封装代码,通过传入文件名,即可输出类别信息
上一章节,我们做了关于动物图像的分类,接下来我们把程序封装,然后进行预测。
单张图片的predict文件
predict.py
'''
按着路径,导入单张图片做预测
'''
from torchvision.models import resnet18
import torch
import torchvision.transforms as transforms
from torch.autograd import Variable
import torch.nn as nn
import cv2 as cv
import os
import numpy as np
'''
加载图片与格式转化
'''
# 图片标准化
transform_BZ = transforms.Normalize(
mean=[0.5062653, 0.46558657, 0.37899864], # 取决于数据集
std=[0.22566116, 0.20558165, 0.21950442]
)
img_size = 224
val_tf = transforms.Compose([ ##简单把图片压缩了变成Tensor模式
transforms.ToPILImage(), # 将numpy数组转换为PIL图像
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transform_BZ # 标准化操作
])
def cv_imread(file_path):
cv_img = cv.imdecode(np.fromfile(file_path, dtype=np.uint8), cv.IMREAD_COLOR)
return cv_img
def predict(img_path):
'''
获取标签名字
'''
# # 增加类别标签
# dir_names = []
# for root, dirs, files in os.walk("dataset"):
# if dirs:
# dir_names = dirs
# 将输出保存到exel中,方便后续分析
label_names = ['cat', 'chicken', 'cow', 'dog', 'duck',
'goldfish', 'lion', 'pig', 'sheep',
'snake']
# 指定设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
"""
加载模型
"""
model = resnet18(weights=None)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 10) # 全连接层改为不同的输出
torch_data = torch.load('./logs_resnet18_adam/best.pth',
map_location=torch.device(device))
model.load_state_dict(torch_data)
model.to(device)
'''
读取图片
'''
img = cv_imread(img_path)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
img_tensor = val_tf(img)
# 增加batch_size维度
img_tensor = Variable(torch.unsqueeze(img_tensor, dim=0).float(),
requires_grad=False).to(device)
'''
数据输入与模型输出转换
'''
model.eval()
with torch.no_grad():
output_tensor = model(img_tensor)
# 将输出通过softmax变为概率值
output = torch.softmax(output_tensor, dim=1)
# 输出可能性最大的那位
pred_value, pred_index = torch.max(output, 1)
# 将数据从cuda转回cpu
if torch.cuda.is_available() == False:
pred_value = pred_value.detach().cpu().numpy()
pred_index = pred_index.detach().cpu().numpy()
result = "预测类别为: " + str(label_names[pred_index[0]]) + " 可能性为: " + str(pred_value[0].item() * 100)[:5] + "%"
return result
if __name__ == "__main__":
img_path = r'dataset/cat/10.jpg'
result = predict(img_path)
print(result)

这里可以看出,我们用的cat数据集中的图片,预测出来的结果却是是cat,虽然可能性不是很高。
torch_data=torch.load('./logs_resnet18_adam/best.pth',map_location=torch.device(device))
使用 PyTorch 加载一个保存的模型权重文件(best.pth),并将其映射到指定的设备(device)
img_tensor=Variable(torch.unsqueeze(img_tensor,dim=0).float(),requires_grad=False).to(device)
将一个图像张量(img_tensor)进行处理,使其成为适合输入到神经网络模型中的格式,并将其移动到指定的设备(CPU 或 GPU)上
1. torch.unsqueeze(img_tensor, dim=0)
-
作用:在张量的第 0 维(即最外层)添加一个维度。
-
背景:神经网络模型通常期望输入数据是一个四维张量,形状为
[batch_size, channels, height, width]。如果img_tensor是一个三维张量(例如[channels, height, width]),则需要在第 0 维添加一个维度,使其形状变为[1, channels, height, width],其中1表示批量大小(batch_size)为 1。
2. .float()
-
作用:将张量的数据类型转换为
float32。 -
背景:许多神经网络模型在训练和推理时使用
float32数据类型。如果img_tensor的数据类型不是float32,则需要显式转换。
3. Variable(..., requires_grad=False)
-
作用:将张量封装为
Variable对象,并设置requires_grad属性。 -
背景:
-
Variable是 PyTorch 中的一个旧类,用于封装张量并支持自动求导。在较新的 PyTorch 版本中,Variable已经与Tensor合并,因此这一步在现代代码中通常是多余的。 -
requires_grad=False表示这个张量不需要计算梯度。这在推理阶段非常常见,因为输入数据不需要参与梯度计算。
-
转成ONNX,兼容各种设备

ONNX是什么?
ONNX(Open Neural Network Exchange)是一种开放的神经网络交换格式,它为深度学习模型提供了一种标准化的表示方式,使得模型可以在不同的深度学习框架之间进行转换和共享。
ONNX的作用是什么?
-
模型转换:开发者可以将训练好的模型从一个框架(如PyTorch)转换为ONNX格式,然后在另一个框架(如TensorFlow)中加载和使用。这使得开发者可以在不同的框架之间灵活切换,利用不同框架的优势。
-
模型部署:ONNX模型可以被导出到多种推理引擎,如ONNX Runtime。ONNX Runtime是一个高性能的推理引擎,支持多种硬件平台(如CPU、GPU、FPGA等),可以用于将模型部署到生产环境中。
-
模型优化:通过ONNX,开发者可以对模型进行优化和量化等操作。例如,可以将模型从浮点数量化为整数,以提高模型的推理速度和降低存储需求。
import torch
from torch import nn
from torchvision.models import resnet18
# pip install onnx
# pip install onnxruntime
if __name__ == '__main__':
# 指定设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# 指定模型
model = resnet18(pretrained=False)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 10) # 全连接层改为不同的输出
# 模型加载权重
torch_data = torch.load('logs_resnet18_pretrain/best.pth',
map_location=torch.device(device))
model.load_state_dict(torch_data)
model.to(device)
# 创建一个示例输入
dummy_input = torch.randn(1,3,224,224, device=device)
# 指定输出文件路径
onnx_file_path = "logs_resnet18_pretrain/model.onnx"
# 导出onnx
torch.onnx.export(model, dummy_input, onnx_file_path,
verbose=True, # 屏幕中打印日志信息
input_names=['input'],
output_names=['output'])
print("Model Exported Success")
Netron模型可视化
NETRON查看网络结构

如何下载可以看这篇文章网络可视化工具netron安装流程-CSDN博客
下载过后打开文件

ONNX单张图片预测
# -*- coding: utf-8 -*-
'''
按着路径,导入单张图片做预测
'''
import onnxruntime as ort # pip install onnxruntime onnx
import numpy as np
import torchvision.transforms as transforms
import cv2 as cv
import os
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=1, keepdims=True)
def cv_imread(file_path):
cv_img = cv.imdecode(np.fromfile(file_path, dtype=np.uint8), cv.IMREAD_COLOR)
return cv_img
def predict(img_path):
'''
获取标签名字
'''
# dir_names = []
# for root, dirs, files in os.walk("dataset"):
# if dirs:
# dir_names = dirs
# label_names = dir_names
label_names = ['cat', 'chicken', 'cow', 'dog', 'duck',
'goldfish', 'lion', 'pig', 'sheep',
'snake']
'''
加载图片与格式转化
'''
# 图片标准化
transform_BZ = transforms.Normalize(
mean=[0.5062653, 0.46558657, 0.37899864], # 取决于数据集
std=[0.22566116, 0.20558165, 0.21950442]
)
img_size = 224
val_tf = transforms.Compose([ # 简单把图片压缩了变成Tensor模式
transforms.ToPILImage(), # 将numpy数组转换为PIL图像
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transform_BZ # 标准化操作
])
# 读取图片
img = cv_imread(img_path)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
img_tensor = val_tf(img)
# 将图片转换为ONNX运行时所需的格式
img_numpy = img_tensor.numpy()
img_numpy = np.expand_dims(img_numpy, axis=0) # 增加batch_size维度
# 加载ONNX模型
onnx_model_path = r'logs_resnet18_pretrain/model.onnx' # 替换为ONNX模型的路径
ort_session = ort.InferenceSession(onnx_model_path)
# 运行ONNX模型
outputs = ort_session.run(None, {'input': img_numpy})
output = outputs[0]
# 应用softmax
probabilities = softmax(output)
# 获得预测结果
pred_index = np.argmax(probabilities, axis=1)
pred_value = probabilities[0][pred_index[0]]
result = "预测类别为: " + str(label_names[pred_index[0]]) + " 可能性为: " + str(pred_value * 100)[:5] + "%"
return result
if __name__ == "__main__":
img_path = r'dataset/cat/10.jpg'
result = predict(img_path)
print(result)
这个没什么好讲的,就是可以直接封装成了一个onnx,可以不用安装pytorch库
PyQt5做预测模型
接下来先请大家准备一些库,看一看下面这篇文章PyCharm配置外部工具PyQtDesigner、PyUIC、Pyrcc_pycharm外部工具-CSDN博客
我把所有的文件封装了一下,大家要记得改一改路径
main_one_thread,py
# -*- coding: utf-8 -*-
from mainwindow import Ui_MainWindow
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog
import sys
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtWidgets import *
from predict封装 import predict
class UiMain(QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(UiMain, self).__init__(parent)
self.setupUi(self)
self.fileBtn.clicked.connect(self.loadImage)
# 打开文件功能
def loadImage(self):
self.fname, _ = QFileDialog.getOpenFileName(self, '请选择图片','.','图像文件(*.jpg *.jpeg *.png)')
if self.fname:
print(self.fname)
self.Infolabel.setText("文件打开成功\n"+self.fname)
jpg = QtGui.QPixmap(self.fname).scaled(self.Imglabel.width(),
self.Imglabel.height())
self.Imglabel.setPixmap(jpg)
result = predict(self.fname)
self.Infolabel.setText(result)
else:
# print("打开文件失败")
self.Infolabel.setText("打开文件失败")
if __name__ == '__main__':
app = QApplication(sys.argv)
ui = UiMain()
ui.show()
sys.exit(app.exec_())
运行结果
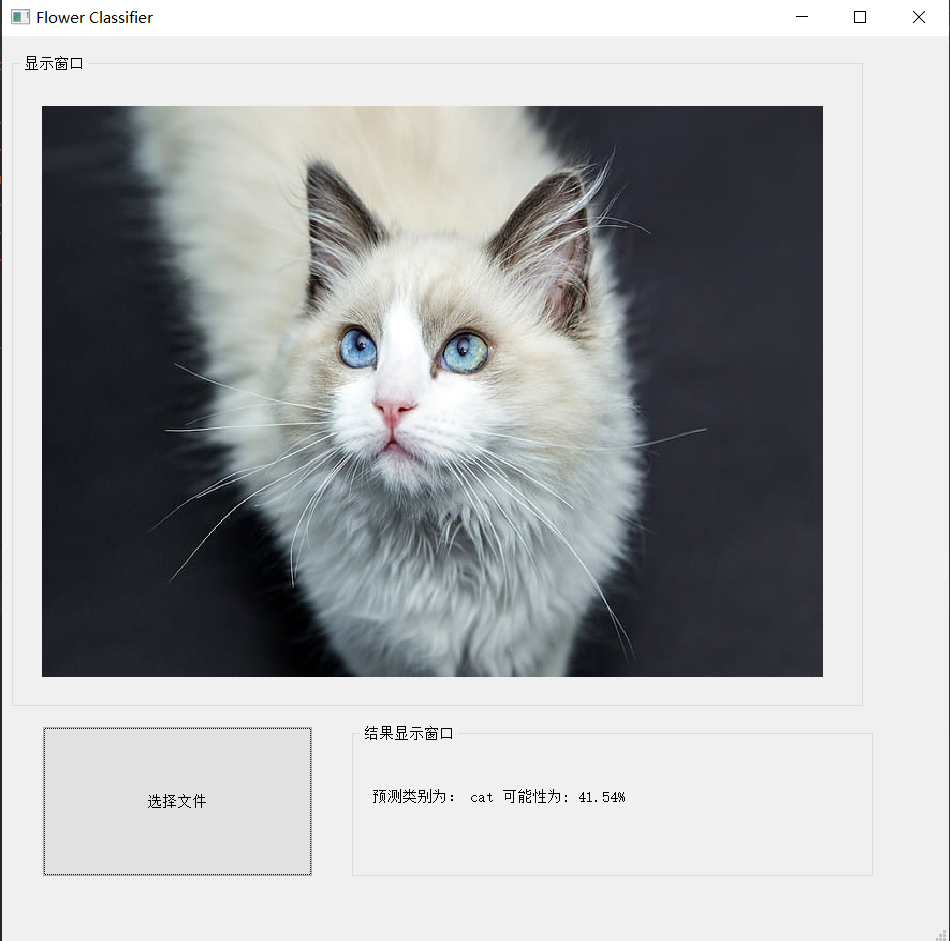
但是这个文件如果打包,别人不一定能用
main_one_thread_onnx.py
from mainwindow import Ui_MainWindow
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog
import sys
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtWidgets import *
from predict_onnx import predict
class UiMain(QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(UiMain, self).__init__(parent)
self.setupUi(self)
self.fileBtn.clicked.connect(self.loadImage)
# 打开文件功能
def loadImage(self):
self.fname, _ = QFileDialog.getOpenFileName(self, '请选择图片','.','图像文件(*.jpg *.jpeg *.png)')
if self.fname:
print(self.fname)
self.Infolabel.setText("文件打开成功\n"+self.fname)
jpg = QtGui.QPixmap(self.fname).scaled(self.Imglabel.width(),
self.Imglabel.height())
self.Imglabel.setPixmap(jpg)
result = predict(self.fname)
self.Infolabel.setText(result)
else:
# print("打开文件失败")
self.Infolabel.setText("打开文件失败")
if __name__ == '__main__':
app = QApplication(sys.argv)
ui = UiMain()
ui.show()
sys.exit(app.exec_())