近期发现了一个项目,它的前身是ChatGLM,在我之前的博客中有关于ChatGLM的部署过程,本项目在前者基础上进行了优化,可以基于当前主流的LLM模型和庞大的知识库,实现本地部署自己的ChatGPT,并可结合自己的知识对模型进行微调,让问答中包含自己上传的知识。依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。下面具体讲解如何来实现本地部署,过程十分简单,使用起来十分方便。
目录
一、代码下载
二、 模型支持
2.1 LLM 模型支持
2.2 Embedding 模型支持
三、开发部署
3.1 软件需求
3.2 开发环境准备
3.3 下载模型至本地
3.4 设置配置项
3.5 知识库初始化与迁移
3.6 一键启动API 服务或 Web UI
四、添加个人知识库
4.1 本地添加知识库
4.2 通过web页面添加知识库
4.3 重新微调模型
一、代码下载
项目链接 GitHub - chatchat-space/Langchain-Chatchat
将该代码下载到本地。
二、 模型支持
本项目中默认使用的 LLM 模型为 THUDM/chatglm2-6b,默认使用的 Embedding 模型为 moka-ai/m3e-base 为例。
2.1 LLM 模型支持
本项目最新版本中基于 FastChat 进行本地 LLM 模型接入,支持模型如下:
- meta-llama/Llama-2-7b-chat-hf
- Vicuna, Alpaca, LLaMA, Koala
- BlinkDL/RWKV-4-Raven
- camel-ai/CAMEL-13B-Combined-Data
- databricks/dolly-v2-12b
- FreedomIntelligence/phoenix-inst-chat-7b
- h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b
- lcw99/polyglot-ko-12.8b-chang-instruct-chat
- lmsys/fastchat-t5-3b-v1.0
- mosaicml/mpt-7b-chat
- Neutralzz/BiLLa-7B-SFT
- nomic-ai/gpt4all-13b-snoozy
- NousResearch/Nous-Hermes-13b
- openaccess-ai-collective/manticore-13b-chat-pyg
- OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
- project-baize/baize-v2-7b
- Salesforce/codet5p-6b
- StabilityAI/stablelm-tuned-alpha-7b
- THUDM/chatglm-6b
- THUDM/chatglm2-6b
- tiiuae/falcon-40b
- timdettmers/guanaco-33b-merged
- togethercomputer/RedPajama-INCITE-7B-Chat
- WizardLM/WizardLM-13B-V1.0
- WizardLM/WizardCoder-15B-V1.0
- baichuan-inc/baichuan-7B
- internlm/internlm-chat-7b
- Qwen/Qwen-7B-Chat
- HuggingFaceH4/starchat-beta
- 任何 EleutherAI 的 pythia 模型,如 pythia-6.9b
- 在以上模型基础上训练的任何 Peft 适配器。为了激活,模型路径中必须有
peft。注意:如果加载多个peft模型,你可以通过在任何模型工作器中设置环境变量PEFT_SHARE_BASE_WEIGHTS=true来使它们共享基础模型的权重。
以上模型支持列表可能随 FastChat 更新而持续更新,可参考 FastChat 已支持模型列表。
除本地模型外,本项目也支持直接接入 OpenAI API,具体设置可参考 configs/model_configs.py.example 中的 llm_model_dict 的 openai-chatgpt-3.5 配置信息。
2.2 Embedding 模型支持
本项目支持调用 HuggingFace 中的 Embedding 模型,已支持的 Embedding 模型如下:
- moka-ai/m3e-small
- moka-ai/m3e-base
- moka-ai/m3e-large
- BAAI/bge-small-zh
- BAAI/bge-base-zh
- BAAI/bge-large-zh
- BAAI/bge-large-zh-noinstruct
- sensenova/piccolo-base-zh
- sensenova/piccolo-large-zh
- shibing624/text2vec-base-chinese-sentence
- shibing624/text2vec-base-chinese-paraphrase
- shibing624/text2vec-base-multilingual
- shibing624/text2vec-base-chinese
- shibing624/text2vec-bge-large-chinese
- GanymedeNil/text2vec-large-chinese
- nghuyong/ernie-3.0-nano-zh
- nghuyong/ernie-3.0-base-zh
- OpenAI/text-embedding-ada-002
三、开发部署
3.1 软件需求
本项目已在 Python 3.8.1 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。
3.2 开发环境准备
参见 开发环境准备。
请注意: 0.2.3 及更新版本的依赖包与 0.1.x 版本依赖包可能发生冲突,强烈建议新建环境后重新安装依赖包。
首先要创建虚拟环境,然后在虚拟环境中切换到代码文件目录:
cd /d E:\Demo\Langchain-Chatchat-master # 切换到代码所在位置创建虚拟环境:
conda create -n Chat_GLM python=3.9 # 虚拟环境名称为ChatGLM启用虚拟环境:
conda activate ChatGLM安装环境依赖:
pip install requirements.txt安装zh_core_web_sm语言包:
spacy/zh_core_web_sm at main (huggingface.co)
只需下载下方图片目录中的whl文件,然后切换到zh_core_web_sm-any-none-any.whl目录,采用pip 安装
pip install zh_core_web_sm-any-none-any.whl
3.3 下载模型至本地
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/chatglm2-6b 与 Embedding 模型 moka-ai/m3e-base 为例。直接点击下载。
网盘下载:
链接:https://pan.baidu.com/s/14vm-yc8EDQ3DqrRAliFWXw?pwd=eaxq
提取码:eaxq链接:https://pan.baidu.com/s/1OAqm5sQOUHYyg-YzZu7eCw?pwd=0arh
提取码:0arh
3.4 设置配置项
复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。
在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 和 configs/server_config.py 中的各项模型参数设计是否符合需求:
- 请确认已下载至本地的 LLM 模型本地存储路径写在
llm_model_dict对应模型的local_model_path属性中,如:
llm_model_dict={
"chatglm2-6b": {
"local_model_path": "E:\Demo\chatglm2-6b", # 只需该这里
"api_base_url": "http://localhost:8888/v1", # "name"修改为 FastChat 服务中的"api_base_url"
"api_key": "EMPTY"
},
}- 请确认已下载至本地的 Embedding 模型本地存储路径写在
embedding_model_dict对应模型位置,如:
embedding_model_dict = {
"m3e-base": "E:\Demo\m3e-base", # 只需改这里
}如果你选择使用OpenAI的Embedding模型,请将模型的 key写入 embedding_model_dict中。使用该模型,你需要能够访问OpenAI官的API,或设置代理。
3.5 知识库初始化与迁移
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
-
如果您是从
0.1.x版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型与configs/model_config.py中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可: -
python init_database.py -
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启
normalize_L2,需要以下命令初始化或重建知识库: -
python init_database.py --recreate-vs
3.6 一键启动API 服务或 Web UI
1. 一键启用默认模型
一键启动脚本 startup.py,一键启动所有 Fastchat 服务、API 服务、WebUI 服务,示例代码:
python startup.py -a自动跳转到web页面,若不能跳转记得在代码末尾按一下Enter键,即可一键启动web页面。

并可使用 Ctrl + C 直接关闭所有运行服务。如果一次结束不了,可以多按几次。
可选参数包括 -a (或--all-webui), --all-api, --llm-api, -c (或--controller), --openai-api, -m (或--model-worker), --api, --webui,其中:
--all-webui 为一键启动 WebUI 所有依赖服务;
--all-api 为一键启动 API 所有依赖服务;
--llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务;
--openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务;
其他为单独服务启动选项。2. 启用非默认模型
若想指定非默认模型,需要用 --model-name 选项,示例:
python startup.py --all-webui --model-name Qwen-7B-Chat更多信息可通过 python startup.py -h查看。
四、添加个人知识库
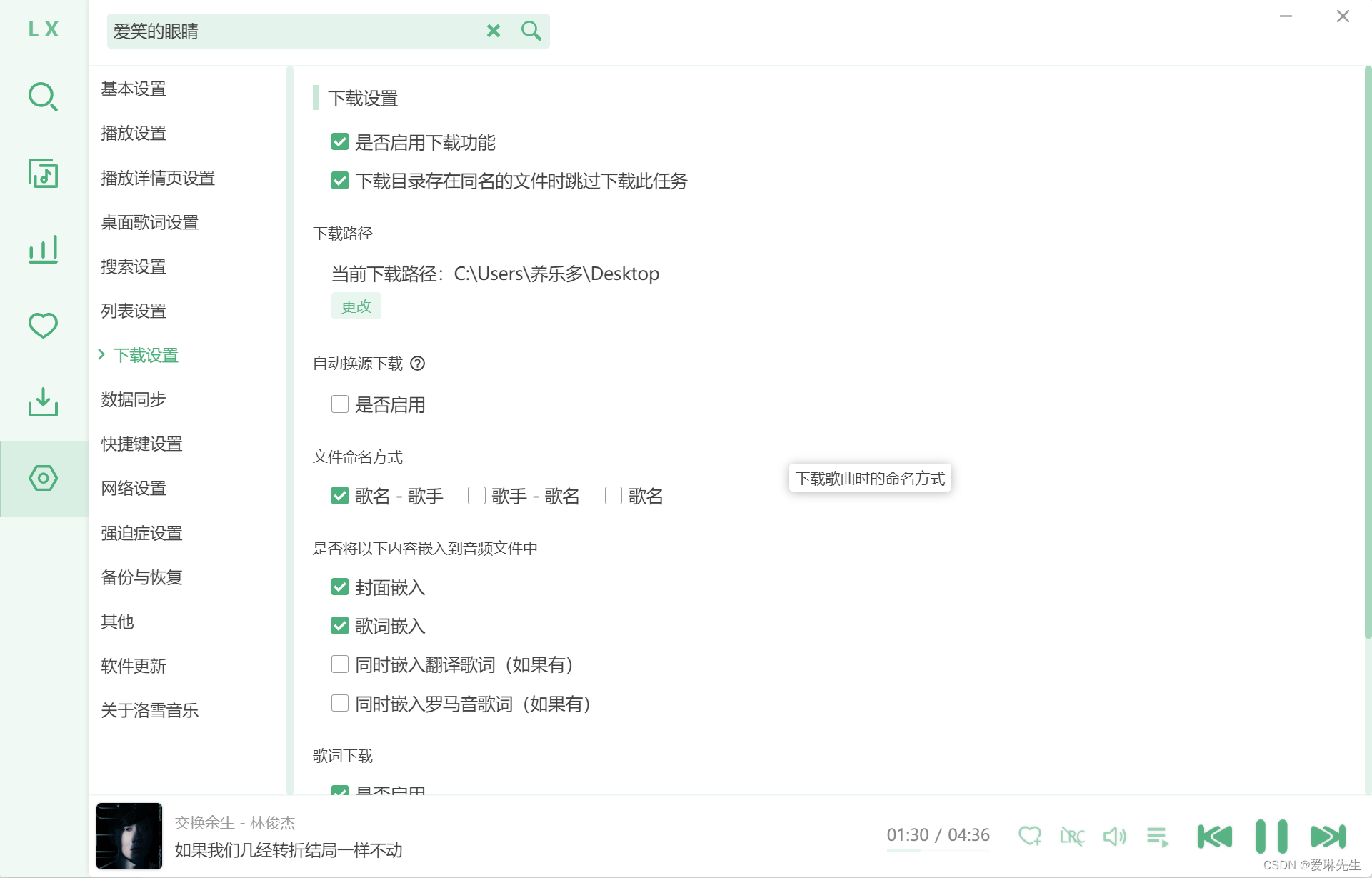
如果当前回答结果并不理想,如下图所示,可添加知识库,对知识进行优化

4.1 本地添加知识库
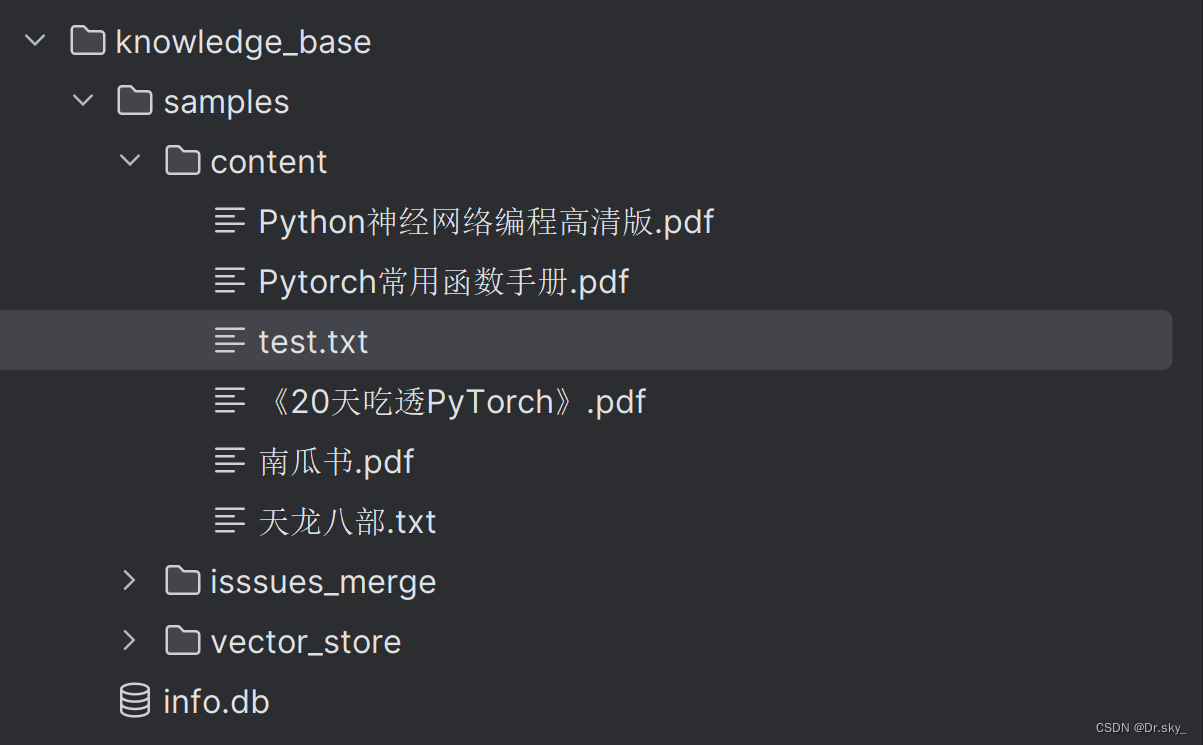
将文档添加到knowledge_base——samples——content目录下:
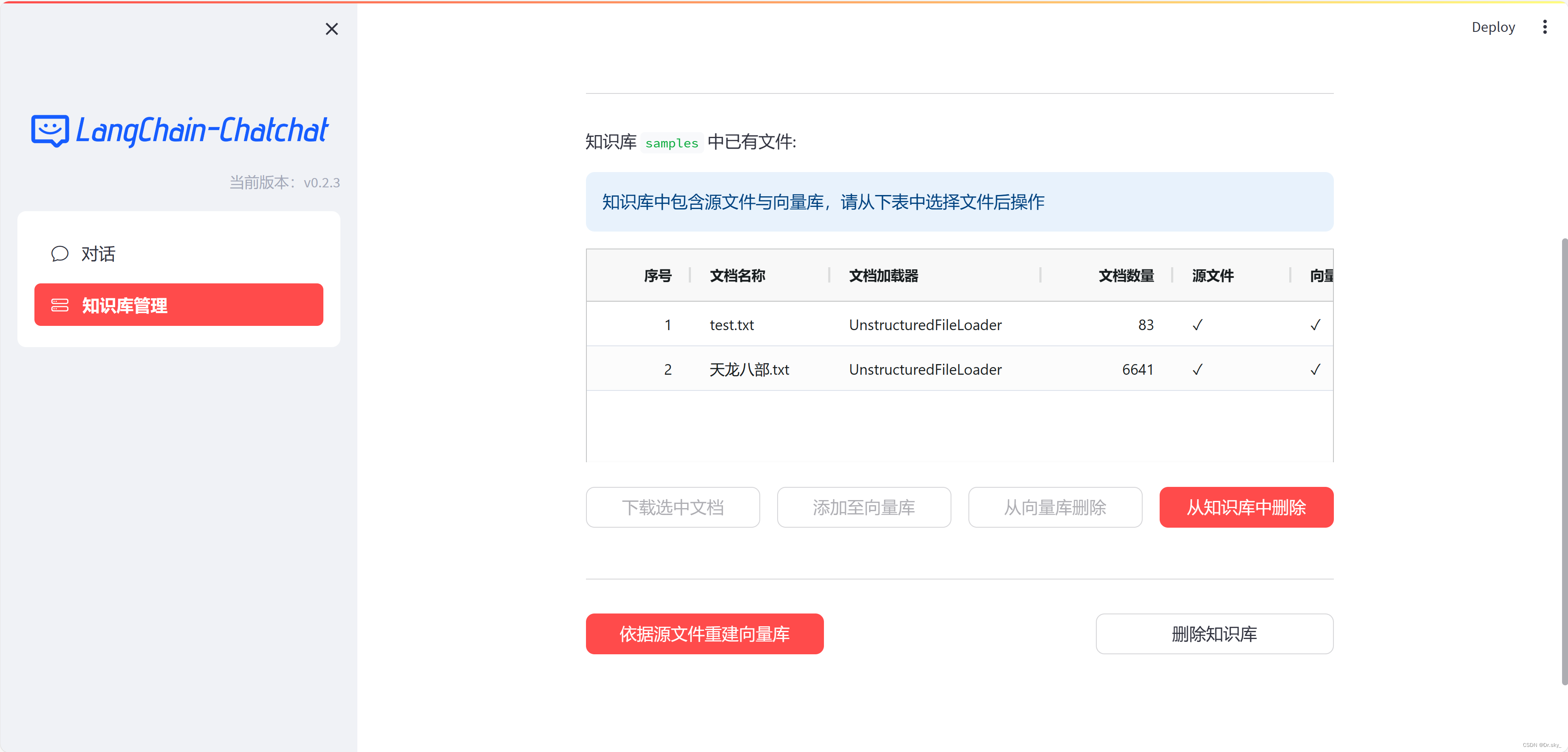
4.2 通过web页面添加知识库
4.3 重新微调模型
知识库添加完成之后,按照3.5-3.6重新运行程序,即可实现本地知识库更新。如下图所示,添加完《天龙八部》电子书之后,回答结果变得精准。

提升回答速度,把CPU改为GPU:
model_config.py文件中,修改
# Embedding 模型运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
EMBEDDING_DEVICE = "auto"为:
# Embedding 模型运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
EMBEDDING_DEVICE = "cuda"修改
# LLM 运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
LLM_DEVICE = "auto"为:
# LLM 运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
LLM_DEVICE = "cuda"提示:
若上述部署中遇到问题,可关注我dy:dyga9uraeovh






![[学习笔记]PageRank算法](https://img-blog.csdnimg.cn/48de627f51ec460f8aa932c198d22b72.png)