2.1 Statement 模式的概念
Statement 是基于语句的复制模式。
Statement 模式将数据库中执行的修改操作记录为 SQL 语句,再从数据库上执行相同的 SQL 语句来实现数据同步。
2.2 Statement 模式的优点
Statement 模式的优点是简单明了,易于理解和实现。
2.3 Statement 模式的缺点
Statement 模式在执行涉及非确定性函数、触发器和存储过程等操作时,可能会导致不一致的结果。
1)不支持 RU、RC 隔离级别;
2)binglog 日志文件中,上一个事物的结束点是下一个事物的开始点;
3)DML、DDL 语句都会明文显示;
4)对一些系统函数不能准确复制或者不能复制;
5)主库执行 delete from t1 where c1=xxx limit 1,statement 模式下,从库也会这么执行,可能导致删除的不是同一行数据;
6)主库有 id=1 和 id=10 两行数据,从库有 id=1,2,3,10 这四行数据,主库执行 delete from t1 where id<10 命令,从库删除过多数据。
2.4 Statement 模式的应用场景
Statement 模式适用于大多数情况下的数据库复制需求。
例如:
1)一次更新大量数据,如二十万数据。反之,在复制时,从库可能会追得太慢,然后导致延时;
2)使用 pt-table-checksum 工具时。
2.1 Row 模式的概念
MySQL 5.7 默认的日志模式为 Row。
Row 模式是基于行的复制模式,它将数据库中实际修改的行记录写入 Binlog ,从数据库通过解析 Binlog 来逐行执行相应的修改操作。
相对 statement ,Row 模式更加精确、安全,能够确保数据的一致性。
2.2 Row 模式的优点
Row 模式能准确复制修改的行记录,避免了语句复制模式下的不确定性问题。
2.3 Row 模式的缺点
如果 Binlog 文件较大,传输成本就会很高,在某些情况下,可能会导致性能下降。
1)在表有主键的情况下复制更加快;
2)系统的特殊函数也能复制;
3)更少的锁,只有行锁;
4)Binlog 文件比较大,假设单语句更新 20 万行数据,可能要半小时,也有可能把主库跑挂;
5)MySQL 5.6 之前的版本,无法从 binog 看见用户执行的 SQL 语句;
6)DDL 语句明文显示,DML 语句加密显示;
7)DML 经过 base64 加密,需要使用参数 --base64-output=decode-rows --verbose;
8)update 修改的语句可以看到历史旧数据。
2.4 Row 模式的应用场景
Row 模式适用于对数据一致性要求较高的场景,特别是涉及一些复杂的数据库操作和业务逻辑。例如,涉及触发器、存储过程和函数等的数据库操作。
使用Row 模式时需注意,Row 模式可能导致 Binlog 文件较大,需要合理设置 Binlog 文件大小和保留时间。
3.1 Mixed 模式的概念
Mixed 模式(混合模式)是将语句复制模式和行复制模式结合起来使用。
大多数的修改操作,通常使用 Statement 模式记录对应的 SQL 语句。
一些特殊的操作,涉及非确定性函数和存储过程等,则使用 Row 模式记录修改的行记录。
3.2 Mixed 模式的优缺点
Mixed 模式综合了语句复制模式和行复制模式的优点,能够在大多数情况下高效地记录修改操作,并在需要时使用行复制模式确保数据的准确性。
但 Mixed 模式对一些特殊操作的处理可能会很复杂,需要特别注意下配置和管理。
我们来测试下没有主键的情况下,从库复制延时情况:
主库:创建无主键的表log_test然后用存储过程插入4000000行数据:
delimiter //
drop procedure if exists insert_log_test;
create procedure insert_log_test()
begin
declare i int;
set i = 0;
start transaction;
while i < 1000000 do
insert into log_test values (i,'中间提交的事务+++++++++**********++++++++');
insert into log_test values (i,'中间提交的事务+++++++++**********++++++++');
insert into log_test values (i,'中间提交的事务+++++++++**********++++++++');
insert into log_test values (i,'中间提交的事务+++++++++**********++++++++');
set i = i + 1;
end while;
commit;
end//
delimiter ;
mysql> call insert_log_test();
Query OK, 0 rows affected (1 min 17.62 sec)
mysql> select count(*) from log_test;
+----------+
| count(*) |
+----------+
| 4000000 |
+----------+
1 row in set (2.10 sec)
mysql> update log_test set id=id+80000000;
Query OK, 4000000 rows affected (17.84 sec)
Rows matched: 4000000 Changed: 4000000 Warnings: 0
备库:可以看到Seconds_Behind_Master一直在增大
[root@localhost:mytest1]>show slave status\G;
Exec_Master_Log_Pos: 1012007859
Relay_Log_Space: 1453954904
Seconds_Behind_Master: 431
可以看到5分钟的时间,更新了不到10000行数据,追平主库需要大概5分钟*400=20000分钟=330小时=14天。。。。。
[root@localhost:mytest1]>select now();
+---------------------+
| now() |
+---------------------+
| 2023-09-11 16:13:38 |
+---------------------+
1 row in set (0.00 sec)
[root@localhost:mytest1]>select count(*) from log_test where id>80000000;
+----------+
| count(*) |
+----------+
| 39629 |
+----------+
1 row in set (2.59 sec)
[root@localhost:mytest1]>select now();
+---------------------+
| now() |
+---------------------+
| 2023-09-11 16:18:38 |
+---------------------+
1 row in set (0.00 sec)
[root@localhost:mytest1]>select count(*) from log_test where id>80000000;
+----------+
| count(*) |
+----------+
| 48282 |
+----------+
1 row in set (2.29 sec)
那存在主键,只存在普通索引和无任何索引三种情况,延时的不同以及原理是什么呢?
那存在主键,只存在普通索引和无任何索引三种情况,延时的不同以及原理是什么呢?
1)只存在普通索引:
从库应用的时候会重新评估应该使用哪个索引,优先使用主键和唯一键。因为表只有一个普通索引key,对于Event中的每条数据都需要进行索引定位操作,并且对于非唯一索引来讲第一次返回的第一行数据可能并不是删除的数据,可能还需要继续扫描下一行。大概的流程如图:
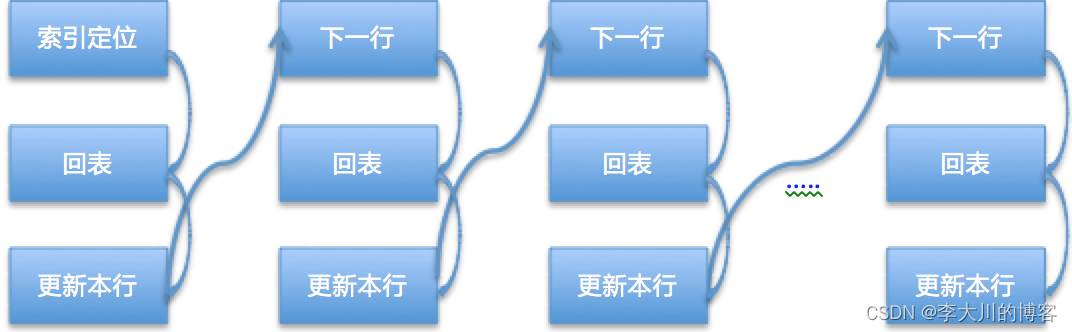
2)存在主键:
主库执行时会首先利用主键,只需要一次索引定位,然后顺序扫描接下来的数据进行更新就可以了。大概的流程如图:
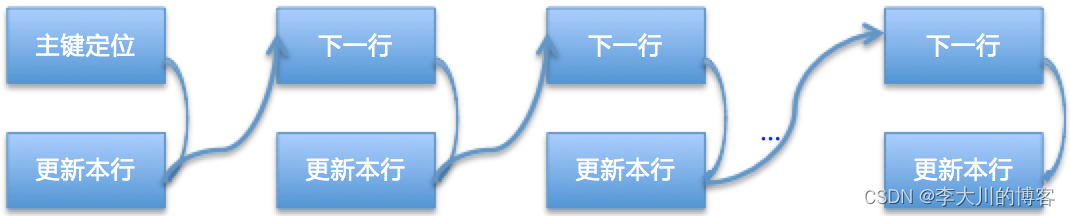
3)不存在任何索引
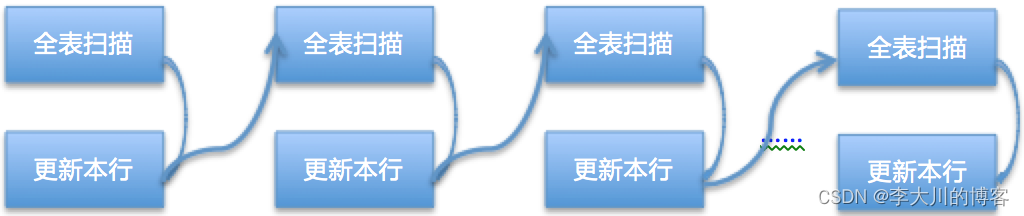
如果表上一个索引都没有的话,从库执行的每个event都要进行全表扫描,代价非常大,这也是表上没有索引从库会有比较大同步延迟的关键原因。大概的流程图:
我们来实际测试一下,存在主键的情况下,从库追日志的性能提高多少,测试结果:等主库Update完成后,立即在从库查询,就发现已经追平了,由此可见主键的对提升性能的重要性。
主:
delimiter //
drop procedure if exists insert_log_test;
create procedure insert_log_test()
begin
declare i int;
set i = 0;
start transaction;
while i < 1000000 do
insert into log_test_new values (default,i,'中间提交的事务+++++++++**********++++++++');
insert into log_test_new values (default,i,'中间提交的事务+++++++++**********++++++++');
insert into log_test_new values (default,i,'中间提交的事务+++++++++**********++++++++');
insert into log_test_new values (default,i,'中间提交的事务+++++++++**********++++++++');
set i = i + 1;
end while;
commit;
end//
delimiter ;
mysql> create table log_test_new(id_primary INT PRIMARY KEY AUTO_INCREMENT,id int,name VARCHAR(100));
Query OK, 0 rows affected (0.01 sec)
mysql> source /home/mysql/liys/insert_log_test.sql;
Query OK, 0 rows affected (0.01 sec)
Query OK, 0 rows affected (0.01 sec)
mysql> call insert_log_test();
Query OK, 0 rows affected (1 min 18.90 sec)
update log_test_new set id=id+80000000;
从:从库很快就追平了日志,等主库Update完成后,立即在从库查询,就发现已经追平了,由此可见主键的对提升性能的重要性。
[root@localhost:mytest1]>select count(*) from log_test_new where id>=80000000;
+----------+
| count(*) |
+----------+
| 4000000 |
+----------+
1 row in set (1.45 sec)
[root@localhost:mytest1]>select * from log_test_new where id=80000000;
+------------+----------+--------------------------------------------------+
| id_primary | id | name |
+------------+----------+--------------------------------------------------+
| 1 | 80000000 | 中间提交的事务+++++++++**********++++++++ |
| 2 | 80000000 | 中间提交的事务+++++++++**********++++++++ |
| 3 | 80000000 | 中间提交的事务+++++++++**********++++++++ |
| 4 | 80000000 | 中间提交的事务+++++++++**********++++++++ |
+------------+----------+--------------------------------------------------+
4 rows in set (1.67 sec)