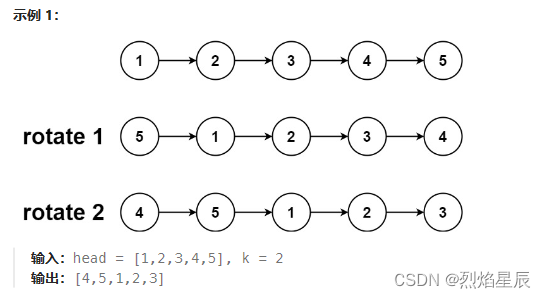
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
小屋里面一直在输出关于数据科学领域的文章,绝大部分都是基于Python,少量的MySQL(MySQL存储数据用)。本文重点给大家介绍Python中科学领域常用的20个库。
数据科学首选Python
Python是当今使用最广泛的编程语言,其在数据科学领域表现出色,原因主要有以下几点:
- 易学易用:Python是一种非常容易学习和使用的编程语言,它的语法简单清晰,对于初学者来说非常友好。同时,Python还有大量的库和框架可供使用,使得在Python中进行数据科学工作变得相对简单。
- 强大的数据处理能力:Python有很多库可以用来处理和分析大量数据,例如Pandas和NumPy,它们可以用来处理数据清洗、转换、统计分析等任务。此外,Python还有许多其他库,如Scikit-learn和TensorFlow等,可以用来建立和训练机器学习模型。
- 数据可视化:Python有很多库可以用来创建高质量的数据可视化,例如Matplotlib和Seaborn。这些库可以用来创建各种类型的图表和图形,从简单的条形图和散点图到复杂的热力图和3D图形等。
- 高效的并行计算:Python可以通过使用多线程、多进程或分布式计算框架来提高计算效率,从而更快地完成数据科学任务。
- 广泛的社区支持:Python有一个非常活跃的社区,有许多专家和爱好者在使用Python进行数据科学方面的研究和实践。这意味着在使用Python进行数据科学工作时,可以方便地找到大量的教程、示例代码和问题解答。
- 与其他工具集成:Python可以很容易地与其他工具集成,例如与SQL数据库交互、与R语言集成等。这使得Python在数据科学领域更加灵活和通用。
小编带领大家快速认识下20个最适合数据科学的Python库,它们主要涉及:数值计算、数据预处理、数据可视化、机器学习建模、深度学习建模、模型可解释性等:
- NumPy
- SciPy
- Pandas
- Matplotlib
- SciKit-Learn
- TensorFlow
- Keras
- PyTorch
- Scrapy
- BeautifulSoup
- LightGBM
- plolty
- ELI5
- Theano
- NuPIC
- Ramp
- Bob
- PyBrain
- Caffe2
- Chainer
1、SciPy
SciPy(Scientific Python)是一个免费和开源的Python库,用于数据科学,广泛用于高级计算。它广泛用于科学和技术计算,因为它扩展了NumPy,并为科学计算提供了许多用户友好且高效的例程。

特点:
- 建立在Python的NumPy扩展上的算法和功能集合
- 用于数据操作和可视化的高级命令
- 使用SciPy ndimage子模块进行多维图像处理
- 包括用于解决微分方程的内置函数
主要应用:
- 多维图像操作
- 解决微分方程和傅里叶变换
- 优化算法
- 线性代数、积分、插值等
2、Numpy
NumPy(Numeric Python)是Python中用于数值计算的基本软件包;它包含一个功能强大的N维数组对象。
NumPy的由来可以追溯到Python语言的一个扩展程序库,即Numeric,它代表“Numeric Python”。Numeric最早是由Jim Hugunin与其它协作者共同开发的。2005年,Travis Oliphant在Numeric中结合了另一个同性质的程序库Numarray的特色,并加入了其它扩展而开发了NumPy。
它是一个通用的数组处理软件包,提供高性能的多维数组对象(称为数组)以及用于处理它们的工具。NumPy还通过提供这些多维数组以及提供在这些数组上高效操作的函数和运算符来解决速度慢的问题。

特点:
- 提供快速、预先编译的数值函数
- 面向数组的计算以获得更好的效率
- 支持面向对象的方法
- 通过向量化进行紧凑和更快的计算
主要应用:
- 在数据分析中广泛使用
- 创建功能强大的N维数组
- 形成其他库(如SciPy和scikit-learn)的基础
- 与SciPy和matplotlib一起使用时可以替代MATLAB
3、Pandas
Pandas的名字来自于面板数据(panel data)和数据分析(data analysis)库。它是数据科学领域最流行和广泛使用的Python库之一,与NumPy和matplotlib一起使用,一起被称之为"数据分析三剑客"。
它在GitHub上有大约1700条评论和一个由1200个贡献者组成的活跃社区,主要用于数据分析和清理。Pandas提供快速、灵活的数据结构,例如数据帧,旨在非常轻松直观地处理结构化数据。

主要特点:
- 流利的语法和丰富的功能让您自由处理缺失数据
- 可以在一系列数据上创建自己的函数并运行它
- 高层次对象的应用:包含高层次的数据结构和操作工具
主要应用:
- 一般数据整理和数据清理
- ETL(提取、转换、加载)作业用于数据转换和数据存储,因为它很好地支持将CSV文件加载到其数据帧格式中
- 在各种学术和商业领域中使用,包括统计、金融和神经科学
- 时间序列特定功能,例如日期范围生成、移动窗口、线性回归和日期偏移
4、matplotlib
Matplotlib拥有功能强大且美观的可视化效果。它是最为广泛使用的Python静态绘图库。因为它产生的图形和图表,它被广泛应用于数据可视化。它还提供了一个面向对象的API,可以用来将这些图形嵌入到应用程序中。

特点:
- 可以作为MATLAB的替代品使用,具有免费和开源的优点
- 支持数十种后端和输出类型
- Pandas本身可以用作包装器,以驱动MATLAB API,使其更简洁
- 低内存消耗和更好的运行时性能
主要应用:
- 变量相关分析
- 可视化模型的95%置信区间
- 散点图等的异常检测
- 可视化数据分布以获得即时洞察力
5、Scikit-Learn
最为经典的机器学习库,几乎提供了所有用户需要的机器学习算法。Scikit-learn旨在融入NumPy和SciPy中。

主要应用:
- 聚类分群
- 分类
- 回归预测
- 模型选择
- 数据降维

6、TensorFlow
TensorFlow是Google开发的一个基于数据流图的开源机器学习框架。它支持多种机器学习和深度学习算法,包括神经网络、卷积神经网络、循环神经网络等,被广泛应用于语音识别、图像识别等多项机器学习和深度学习领域。

特点:
- 更好的计算图形可视化
- 并行计算以执行复杂模型
- 由Google支持的无缝库管理
- 更快的更新和频繁的新版本以提供最新的功能
TensorFlow对于以下应用特别有用:
- 语音和图像识别
- 基于文本的应用
- 时间序列分析
- 视频检测
7、Keras
Keras类似于TensorFlow,是另一个广泛用于深度学习和神经网络模块的流行库。Keras支持TensorFlow和Theano后端,因此如果您不想深入了解TensorFlow的细节,Keras是一个不错的选择。

主要特点:
- Keras提供大量预先标记的数据集,可直接导入和加载
- 它包含各种已实现的层和参数,可用于神经网络的构建、配置、训练和评估
应用:
Keras最重要的应用之一是深度学习模型,这些模型提供预训练权重。您可以直接使用这些模型进行预测或提取其特征,而无需创建或训练自己的新模型。
8、PyTorch
PyTorch是一个开源的机器学习框架,基于Torch库,主要用于计算机视觉和自然语言处理等领域的应用。由于其优秀的灵活性和速度,PyTorch已在全球范围内广受数据科学家和研究者的欢迎,成为深度学习研究和应用的首选框架之一。

PyTorch的主要特点和优点包括:
- 动态计算图:PyTorch的动态计算图是其最显著的特点之一,这使得其能更高效、快速地进行模型训练和优化。与TensorFlow等其他框架不同,PyTorch的计算图是动态更新的,这意味着PyTorch的计算图可以根据实际需要进行添加、删除和修改操作。这大大提高了模型的灵活性和可操作性。
- 易于学习和使用:PyTorch采用了Python语言进行开发,这意味着如果你熟悉Python,就可以很快上手。此外,PyTorch的文档也非常完善,社区支持和贡献也非常活跃,对新手更加友好。
- 良好的可视化和调试功能:PyTorch提供了非常便捷的可视化和调试功能,使开发者可以轻松地实现网络训练和模型调优。同时,PyTorch还支持命令式编程,这意味着开发者可以逐行调试代码,并且直接查看变量和梯度。
- 支持多设备:PyTorch支持GPU加速,并且可以使用不同的GPU进行并行计算,这大大提高了模型训练和优化的效率,尤其对于计算量非常大的深度学习任务尤为重要。
PyTorch的应用非常广泛,包括但不限于以下几个方面:
- 计算机视觉:PyTorch在计算机视觉领域有广泛的应用,例如图像识别、目标检测、人脸识别等。一些知名的计算机视觉项目,如Facebook的DeepFace和OpenCV的深度学习模块,都是使用PyTorch开发的。
- 自然语言处理:PyTorch也广泛应用于自然语言处理领域,包括文本分类、情感分析、机器翻译等。许多自然语言处理库和框架,如Facebook的fastText和苹果的Siri,都是使用PyTorch构建的。
- 强化学习:由于PyTorch具有动态计算图和高效的GPU加速功能,它也被广泛应用于强化学习领域。一些知名的强化学习算法,如OpenAI的GPT-2和DeepMind的AlphaGo,都是使用PyTorch实现的。
- 生成模型:PyTorch在生成模型领域也有广泛的应用,如GAN、VAE和变分自编码器等。许多知名的生成模型项目,如DALL-E和GPT-3,都是使用PyTorch训练和实现的。

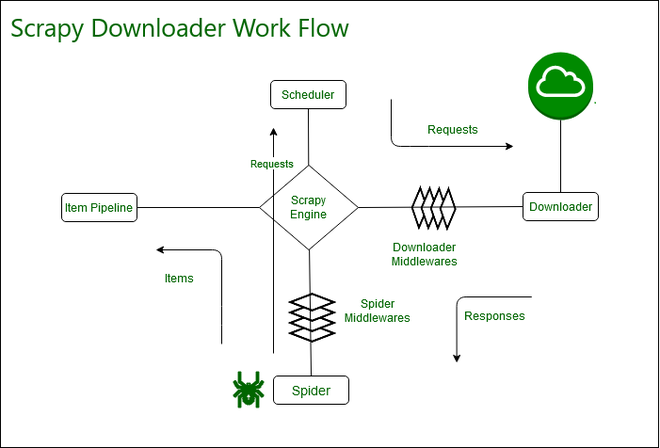
9、Scrapy
Scrapy是一个用于Python的快速、高层次的屏幕抓取和Web抓取框架,主要用于抓取Web站点并从页面中提取结构化的数据。
它被设计为一个框架,可以根据需求方便地进行修改,因此,它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,甚至最新版本提供了web2.0爬虫的支持。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试等,它也可以用来访问API来提取数据。

Scrapy的主要特点如下:
- 快速:Scrapy框架运行速度快,可以快速地爬取和解析网页。
- 高层次:Scrapy使用Python语言编写,易于理解和使用,同时它还提供了丰富的API和中间件,方便用户进行定制化开发。
- 灵活性:Scrapy框架可以轻松实现各种类型的爬虫,无论是针对单个网站的爬虫,还是跨多个站点的爬虫,都可以轻松实现。
- 数据结构化:Scrapy可以将爬取到的数据存储在JSON、CSV或其他格式中,方便用户进行数据分析和处理。
- 可扩展性:Scrapy框架支持插件机制,用户可以通过编写插件来扩展其功能,使其更加灵活和高效。
Scrapy的应用非常广泛,例如:
- 数据挖掘:可以通过Scrapy框架爬取和分析大量的网页数据,从中提取有用的信息,用于商业智能、市场分析等领域。
- 信息处理:可以通过Scrapy框架爬取互联网上的信息,并进行整理、归类和存档,以便后续检索和分析。
- 历史数据存储:可以通过Scrapy框架将历史数据爬取并存储到数据库中,方便后续的数据分析和可视化等工作。
- 自动化测试:可以通过Scrapy框架爬取测试数据,并自动化执行测试脚本,提高测试效率和准确性。
主要的流程图:
10、BeautifulSoup
Beautiful Soup是一个Python库,用于从网页中提取和操作数据。它具有以下特点:
- 简单易用:Beautiful Soup提供了简单的API和python式函数,使得从网页中提取数据变得非常容易。不需要编写复杂的正则表达式,使得使用起来更加方便。
- 支持多种解析器:Beautiful Soup支持多种解析器,如Python的内置解析器和第三方解析器(如lxml和html5lib),可以根据需要选择合适的解析器,适应不同的解析需求。
- 强大的搜索功能:Beautiful Soup提供了灵活而强大的搜索功能,可以根据标签、属性等进行定位和提取信息。它也提供了简单的CSS选择器,使得使用CSS选择器来查找元素更加简单。
- 自动编码转换:Beautiful Soup会自动将转入稳定转换为Unicode编码,输出文档转换为UTF-8编码,使用户不需要考虑编码问题,除非文档没有指定编码方式,这时只需要指定原始编码即可。
- 支持HTML和XML:Beautiful Soup可以用于解析HTML和XML文件,使得从这两种格式的网页中提取数据变得更加简单。
应用方面,Beautiful Soup可以用于网页爬取、数据提取、数据分析、自动化测试等多种场景。它使得从网页中提取结构化数据变得更加简单,可以轻松地爬取网页中的数据并进行分析和处理。同时,Beautiful Soup也支持通过代理进行爬取,可以轻松实现分布式爬取等高级功能。

11、LightGBM
LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升决策树(GBDT)算法的分布式梯度提升框架,由微软DMTK团队于2017年开源。它在传统机器学习算法中属于对真实分布拟合的最好的算法之一,被广泛应用于分类与回归比赛,也是工业界中常用的模型之一。

相较于传统的GBDT算法,LightGBM主要解决了GBDT在处理海量数据时遇到的问题,使其可以更快、更有效地应用于工业实践。具体来说,LightGBM通过采用高效的数据结构和分布式计算策略,实现了高效率的并行训练和更低的内存消耗,同时支持快速处理海量数据。
在模型训练方面,LightGBM采用了一种基于叶子节点生长的梯度提升决策树算法,通过迭代地训练弱分类器并组合多个弱分类器,最终得到一个强分类器。每个叶子节点都是一个弱分类器,通过对数据的拟合残差进行分析和优化,不断生长出新的决策树,直到达到预设的迭代次数或收敛条件。
此外,LightGBM还具有多种实用功能和优点。例如,它可以轻松地与其他机器学习算法集成,支持多分类和二分类任务,并且具有很好的可扩展性和稳定性。在竞赛和实际应用中,LightGBM也表现出极佳的性能和准确率,成为了机器学习中一种非常受欢迎的算法。
总之,LightGBM是一种高效、可扩展、易用的梯度提升决策树算法,适用于各种机器学习任务,尤其是处理大规模数据集和工业界应用。
12、Plolty
Plotly是一个功能强大的Python可视化库,它提供了丰富的绘图类型和高度定制的选项,因此可以创建各种类型的交互式图表。然而,使用Plotly需要一定的编程经验和知识,因为它需要理解绘图对象、图形布局、坐标轴、颜色面板等概念。

Plotly_express是Plotly的一个高级封装,专门为复杂的图表提供了一个简单的语法。它通过简洁、一致且易于学习的API,使得用户可以仅通过一次导入就可以在一个函数调用中创建丰富的交互式绘图。这大大降低了使用Plotly的门槛,对于初学者和快速入门者来说非常友好。
对于使用过Seaborn和ggplot2等库的用户来说,Plotly_express的API风格可能会让人感到熟悉和舒适。它支持分面绘图(faceting)、地图、动画和趋势线等高级功能,同时也可以处理数据集、颜色面板和主题等选项。
13、ELI5
ELI5(Explain Like I’m Five,解释给五岁小孩听)是一个Python库,它可以帮助调试机器学习分类器并解释它们的预测。

它使机器学习模型更具可解释性,允许使用统一的API可视化和调试各种机器学习模型。它内置了对几种ML框架的支持,并提供了一种解释黑盒模型的方法。
特点:
- ELI5提供了一系列解释机器学习模型的技术,如特征重要性、排列重要性和SHAP值。
- ELI5提供了调试机器学习模型的工具,如可视化误分类的例子和检查模型的权重和偏差。
- ELI5可以生成人类可读的解释,解释模型是如何做出预测的,这可以帮助与非技术利益相关者进行沟通。
主要应用:
- 模型解释
- 模型调试
- 模型比较
- 特征工程
14、Theano
Theano是一个强大的Python库,被广泛用于深度学习和机器学习领域,特别是处理多维数组的数学表达式。

以下是关于Theano的更详细介绍:
- Theano的历史和背景:Theano起源于2007年,是为了支持深度学习框架而设计的,它是最早的深度学习框架之一。Theano的设计目的是为了解决深度学习中大规模人工神经网络算法的运算问题,它能够高效地在CPU和GPU上进行运算。
- Theano的特点:
- 与Numpy紧密集成:Theano使用了Numpy的ndarray对象进行操作,这使得在处理多维数组时非常高效。
- GPU的透明使用:Theano可以在GPU上运行计算,这使得处理大规模数据时速度更快。
- 高效的象征性差异:Theano提供高效的符号性差异功能,这使得我们能够对函数进行自动微分和优化。
- 优化和稳定性:Theano进行了大量的优化和稳定性测试,确保计算结果的正确性和可靠性。
- 动态C代码生成:Theano能够生成动态C代码,这使得计算速度更快。
- Theano的应用领域:Theano被广泛应用于许多领域,包括但不限于以下领域:
- 深度学习:作为深度学习框架的重要组成部分,Theano被广泛应用于深度神经网络的训练和推理。
- 机器学习:Theano也被广泛应用于各种机器学习算法的开发和优化。
- 数据科学:Theano可以帮助数据科学家进行数据分析和处理,以及构建复杂的数据分析模型。
- 科学计算:Theano还被广泛应用于科学计算领域,例如物理模拟、图像处理等领域。
- Theano的下载和使用:可以通过PyPI或conda等包管理工具来下载和使用Theano,也可以通过访问Theano的官方网站获取更多详细的使用说明和教程。
总的来说,Theano是一个功能强大、稳定可靠的Python库,它被广泛应用于深度学习、机器学习、数据科学和科学计算等领域,是这些领域中不可或缺的工具之一。
15、NuPIC
Numenta Platform for Intelligent Computing(NuPIC)是一种基于分层式即时记忆(HTM)理论的开源项目,由Numenta公司开发。HTM理论是关于大脑神经元如何处理和记忆信息的理论,NuPIC以此为基础来模拟大脑活动,进而实现智能化计算。

NuPIC可以应用于多种领域,如异常检测、预测、降维与模式识别等。它被设计为处理实时流数据,可以学习和响应不断输入的数据流,适用于实时应用。
NuPIC具有灵活和可扩展的网络API,使得开发者可以轻松地构建自定义的HTM网络,用于处理特定应用的任务。其应用实例包括图像识别和简单的预测等。
应用:
- 异常检测:NuPIC可以应用于异常检测任务,例如在网络安全、金融市场预测等领域中检测异常行为或事件。通过模拟大脑神经网络的行为,NuPIC可以学习和适应数据的正常模式,并在出现异常情况时及时地检测和响应。
- 预测:NuPIC的预测能力基于其HTM算法的学习和记忆能力。它可以处理时间序列数据,例如股票价格、气候变化等,并从中学习模式和趋势,然后进行未来趋势的预测。此外,NuPIC还可以应用于时间序列分析、时间序列预测、语音识别等任务。
- 降维与模式识别:NuPIC可以应用于降维和模式识别任务,例如在图像处理、语音识别和自然语言处理等领域中。通过模拟大脑的学习和记忆机制,NuPIC可以识别和理解数据中的复杂模式,并将其表示为更低维度的特征,从而加速处理速度并改善性能。
16、Ramp
Ramp是一个在Python语言下制定机器学习中加快原型设计的解决方案的库程序。它是一个轻型的pandas-based机器学习中可插入的框架,它现存的Python语言下的机器学习和统计工具(比如scikit-learn,rpy2等)Ramp提供了一个简单的声明性语法探索功能从而能够快速有效地实施算法和转换。

主要应用:
- 构建预测模型:Ramp是一个非常适合构建预测模型的Python库。它提供了一个简单易用的接口,使数据科学家和机器学习实践者可以快速地构建各种类型的预测模型,包括监督学习、无监督学习和深度学习模型等。
- 评估模型性能:Ramp还提供了一系列工具,帮助用户评估模型的性能。用户可以使用Ramp来比较不同模型的准确性、精确度和召回率等指标,从而选择最适合特定任务的模型。此外,Ramp还支持交叉验证和其他评估技术,以确保模型在未知数据上的性能。
- 团队合作与部署:Ramp的协作环境使得数据科学家和机器学习实践者可以更轻松地合作,共同构建和评估模型。这可以加速项目进展,提高模型质量,同时减少错误和浪费的时间。此外,Ramp还支持将模型部署到不同的环境中,例如本地服务器、云端或嵌入式设备上,从而扩大了模型的应用范围。
17、Bob
Bob是一个集成了多种Python数据科学库的集合,它提供了用于机器学习、计算机视觉和信号处理的各种工具和算法。

以下是对Bob的一些特点和应用的更详细介绍:
特点:
- 数据读写灵活性:Bob支持多种数据格式的读取和写入,包括音频、图像、视频等。这使得在使用Bob进行数据处理时,可以具有很高的灵活性和便利性。无论是从不同格式的数据源中读取数据,还是将处理后的数据保存为不同的格式,Bob都提供了简单易用的接口。
- 预置算法和模型:Bob包含了多种预置的算法和模型,如面部识别、说话者验证和情绪识别等。这些算法和模型都是经过优化的,可以直接在各种应用中使用。这也使得开发者可以更快速地开展相关任务,而无需从头开始实现这些算法。
- 模块化和可扩展性:Bob被设计成模块化和可扩展的架构,这意味着开发者可以根据自己的需要,轻松地添加新的算法和模型。这种设计方式也使得Bob能够适应不同的应用场景,并且方便用户根据自身需求进行定制。
应用:
- 面部识别:Bob提供了一系列的面部识别算法和工具,可以用于各种面部识别相关的任务。无论是基于传统的人脸检测算法,还是基于深度学习的人脸识别方法,Bob都提供了相应的工具和接口。同时,Bob还提供了面部特征提取的工具,可以用于面部比对、面部跟踪等应用。
- 说话者验证:Bob包含了多种说话者验证的算法和模型,可以用于验证说话者的身份。这种技术在安全监控、语音助手、人机交互等领域都有广泛的应用。通过使用Bob提供的工具和接口,开发者可以轻松地实现说话者验证的功能。
- 情绪识别:Bob提供了情绪识别的算法和模型,可以用于从语音、文本或面部表情中识别出情绪。这种技术在人机交互、社交媒体分析、心理学研究等领域都有广泛的应用。通过使用Bob提供的工具和接口,开发者可以轻松地实现情绪识别的功能。
- 生物特征认证:Bob的面部识别、说话者验证和情绪识别等功能可以联合使用,实现一种生物特征认证的方法。这种方法基于每个人的生物特征是独一无二的这一原理,可以用于身份验证和安全控制等场景。通过Bob集成的各种功能,能够更加准确地进行个体识别和验证,提高了认证的安全性和可靠性。
18、PyBrain
PyBrain确实是一个功能强大的Python机器学习库,它提供了许多工具和算法来构建和训练神经网络,适用于多种机器学习任务。

您提到了一些PyBrain的特点和应用领域,以下是您提到的内容的一些简要概述:
特点:
- 灵活且可扩展的架构:PyBrain的架构设计得非常灵活,易于扩展,允许用户轻松地构建和定制神经网络模型。这意味着用户可以根据自己的需求轻松地创建和修改模型,而无需过多地修改框架本身。
- 广泛的算法支持:PyBrain提供了多种算法来支持各种机器学习任务,包括监督学习、无监督学习和强化学习等。例如,它支持前馈神经网络、循环神经网络、支持向量机和强化学习等算法,可以满足不同类型任务的需求。
- 可视化工具:PyBrain包括一些工具,可以用于可视化神经网络的性能和结构,使得用户可以更轻松地理解和调试自己的模型。这种可视化功能可以帮助用户更好地理解模型的运行情况,以及如何改进模型的性能。
应用领域:
- 模式识别:PyBrain可以用于构建和训练神经网络模型,以识别和分析各种模式。例如,可以使用PyBrain来识别图像中的物体、识别语音、分析文本等等。
- 时间序列预测:PyBrain还可以用于时间序列预测任务,例如预测股票价格、气候变化等等。通过使用神经网络模型,可以学习历史数据的模式,并用于预测未来的趋势。
- 强化学习:PyBrain支持强化学习算法,可以用于构建智能控制系统和自主决策系统等。例如,可以使用PyBrain来训练一个自动驾驶汽车控制系统,使其能够根据环境信息自主决策如何行驶。
- 自然语言处理:PyBrain还可以用于自然语言处理任务,例如文本分类、情感分析、机器翻译等等。通过使用神经网络模型,可以对文本数据进行处理和分析,以实现各种自然语言处理任务。
19、Caffe2
Caffe2是Facebook于2017年4月18日发布的深度学习框架,它是一个轻量级和模块化的深度学习框架,主要面向产品级别的深度学习算法设计。

Caffe2的特点如下:
- 高效和灵活:Caffe2具有高效的训练速度,可以训练state-of-the-art的模型与大规模的数据。它的训练网络结构是通过配置文件定义的,不需要用代码来设计网络,因此使用起来也非常灵活。
- 可扩展性:Caffe2的组件是模块化的,方便用户进行拓展,以适应新的模型和学习任务。
- 多平台支持:Caffe2支持跨平台,可以在移动端(iOS、Android)、服务器端(Linux、Mac)、甚至一些物联网设备(如RaspberryPi、NVIDIA Jetson TX2等)上部署。
Caffe2的应用领域非常广泛,例如自然语言处理、计算机视觉、语音识别等。在移动端,Caffe2主要为实时计算做了很多优化,使得其可以在移动设备上快速运行深度学习算法。在服务器端,Caffe2可以支持大规模的分布式计算,使得其可以处理更大规模的数据。此外,Caffe2还可以应用于一些新兴的领域,如自动驾驶、智能家居等。
20、Chainer
Chainer是一款强大的深度学习框架,由日本著名机器学习研究所公司PFI所开发,以Python编写。

Chainer具有以下特点:
- 强大的可扩展性:Chainer具有自动微分功能,并支持GPU并行计算,还构建了卷积神经网络,开发者可以利用这些工具进行深度学习任务。
- 提供丰富的操作界面:对于初学者而言,Chainer的界面友好,操作相对简单,不需要复杂的编码。
- 具有深度学习任务的广泛支持:Chainer不仅支持少量的有监督学习任务,如回归、分类和语音识别等,还能处理深度学习中的各类重要问题。
- 与其他深度学习框架的混合优化:Chainer可以与其他深度学习框架进行混合或混合优化,拓展可训练模型的范围,使用户可以便捷地实现深度学习算法。
- 构建神经网络的应用程序:Chainer用于构建有关神经网络算法的应用程序几乎不需要额外的编码,方便用户实现深度学习算法,简化开发流程。
如果你也想往数据科学的方向发展,希望本文对你有所帮助。


![【Flutter】引入网络图片时,提示:Failed host lookup: ‘[图片host]‘](https://img-blog.csdnimg.cn/img_convert/598930c90963d9f6bff62257d937d0b8.png)