导读
随着人工智能技术的飞速发展,越来越多的领域开始与人工智能技术深度融合,产生了一种新型的技术模式——AI+。AI+是指将人工智能技术与其他领域的技术或应用进行结合,在提高效率、精度和创新能力的同时,也为人工智能技术的发展提供了更多的应用场景和数据支持。
其中,AI+医疗是人工智能技术与医疗领域的深度融合,通过结合人工智能技术,改善医疗诊断、预测和治疗效果等方面,为医疗领域带来了新的变革。
智能导诊:基于大模型的智能导诊系统
大模型已经开始从通用领域向专业领域发展,例如,盘古大模型。

领域大模型的基本思路是在通用大模型基础上利用领域数据进行指令微调。近期Meta AI发布的Llama 2更是将其推向高潮,因为它完全开源,且可商用。
下面介绍几个医疗领域的大模型:
ChatDoctor
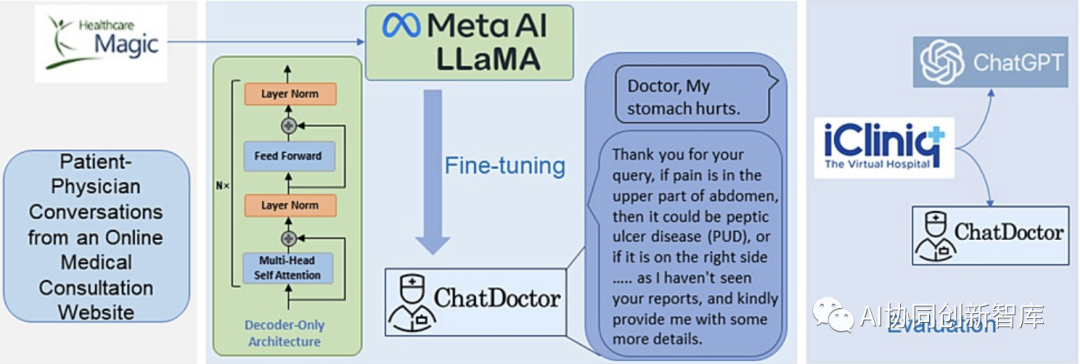
DoctorGLM:基于 ChatGLM-6B的中文问诊模型
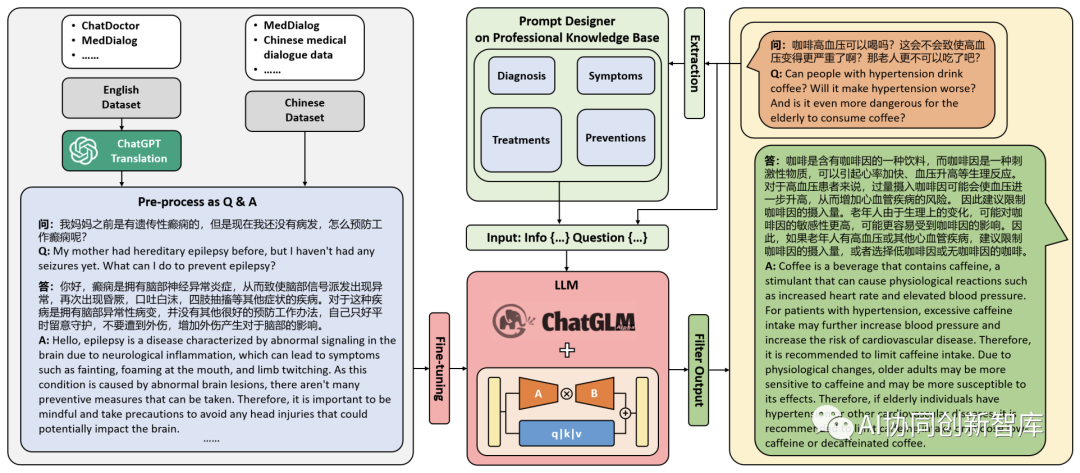
医疗健康大模型NHS-LLM
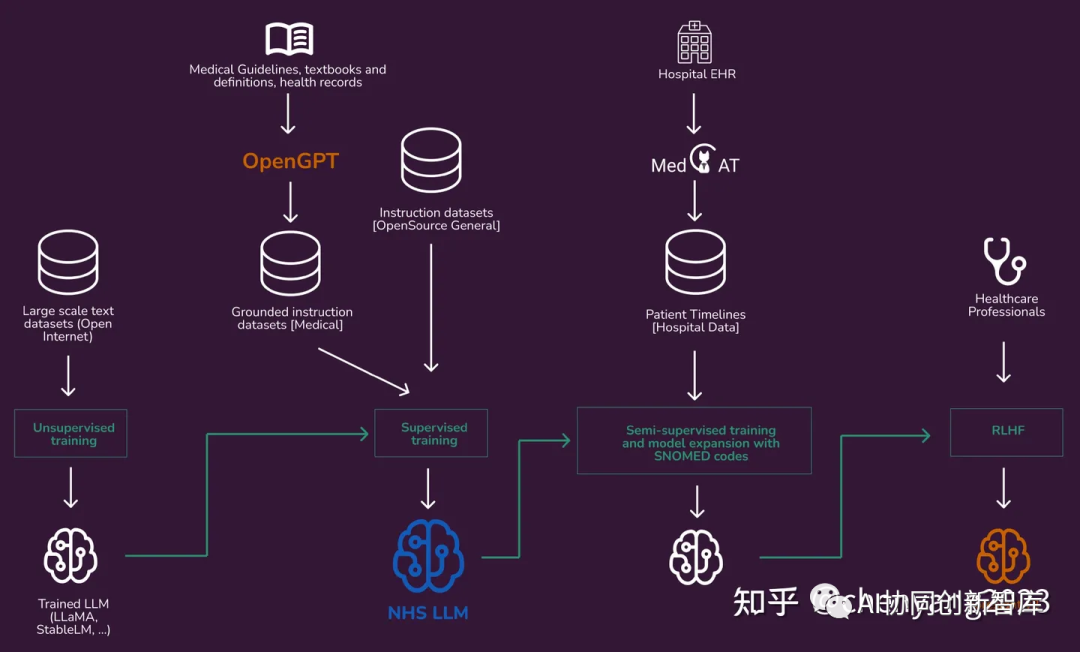
本草[原名:华驼(HuaTuo)]
Demo
地址:https://www.huatuogpt.cn/
ChatMed系列中文医疗大规模语言模型
相关链接
GitHub: github.com/michael-wzhu/ChatMed
AD-AutoGPT:用于阿尔茨海默病信息流行病学的自主GPT
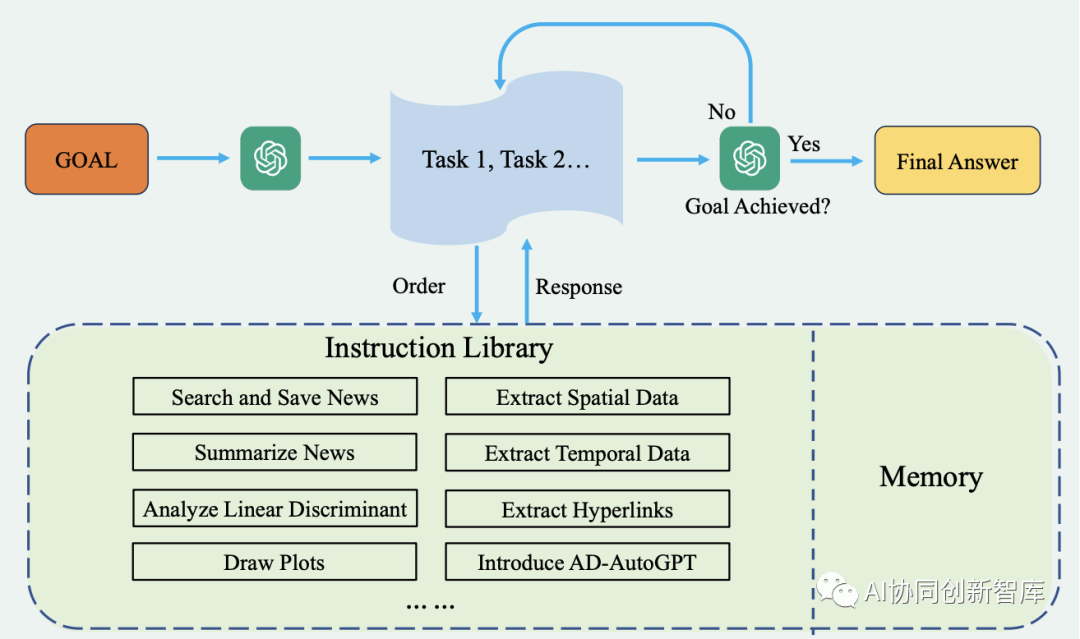
受限于医疗常识的短缺和医院科室复杂性,目前仍然有很多人去了医院不知道该挂什么科室的号,无奈只能通过语言或者肢体描述向导诊台寻求帮助。
有了领域大模型后,可以将其集成到智能聊天机器人或者小程序中,通过患者的语言或者肢体动作分析出可能的病因以及需要去的检查。
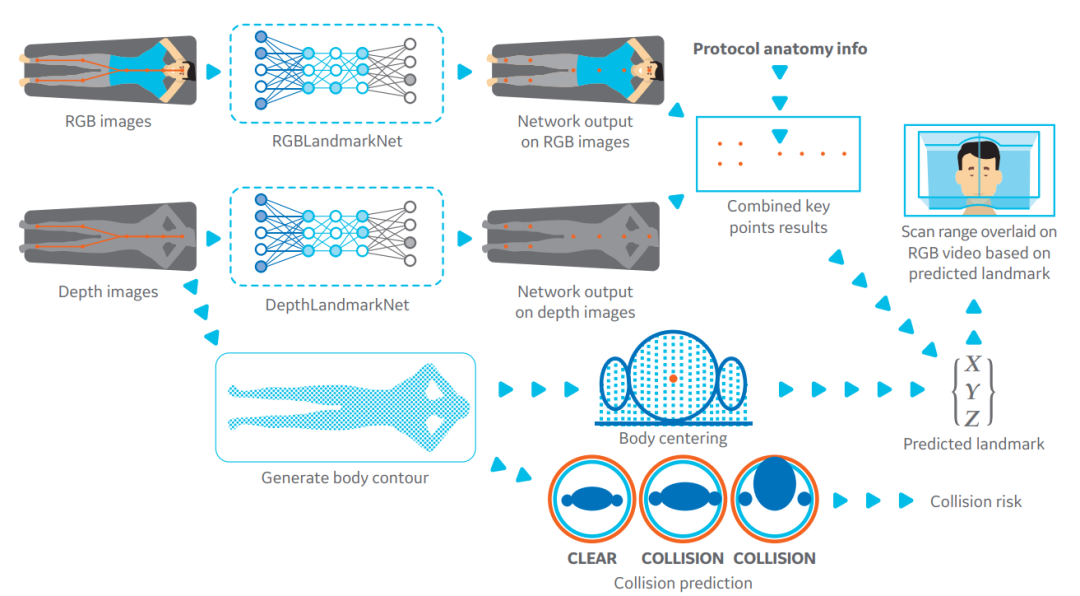
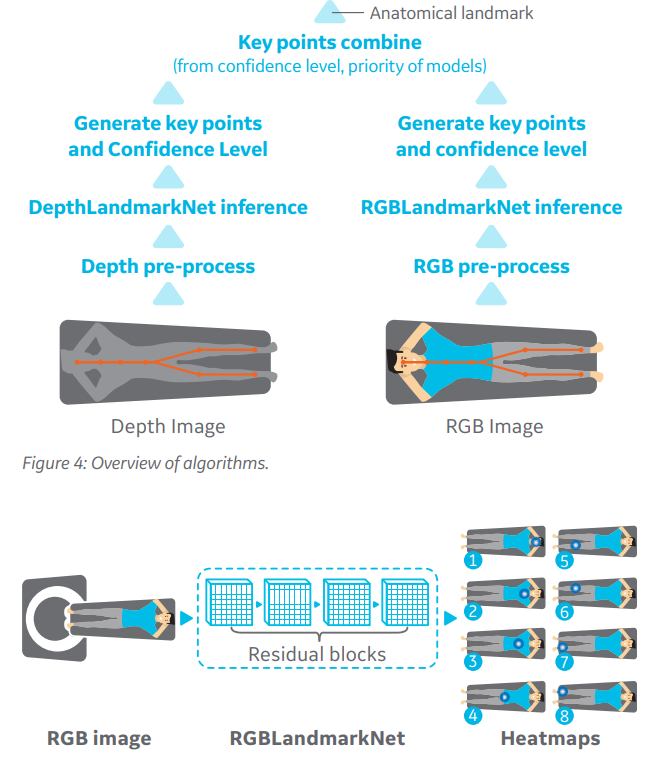
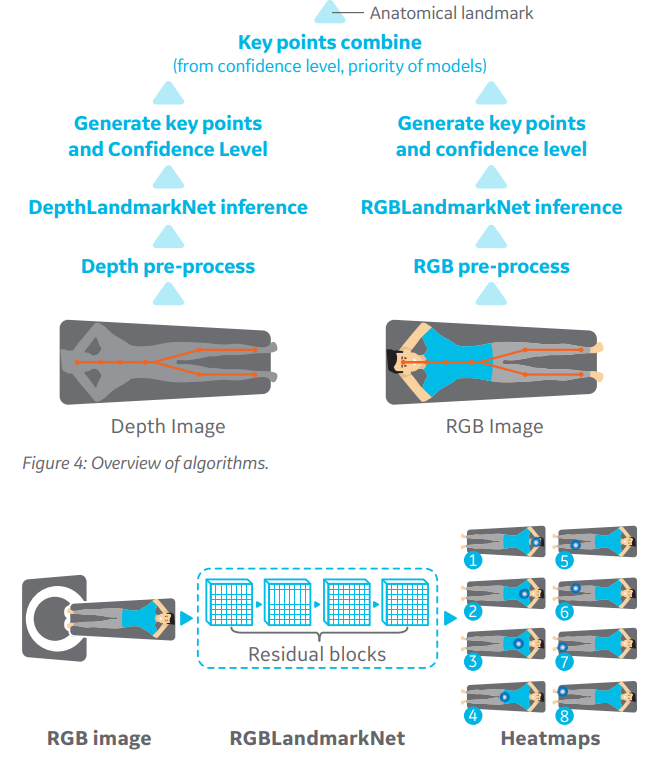
智能扫描:基于深度学习的智能摆位
根据患者的症状,医生需要通过影像设备检查来进一步确认病因,以核磁为例,当患者躺到检查床上,扫描医生要根据检查部位移动床板使其处于磁场中心或者线圈中心。传统的方式是使用激光灯来完成摆位。而摆位是否精确依赖于扫描技师的经验。
基于神经网络的关键点检测算法可以超越人类完成上述任务。
通过在设备上方安装RGB和深度摄像头,在与影像设备进行标定后,即可通过RGB图像获得水平方向的解剖关键点,进行检查部位的定位,通过3D点云数据获得垂直方向的中心点,使检查部位处于图像中心,提高图像质量同时也能够避免磕碰。
下面看一下GE基于AI的自动摆位技术。
智能扫描:基于深度学习的自动定位
无论是CT还是MRI检查,都需要先扫描定位图像,然后在其基础上进行二次定位。
以头部扫描为例。
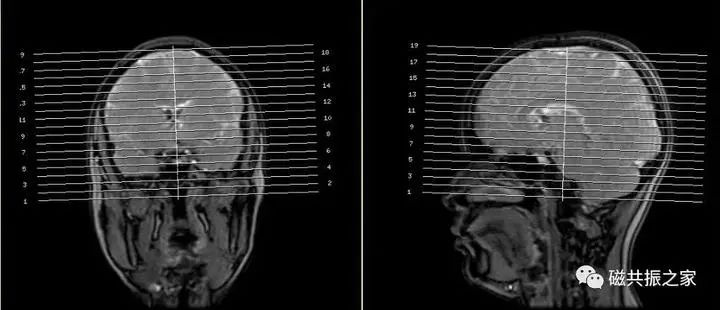
(图片来源于磁共振之家)
传统方式是扫描技师根据经验设置定位框位置和角度。而这个工作可以通过基于深度学习的图像分割算法或者关键点检测算法来完成。
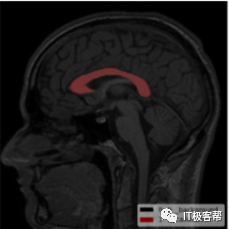
例如,当以矢状位图像定位横轴位时,可以通过分割胼胝体,然后以胼胝体包围盒的中心和角度作为定位框的中心和角度。
扫描脊柱时,也可以通过分割脊柱来实现自动定位功能。
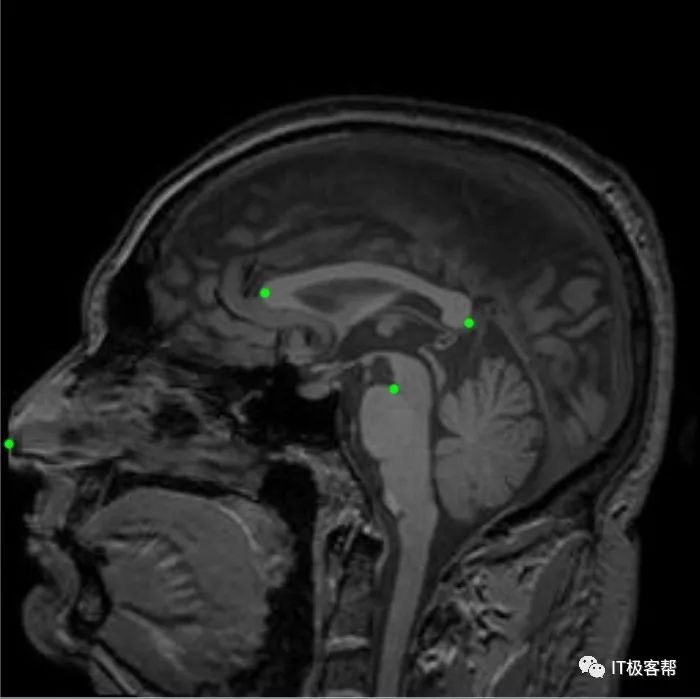
但通过胼胝体能够实现的扫描角度和位置比较单一,为了适应不同疾病的扫描,更好的方法是分割关键点。
智能重建:基于深度学习的图像重建
CT技师既希望患者受到的辐射剂量小,又希望得到的CT图像质量好,MRI技师既希望扫描的时间短,又希望得到的MRI图像质量好。
很可惜,这两者是矛盾的。
传统的图像增强方法很难完美复原真实解剖结构,所以人们开始将目光转向深度学习。
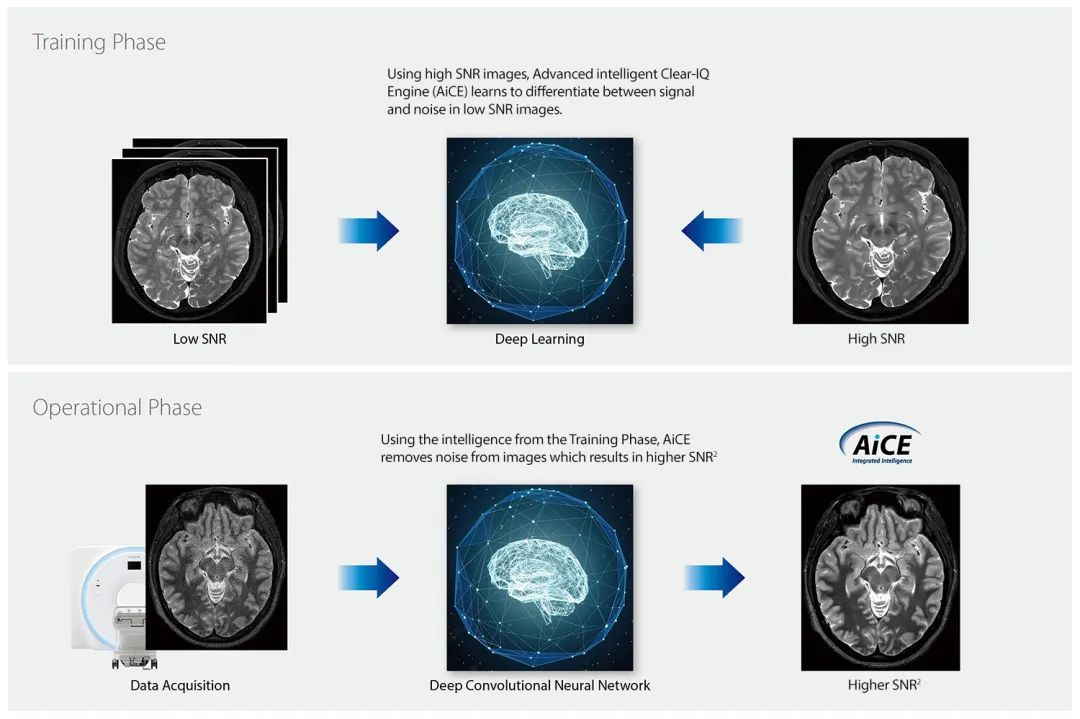
通过人为生成或者分别真实扫描高,低质量的数据,低质量数据作为神经网络的输入,高质量数据作为标签来训练网络,使其找到背后的映射关系。
其中数据可以是空间域的解剖图像,也可以是频率域的原始图像,模型既可以是前馈神经网络,也可以是CNN网络。
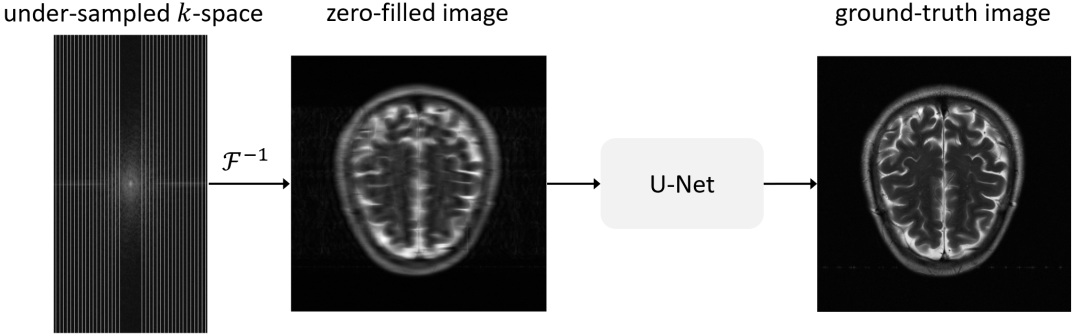
常用的神经网络模型有VarNet和UNet。
UNet的思路是先将降采样的频率域图像经过傅里叶逆变换转换为空间域图像,作为UNet网络的输入,原始未经降采样的k-space图像经过傅里叶逆变换后的空间域图像作为标签,训练的目的就是让两者越接近越好。
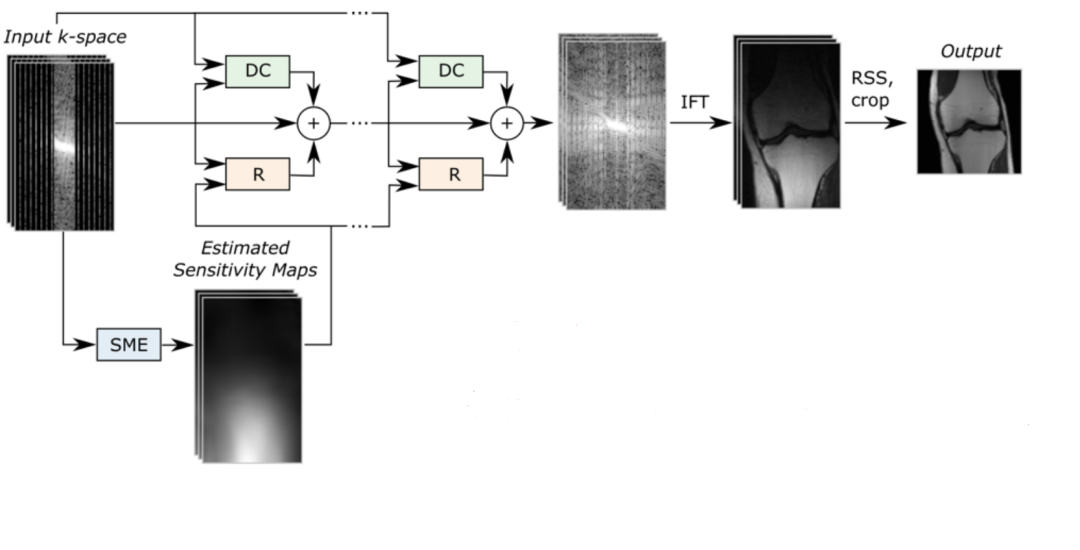
Varnet则是使用频率域作为输入,重建后的空间域图像作为输出。
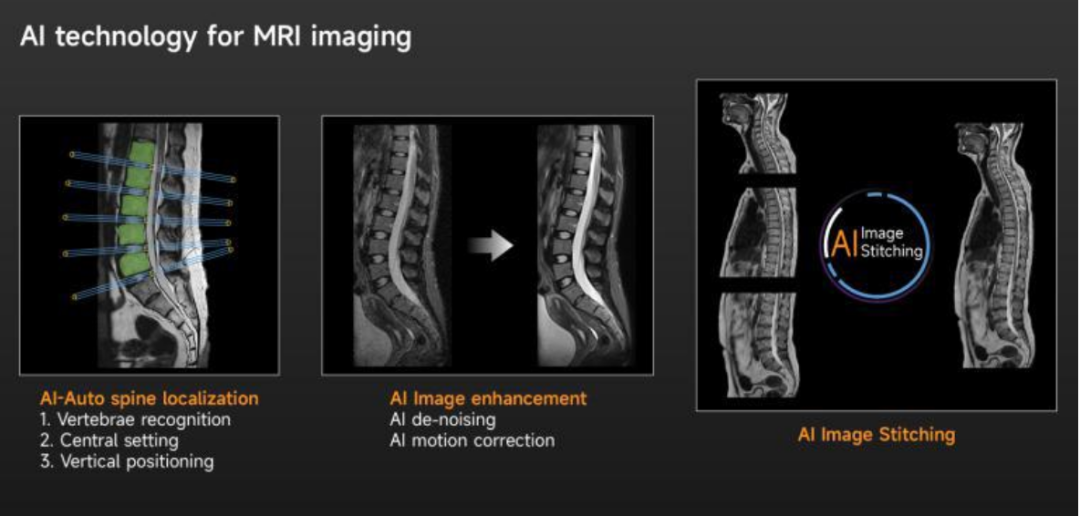
智能后处理:基于深度学习的图像拼接
受限于影像设备的扫描视野FOV,很难只通过一次扫描对整个脊柱进行成像,此时就只能分段扫描,然后借助软件将其拼接在一起。
传统的方法可以通过扫描端进行精确控制,后处理只需要根据重合大小进行简单的拼接即可,但这要求扫描的图像没有形变。
另一种传统方法是扫描端只需要满足有重合即可,后处理通过特征点检测和匹配计算变换矩阵H,最后生成拼接融合图像。如果人体解剖特征点不明显,可以人为添加LandMark。
在基于特征点的图像拼接算法中,特征点的质量以及匹配算法尤为重要,为了提升拼接准确性,可以使用基于神经网络的特征点检测和匹配算法。
其中特征点检测算法为SuperPoint,特征点匹配算法为:LightGlue。
我在[SuperPoint+LightGlue:基于深度学习的特征提取和匹配预训练模型集成到了OpenCV中,并且开源]中已经进行了详细介绍了。
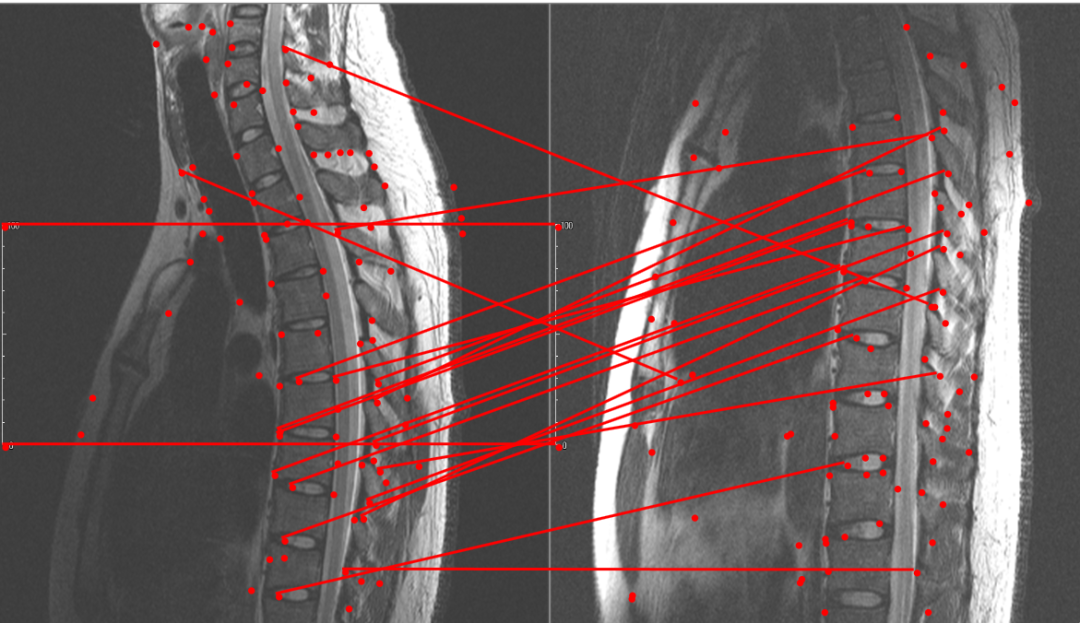
智能后处理:基于深度学习的图像配准
图像拼接有两种模型,一种是仿射变换,也就是变换前后保持平行不变性,另一种是透视变换,也就是变换前后保持直线性。如果这两种模型都无法纠正形变,那就需要图像配准了,而且是非刚性配准,因为对于刚性配准,仿射变换就能实现。
配准的本质其实很简单,对于刚性配准,就是求一个3*3的变换矩阵,该矩阵由旋转矩阵和平移向量组成。
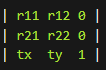
该变换矩阵同时作用于图像所有像素点,对于非刚性配准,单个矩阵无法满足不规则形变,需要置换场来描述图像之间的变形关系。
什么是置换场呢?置换场本质是一个向量场,向量描述了坐标的偏移,对于2D图像,置换场就是两个与图像一样大小的矩阵,两个矩阵每个位置的元素分别对应移动图像在水平和垂直方向的偏移。
知道了配准的数学模型后,接下来就是求变换矩阵或者置换场。其思路跟机器学习训练很像,变换矩阵和置换场就好比机器学习模型参数,然后定义目标函数来衡量配准效果,例如SSIM,其优化问题通常为非凸问题,需要通过优化算法来迭代更新参数。
当然,还可以通过样条插值来拟合图像间的置换场。
讲完了传统的图像配准算法,接下来让我们看一下基于深度学习的配准算法。
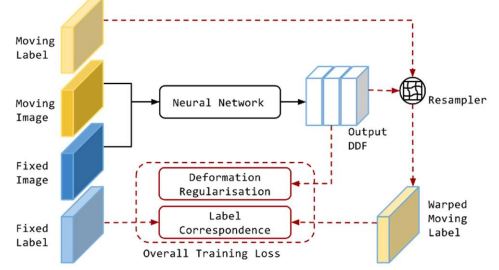
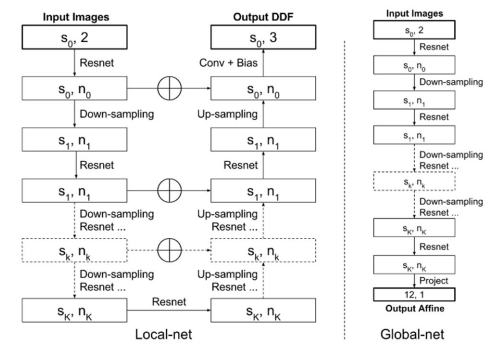
Global-net对应的是刚性配准,网络输出33大小的仿射变换矩阵;Local-net对应的是非刚性配准,网络输出的是widthheight*3的置换场,width和height分别对应图像宽和高,3代表三维向量场,也就是三个轴方向的偏移。
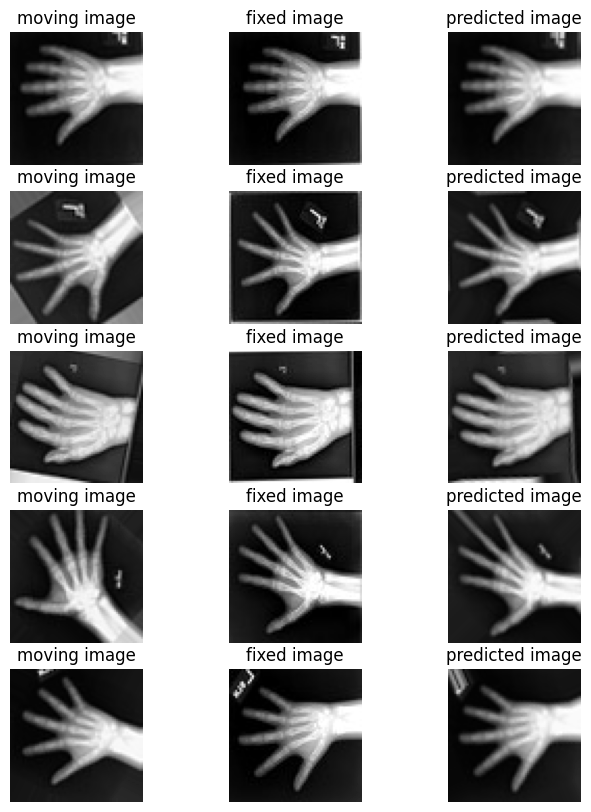
智能后处理:基于深度学习的图像分类
当患者看到检查报告单上的高密度,低回声字样时,难免心里一颤,但即使真的有病变也不一定就是恶性肿瘤,最终结果还要经过切片病理检查。但在这之前医生根据病变的边缘,大小,形状,密度已经可以大概判断出良恶性了。
基于深度学习的图像分类也是如此,将大量代表标签的数据,各种类型的数据喂给模型,模型就能学到背后的模式。
对于病例切片图像,基于深度学习分类算法更为重要,因为切片图像很大,医生需要在显微镜下逐像素观察,十分累人。
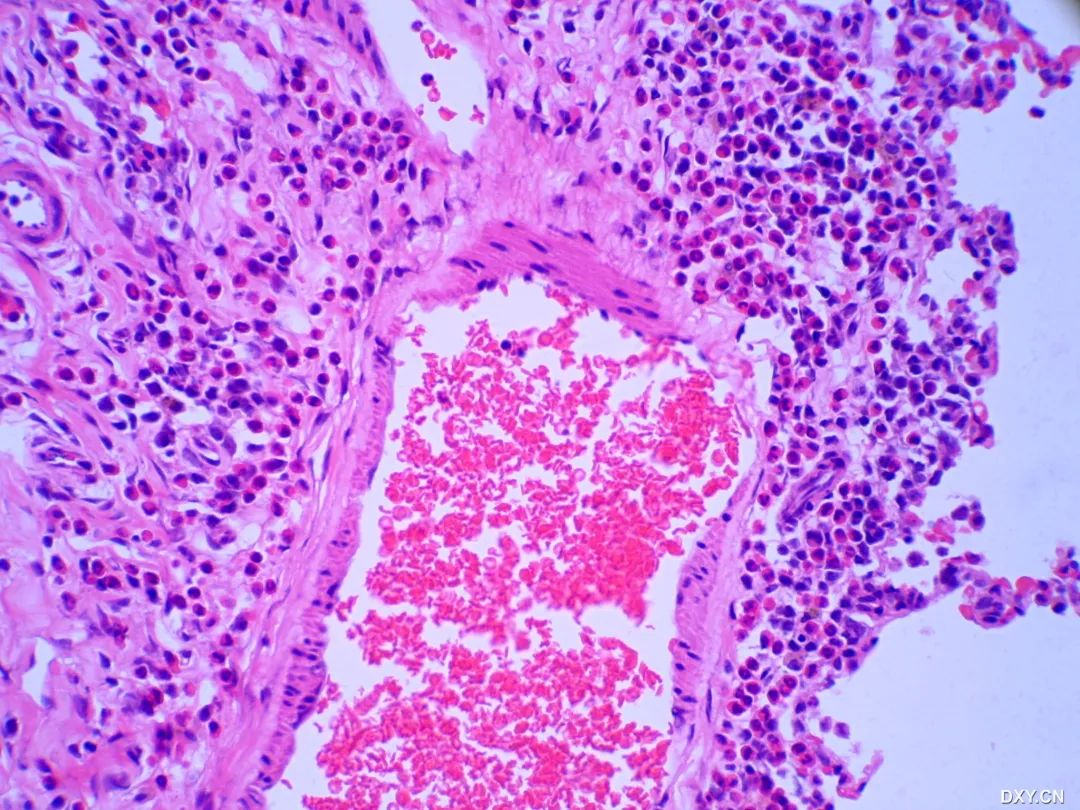
智能后处理:基于深度学习的目标检测
通过图像分类,只能得到定性结果,而定量结果往往更为重要。基于深度学习的图像目标检测算法不仅能得到类别,还能够计算病灶位置,最大径等信息。常见的目标检测应用有肺结节检测,脑出血检测等。
常见的目标检测算法有一阶段的YOLO系列,以及两阶段的R-CNN系列。
但为了得到更多的定量信息,两个方向值得关注。
第一个是带旋转框的目标检测,常见的模型有S2ANet。
https://arxiv.org/pdf/2008.09397.pdf
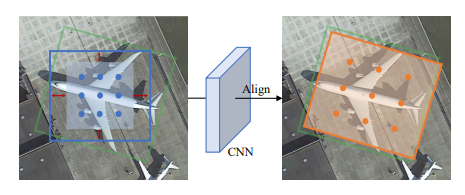
第二个是3D目标检测。常见的模型有DD3D。
https://arxiv.org/pdf/2108.06417v1.pdf

智能后处理:基于深度学习的图像分割
图像分割无疑要比目标检测包含更多的定量信息,常见的应用有血管分割,肝脏分割等。
医疗图像,很多器官都是跨层的,也就是属于3D空间信息,并且形态各异,传统的2D分割网络,例如Unet,VNet对于血管分割效果不是很好,所以一般使用3D分割网络,例如UNet3D或者基于视觉Transformer的分割模型。另外,对于血管分割还要考虑血管的连续性,以及由于血管斑块闭塞等引起的链接异常。
当视觉基础模型Segment Anything出现后,在一定程度上解决了传统模型只能适用于某一特定类型数据的尴尬。
基础模型+特定领域微调是未来的分割的方向。
总结
其实AI不仅能够让影像设备变得更智能,AI可以赋能一切,智能设备,数智医疗,智慧社区,智慧城市等等。
希望阅读本文后,你也能在你的领域发掘出AI的无限潜能。