文章目录
- CPU高速缓存
- 高速缓存
- storeBuffer
- invalidate message queue
- JMM 内存屏障
- volatile
CPU高速缓存
高速缓存
每个cpu核心都有自己的高速缓存,结构如下
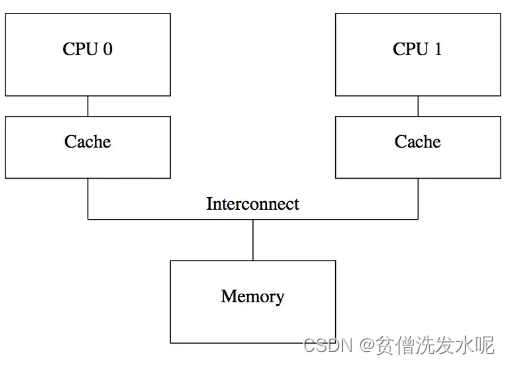
有缓存必有一致性问题,CPU0和CPU1之间的缓存是如何保持一致的。比较常见的一种做法就是 MESI 缓存一致性协议。
MESI 缓存一致性协议
在CPU缓存中最小的存储单元称为缓存行(cache line),一般大小为64B。缓存中每个缓存行都有2个Bit位去存储缓存状态,分别是 M,E,S,I。
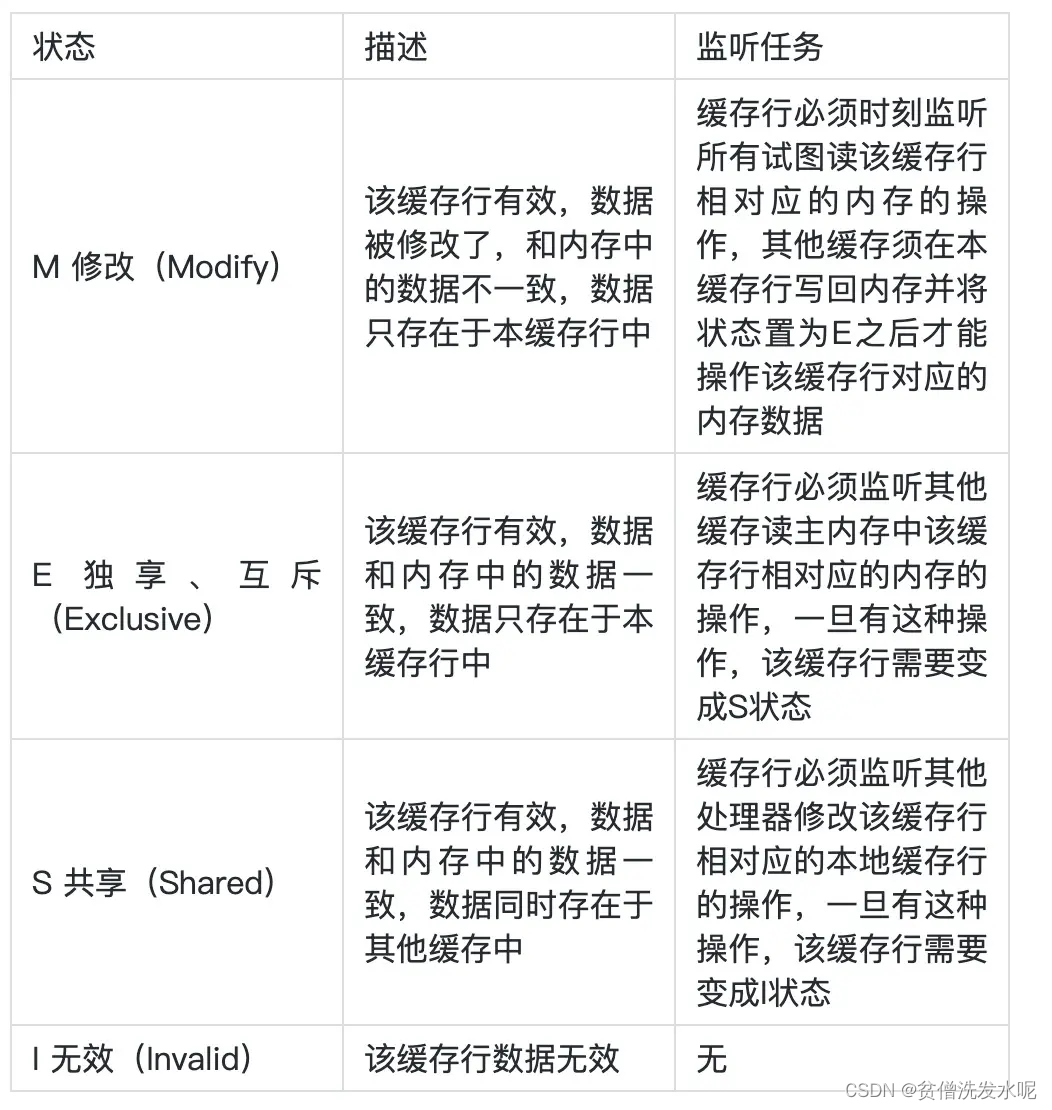
这些标记是如何保证缓存一致性的?
1、写操作时,如果发现写的缓存行是 S,就将该缓存行变成 M,其他缓存行状态变为 I。
2、读操作时,如果发现读的缓存行是 I,就从主存读取新的数据。
3、在任何操作之前(不管是读还是写),如果发现其他缓存行存在 M,就先将其写回主存变成 E。
cpu core是如何感知到其他缓存行的变化的?
每个cpu core都配备了一个总线嗅探器(Bus Snooper),这是一个硬件单元,可以检测总线上的读取和写入操作,以及这些操作所涉及的内存地址。当一个cpu core执行读取或写入操作时,这个操作的数据和内存地址会传输到系统总线上,总线嗅探器会监视总线上的这些数据传输。
storeBuffer
单靠cache对cpu的性能压榨设计者们感觉还不够。考虑这么一种场景:core 1 store数据,此时发送Invalidate message到总线上,其他core收到消息后无效自己的缓存行并回复ack,而core 1需要等到收到其他core的Invalidate message ack,才可以继续往下执行。这意味着core 1存在等待。
身为优秀的设计者,他们无法忍受这种盲等的行为,所以他们引入了 storeBuffer 处于cpu core与cache之间。
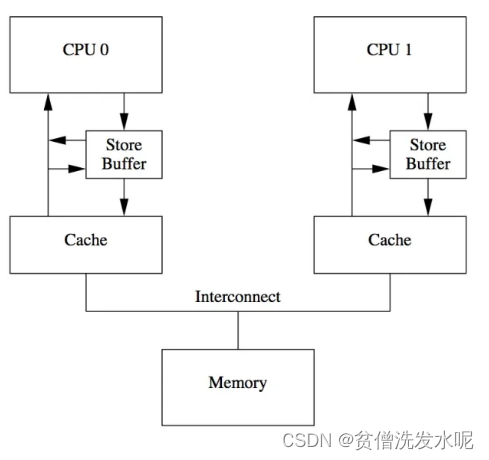
有了store buffer之后core 1如果执行store操作就不用立刻向core2发送invalidate message了,只需要将值添加到store buffer中即可。
注意,此时只是把数据写入store buffer,不会立马更新cache。读数据时如果store buffer存在值,就直接从store buffer获取(store forwarding)。
那么 store buffer 什么时候刷到cache?
当storebuffer满了之后会刷,或者使用 memory barrier(CPU 内存屏障)人为的去控制(比较常见的,在C/C++中,smp_mb()方法将storebuffer中的数据全部刷进cache)。
invalidate message queue
当 storebuffer 刷到 cache 后,同样还是少不了发送 invalidate message 并等待 ack。假如此时其他核心已经很忙了就会导致 invalidate message 处理被延后,导致ack的回复被延后。
设计者为了进一步压榨cpu的性能,引入了 invalidate message queue 。
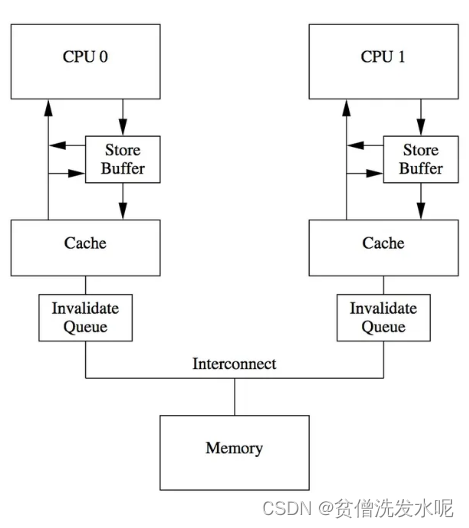
这样当发送 invalidate message 后,只需push到对应 invalidate queue 后即可立马回复ack。
那么 invalidate message 什么时候刷到cache?
同样也可以通过 smp_mb() 添加 memory barrier 将 invalidate queue 刷到cache。
smp_mb()是mfence全屏障(将store buffer和invalidate queue都flush一遍),除此之外还有lfence读屏障(将 invalidate queue flush),sfence写屏障(将 storebuffer flush)。
JMM 内存屏障
众所周知,JMM 内存模型分为工作内存,主内存。这里的工作内存和主内存虽然和上面的cpu缓存和主存很像,但严格意义上来说不是一个概念。JMM 的工作内存和主存是逻辑上的划分,并没有特别指定一个具体的实物,以工作内存为例,可以在内存也可以在cpu缓存(绝大部分情况下在CPU缓存)。
同理,JMM 内存屏障也是一种抽象概念,是 JAVA 为了更好的描绘线程之间的内存关系而衍生出来的一种概念,在不同的处理器/操作系统上会有不同的实现。换句话说,即使没有CPU内存屏障,也不影响 JMM 内存屏障的存在与否。
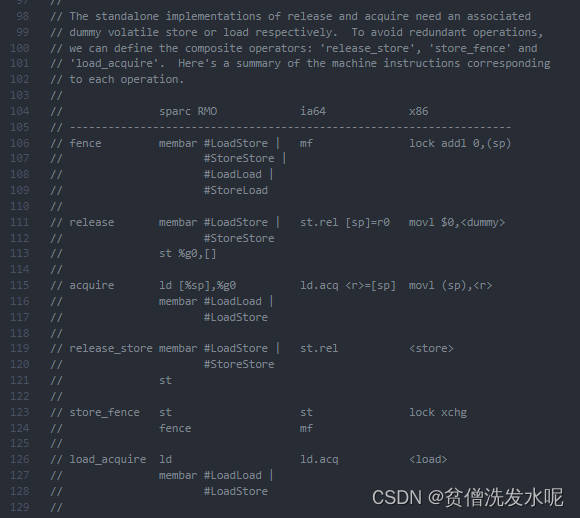
理论上JMM内存屏障长这样:

实际上,不同的cpu会有不同的JMM内存屏障实现(即不同的OrderAcess实现类)。
以x86_linux系统为例,JMM内存屏障长这样:

其实在x86_linux的实现中只有 storeload 才有CPU内存屏障的效果,其他三个屏障是没有的。
因为加入内存屏障的目的是防止一切重排导致的程序乱序。而x86处理器不会对loadload、loadstore和storestore操作做CPU指令重排序,同时这三种情况也不会发生内存重排序,所以就没必要加CPU内存屏障。
重排序的3种情况:
编译器重排、CPU 指令重排、内存重排(内存重排就是因为引入了上面说的 store buffer 和 invalidate queue 导致 memory order 和 program order 不一致,看起来就像是程序乱序执行了一样)
虽然loadload、loadstore和storestore不会发生CPU层面的重排序,但是编译时期还是有可能发生重排序的。所以对于 loadload,loadstore 调用了 acquire() 方法确保屏障前的读取和屏障后的读写不会编译重排(编译屏障)。对于 storestore 调用了release() 方法确保屏障前的读写和屏障后的写入不会编译重排(编译屏障)。
什么是acquire/release?
acquire:任何读操作不会与其之后的任何读/写操作重排序。
release:任何写操作不会与其之前的任何读/写操作重排序
换句话说,acquire 实现了 LoadLoad + LoadStore,release 实现了 LoadStore + StoreStore。
而x86使用的内存模型是Strong Memory Model(强内存模型),每个机器执行指令默认地包含acquire、release语义,这也正是x86在loadload、loadstore和storestore不会发生CPU层面重排序的原因。
我的理解是JMM在实现内存屏障时也同样沿用了acquire/release的命名,在不同的cpu实现上可能会有不同的效果,比如x86只有编译屏障的效果,因为x86天然不会重排除storeload外的三种情况。而其他没有“天然支持”的cpu既有编译屏障又有cpu层屏障的效果。
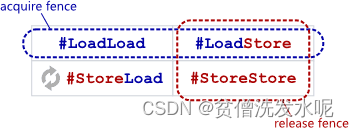
至于 storeLoad,调用了 fence() ,fence实现了全屏障效果(通过 lock 前缀指令实现),所以该屏障开销是最大的。
跟release/acquire类似,fence(通过 lock 前缀指令实现)实现了 LoadStore + StoreStore + LoadLoad + StoreLoad。
lock前缀指令,虽然lock指令不是内存屏障,但是却具有内存屏障的功能:
1、确保lock后面的指令变成一个原子操作。在一些老版本的处理器中,带有lock前缀的指令会锁住总线,使得其他处理器暂时无法通过总线访问共享内存,这会带来昂贵的开销。在后面的处理器,Intel使用缓存锁定(Cache Locking)来保证指令执行的原子性。大大降低lock前缀指令的开销。
2、禁止该指令与之前和之后的读和写指令重排序。
3、会flush store buffer(x86处理器没有 Invalidate Queue,所以不需要flush Invalidate Queue)。
为什么有了MESI还需要JMM内存屏障?
第一:因为CPU的结构不只有cache,还是做了优化的,存在 store buff 和 invalidate message queue,在保证可见性的场景下需要cpu内存屏障flush其内容到cache。第二:编译时期也是可以发生重排序的,所以单靠cpu层面的屏障是不够的,还需要java层面的内存屏障来避免编译时期的重排序。换句话说,JMM内存屏障是应用层的东西,而MESI是硬件层的东西。
volatile
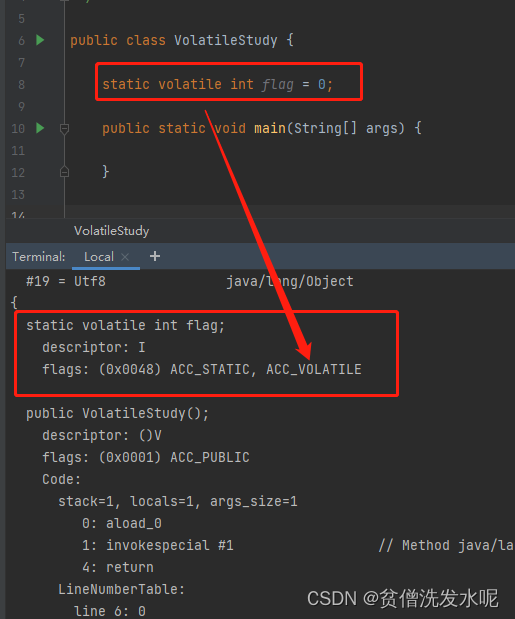
接下来从字节码开始分析volatile。
首先,打印字节码文件,发现volatile变量打上 ACC_VOLATILE 的标记
然后来到JVM处理标签的地方
volatile写:
bytecodeInterpreter.cpp#run#CASE(_putfield)/CASE(_putstatic)
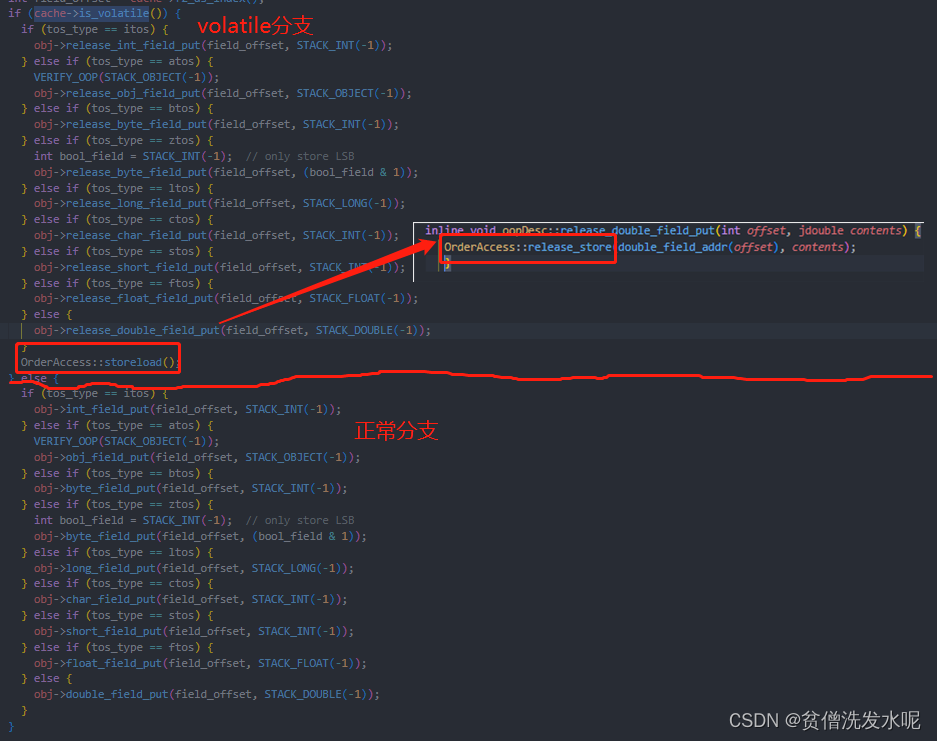
volatile读:
bytecodeInterpreter.cpp#run#CASE(_getfield)/CASE(_getstatic)
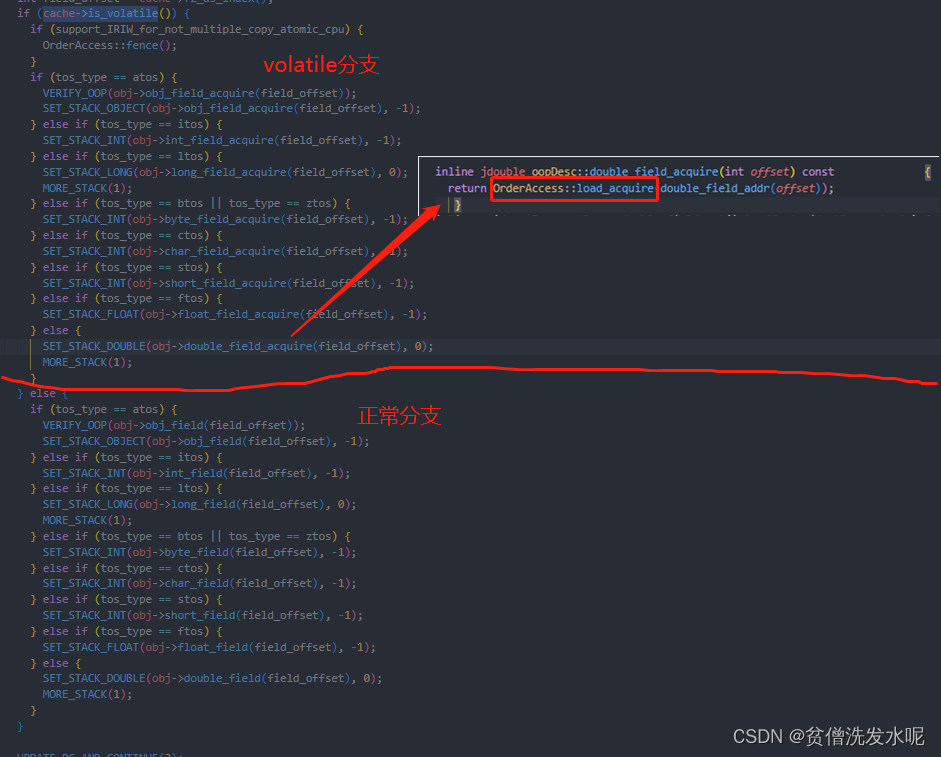
把上面的截图用伪代码总结一下就是
if(属性读指令){
if(属性被volatile修饰){
OrderAccess::load_acquire
}else{
正常读
}
}
else if(属性写指令){
if(属性被volatile修饰){
OrderAccess::release_store
OrderAccess::storeload
}else{
正常写
}
}
什么是load_acquire,什么是release_store?
在JVM源码中的 orderAccess.hpp 可以找到相关的注释
我的理解是 acquire = LoadLoad屏障 + LoadStore屏障
而 load_acquire = load + acquire ,即等价于 load指令 + LoadLoad屏障 + LoadStore屏障。
同理 release = LoadStore + StoreStore屏障
而 release_store = release + store ,即等价于 LoadStore屏障 + StoreStore屏障 + store指令。
所以总的来说从代码的解释上看就是
volatile读之后加 LoadLoad,LoadStore
volatile写之前加 LoadStore,StoreStore,写之后加 StoreLoad
理论上volatile写之后,只有当后续有volatile读才需要插入storeLoad屏障。但是,多线程环境下编译器无法确定volatile写后,其他cpu是否有volatile读操作,所以voliate写后一律加上storeLoad。
这与 Doug Lea 总结的 JSR 133 相关的规范是一致的(原本链接:https://gee.cs.oswego.edu/dl/jmm/cookbook.html)

不过这篇文章的最后,有提到实际上JMM是如何插入内存屏障的,如下

可以发现,volatile 写之前只插入了storestore屏障,并没有loadstore屏障。
同理看下面这张图,引用自《java并发编程的艺术》- 3.4.4 volatile内存语义的实现
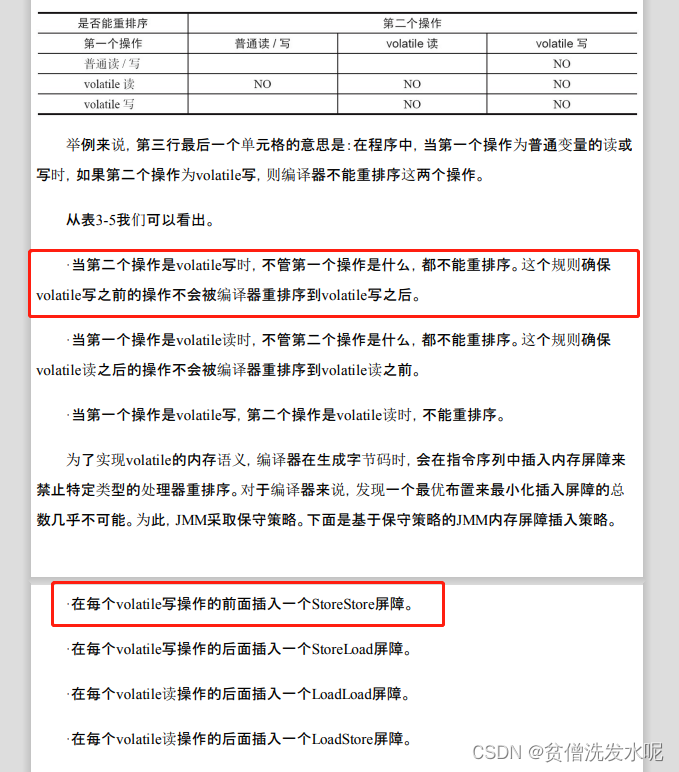
《java并发编程的艺术》跟上面 Doug Lea 表达的观点也是一样的。
在规范上都说volatile写前面的任何操作都禁止与volatile重排,即意味着普通读和volatile写也不能重排,也就是说规范上应该要加loadstore和storestore两个屏障才对。但一提到实际上是如何插入屏障的,又说volatile写前面只插入storestore屏障。
这到底是为什么?volatile写之前到底需不需要loadstore屏障?
说实话我也不知道。我只能就此表达一些我自己的短见。
我觉得这是规范与实际实现上的差异,就是规范上的说法是一个适用于任何场景任何cpu的完美解决方案。但是在实际实现上,比如在x86,开发人员发现即使普通读和volatile写重排了也不会违反happens-before原则,所以就没加loadstore屏障以提高性能。
个人水平有限,文中所有内容都仅代表我个人观点,如有不对,欢迎指正。