0. 简介
最近作者希望系统性的去学习一下CUDA加速的相关知识,正好看到深蓝学院有这一门课程。所以这里作者以此课程来作为主线来进行记录分享,方便能给CUDA网络加速学习的萌新们去提供一定的帮助。
1. CUDA中的Stream和Event
1.1 CUDA stream
CUDA stream是GPU上task 的执行队列,所有CUDA操作(kernel,内存拷贝等)都是在stream上执行的。
一般来说,CUDA stream有两种形式,隐式流,又叫默认流,NULL流;所有的CUDA操作默认运行在隐式流里。隐式流里的GPU task和CPU端计算是同步的。例如𝑛=1这行代码,必须等上面三行都执行完,才会执行它。
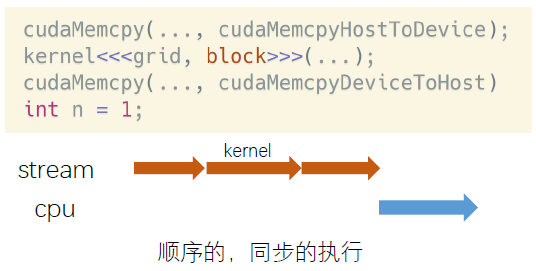
另一个是显式流,指的是显式申请的流。显式流里的GPU task和CPU端计算是异步的。不同显式流内的GPU task执行也是异步的。

具体存在有以下几个函数
- 定义
cudaStream_tstream;
- 创建
cudaStreamCreate(&stream);
- 数据传输
cudaMemcpyAsync(dst, src, size, type, stream)
- kernel在流中执行
kernel<<<grid, block, sharedMemSize, stream>>>(argument list);
- 同步和查询
cudaError_tcudaStreamSynchronize(cudaStream_tstream)
cudaError_tcudaStreamQuery(cudaStream_tstream);
- 销毁
cudaError_tcudaStreamDestroy(cudaStream_tstream);
具体的示例代码如下

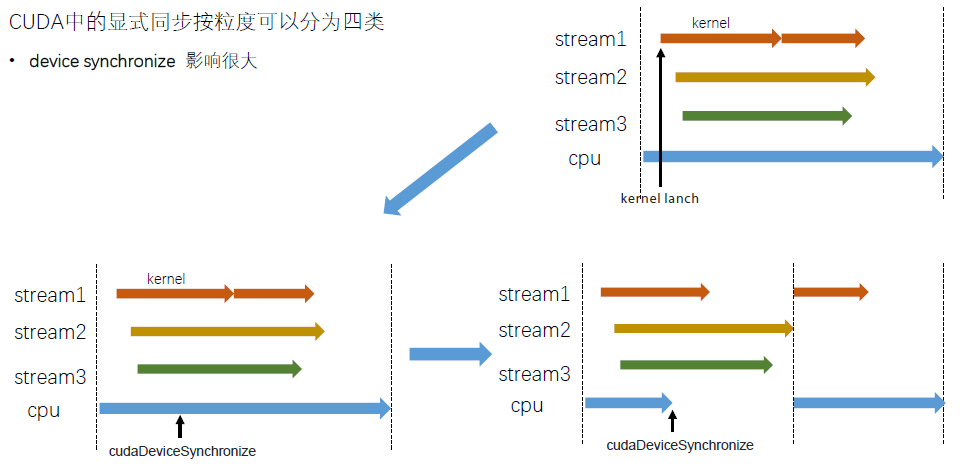
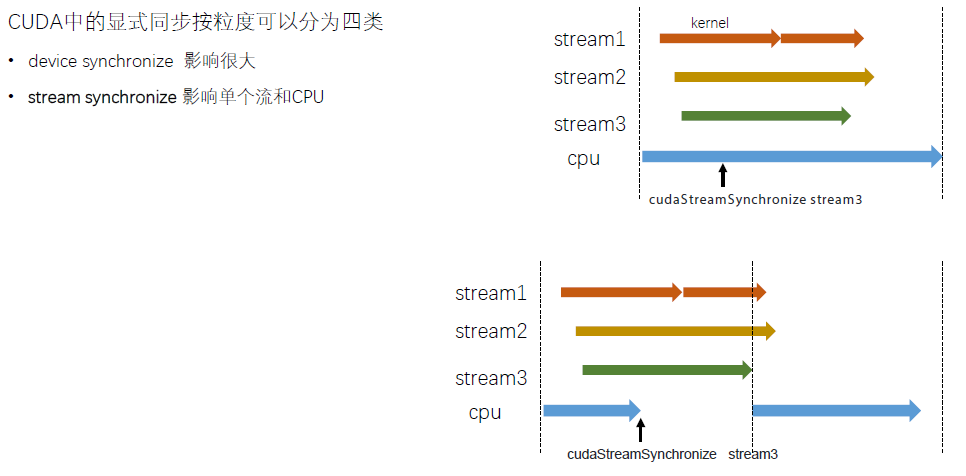
显式流里的GPU task与CPU端task 的执行是异步的,使用stream一定要注意同步,例如cudaStreamSynchronize() 是同步一个流;cudaDeviceSynchronize() 同步该设备上的所有流;而cudaStreamQuery() 则是查询一个流任务是否完成。与隐式的对比如下,值得注意的是H2D 和D2H 没有重叠的原因是它们已经在不同stream上了。
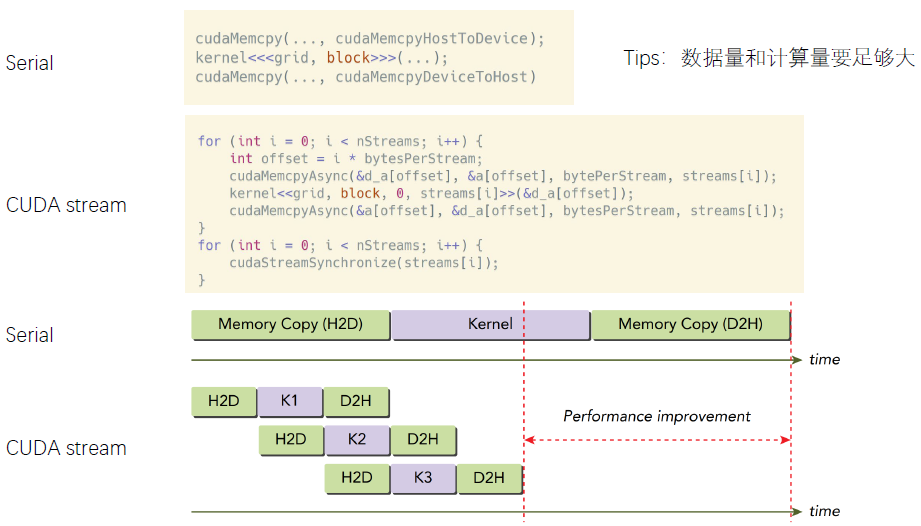
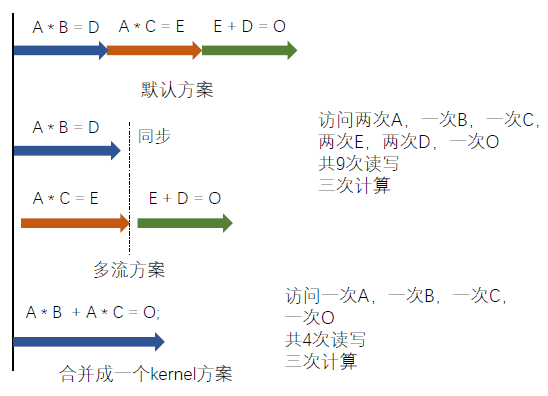
多流可以实现数据传输与kernel计算的并行,因为一个kernel往往用不了整个GPU的算力。多流可以让多个kernel同时计算,充分利用GPU算力。当然不是流越多越好。GPU内可同时并行执行的流数量是有限的。
真正意义上式将kernel合并,将小任务合并成大任务,这是更有效的行为。因为GPU一般处理简单可并行计算,大部分kernel都是访存密集型,这是GPU不擅长的,所以将小任务合并成大任务。
1.2 CUDA Event
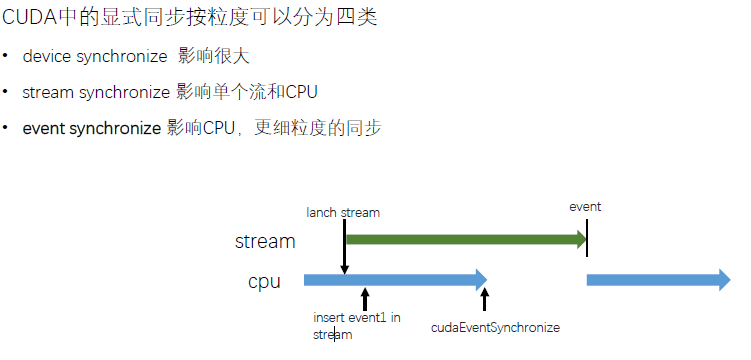
CUDA Event,在stream中插入一个事件,类似于打一个标记位,用来记录stream是否执行到当前位置。Event有两个状态,已被执行和未被执行。
- 定义
cudaEvent_t event
- 创建
cudaError_t cudaEventCreate(cudaEvent_t* event);
- 插入流中
cudaError_t cudaEventRecord(cudaEvent_tevent, cudaStream_tstream = 0);
- 销毁
cudaError_t cudaEventDestroy(cudaEvent_tevent);
- 同步和查询
cudaError_t cudaEventSynchronize(cudaEvent_tevent);
cudaError_t cudaEventQuery(cudaEvent_tevent);
- 进阶同步函数
cudaError_t cudaStreamWaitEvent(cudaStream_tstream, cudaEvent_tevent);
下面是相应的适配


2. CUDA常用的例子
cuda中threadIdx、blockIdx、blockDim和gridDim的使用,这里可以看一下上一讲的示例
-
threadIdx是一个uint3类型,表示一个线程的索引。调用方法:(a.x, a.y, a.z)
-
blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
-
blockDim是一个dim3类型,表示线程块的大小。
-
gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
2.1 一维线程的使用
__global__ void add_kernel(double *a, double *b, double *c) {
//block id
int tid = blockIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
err1 = cudaMalloc((void**)&dev_a, N * sizeof(double));
err2 = cudaMalloc((void**)&dev_b, N * sizeof(double));
err3 = cudaMalloc((void**)&dev_c, N * sizeof(double));
//表示 N 个block, 每个block分配 1个 thread
add_kernel << <N, 1 >> > (dev_a, dev_b, dev_c);在GPU上相加操作
用完设备指针要释放
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
2.2 二维block的使用
__global__ void kernel(unsigned char *ptr) {
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
//...
}
unsigned char *dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grid(DIM1, DIM2); 实际上是DIM1*DIM2*1的三维线程格
//三维grid, 1个thread
kernel << <grid, 1 >> > (dev_bitmap);
HANDLE_ERROR(cudaFree(dev_bitmap));
2.3 更多自由搭配:(1/2/3维度block)*(1/2/3维度thread)
//thread 1D
__global__ void testThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = b[i] - a[i];
}
//thread 2D
__global__ void testThread2(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x;
c[i] = b[i] - a[i];
}
//thread 3D
__global__ void testThread3(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
c[i] = b[i] - a[i];
}
//block 1D
__global__ void testBlock1(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = b[i] - a[i];
}
//block 2D
__global__ void testBlock2(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x;
c[i] = b[i] - a[i];
}
//block 3D
__global__ void testBlock3(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
c[i] = b[i] - a[i];
}
//block-thread 1D-1D
__global__ void testBlockThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x + blockDim.x*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 1D-2D
__global__ void testBlockThread2(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int i = threadId_2D+ (blockDim.x*blockDim.y)*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 1D-3D
__global__ void testBlockThread3(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 2D-1D
__global__ void testBlockThread4(int *c, const int *a, const int *b)
{
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadIdx.x + blockDim.x*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 3D-1D
__global__ void testBlockThread5(int *c, const int *a, const int *b)
{
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadIdx.x + blockDim.x*blockId_3D;
c[i] = b[i] - a[i];
}
//block-thread 2D-2D
__global__ void testBlockThread6(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 2D-3D
__global__ void testBlockThread7(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 3D-2D
__global__ void testBlockThread8(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_3D;
c[i] = b[i] - a[i];
}
//block-thread 3D-3D
__global__ void testBlockThread9(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_3D;
c[i] = b[i] - a[i];
}
调用为:
//testThread1<<<1, size>>>(dev_c, dev_a, dev_b);
//uint3 s;s.x = size/5;s.y = 5;s.z = 1;
//testThread2 <<<1,s>>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testThread3<<<1, s >>>(dev_c, dev_a, dev_b);
//testBlock1<<<size,1 >>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 5; s.y = 5; s.z = 1;
//testBlock2<<<s, 1 >>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testBlock3<<<s, 1 >>>(dev_c, dev_a, dev_b);
//testBlockThread1<<<size/10, 10>>>(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 10; s2.z = 1;
//testBlockThread2 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 5; s2.z = 2;
//testBlockThread3 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread4 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 5; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread5 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 1;
//testBlockThread6 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 5; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 2;
//testBlockThread7 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 5; s2.z = 1;
//testBlockThread8 <<<s1, s2 >>>(dev_c, dev_a, dev_b);
uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
uint3 s2; s2.x = size / 200; s2.y = 5; s2.z = 2;
testBlockThread9<<<s1, s2 >>>(dev_c, dev_a, dev_b);
//或者:
dim3 blocks(DIM/16,DIM/16,1); 二维线程块
dim3 threads(16,16,1); 二维线程
func_kernel<<<blocks,threads>>>(参数);
注意的是 blockDim.x和 gridDim.x确实有一个物理上的最大值,但在使用时的大小是由在代码中的设定决定的,比如下面的:
__global__ void add_kernel(double *a, double *b, double *c) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
add_kernel << < 128, 128 >> > (dev_a, dev_b, dev_c);在GPU上相加操作
3. gpu 的内存结构
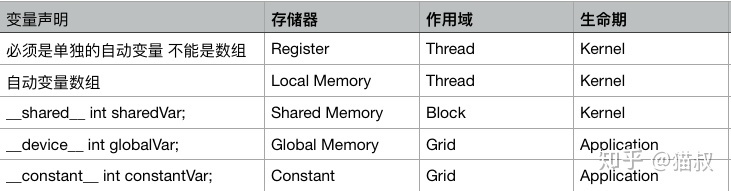
cuda中有寄存器内存,局部内存,共享内存,常量内存,纹理内存,全局内存。寄存器内存用于定义线程专属私有变量。当私有变量申请大小溢出时,自动转为局部内存。当在核函数里面申请局部数组时,自动称为局部内存。
3.1 共享内存
共享内存(shared memory,SMEM)是GPU的一个关键部分,物理层面,每个SM都有一个小的内存池,这个线程池被次SM上执行的线程块中的所有线程所共享。共享内存使同一个线程块中可以相互协同,便于片上的内存可以被最大化的利用,降低回到全局内存读取的延迟。 共享内存是被我们用代码控制的,这也是是他称为我们手中最灵活的优化武器。 一级缓存,二级缓存,共享内存,以及只读和常量缓存,他们的关系如下图:
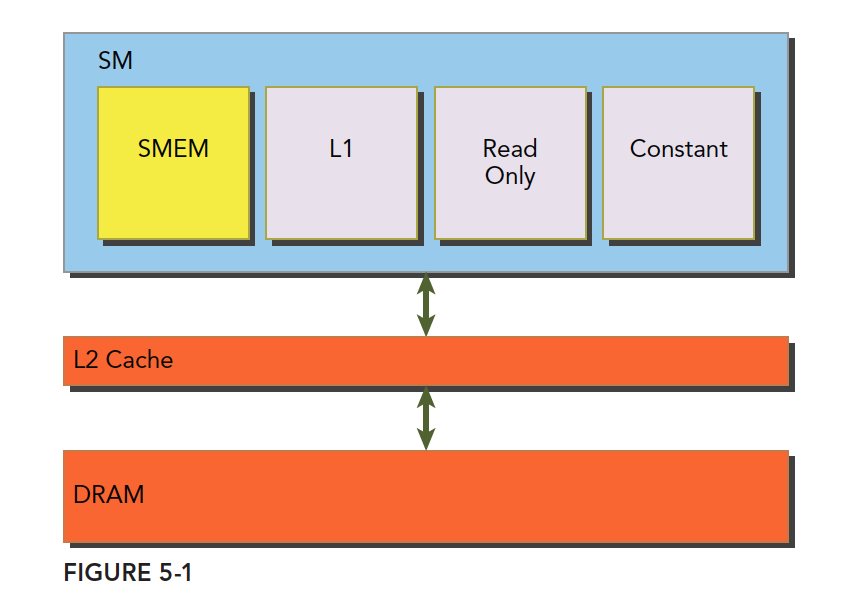
可以看到, 共享内存(SMEM), 一级缓存, 只读缓存和常量缓存更接近SM计算核心,有更低的访问延迟和传输带宽。
将线程块分解为线程的目的,除了物理设备上线程块最大数目的限制,还有一个原因是 CUDA C支持共享内存。对于GPU上的每一个线程块,编译器都为该共享变量创建一个副本,而线程块中的每一个线程共享这块内存。由于共享内存驻留在物理GPU上而不是GPU之外的系统内存中,访问共享内存的延迟要远低于访问普通内缓存区的延迟。
3.2 常量内存
常量内存用于保存在核函数执行期间不会发生变化的数据,由于GPU的性能瓶颈通常不在于芯片的数学吞吐能力,而在于芯片的内存带宽,合理利用常量内存能有效减小内存的带宽的消耗。常量内存存在于核函数之外,在kernel函数外声明,即常量内存存在于内存中,并不在片上,常量内容的访问速度也是很快的,这是因为每个SM都有专用的常量内存缓存,会把片外的常量读取到缓存中;对所有的核函数都可见,在Host端进行初始化后,核函数不能再修改。
写法:
__constant__ Sphere s[num]
对于常量内存,不需要再用 cudaMalloc() 或者 cudaFree() 来申请或释放内存空间,编译器会自动为这个数组提交一个固定的大小。
cudaMemcpy() 会将主机内存复制到全局内存,而cudaMemcpyToSymbol() 会将主机内存复制到常量内存。
常量内存为什么有效:
-
对常量内存的单次操作
可以广播到其他临近线程,范围为半个线程束(Wrap)。 -
常量内存的数据将
缓存起来,因此对相同地址的连续读操作不会产生额外的内存通信量。
常量内存有两个特性,一个是高速缓存,另一个是它支持将单个值广播到线程束中的每个线程。但要注意的是,对于那些数据不太集中或者数据重用率不高的内存访问,尽量不要使用常量内存。
3.3 纹理内存
同常量内存一样,纹理内存(Texture Memory)也是一种只读内存。 之所以称之为 “纹理”,是因为最初是为图形应用设计的。 当程序中存在大量局部空间操作时,纹理内存可以提高性能。 纹理内存的优势: 1.它们是被缓存的,如果它们在texture fetch 中将提供更高的带宽 2.它们不会像全局或常驻内存读取时受内存访问模式的约束 3.寻址计算时的延迟更低,从而提高随机访问数据时的性能 4.在一个操作中,包装的数据可以通过广播到不同的变量中 5.8-bit和16-bit的整型输入数据可以被转换成在范围[0.0,1.0]或[-1.0,1.0]的浮点数
3.4 全局内存
全局内存,就是我们常说的显存,就是GDDR的空间,全局内存中的变量,只要不销毁,生命周期和应用程序是一样的。 在访问全局内存时,要求是对齐的,也就是一次要读取指定大小(32、64、128)整数倍字节的内存,数据对齐就意味着传输效率降低,比如我们想读33个字节,但实际操作中,需要读取64字节的空间。
4. 原子操作
对于有很多线程需要同时读取或写入相同的内存时,保证同一时间只有一个线程能进行操作。 只支持某些运算(加、减、最小值、异或运算等,不支持求余和求幂等)和数据类型(整型)







![C. The Third Problem(MEX,思维,组合数)[Codeforces Round #804 (Div. 2)]](https://img-blog.csdnimg.cn/288fa3c217684ccaa6e1c3a830f3fa79.png)




