在空间中发生位移。这就是传统平移等变CNN的特征图的变换行为。
• 更一般的仿射群元𝑡𝑔在标量场上的作用为𝑡𝑔▷𝑠 :=𝑠((𝑡𝑔)−1𝑥) =𝑠(𝑔−1𝑥−𝑡)。这添加了空间旋转或反射,例如𝑔 ∈ 𝑂 (𝑑 ),参见图8 (左)。
• 切向量场是函数𝑣:𝑅𝑑 → 𝑅𝑑。
如图8 (右)所示,𝑔 ∈ 𝐺 不仅将向量移动到新的空间位置,还会对每个向量本身进行作用,例如当𝐺 = 𝑆𝑂(𝑑)时旋转向量。数学上,这个作用的公式为𝑡𝑔 ▷ 𝑣 := 𝑔 · 𝑣((𝑡𝑔)−1𝑥)。 一般来说,场类型由任意的𝐺表示𝜌: 𝐺 → 𝐺𝐿(R𝑐)来确定,它解释𝐺在R𝑐中的特征向量的作用。整个特征场的对应作用变为: 𝑡𝑔 ▷ 𝑓 := 𝜌(𝑔)𝑓 (𝑡𝑔)−1𝑥。(47) 值得注意的是,当选择平凡表示𝜌 (𝑔) = 1或定义表示𝜌 (𝑔) = 𝑔时,将恢复标量场和切向量场。其他例子包括𝜌(𝑔) = (𝑔−⊤)⊗𝑟 ⊗ 𝑔⊗𝑠的张量乘积表示,对应于(𝑟,𝑠)阶张量场,或不可约表示,例如当𝐺 = 𝑆𝑂(3)时张量场网络的2𝑙+1维特征。第2.2节中的群卷积对应于循环群𝐺 = 𝐶4(包括90°旋转)的正则表示,它由置换矩阵以循环方式移动场的四个通道组成:
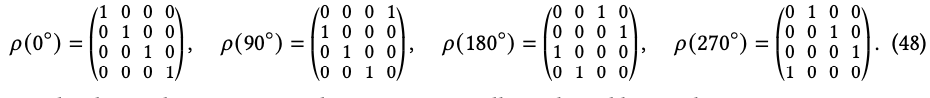
可以证明,群卷积通常可以用正则𝐺-representation来解释。
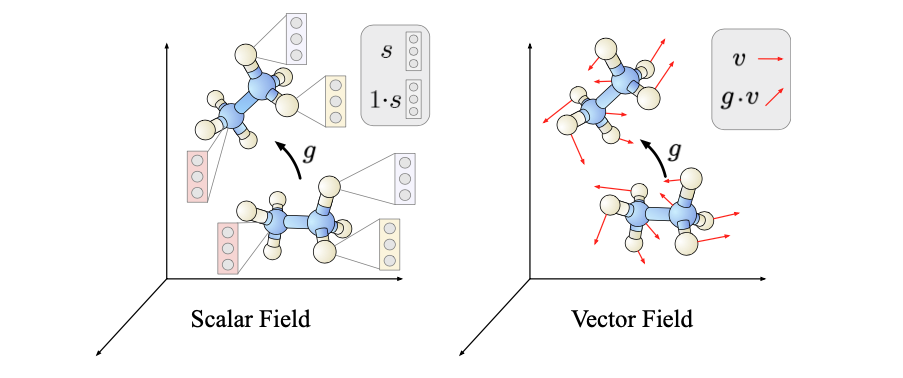
图8. 标量场和矢量场作为特征向量场的简单示例。仿射群通过两种方式对这些场进行作用:(1) 在空间中移动特征(黑色箭头),(2) 通过某个群表示𝜌来改变特征本身。对于平凡表示𝜌(𝑔) = 1,这解释了标量场,而𝜌(𝑔) = 𝑔描述了矢量场。上面的所有特征空间都对应于𝐺-representation的某种选择,例如Wigner-D矩阵𝜌 = 𝐷l用于张量场网络和𝐺 = 𝑆𝑂(3)。可控CNN是由从特征场到特征场的等变映射层构建的,例如从标量场到矢量场或反之亦然。线性等变映射必然是卷积操作,但是具有附加的对称性约束的“可控卷积核”。该图取自Weiler和Cesa [2019b],经过许可修改。
2.8.2 可控卷积。
目前我们只描述了特征空间和它们的群作用,但没有描述它们之间的等变层。特别对于线性层,Weiler等人[2018b]证明了从输入场𝑓in(类型为𝜌in)到输出场𝑓out(类型为𝜌out)的最一般线性等变映射由卷积给出
∫ 𝑑 R 𝐾:R𝑑 →R𝑐out×𝑐in, (50)
这些卷积还需要满足对称约束条件,即
𝐺 -steerability 1 −1 𝑑 𝐾(𝑔𝑥) = |det𝑔|𝜌out(𝑔)𝐾(𝑥)𝜌in(𝑔) ∀𝑔∈𝐺,𝑥∈R . (51)
直观地,卷积操作确保平移等变性,而𝐺-steerability添加了𝐺 -actions下的等变性,从而确保了该操作在指定的场类型𝜌in和𝜌out之间进行映射。注意,标量卷积核将为R𝑑的每个点分配一个标量,然而,由于我们在𝑐in和𝑐out维特征向量的场之间进行映射,卷积核是𝑐out ×𝑐in矩阵值的。5 卷积操作的高效实现已经准备就绪,因此实现等变卷积的主要困难在于对可控核进行参数化。为此,观察到核形成一个向量空间,并且核约束是线性的-可控核因此属于一个向量子空间,并且仅需解出以可学习系数扩展可控核的基础。这样的基础已经针对𝑆𝑂 (3) 不可约表示[Weiler等人2018b],任意𝐺 ≤ 𝑂 (2) 的一般表示[Weiler和Cesa 2019b],以及随后任意紧致群𝐺(即𝐺 ≤𝑂(𝑑))的一般表示[Lang和Weiler 2020;Cesa等人2022b]进行推导。它们在PyTorch和jax的escnn库中实现[Cesa等人2022a]。
为了澄清核约束条件并展示可控卷积神经网络(steerable CNNs)与前几节中的等变模型的关系,我们来看一些具体的例子。
• 最简单的例子是当𝜌in和𝜌out是平凡表示时,也就是核在标量场之间进行映射。此时𝐾:R𝑑→R1×1=R是一个满足𝐾(𝑔𝑥)=𝐾(𝑥)的标量核。对于正交群𝐺≤𝑂(𝑑),例如旋转和反射,体积缩放因子| det𝑔|消失了,并且约束要求核是𝐺-不变的(例如旋转或反射不变)。
• 对于𝑑=2,𝜌in是平凡表示,𝜌out是等式(48)中定义的𝐶4的正则表示,核的形式为𝐾:R2→R4×1。约束条件变为𝐾(𝑔𝑥)=𝜌out(𝑔)𝐾(𝑥),意味着左边的𝐺-旋转核应该与右边的原始核在四个通道上的循环移位后保持一致。这正是第2.2节中核的构造方式,在图5的左侧部分可见。
• 我们修改上一个例子,现在要求𝜌in=𝜌out都由正则的𝐶4表示给出。核𝐾:R2→R4×4应满足𝐾(𝑔𝑥)=𝜌out(𝑔)𝐾(𝑥)𝜌in(𝑔)−1,这意味着空间旋转等效于同时将其行和列进行移位。相应的操作是正则群卷积,其核显示在图5的右侧部分。
• 现在假设𝜌in是平凡表示,𝜌out=𝐷l是𝑆𝑂(3)的不可约表示。相应的核𝐾:R3→R(2l+1)×1需要满足𝐾(𝑔𝑥)=𝐷l(𝑔)𝐾(𝑥),其中核的角部分是球谐函数,径向部分是可学习的。这解释了方程(13)中的那些TP操作,其中𝒉l1 :=𝑓in(𝑥𝑗)是𝑗标量阶数l1=0(平凡)和l2=l3 := l的输入特征。
• 如果𝜌in=𝐷l1和𝜌out=𝐷l3都是𝑆𝑂(3)的不可约表示,我们得到𝐾:R3→R(2l3+1)×(2l1+1)。约束条件𝐾(𝑔𝑥)=𝐷l3(𝑔)𝐾(𝑥)𝐷l1(𝑔)−1等价于vec𝐾(𝑔𝑥)= 𝐷l1 ⊗𝐷l3(𝑔)vec𝐾(𝑥)。通过Clebsch-Gordan分解不可约表示张量积,可以轻松证明这样的可控核与方程(13)中的一般TP操作完全一致;有关详细信息,请参阅[Weiler等人2018b]或[Lang和Weiler 2020]。
• 第2.4.2节中的𝑆𝑂(3)等变球通道网络(SCNs)操作的是函数域在2-球S2上的无限维特征向量。从表示论的角度看,它们只是[Weiler和Cesa 2019b]和[Cesa等人2022b]中描述的商表示。作为标准可控卷积神经网络的扩展,SCNs中使用的可控核本身是通过消息从数据中计算出来的。
使用可控卷积神经网络的优点是什么?
(1)它以一般设置解释了等变卷积,与特定空间、对称群或群表示的选择无关。从而澄清了前述各种方法之间的关系。
(2)前述方法是通过提出特定操作来引入的,随后证明其对特定群作用是等变的。相反地,可控卷积神经网络首先固定群作用,然后推导出它们之间的等变线性映射。例如,张量场网络中的TP操作与可控核解之间存在一一对应关系,但是核约束条件的表述允许证明这些解的完备性。在许多其他情况下,可以证明这些作者只是使用了所有可允许的核的一个子集,从而不必要地限制了网络的表达能力[Weiler等人2021]。 (3)上述方法仅描述了每个模型(或场类型类)的单个场类型。可控卷积神经网络允许构建混合模型,其特征空间可以同时在正则、不可约、商或任何其他场类型的特征向量上操作。
抽象的表示论形式提出了对进一步空间的自然推广。具体而言,Cohen等人[2019]将可操纵CNNs扩展到了齐次空间,包括球形卷积等。Weiler等人[2021]表明,黎曼流形上的无坐标卷积类似地需要𝐺可操纵的核。这个形式实际上是一个规范场论,特别证明了本节中的等变网络不仅在全局变换下等变,而且在更一般的局域规范变换下也等变。
可驾驶核与量子力学中出现的标量、矢量或球张量算符有着有趣的联系。两者都被形式化为所谓的表示算符,并由著名的Wigner Eckart定理[Jeevanjee 2011b;Wigner 1931]描述。Lang和Weiler[2020]证明了这种联系,并展示了它如何解决一般情况下的核约束。
Jenner和Weiler [2022]将可操纵CNNs扩展到了Schwartz分布设置。这尤其涵盖了可操纵的偏微分算子(PDOs),这解释了在物理科学中普遍出现的PDOs如何满足对称性。
2.9 开放研究方向
作者:汉娜·劳伦斯,谢雨晴,塔斯·斯密特 除了前面提到的领域,在本节中我们还重点介绍一些最前沿和令人兴奋的研究方向。由于该领域发展迅速,我们预计未来将丰富上述每个方向,并包括更多的主题。
2.9.1 对称性破缺。
自发对称性破缺对于解释许多自然现象至关重要,例如磁性、超导甚至希格斯机制[Beekman等人,2019;Strocchi,2005],并与神经网络训练[Ziyin和Ueda,2022]相关。在这种情况下,我们有一个高度对称的输入,希望预测一个低对称性的输出。对于等变网络来处理这种行为是可取的,然而,它们在根本上存在限制。
假设我们的等变模型是函数𝑓:𝑋→𝑌。对于输入𝑥,假设它在群𝐺下是对称的。那么对于任意𝑔∈𝐺,𝑓(𝑔𝑥) = 𝑓(𝑥)。这意味着输出也必须在𝐺下是不变的,因此它必须具有相同或更高的对称性。这意味着我们永远无法以等变的方式预测一个单一的低对称性输出。如果我们尝试这样做,模型将仅对所有退化结果求平均,这可能是无用的。
在解决等变模型的对称性破缺问题时有两种观点。
第一种观点是实际上存在一个特定的退化解,我们希望预测这个解。在这种情况下,我们知道根据对称性,我们缺少进行任务所需的信息。事实证明,通过使用损失函数的梯度,我们可以推断出需要什么类型的额外输入来打破对称性[斯密特等人,2021]。
第二种观点是所有较低对称性的输出都是同样有效的。在这种情况下,我们希望同时表示所有输出和/或以相等概率从中进行随机抽样。正确处理这种情况仍然是一个未解决的问题。
2.9.2 等变性与不变性的经验性益处与成本。
已经观察到等变性相对于不变性具有可测量的优势。已经证明,增加特征的阶数(即最大球谐阶数)在𝑆𝐸(3)和𝐸(3)等变模型中会改善性能[Batzner et al. 2022; Musaelian et al. 2023a; Owen et al. 2023; Yu et al. 2023c,b]。
等变性的计算成本主要由张量积(包括分解成不可约表示)支配,其中涉及两个输入与三指数Clebsch-Gordan张量 𝐶(𝑙3,𝑚3) 𝑋(𝑙1,𝑚1)𝑌(𝑙1,𝑚1) = 𝑍(𝑙3,𝑚3) 的收缩。在体素模型中,可以为“传统”卷积滤波器预先计算此收缩(𝑙1,𝑚1)(𝑙2,𝑚2)
以降低计算成本。否则,必须明确计算它,例如“传统”的逐点卷积和特征的直接张量积。
通过算法的权宜之计(例如,在第2.4.2节中提到的eSCN类操作[Passaro and Zitnick 2023])和张量积操作的优化,可以克服这些开销,无论是通过优化的内核、领域特定编译器还是更加定制的硬件。
2.9.3 等变神经架构的通用性。
前面的章节详细讨论了如何定制神经架构,使其只能表示不变或等变函数,不管学到了什么权重。尽管这项工作的根本目标是有利地限制可学函数的族群,使其仅包含地面真实解决方案,但了解在等变函数族中给定架构的表达力有多强也很重要。例如,地面真实解是否仍包含在架构家族可表示的等变函数集合中?显然,这是一个重要的合理性检查。
非正式地说,如果一个等变架构家族是普遍的,那么对于任何连续等变函数和错误阈值 𝜖,通常存在一个足够“大”的网络(例如,在某种意义上有足够多的通道、层或阶数),它可以在某种函数范数下以误差 𝜖 近似表示该函数。令人高兴的是,先前的研究已经证明了许多等变架构是普遍的。简而言之,[Yarotsky 2018]首次证明了基于多项不变和等变的等变网络是普遍的,而Bogatskiy等人[2022]则表明,基于李群的不可约表示的张量积的大多数架构是普遍的。Dym和Maron [2021]还证明了𝑆𝐸(3)-变压器和张量场网络,这是两种流行的用于点云输入的架构,也是普遍的。然而,表征图神经网络的表达能力是一个活跃的研究领域,它们通常不是普遍的。基础性工作[Xu et al. 2018]将消息传递架构的表达能力与Weisfeiler-Lehman图同构测试的等级联系起来,Joshi等人[2023]最近开始将这项工作扩展到几何图网络(即嵌入在3D空间中的图,通常是将每个点连接到其最近邻居之后如何处理点云的方式)。这种对普遍性的分析不足以预测不同等变架构的相对性能,但在选择适合给定科学任务的等变学习方法时,它是一个值得评估的重要标准。
2.9.4 等变性的替代方法:帧平均。
正如前一节所述,目前基于张量的架构,例如第2.4节和第2.9.2节讨论的那些,存在可伸缩性问题。例如,遵循张量场网络[Thomas et al. 2018]模板的点云架构在单次前向传递时需要时间𝑂(𝐿6),其中𝐿是最大球谐指数[Passaro and Zitnick 2023]。最近,帧平均已经成为一种轻量级的替代方法,用于在学习管道中实施等变性。
形式上,移动框架最早由数学家Élie Cartan于1937年首次定义,它是一个平滑、等变的映射 𝜌 : M → 𝐺,其中 M 是一个流形,Lie 群 𝐺 在其上平滑地作用[Cartan 1937]。等变性质保证了 𝜌(𝑔𝑚) = 𝑔𝜌(𝑚) 对于 ∀𝑚 ∈ M 都成立。尽管 Cartan 定义这些对象是为了研究子流形的不变性,但它们为在学习流程中强制等变性提供了一种直观的方法。
形式上,移动框架最早由数学家Élie Cartan于1937年首次定义,它是一个平滑、等变的映射 𝜌 : M → 𝐺,其中 M 是一个流形,Lie 群 𝐺 在其上平滑地作用[Cartan 1937]。等变性质保证了 𝜌(𝑔𝑚) = 𝑔𝜌(𝑚) 对于 ∀𝑚 ∈ M 都成立。尽管 Cartan 定义这些对象是为了研究子流形的不变性,但它们为在学习流程中强制等变性提供了一种直观的方法。
首先,假设我们已经有一个函数 𝑓 : M → Y,其中 Y 是某个目标空间,以及一个移动框架 𝜌。我们可以使用 𝜌 使 𝑓 不变(称为 𝑓 的不变化)如下:
𝑓′(𝑚):=𝑓(𝜌(𝑚)−1𝑚) ∀𝑚∈M。
很容易检查,如果 𝑓′ 在不变性方面是如此的,即
𝑓′(h𝑚) = 𝑓 (𝜌(h𝑚)−1h𝑚) = 𝑓 ((h𝜌(𝑚))−1h𝑚) = 𝑓 (𝜌(𝑚)−1𝑚) = 𝑓′(𝑚)。
非常类似地,我们可以使用 𝜌 使 𝑓 等变,如下所示:
𝑓 ′′(𝑚) := 𝜌(𝑚)𝑓 (𝜌(𝑚)−1𝑚)。
可以再次检查,如果 𝑓 ′′ 在等变性方面是如此的,即
𝑓 ′′(h𝑚) = 𝜌(h𝑚)𝑓 (𝜌(h𝑚)−1h𝑚) = 𝜌(h𝑚)𝑓 (𝜌(𝑚)−1𝑚) = h𝜌(𝑚)𝑓 (𝜌(𝑚)−1𝑚) = h𝑓 ′′(𝑚)。
这里需要注意的是输入和输出的群作用是相同的。要使 𝑓 对 Y 上的不同群作用等变,我们只需要另一个移动框架 𝜌',该框架相对于该群作用是等变的,并可以定义 𝑓 ′′(𝑚) := 𝜌′(𝑚)𝑓 (𝜌(𝑚)−1𝑚)。此外,尽管移动框架最初是为 Lie 群在流形上的作用而定义的,上述直观的推理适用于任何在任何空间 M 上作用的群。
因此,等变机器学习的一个简单方法是使用任意架构学习函数 𝑓,然后使用上述移动框架构造方法使其不变或等变。必须通过移动框架进行反向传播,这需要一定的平滑性,但端到端的框架可以在不需要对群 𝐺 进行任何特殊化处理的情况下产生等变函数,并且允许使用高效的标准架构 𝑓。直观地说,框架方法通过仅依赖于每个轨道上的一个固定点上的行为,将任意函数 𝑓 转化为等变函数。Puny 等人[2021]将这一框架推广到允许在每个轨道上的等变点集上进行平均。具体地说,他们更一般地将框架定义为一个集合值函数,𝐹 : M → 2𝐺 \∅,它是等变的:𝐹(𝑔𝑚) = 𝑔
𝐹(𝑚),其中等号是集合之间的等号。然后可以检查以下“框架平均”函数如果是等变的,那么:
〈𝑓 〉F (𝑥) := 1 ∑︁ 𝑓 (𝑔−1𝑥).
𝑔∈F(𝑥)
我们注意到,当框架映射到输入空间 M 的所有元素的𝐺 ∈ 2𝐺时,框架平均会减少到已知的用于组平均函数的 Reynolds 运算符(将给定函数投影到𝐿2意义下最接近的等变函数,参见例如[Elesedy and Zaidi 2021])。此外,当 F 总是映射到包含一个群元素的集合时,该公式恢复了经典的框架视角。不管选择的 F,值得注意的是,所得到的等变流程能够产生任何等变函数,只要通用架构本身是通用的。
框架和等变架构之间的权衡仍然是一个活跃的研究领域。例如,Pozdnyakov 和 Ceriotti [2023] 提出,框架平均法比选择旋转等变性的单一框架更为优越,原因在于观察到将点云规范化为单一坐标系的方法通常不是平滑的,也就是说,添加或删除一个点,或者稍微改变其位置,可能会极大地改变坐标系的选择。相反,他们建议计算在一个中心点的所有邻居对定义的框架上的加权平均,其中权重被特定选择以确保平滑性。然而,这个过程计算密集。Duval 等人[2023]解决了平均在由主成分分析定义的较小坐标系集合上的计算挑战,在训练过程中每次前向传递都会随机采样一个坐标系,以牺牲了训练时的等变性以换取效率。他们在材料科学任务上展示了有希望的性能和时间权衡,包括在。鉴于这两篇论文已经建立了找到“好”的坐标框架或一组坐标框架的困难,Kaba 等人[2022]提出的一个有前途的方向是使用非常轻量级的等变架构学习坐标框架。最后,一些多样且最近的架构可以解释为建立了局部坐标框架[Passaro and Zitnick 2023; Pozdnyakov and Ceriotti 2023],包括 AlphaFold2 的结构模块[Jumper et al. 2021],并将基于框架的等变性方法应用于局部邻域是一个有希望的方向(因为它对不仅全局而且局部等变性都编码了归纳偏见)。未来,对于那些计算效率至关重要的应用场景,框架可能提供一种有吸引力的替代方案。
有时,物理问题并不完全符合群对称性,但对称性仍然提供了有用的近似(例如,如果真实函数仍然接近于等变函数)。这种所谓的“近似对称性”可以出现出于各种原因,包括边界效应、离散化误差,或者更与问题本身相关的东西,比如部分等变性或破缺对称性的属性。例如,数字分类对小角度旋转是不变的,但将“6”旋转成“9”,所以这个问题并不是真正的旋转不变的。更具科学性的例子是,板的扩散系数的变化可能会破坏热扩散的旋转各向同性[Wang et al. 2022i]。在这种情况下,对甚至近似对称性的归纳偏见仍然可以有利于减少神经网络的搜索空间。
Residual Pathway Priors [Finzi et al. 2021] 首次提出通过将可学习的权重矩阵参数化为等变和不受约束矩阵的和来放宽精确等变性约束,其中损失函数确保了等变性受到偏爱。在视觉、合成动力系统和强化学习任务中,他们证明他们的方法在具有近似对称性的情况下表现优越,但在完全对称或没有对称性的情况下并不显著降低性能。
更近期,Wang 等人[2022i]提出了一种对群卷积的泛化方法(以及可旋转的 CNNs,这里我们省略细节,但类似于 G-CNN 情况),如下所示:
普通群卷积:(𝑓 ∗𝐺 𝜙)(𝑔) = ∑︁ 𝑓 (h)𝜙(𝑔−1h). h∈𝐺
𝐿
放松群卷积:(𝑓 e∗𝐺 𝜙)(𝑔) = ∑︁ 𝑓 (h)𝜙(𝑔,h),其中 𝜙(𝑔,h) := ∑︁𝑤𝑙 (h)𝜙𝑙 (𝑔−1h)。
h∈𝐺 𝑙=1
在上面的公式中,𝑓 和 𝜙 分别是从 𝐺 到 R𝑐𝑖𝑛 和 R𝑐𝑖𝑛 ×𝑐𝑜𝑢𝑡 的函数。直观地说,这样的公式允许卷积滤波器依赖于位置。参数 𝐿 的选择,即滤波器组的数量,影响了学习函数可以偏离完全对称性的程度。为了鼓励对称性,网络被初始化为普通群卷积(它是放松群卷积的特殊情况),损失函数中的一个项抑制了每个 𝑤𝑙 中的变化。他们在合成烟雾柱和实验喷气流数据集上表现出了优越性能,相对于完全等变和通用(完全不对称)架构。请注意,这些权衡在最近的工作中也在理论上得到了合理的解释[Petrache and Trivedi 2023]。
其他工作提出了群卷积的替代放松方法。van der Ouderaa 等人[2022]相反,非常一般地放松了 𝜙 (𝑔−1h),使其成为 𝜙 (𝑔−1h, h),他们使用了一些技巧对其进行了参数化(使用了群的李代数和傅里叶特征)。Romero 和 Lohit [2022]则通过学习群卷积上的非均匀度量来放松群卷积。
前述的流程都是受到数据的启发并在测试时使用的,这些数据只大致符合群对称性。然而,对于具有真正群对称性的任务,目前仍然是一个开放的问题,这些近似等变网络是否会在长期内提供任何优势。例如,点云数据的球形通道网络(在第 2.4 节讨论)在发布时在 Open Catalyst 数据集上达到了最先进的结果,尽管它们没有完全旋转等变性。然而,它们后来被完全等变的网络超越了[Passaro and Zitnick 2023]。尽管如此,对于带有噪声、近似对称性甚至略微错误的对称性的真实世界数据,这些方法在完全对称和无约束架构之间有巧妙的插值优势。