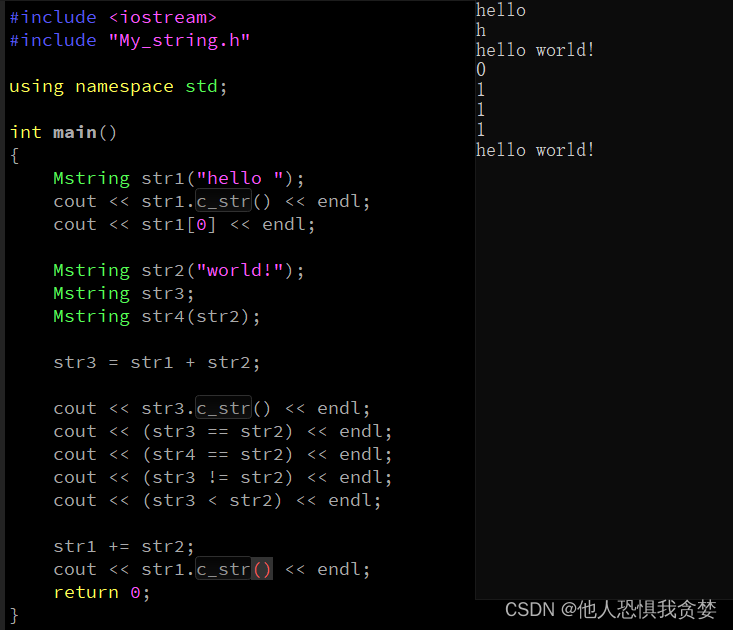
🔗 课程链接:李樾老师和谭天老师的:
南京大学《软件分析》课程11(Pointer Analysis - Context Sensitivity I)_哔哩哔哩_bilibili
南京大学《软件分析》课程12(Pointer Analysis - Context Sensitivity II)_哔哩哔哩_bilibili
目录
第八章 上下文敏感的指针分析
8.1 上下文敏感技术的介绍
8.1.1 为什么需要上下文敏感技术
8.1.2 基本概念
1. 定义
2. 策略——call-site sensitivity(call-string)
3. 实现——基于克隆的上下文敏感(Cloning-Based Context Sensitivity)
4. Context-Sensitive Heap
8.1.3 Context-Sensitive Heap的例子
8.2 规则 Rule
8.2.1 Domains and Notions 域与符号
8.2.2 Rules 规则
1. 处理4种基本语句的规则
2. 处理Call语句的规则
8.3 算法实现
8.3.1 Pointer Flow Graph with C.S.
8.3.2 算法总体
8.3.3 ProcessCall的不同——Select上下文⭐
8.4 上下文敏感的变种
8.4.1 从上下文敏感的视角,看上下文不敏感技术
8.4.2 调用点敏感(Call-Site Sensitivity)
8.4.3 对象敏感(Object Sensitivity)
8.4.4 类型敏感(Type Sensitivity)
8.4.5 总结
第八章 上下文敏感的指针分析
在第六章中介绍了上下文敏感的一些知识,这是提升指针分析精度最有效的技术,特别是对java。只要是跨函数涉及过程间的,基本都很有用。本章内容可能需要第六章和第七章的内容,再次贴一个之前的笔记连接:
8.1 上下文敏感技术的介绍
8.1.1 为什么需要上下文敏感技术
如下图所示的程序,如果进行上下文不敏感的常量传播分析,id被调用了两次,一次传入的是n1 一次是n2,就会导致 id 方法的参数 n 在不同上下文里的对象混在一起,指针域为{o1, o2},再顺着指针分析传播的时候,通过返回值给x和y,会传递虚假的值,再分析 i 值的时候,会导致i = NAC
 可
可
所以,上下文不敏感的技术(Imprecision of Context Insensitivity, C.I.),再处理一个方法的多个不同上下文的调用的时候,会混在一起传播,会引入假的数据流,丢失精度。
如果是上下文敏感的技术,如下,在不同的调用的时候,会进行标记,从而不会将所有参数的传递混在一起,这样分析出来的i 就是正确的值 1。

8.1.2 基本概念
1. 定义
上下文敏感(Context Sensitivity, C.S.)模型通过区分不同上下文的不同数据流来调用上下文以提高精度。
2. 策略——call-site sensitivity(call-string)
使用call-site sensitivity(call-string) 策略,将方法的每个上下文表示为一系列调用点(a chain of call sites),也就是对方法、caller、caller的caller的call site,通过一系列调用可以到达这个方法的call site 链,把这一系列call sites 当作上下文(是动态执行的调用栈的一个抽象)。
如下图所示,id(Number)的上下文,就是[1] 和 [2] 。

3. 实现——基于克隆的上下文敏感(Cloning-Based Context Sensitivity)
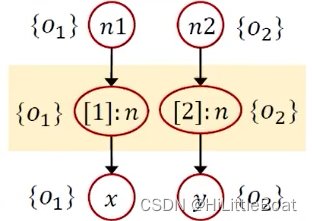
在基于克隆的上下文敏感指针分析中,会给每个方法加一个或多个上下文进行修饰。给方法加上下文,实际上就是给变量加上下文(变量在某方法中声明),可以当作对一个变量的标记,标记从哪个call-site过来。基本上,每个方法及其变量都是克隆的,每个上下文对应一个克隆。
如下图所示,对上述程序中的id 方法 中的变量加上各自的上下文,以免混淆:
4. Context-Sensitive Heap
对于像Java这种OO语言,会频繁对对象进行操作,又因为这些对象经常分配在堆区,所以把这种频繁修改对象的行为称为heap-intensive。
对于heap-intensive,在实际中,为了提升精度,我们不仅要给变量加上下文,还要给对象加上下文(heap contexts),给对象的上下文来自于所在的方法。
加上堆抽象的上下文敏感技术提供了更精细的粒度堆模型。

8.1.3 Context-Sensitive Heap的例子
对下图代码,在采用上下文敏感的技术时,如果只考虑变量的上下文,不考虑Heap的上下文,对代码进行分析的结果如中间的表格所示,如果考虑heap、也考虑变量的上下文时候,分析结果如最右边:

对于第一种不考虑heap上下文的方法,实际上,在动态运行的时候,n是不会指向o2的。之所以会产生假的数据流,是因为这里的heap,在动态运行时,其实创建了两个o8,分别指向不同上下文中创建的两个对象x1 和 x2,然后又在o8处汇合了,一起传出去给n,导致了假的数据流。
在我们给对象加了上下文的时候,就可以有效地区分开,从而提升精度。对于变量和heap都是需要加上上下文来分析的。
8.2 规则 Rule
8.2.1 Domains and Notions 域与符号
| 上下文 | c, c', c'' ∈ C | C表示程序中所有的上下文,具体的上下文用c, c',c'' 表示 C里具体的内容为一系列call sites 形成的串(列表) |
| 上下文敏感的方法 | c: m ∈ C × M | 在具体的方法前,加上具体的上下文,表示上下文c之下的方法m |
| 上下文敏感的变量 | c: x, c': y ∈ C × V | |
| 上下文敏感的对象 | c: oi, c': oj ∈ C × O | |
| Fields | f, g ∈ F | Field 本身不需要加上下文,因为field挂靠在某个object上 |
| Instance fields | c: oi.f, c': oj.g ∈ C × O × F | 具体某个对象的field,需要加上具体的上下文的对象 |
| 上下文敏感的指针 | CSPointer = (C×V)∪(C×O×F) | 指针有两种,变量和field |
| 指向关系 | pt : CSPointer → 𝒫(C × O) | 即把上下文敏感的指针,映射到 带有上下文的对象的幂集中。 |
8.2.2 Rules 规则
1. 处理4种基本语句的规则
如下图所示,就是上下文敏感下的指针分析处理4种语句的的规则,对比7.1.2中没有上下文敏感的规则,其实只多了红色的部分:上下文。(横线上的公式表示条件,横线下为结论)
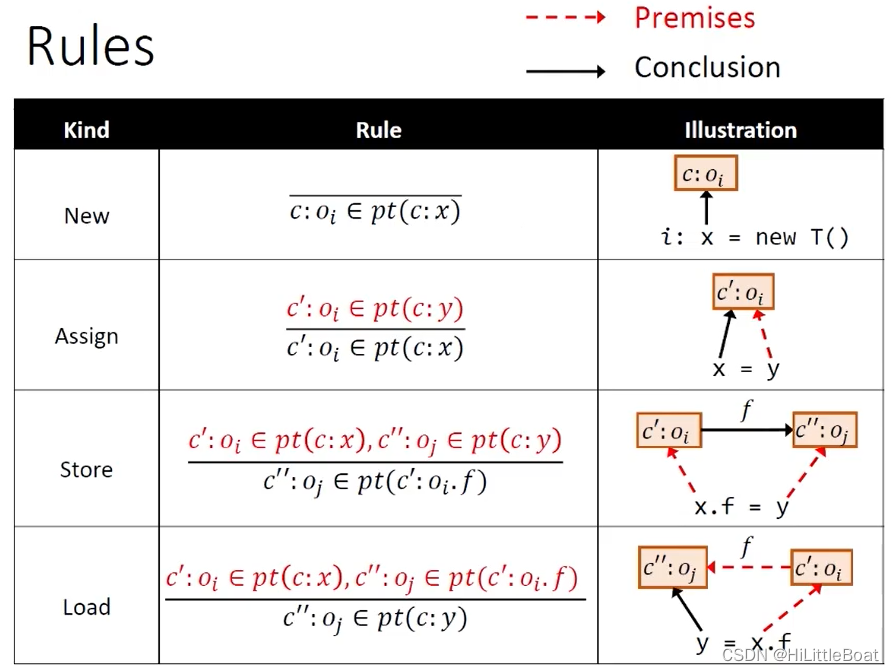
感觉和7.1.2中的规则区别不大,这里就不再一条一条详细写了,可以对比下第七章的笔记:
【软件分析/静态分析】chapter7 课程09/10 指针分析基础(Pointer Analysis Foundations)_HiLittleBoat的博客-CSDN博客
2. 处理Call语句的规则
call 语句是很重要的,因为它决定你的上下文是如何产生的。具体的规则如下:
在7.4.2中处理没有上下文敏感的调用语句是,主要一般负责如下4件事情:
- dispatch → 传递receive objects → 传参数 → 传返回值
加上上下文之后,主要区别有两点,
① 在dispatch找到目标方法m之后,要进行很关键的一步:Select,选择目标方法t的上下文
② 找到上下文之后,带着上下文信息,传receive object、参数、返回值,例如对于变量x 需要将 c': x,传到找到的目标方法的上下文里的m_this。
所以,在处理上下文敏感的调用语句的时候,主要负责如下5件事情:
- dispatch → select → 传递特定上下文的receive objects → 传特定上下文的参数 → 传特定上下文的返回值
对于Select方法,主要是根据传入一系列参数(如下)来求目标方法的上下文,参数如下:
- c:这个语句所在方法的上下文
- l : 调用点,可以是这条语句的标签label,
- c': oi :receive object
- m: 目标方法
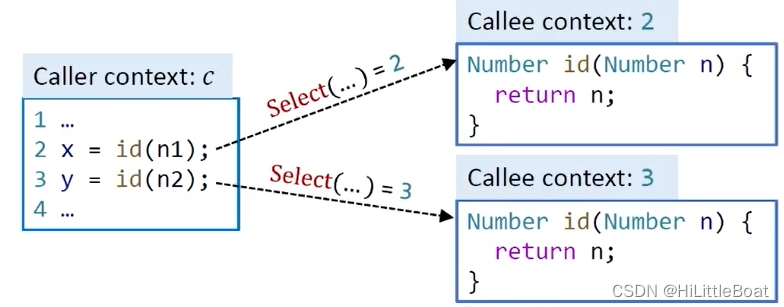
①先看一个例子:
这里,c为这些调用语句所在的方法/上下文,给Select传入一系列参数,选出第2行语句的目标方法 id(Number n) 的上下文是2,第3行的目标方法的上下文是3,然后跟目标函数组合在一起。
之后会对该方法进行克隆,有一个上下文就克隆一次,将针对特定上下文,传receive object(处理this语句)、传参、传返回值。
要注意,这里的例子中是可以用call site,也就是这个语句的label来进行表示上下文的,上下文也有其他的表示方法,具体怎么选,上下文用什么表示,会在8.3 算法实现部分介绍。
8.3 算法实现
8.3.1 Pointer Flow Graph with C.S.
我们用Pointer Flow Graph with C.S.(上下文敏感的指针流图)来表示对象在程序中指针之间的流动。他的组成如下:
- Nodes:CSPointer = (C×V)∪(C×O×F)
一个节点可能表示一个特定上下文的变量,或一个特定上下文抽象对象的一个field。
于PFG相比,在上下文敏感的PFG中,每个节点都会带有上下文 - Edges:CSPointer × CSPointer
一条边x→y,表示指针x所指向的对象可能流向y,并会被y所指向。
针对每条规则,形成的PFG边,具体可以比较7.2.2的PFG来看,如下: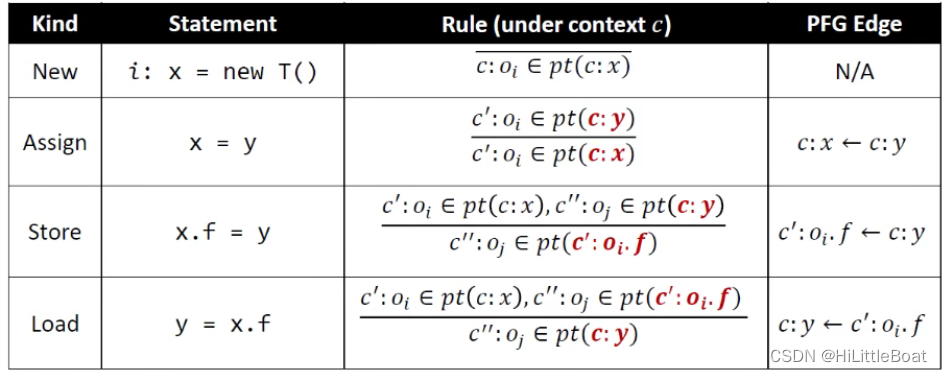

8.3.2 算法总体
如下图所示为整个算法
实际上,如果没有加上那些上下文c、c',就是一个上下文不敏感的指针分析。主体框架、思想和流程跟之前都是完全一致的,都是建立pfg,然后在pfg上传播指针的指向关系。其中AddEdge(s, t)和Propagate(n, pts)函数跟之前上下文不敏感的指针分析是完全一样的,代码就不在赘述。
主要区别有两点,即黄色高亮的地方:
① 给每个变量、函数、调用点等都加上了所在的上下文。
② 在处理调用的函数ProcessCall()函数中,增加了调用Select函数的部分。
这里主要阐述第二点不同,其他的地方就不再赘述了,可以参考上一篇chapter7 指针分析的笔记。
8.3.3 ProcessCall的不同——Select上下文⭐
上下文敏感的指针分析在处理调用语句的时候,会先根据流入的新对象oi,dispatch到真正的目标函数m,然后用select选出这个目标函数的上下文c^t。
主要根据以下信息来选择上下文(Select函数需要的参数):
- 调用者x所在的上下文 c
- 调用点本身 l
- 流入调用者的新对象 c': oi
- 目标函数 m
不同的select定义的方式,取决于不同的上下文敏感的策略,在8.4中会介绍3种最常用的上下文敏感的策略,然后再详细介绍各自的select方法。
8.4 上下文敏感的变种
上下文的选取主要有:
- call-site sensitivity
- object sensitivity
- Type sensitivity
- ……
8.4.1 从上下文敏感的视角,看上下文不敏感技术
上下文不敏感可以看作时上下文敏感的一个特殊情况,对于C.I.来说,Select函数在任何情况下都返回一个空的上下文,也就是在任何情况下都是一样的上下文
![]()
8.4.2 调用点敏感(Call-Site Sensitivity)
1. Call-Site Sensitivity原理
每个上下文由一系列调用链组成,在方法调用的时候,将调用点(call site)加入到caller的上下文中。实际上就是调用栈的抽象。

call-site sensitivity 也可以叫做call-string sensitivity,或k-CFA*
*论文出处:
Olin Shivers,1991. "Control-Flow Analysis of Higher-Order Languages".Ph.D. Dissertation. Carnegie Mellon University.
2. 例子
如下图所示,对于左边的程序,上下文如右边所示,每增加一次调用,就会加入一个新的上下文,但是对于15行有递归调用的情况,就可能会一直调用下去,导致context无限了。

所以,我们需要保证算法能够终止。再分析真实程序的时候,程序可能很复杂,调用链非常长,现在的静态分析没法解决这样的上下文。由此引入,k-Limiting Context Abstraction,来限制调用链的长度。
3. k-Limiting Context Abstraction
- 目的:
- 确保指针分析的终止
- 在现实世界的程序中,太多的上下文(长调用链)破坏了指针分析
- 方法:为上下文长度设置一个上限,用k表示
- 对于调用点敏感方法,每个上下文都由调用链的最后一个k call sites 组成
- 在实际应用中,k是一个小数目(通常是≤3)
- 方法上下文和堆上下文可以使用不同的k
- 例如:k=2用于方法上下文,k=1用于堆上下文
4. k-Call-Site Sensitivity/k-CFA
- ① 1-call-site/1-CFA
如下图所示,当限制为1 的时候,对于每个上下文的调用链的长度只会去最后一个,第13行在第一次被9调用到的时候,上下文是[9],之后第一次被15调用时,得到上下文[15],之后再被15重复调用,就会只截取15,就不会再分析一次。

- ② 2-call-site/2-CFA
在实际应用中,我们会更倾向于用2层上下文,用调用的最后两个元素,来表示一个上下文。
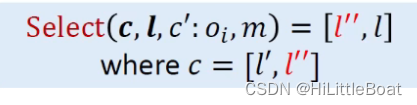
5. 例子
- ① 1-call-site 例子
接下来,会结合8.3部分的算法(如下图所示),来具体分析一下下边的程序,为了简便,分析的过程中省去了heap的上下文和C.id里的this 变量,主要左下角的代码,最终目标是,分析第16行代码x.get() 会调用哪些方法。

首先,将一系列的数据结构(WL, PFG, S, RM, CG)初始化为空,
然后,使用AddReachable()方法,将加了上下文表示的方法,[ ]:C.main() ,加入RM,表示该方法可达,
然后,处理该main方法里的语句,这里有一个new语句,将其指针和对应heap对,<[ ]:c, {o3}>加入WL(这里的o3 先省略了上下文)

然后从WL中取出<[ ]:c, {o3}>,处理过程跟c.i.是一样的,具体过程不再详细解释,这里把o3传到[ ]:c的指针集中,
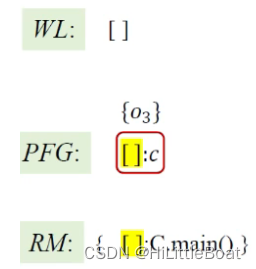
然后需要根据ProcessCall()方法处理第4行,c的方法调用语句:

这里就涉及到了上下文敏感分析的关键一步:选取上下文。这里即为第4行调用了C.m方法,这里C.m的上下文即为[4],然后将<[4]:C.m_this, {o3}>传入WL中,然后连接CG,使用AddReachable()方法处理新可达的[4]:C.m方法,处理其new语句,再加入WL中,结果如下:

接下来,从WL中取出来<[4]:C.m_this, {o3}>,进行处理,同样,处理其相关语句,涉及14、15行的两个调用:
对于14,先选出来他的dispatch ,即7行的 C.id方法,接下来选择其上下文,即[14],然后加调用边 [4]:14 → [14]:C.id(Number),再往RM中添加方法 [14]:C.id(Number)。这个调用中涉及到了关键的传参和返回值:[4]:n1→[14]:n,及[14]:n→[4]:x。
对于15,同理,加调用边,加RM,处理传参和返回值,得到的结果如下图所示:

接着继续从WL中取出来未处理的pair,进行处理,这里不在详细介绍步骤,主要是沿着PFG,传递指针域。
对比c.i. ,上下文敏感的技术可以将不同上下文的节点区分开,最终结果如下图所示:

8.4.3 对象敏感(Object Sensitivity)
1. 原理
每个上下文都包含一个抽象对象列表(由他们的allocation sites表示)。
- 在方法调用时,使用接收对象及其heap context作为被调用上下文。
- 区分数据流在不同对象上的操作。
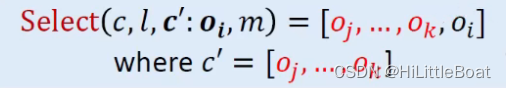
论文出处:
Ana Milanova,Atanas Rountev, and Barbara G.Ryder. " Parameterized ObjectSensitivity for Points-to and Side-Effect Analyses for Java".lSSTA 2002.
2. C.S.(1-Object) vs. C.S.(1-Call-site)
① 在如下例子中,对比1-call-site,1-object可以拿到准确的结果,如下图所示:

1-call-site方法会把doSet 混在一起
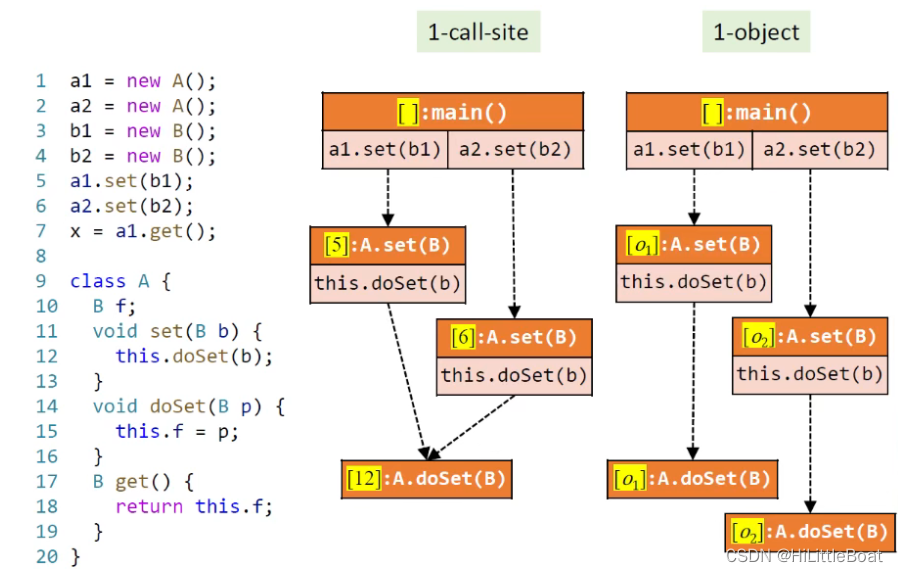
打个比方,就相当于,1-call-site 会一直记得从哪个屋子进来的,而1-object会一直记得记得这个人是谁。
② 但是对于以下的程序,1-Call-site会比1-object更准确:因为同一个receiver object 用不同参数多次调用了子函数,导致局部变量无法区分。

③ 总结:
综上,在理论上,这两种方法的精度是没有办法直接比较的。但是在实际应用中,对于像java的这种OO语言来说,对象敏感表现优于调用点敏感。
8.4.4 类型敏感(Type Sensitivity)
1. 原理
每个上下文都包含一个类型列表。在用方法调用时基于创建点所在的类型,作为被调用上下文。

是对 object sensitivity 的抽象,精度要弱于 object。
论文出处:
Yannis Smaragdakis, Martin Bravenboer, and Ondrej Lhotwk." Pick YourContexts Well: Understanding Object-Sensitivity".POPL 2011.
8.4.5 总结
精确度:object > type > call-site
效率:type > object > call-site
参考:
https://wenku.baidu.com/view/5cadf582de3383c4bb4cf7ec4afe04a1b071b0ad.html?_wkts_=1692682599401&bdQuery=%E4%B8%8A%E4%B8%8B%E6%96%87%E6%95%8F%E6%84%9F%E7%9A%84%E6%8C%87%E9%92%88%E5%88%86%E6%9E%90%E6%8A%80%E6%9C%AF