文章目录
目录
文章目录
前言
一、mycat原理
二、mycat完成读写分离
2.1搭建MySQL的主从模式
2.2实现读写分离
三、mycat垂直分库
四、水平分表
五、水平拆分表的连表操作
六、全局表
总结
前言
Mycat是==数据库中间件==,所谓中间件,是一类连接软件组件和应用的计算机软件,以便软件各部件之间的通信。
例如 tomcat,web的中间件。而数据库中间件是==连接Java应用程序和数据库中间的软件==
Java与数据库的紧密耦合
高访问量高并发对数据库的压力
读写请求数据不一致
我们现在普遍的Java应用程序都是直接连接了MySQL软件进行读写操作,也就是我们在Java中的配置文件等定义了mysql的数据源,直接连接到了我们的mysql软件,但是当某些情况下我们可能需要用到了多个数据库,这个时候我们可能就需要配多个数据源去连接我们的多个数据库,这个时候我们进行sql操作的时候就会很麻烦,因为Java与数据库有了一个紧密的耦合度,但是如果我们在Java应用程序与mysql中间使用了mycat,我们只需要访问mycat就可以了,至于数据源等问题,mycat会直接帮我们搞定。
再来说一下高访问量高并发,我们都知道==mysql数据库实际上在数据查询上是有一个瓶颈的==,当我们的数据太多的时候,对于互联网上有高并发的请求的时候,这个时候对我们mysql的压力是非常大的,当访问量一大,就可能会出现查不出数据,响应的时间太长等,这个时候我们可能需要有==多个服务器对数据库进行读写分离==,以及对==数据库进行集群==,这个时候我们的sql语句要进行分类,哪个sql语句要访问哪个数据库,这个时候只要交给中间件就可以了。
一、mycat原理
Mycat 的原理中最重要的一个动词是==“拦截”==,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了一些特定的分析:如==分片分析==、==路由分析==、==读写分离分析==、缓存分析等,然后将此 SQL 发 往后端的==真实数据库==,并将返回的结果做适当的处理,最终再返回给用户。

二、mycat完成读写分离
2.1搭建MySQL的主从模式
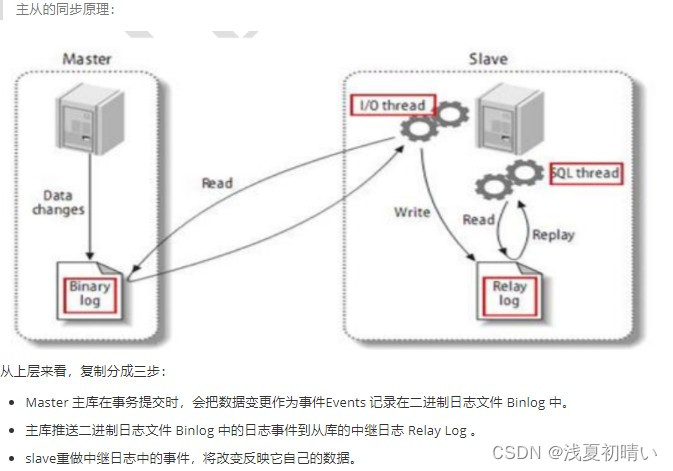
准备条件 两台已经安装了数据库的虚拟机
1. 启动mysql -----systemctl start mysqld
2. 查看mysql是否设置了远程连接. window中的navicat连接mysql.
注意 如果第二台虚拟机是第一台已经安装mysql的克隆机 需要进行以下操作
修改mysql的UUID保证不一样。
第一步 查看uuid命令要登录到mysql里面 show variables like '%server_uuid%';
第二步 找到 find / -name auto.cnf 并删除文件
第三步 重新启动mysql -----systemctl start mysqld搭建主节点
任选一台机子作为主节点
在master 的配置文件(/etc/my.cnf)中,配置如下内容:
#mysql 服务ID,保证整个集群环境中唯一
server-id=1
#mysql binlog 日志的存储路径和文件名
log-bin=/var/lib/mysql/mysqlbin
#错误日志,默认已经开启
#log-err
#mysql的安装目录
#basedir
#mysql的临时目录
#tmpdir
#mysql的数据存放目录
#datadir
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01执行完毕之后,需要重启Mysql: systemctl restart mysqld
查看master状态: show master status;

配置从节点
在 slave 端/etc/my.cnf配置文件中,配置如下内容:
#mysql服务端ID,唯一
server-id=2#指定binlog日志
log-bin=/var/lib/mysql/mysqlbin
执行完毕之后,需要重启Mysql:
systemctl restart mysqld
然后连接到从节点的数据库里执行---指定主从关系。
change master to master_host= '192.168.91.129', master_user='root', master_password='admin', master_log_file='mysqlbin.000001', master_log_pos=154;
指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。开启同步操作
start slave;
查看状态
show slave status\G;
停止同步操作
stop slave;
reset master;
2.2实现读写分离
新开一台虚拟机带数据库 安装上mycat中间件 解压就可以使用
修改配置文件
schema.xml: 定义我们的逻辑库和节点信息
rule.xml: 定义分表的规则
server.xml 定义mycat账户和密码
schema.xml
/*
**这里面,有两个参数需要注意,balance和 switchType。**其中,==**balance指的负载均衡类型,目前的取值有4种**==:
1. **balance="0",** 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
2. **balance="1",**全部的readHost与stand by writeHost参与select语句的负载均衡,
* 简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
3. **balance="2",**所有读操作都随机的在writeHost、readhost上分发。
4. **balance="3",**所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力
*/
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema:定义逻辑库的标签
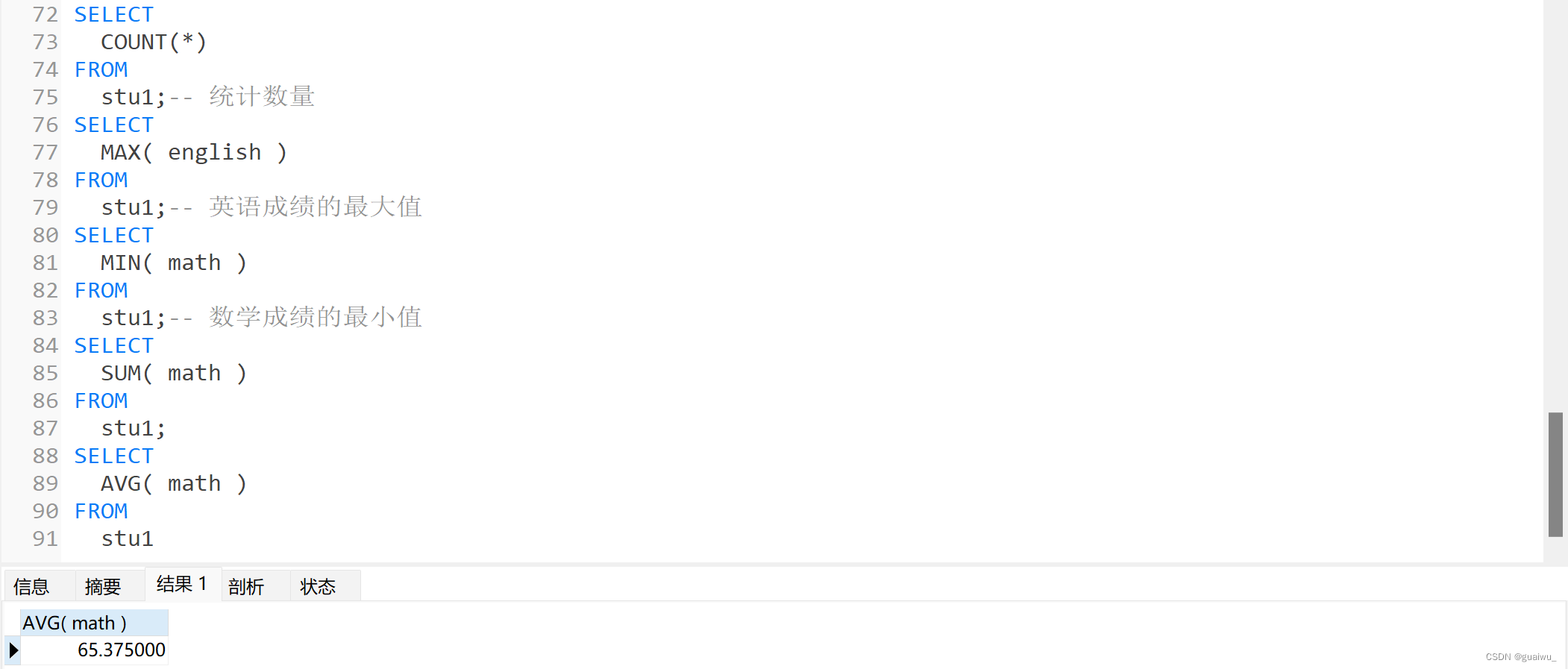
name: 逻辑库的名称,
checkSQLschema: 是否检查sql表结构
sqlMaxLimit: sql最大的显示条数 根据业务以及服务器配置。
dataNode: 数据节点的名称。
-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<!-- dataNode: 定义数据节点的。
name: 数据节点的名称要和上面schema标签中的dataNode属性值一致.
dataHost: 数据主机名
database: 真实数据库名
-->
<dataNode name="dn1" dataHost="host1" database="qy158" />
<!-- dataHost:定义数据主机
name:主机名称保证和上面dataNode标签中的datHost属性值相同
-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.158:3306" user="root"
password="123456">
<readHost host="slave1" url="192.168.223.159:3306" user="root" password="123456"></readHost>
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>修改server.xml 定义逻辑账户和密码
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!-- user定义逻辑账户的标签
name:表示逻辑账户名
-->
<user name="abc">
<!-- 逻辑密码 -->
<property name="password">123456</property>
<!-- 关联的逻辑库schema中的名称对应 -->
<property name="schemas">TESTDB</property>
</user>
</mycat:server>启动mycat 进入到mycat的解压目录下 在它的bin目录下./mycat console
三、mycat垂直分库
一个数据库由==很多表的构成==,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类, 分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面,
分库的原则:
一个问题:在两台主机上的两个数据库中的表,能否关联查询?
不能
分库的原则:有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
先关闭主从
stop slave; 关闭主从关系
修改mycat配置文件--schema.xml文件 主要就是说明那个表放那个库
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema:定义逻辑库的标签
name: 逻辑库的名称,
checkSQLschema: 是否检查sql表结构
sqlMaxLimit: sql最大的显示条数 根据业务以及服务器配置。
dataNode: 数据节点的名称。
-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<!-- customer表 放入dn2-->
<table name="customer" dataNode="dn2"></table>
</schema>
<!-- dataNode: 定义数据节点的。
name: 数据节点的名称要和上面schema标签中的dataNode属性值一致.
dataHost: 数据主机名
database: 真实数据库名
-->
<dataNode name="dn1" dataHost="host1" database="mydb01" />
<dataNode name="dn2" dataHost="host2" database="mydb02" />
<!-- dataHost:定义数据主机
name:主机名称保证和上面dataNode标签中的datHost属性值相同
-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.158:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.159:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>分别再DN1节点和DN2节点创建不同的库
dn1=====>mydb01
dn2=====>mydb02通过mycat完成表的创建
mysql -uabc -P 8066 -h 192.168.223.160 -p123456
-u: mycat逻辑账户
-P: mycat的端口号
-h: mycat服务端的ip
-p: mycat的逻辑密码
#客户表 rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表 rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表 rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);四、水平分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照==某个字段的某种规则==来分散到多个库之中,每个==表中包含一部分数据==。简单来说,我们可以将数据的水平切分理解为是==按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中==
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
按照一列进行拆分。
按照id---- 查询订单时---查询最近的订单数据。---之前的订单很少有人访问
按照订单的日期---双11 双12 ---这种日期的数据存入一张表---该表的记录会非常多。
客户id---->比较均匀的分到相应的表中,而且访问也比较均匀。
修改schema.xml文件 主要就是定义一个规则
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema:定义逻辑库的标签
name: 逻辑库的名称,
checkSQLschema: 是否检查sql表结构
sqlMaxLimit: sql最大的显示条数 根据业务以及服务器配置。
dataNode: 数据节点的名称。
-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<!-- customer表 放入dn2-->
<table name="customer" dataNode="dn2"></table>
<!-- rule:规则:表示orders表中的记录按照该规则分配到dn1和dn2节点上-->
<table name="orders" dataNode="dn1,dn2" rule="mod_rule"></table>
</schema>
<!-- dataNode: 定义数据节点的。
name: 数据节点的名称要和上面schema标签中的dataNode属性值一致.
dataHost: 数据主机名
database: 真实数据库名
-->
<dataNode name="dn1" dataHost="host1" database="mydb01" />
<dataNode name="dn2" dataHost="host2" database="mydb02" />
<!-- dataHost:定义数据主机
name:主机名称保证和上面dataNode标签中的datHost属性值相同
-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.158:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.159:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>修改rule.xml
<tableRule name="mod_rule"> <rule> 指定字段 <columns>customer_id</columns> 分配的算法规则 <algorithm>mod-long</algorithm> </rule> </tableRule>
通过mycat往orders表添加数据。就实现了水平分表
注意分表插入数据时,必须提高列的列表。因为你如果不提供人家无法知道对应那一列的值
五、水平拆分表的连表操作
join:联表查询。
思考: 如果订单详情表和订单表进行联表查询,由于订单表中的记录被拆分到两个库中了,而我们的订单详情表在一个库中存在,那么如果真的要联表查询的化,订单详情只会关联当前库中的订单表。
原则:
使用ER表解决上面的字表关联查询的问题,其将==子表的存储位置依赖于主表==,并且物理上紧邻存放,因此彻底解决了JION 的效率和性能问 题,根据这一思路,提出了基于E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在==同一个数据分片==上。
修改schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema:定义逻辑库的标签
name: 逻辑库的名称,
checkSQLschema: 是否检查sql表结构
sqlMaxLimit: sql最大的显示条数 根据业务以及服务器配置。
dataNode: 数据节点的名称。
-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<!-- customer表 放入dn2-->
<table name="customer" dataNode="dn2"></table>
<!-- rule:规则:表示orders表中的记录按照该规则分配到dn1和dn2节点上-->
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<!-- childTable:orders的子表
name:子表的名称
primaryKey: 子表的主键
joinKey: 子表中的外键列
parentKey: 关联的父表的主键
-->
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id"/>
</table>
</schema>
<!-- dataNode: 定义数据节点的。
name: 数据节点的名称要和上面schema标签中的dataNode属性值一致.
dataHost: 数据主机名
database: 真实数据库名
-->
<dataNode name="dn1" dataHost="host1" database="mydb01" />
<dataNode name="dn2" dataHost="host2" database="mydb02" />
<!-- dataHost:定义数据主机
name:主机名称保证和上面dataNode标签中的datHost属性值相同
-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.158:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.159:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>在159服务器创建订单详情表
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);通过mycat添加订单详情表的记录
INSERT INTO orders_detail(id,detail,order_id) values(7,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(8,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(9,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(10,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(11,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(12,'detail1',6);
六、全局表
dict---->状态 比如支付状态 性别 0 1
订单数据字典表.---存放订单得状态---->支付 未支付 取消 待发货 已发货 已确认。。。。
由于订单数据字典表 再每个节点上都需要。所以我们把数据字典表定义为全局表。
什么样得表适合做全局表.
变动不频繁
数据量总体变化不大
数据规模不大,很少有超过数十万条记录.
鉴于此,Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
全局表的插入、更新操作会实时在==所有节点上执行==,保持各个分片的数据一致性
全局表的查询操作,只从一个节点获取
全局表可以跟任何一个表进行 JOIN 操作将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN 的难题。通过全局表+基于 E-R 关系的分片策略,Mycat 可以满足 80%以上的企业应用开发
修改schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema:定义逻辑库的标签
name: 逻辑库的名称,
checkSQLschema: 是否检查sql表结构
sqlMaxLimit: sql最大的显示条数 根据业务以及服务器配置。
dataNode: 数据节点的名称。
-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<!-- customer表 放入dn2-->
<table name="customer" dataNode="dn2"></table>
<!-- rule:规则:表示orders表中的记录按照该规则分配到dn1和dn2节点上-->
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<!-- childTable:orders的子表
name:子表的名称
primaryKey: 子表的主键
joinKey: 子表中的外键列
parentKey: 关联的父表的主键
-->
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id"/>
</table>
<!-- type:global表示全局表的意思-->
<table name="dict_order_type" dataNode="dn1,dn2" type="global"></table>
</schema>
<!-- dataNode: 定义数据节点的。
name: 数据节点的名称要和上面schema标签中的dataNode属性值一致.
dataHost: 数据主机名
database: 真实数据库名
-->
<dataNode name="dn1" dataHost="host1" database="mydb01" />
<dataNode name="dn2" dataHost="host2" database="mydb02" />
<!-- dataHost:定义数据主机
name:主机名称保证和上面dataNode标签中的datHost属性值相同
-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.158:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 主从之间的维护靠心跳 -->
<heartbeat>select user()</heartbeat>
<!-- 定义主节点的标签 -->
<writeHost host="hostM1" url="192.168.223.159:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>通过mycat创建全局表
注意 这个时候如果想要自动实现表名小写
实现表名小写
第一步 vi /etc/my.cnf
在里面添加
#改变数据库大小写敏感
lower_case_table_names=1
第二步 重启服务应用改变
systemctl restart mysqld
第三步
把其他带mysql的虚拟机都改变一下 测试好使测试 通过mycat的全局表里面的字段 查询确实不区分大小写
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);INSERT INTO dict_order_type(id,order_type) VALUES(101,'Pay');
INSERT INTO dict_order_type(id,order_type) VALUES(102,'NotPay');全局表里面都会有这两条数据







![C. The Third Problem(MEX,思维,组合数)[Codeforces Round #804 (Div. 2)]](https://img-blog.csdnimg.cn/288fa3c217684ccaa6e1c3a830f3fa79.png)



