HBase必知必会理论基础篇
- 1.1 HBase简介
- 1.2 HBase 数据模型
- 1.3 HBase整体架构
- 1.4 HBase 读写流程
- 1.4.1 客户端读取流程
- 1.4.2 客户端写入流程
- 1.5 HBase 客户端常用的方法
- 1.5.1 scan查询
- 1.5.2 get查询
- 1.5.3 put查询
- 1.5.4 delete 查询
- 1.5.5 append 查询
- 1.5.6 increment查询
- 1.6 HBase 过滤器以及协处理器
- 1.6.1 过滤器
- 1.6.2 协处理器
- 1.7 表设计原则
1.1 HBase简介
- HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。
- 它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务,可以存储海量稀疏的数据,并具备一定的容错性、高可靠性及伸缩性。
主要应用场景是实时随机读写超大规模的数据。
hbase特点
- 面向列存储,表结构比较灵活,支持多版本。
- 数据强一致
- 可扩展性高。
- 实时的读/写操作
- 支持单行事务(单row的事务,默认会加行锁)
- 只支持rowkey、rowkey范围查询
- 故障转移
- …
与传统关系数据库相比优点:
1.多版本数据:可以查询存储变动的历史数据
2.数据灵活度:mysql有多少列是固定的,增加null的列会浪费存储空间,hbase为null的column不会被存储,节省空间提 高性能
3.超大数据量
4.自动分区:数据自动切分数据,使得数据存储自动具有水平可扩展性
5.良好扩容
与传统关系数据库相比缺点:
1.不能灵活根据条件查询
2.没有强大关系,事务等
1.2 HBase 数据模型
| 专业术语 | 解释 |
|---|---|
| Table | 有多行组成的hbase表 |
| Raw | HBase中的行里面包含一个key和一个或者多个包含值的列。行按照行的key字母顺序存储在表格中。因为 这个原因,行的key的设计就显得非常重要。数据的存储目标是相近的数据存储到一起。 |
| Column | HBase中的列包含用:分隔开的列族和列的限定符。 |
| Column Family | 因为性能的原因,列族物理上包含一组列和它们的值。每一个列族拥有一系列的存储属性,例如值是否缓存在内存中,数据是否要压缩或者他的行key是否要加密等等。表格中的每一行拥有相同的列族,尽管一个给定的行可能没有存储任何数据在一个给定的列族中 |
| Column Qualifier | 列的限定符是列族中数据的索引。例如给定了一个列族content,那么限定符可能是content:html,也可以是content:pdf。列族在创建表格时是确定的了,但是列的限定符是动态地并且行与行之间的差别也可能是非常大的。 |
| Cell | 单元是由行、列族、列限定符、值和代表值版本的时间戳组成的。 |
| Timestamp | 时间戳是写在值旁边的一个用于区分值的版本的数据。默认情况下,时间戳表示的是当数据写入时RegionSever的时间点,但你也可以在写入数据时指定一个不同的时间戳 |
| 结果排序 | 针对查询结果排序:Row->ColumnFamily->Column qualifier-> timestamp(时间倒序,时间最新最先返回) |
1.3 HBase整体架构
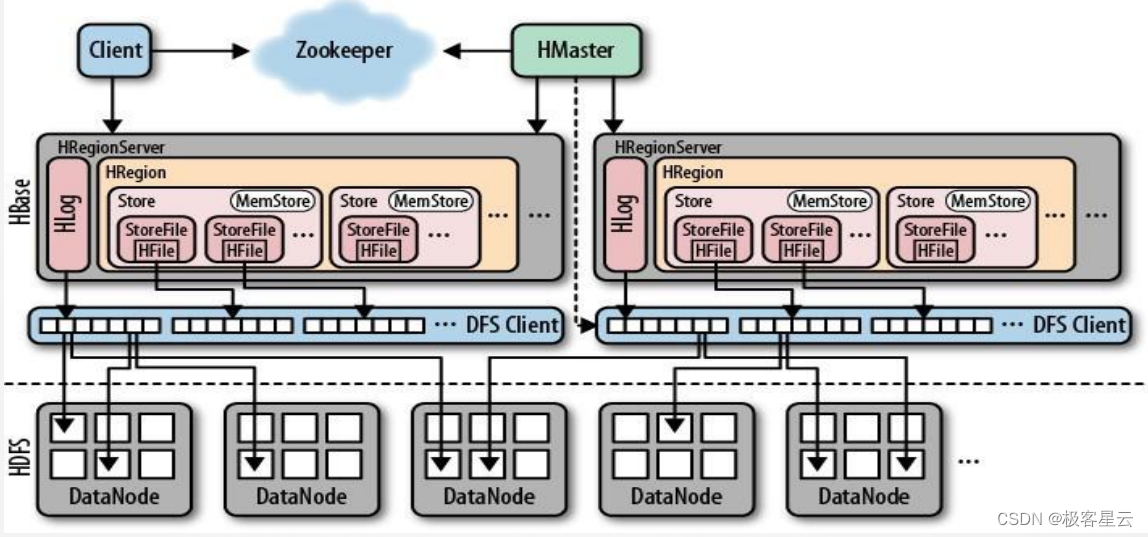
1.4 HBase 读写流程
1.4.1 客户端读取流程
- 客户端首先根据配置信息连接zookeeper集群,读取zookeeper节点上的meta表的位置信息
- client向meta表的region所在的regionserver发起访问,读取meta表的数据,获取hbase集群 上所有表的元数据(当meta信息变化,客户端根据缓存meta信息请求发生异常,会重新加载一份 新的元数据到本地)
- 根据meta表元数据(查询region数,region分布以及region的startkey,stopkey),找到要查 询rowkey数据所在的region分布
- client向regionserver发起读请求访问
- regionserver接到读请求访问,会先扫描memstore写缓存数据,再扫描blockcache读缓存, 若果没有找到数据再去读取storefile中的数据(优先查询本地副本文件)
- regionserver将查询到的结果返回给client
1.4.2 客户端写入流程
- put/delete操作,客户端根据meta信息找到对应的regionserver,然后提交请求。
- 服务器接受到请求,反序列为对应对象,执行操作检查:region是否只读,memstore大小是否
超过blockingMemstoreSize,检查完成执行如下操作
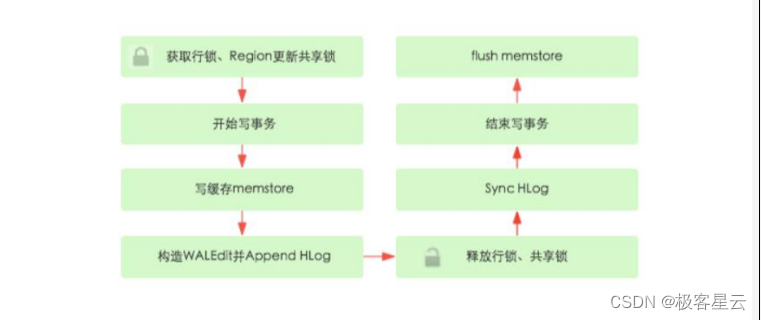
HBase - 数据写入流程解析
1.5 HBase 客户端常用的方法
1.5.1 scan查询
Scan scan= new Scan();
scan.setStartRow(Bytes.toBytes("4"));
scan.setStopRow(Bytes.toBytes("4~"));
scan.setTimeRange(1510735857892L, 1511403550619L);
scan.setCaching(1);//设置一次rpc请求批量读取的Results数量
scan.setBatch(5);//设置返回数据的最大行数
scan.setMaxVersions();//查询列的全部版本
scan.setReversed(true);//默认false,正向查找,若为true则逆向扫描
scan.setCacheBlocks(true);//默认true,查询结果可以缓存到服务器内存
scan.setSmall(false); //64kb以内小范围scan设置为true效果更好,默认false
scan.setFilter(new RowFilter(CompareOp.EQUAL,new BinaryPrefixComparator("4".getBytes())));//设置过滤器
ResultScanner resultScan=table.getScanner(scan);
- hbase scan客户端服务端流程
1.5.2 get查询
Get get=new Get(Bytes.toBytes("1fb7fe0047771222975dfb94fdede2fc"));
get.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("20171115#5000491#100081"));
get.setMaxVersions();
get.setFilter(new ColumnPrefixFilter(Bytes.toBytes("20171115")));
get.setMaxResultsPerColumnFamily(1);//设置每行每个列簇返回的最大条数
get.setTimeRange(1510735857899L,1511403550618L);
Result result=table.get(get);
// 支持Get的批量list执行
List<Get> gets=new ArrayList<Get>();
gets.add(new Get(Bytes.toBytes("1fb7fe0047771222975dfb94fdede2fc")));
gets.add(new Get(Bytes.toBytes("44e29606bcc7332abc8b4ffe3a7c70a6")));
Result[] results=table.get(gets);
1.5.3 put查询
Put put=new Put(Bytes.toBytes("4cdf47795d51dae263b2dd3bca9381b8"));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("20181208#5000491#100084"),System.currentTimeMillis(), Bytes.toBytes("1"));
put.setTTL(10000L);//设置result的过期时间
put.setWriteToWAL(true);//控制写入是否写hlog日志
table.put(put);
// 支持批量put
table.puts(puts)
1.5.4 delete 查询
Delete delete=new Delete(Bytes.toBytes("1fb7fe0047771222975dfb94fdede2fc"));
delete.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("20171116#5000491#100081"), 1511403550618L);
delete.addColumns(Bytes.toBytes("cf"), Bytes.toBytes("20171123#5000491#100084"), 1511403550618L);
delete.setWriteToWAL(true);
table.delete(delete);
支持批量delete
table.delete(deletes);
1.5.5 append 查询
table=HbaseClient.getInstance().getHtable("ApplyLoan_Detail");
Append append=new Append(Bytes.toBytes("1fb7fe0047771222975dfb94fdede2fc"));//value值中追加内容
append.add(Bytes.toBytes("cf"), Bytes.toBytes("20171115#5000491#100081"), Bytes.toBytes("9"));
append.setTTL(10000L);//针对当前result设置失效时间
append.setWriteToWAL(true);
table.append(append);
1.5.6 increment查询
Increment increment=new Increment(Bytes.toBytes("4cdf47795d51dae263b2dd3bca9381b5"));
increment.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("incr"), 10);
increment.setTTL(10000L);
increment.setTimeRange(1510735857892L, 1546070521593L);
increment.setWriteToWAL(true);
1.6 HBase 过滤器以及协处理器
1.6.1 过滤器
- RowFilter,FamliyFilter,QualifierFilter,ValueFilter :行键过滤器,列簇过滤器,列过滤器,值过滤器
- TimestampsFilter:时间过滤器
- SingleColumnValueFilter:单列值过滤器,用一列的值决定这一行的数据是否被过滤,支持一些正则,比
较之类的比较器操作,可与下面四个比较器一起使用:
-
RegexStringComparator:支持正则表达式的值比较
-
SubstringComparator : 用于监测一个子串是否存在于值中,并且不区分大小写
-
BinaryPrefixComparator : 前缀二进制比较器。与二进制比较器不同的是,只比较前缀是否相同。
-
BinaryComparator : 二进制比较器,用于按字典顺序比较 Byte 数据值
-
SingleColumnValueExcludeFilter :单列值排除器
-
PrefixFilter:前缀过滤器,针对行键,筛选出具有特定前缀的行键的数据
-
ColumnPrefixFilter:列前缀过滤器
-
PageFilter:分页过滤器,用在region上,只能保证当前region返回相应的数量,也可以理解为每次数据量=region数量
*pageNum -
KeyOnlyFilter:这个过滤器唯一的功能就是只返回每行的行键,值全部为空,这对于只关注于行键的应用场景来说非常合
适,这样忽略掉其值就可以减少传递到客户端的数据量,能起到一定的优化作用 -
FilterList:多个filter过滤器可以通过进行控制,FilterList.Operator.MUST_PASS_ALL 或者
-
FilterList.Operator.MUST_PASS_ONE控制满足条件
具体处理器详见官网:https://hbase.apache.org/1.2/book.html#thrift.filter_language
1.6.2 协处理器
- 协处理器
HBase作为列式数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。
协处理器是HBase让用户的部分逻辑在数据存放端即HBase服务端进行计算的机制,它允许用户在HBase服务端运行自己
的代码。通过协处理器可以比较容易的实现能够轻易建立二次索引、复杂过滤器以及访问控制等。
协处理器分成两种类型:一个是观察者(Observer),类似于关系数据库的触发器。另一个是终端(Endpoint),动态的
终端有点像存储过程。
-
observer
- 实现自定义observer,根据要监听事件的不同,实现以下不同的observer。
- RegionObserver:观察客户端更新数据操作:Get、Put、Delete等。一般通过继承BaseRegionObserver实现。
- RegionServerObserver:监听regionserver的启动、停止、region合并、split。一般通过继承
- BaseMasterAndRegionObserver实现。
- MasterOvserver:监听表创建、修改、分配region操作。一般通过继承BaseMasterAndRegionObserver实现。
- WalObserver: 监听WAL日志的写入。一般通过继承BaseWALObserver实现。
-
Endpoint
Endpoint是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供
了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端。一般可用于计数、求和等聚合方法。
- 自定义Endpoint
1.编写接口定义proto文件
2.编译proto文件,生成java代码
3.继承CoprocessorService 、自定义service,实现自定义逻辑
- 官方文档:https://hbase.apache.org/1.2/book.html#_coprocessor_overview
- 中文样例:https://www.cnblogs.com/frankdeng/p/9310340.html
- 使用示例:http://blog.csdn.net/carl810224/article/details/52224441
1.7 表设计原则
表模式经验原则:
region 大小在10-50G之间
cell 不大于10MB,如果是mob不让大小超过50MB,否则就考虑将单元数据放到hdfs,将数据的存储指针存到hbase中
每个表的列簇最好在1-3之间,尽可能保持1个最好(原因:数据不均,major造成不必要的io,scan数据量较小的 columnFamily效率会低)
对于一个有1个或2个列族的表来说,region数在50到100左右是一个很好的数字。记住一个region是一个列族的一个连 续分段
列簇尽可能短(每个value都会存储对应的列簇)
如果仅有1个列族忙着写,则只有那个列族在占用越来越多的内存。在分配资源时要注意写模式
保证对写和查询不引起热点数据问题,对rowkey进行hash
尽量减少rowkey和column的大小,rowkey最大长度64kb
倒序时间戳:数据处理找最近时间版本,可设计key如下:key+(Long.MAX_VALUE-timestamp)
预分区:建表提前创建预分区,避免自动split,提升性能
版本:对列簇可单独设置版本,默认1个版本,不建议最大版本设置很大(成百或者更多),除非历史数据特别重要 最小版本数缺省值是0,表示该特性禁用
TTL:针对无用版本进行删除操作,作用在列簇上,客户端也可以设置单元格TTL,但是一个单元TTLs不能延长一个单元 的有效生命周期到超出了一个列的级别TTL设置。禁用:设置hbase.store.delete.expired.storefile为false可以禁用这个功
能,设置最小版本数为0以外的值也可以禁用此功能压缩算法:对于对查询速度要求比较高的,可使用snappy。对应离线数据,追求高压缩率的可使用lzo。
bloomfilter:用于提高随机读(Get)的性能,对于顺序读(Scan)而言,bloomfilter没有什么作用.bloomfilter主要用
于过滤要查询storefile文件。blocksize:请求以Get请求为主,可以考虑将块大小设置较小;如果以Scan请求为主,可以将块大小调大;
每个regionserver上面最好20-200个5-20Gb的region,100个region效果最好
- 英文版:https://hbase.apache.org/1.2/book.html#table_schema_rules_of_thumb
- 中文对应:https://www.cnblogs.com/sunspeedzy/p/7501825.html








![【Flutter】引入网络图片时,提示:Failed host lookup: ‘[图片host]‘](https://img-blog.csdnimg.cn/img_convert/598930c90963d9f6bff62257d937d0b8.png)