深度学习的归一化方法
1 归一化的目的
- 当我们使用梯度下降法做优化时,随着网络深度的增加,输入数据的特征分布会不断发生变化,为了保证数据特征分布的稳定性,会加入Normalization。从而可以使用更大的学习率,从而加速模型的收敛速度,换言之,使用神经网络模型都会使用到激活函数,激活函数都存在饱和区,为了避免梯度消失,一般将数据输入到激活函数之前,对数据分布进行纠正,使得其位于非饱和区域,有利于学习。
- 同时,Normalization也有一定的抗过拟合作用,使训练过程更加平稳。
2 Layer Normalization 和Batch Normalization的原理和区别
- 归一化公式
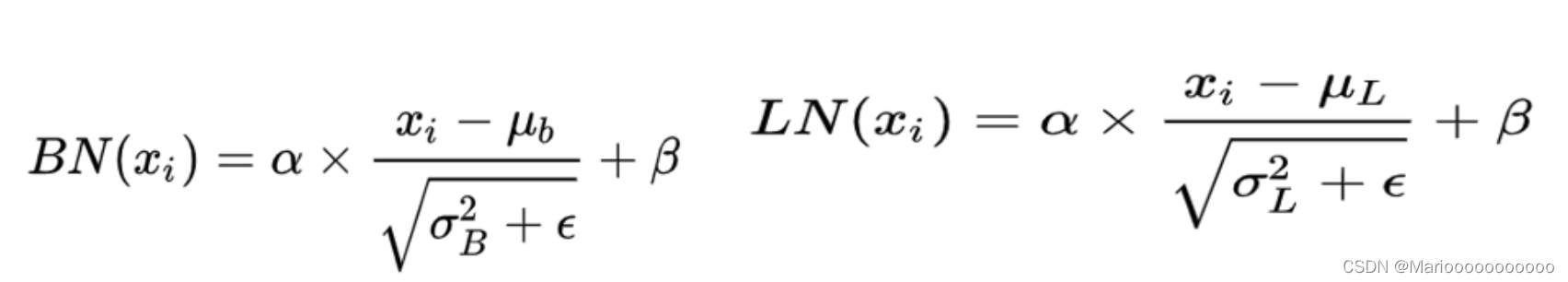
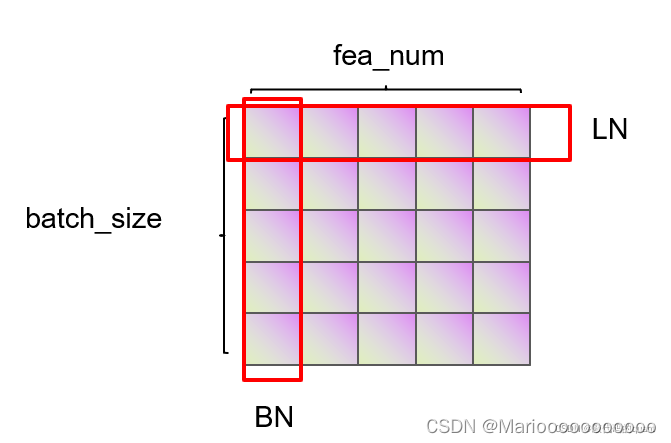
- 区别:看图说话
以下图为例,这里的batch_size为5(行数),也就是这里有五条数据。每一条数据的特征维度是5(列数)。
Batch Normalization就是对所有的样本的同一个特征维度进行归一化,下图圈中的是对五个样本里的第一个特征进行归一化。然后依次对所有五个样本的第二个特征进行归一化…。这样做的好处是对保留了不同样本同一个特征之间的多样性。
Layer Normalization就是对同一个样本的所有特征进行归一化处理。这样做的好处是保留同一个样本的特征之间的多样性。
3 使用场景
在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。但是有些场景是不能使用BN的,例如batch size较小或者序列问题中可以使用LN。这也就解答了RNN 或Transformer为什么用Layer Normalization?
4 使用BN和LN注意的地方
LN针对的是单独一个样本,在训练和预测阶段的使用并无差别;BN是针对一个batch进行计算的,训练时自然可以根据batch计算,但是预测时有时要预测的是单个样本,此时要么认为batch size就是1,不进行标准化处理,要么是在训练时记录标准化操作的均值和方差直接应用到预测数据,这两种解决方案都不是很完美,都会存在偏差。
参考连接:
参考1
参考2