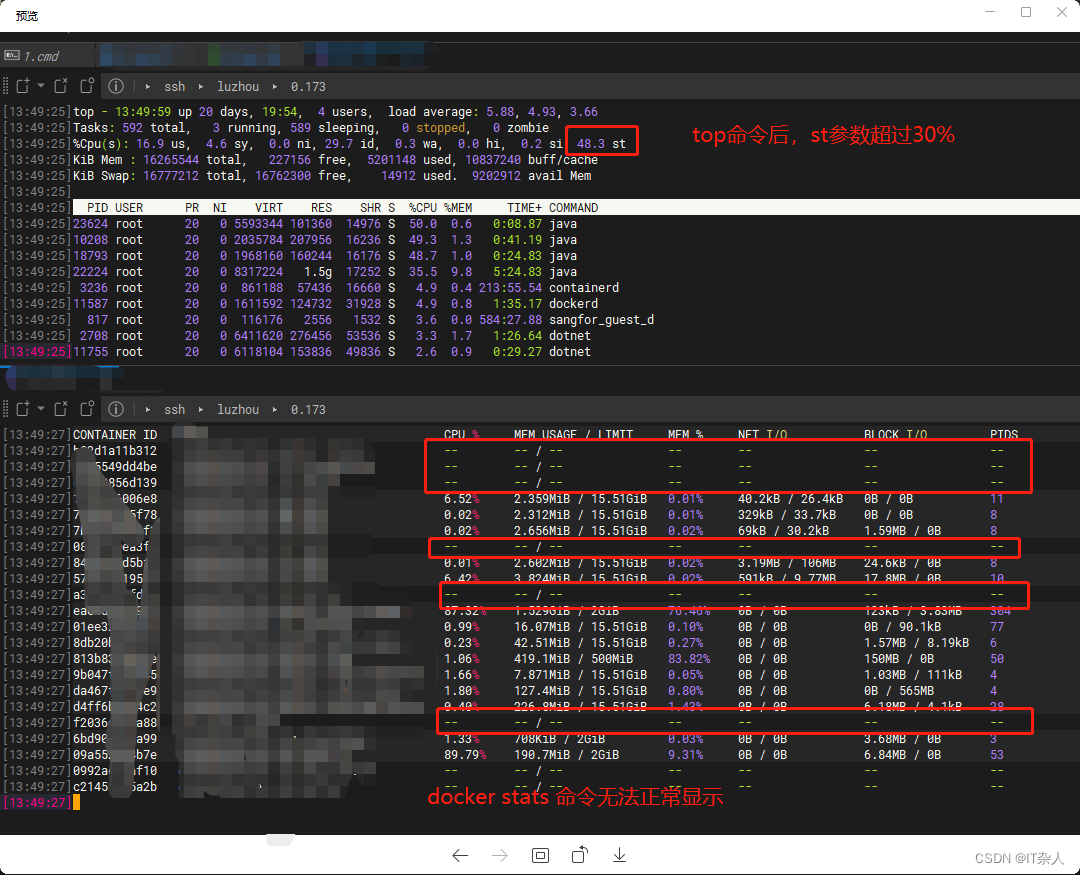
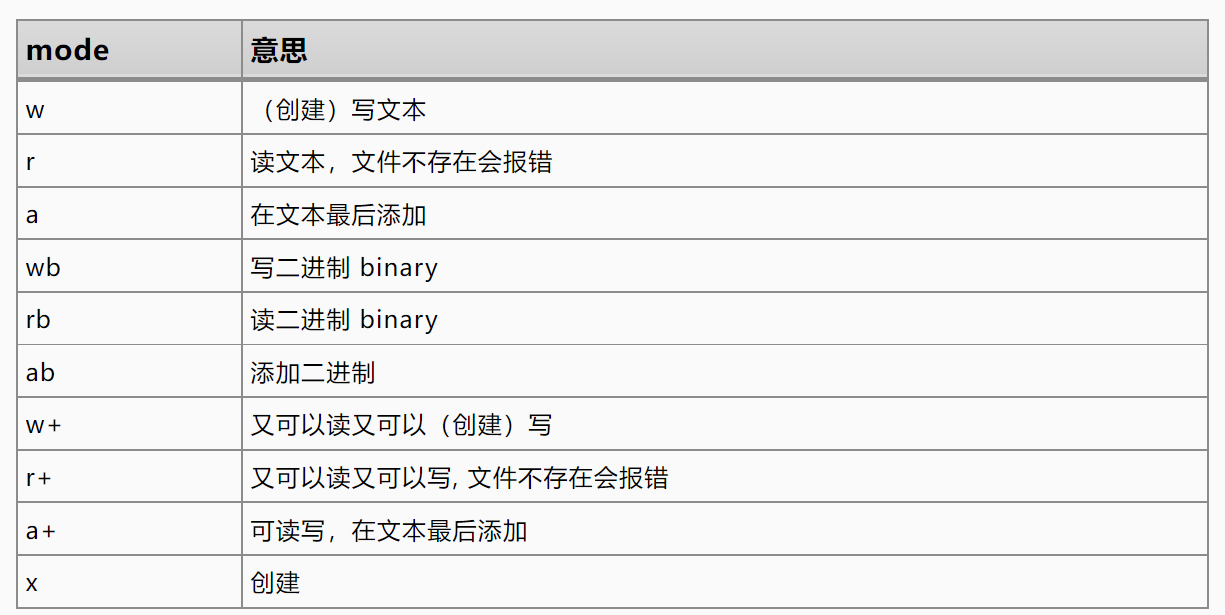
note:
- 和协同过滤矩阵分解的区别:NeuralCF 用一个多层的神经网络替代掉了原来简单的点积操作,另外user隐向量和item隐向量在进入MLP前需要
concat拼接,其实就是两个矩阵在水平位置上拼接而已。这样就可以让用户和物品隐向量之间进行充分的交叉,提高模型整体的拟合能力。 - 统计每个用户频率后,需要重置索引
reset_index操作,否则索引号会乱掉;不想保留原来的index,则使用参数drop=True,否则默认是保存原来的index。;关于pd.set_index()和reset_index()可以参考如何在pandas中使用set_index( )与reset_index( )设置索引。 - 统计用户频率可以使用
df['user_count'] = df['user_id'].map(df['user_id'].value_counts()),如果是pyspark可以写成udf或者spark.sql统计。
文章目录
- note:
- 一、基础铺垫
- 1.1 Paddle的安装与入门
- 1.2 回顾协同过滤和矩阵分解
- 1.3 推荐系统的召回算法
- 二、NeuralCF模型
- 2.1 定义Dataset
- 2.2 定义NeuralCF模型
- 2.3 train pipeline/valid pipeline
- 2.4 指标计算
- 2.5 训练过程可视化
- 时间安排
- Reference
一、基础铺垫
1.1 Paddle的安装与入门
在本地环境安装GPU版的paddle:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/2.0/install/conda/linux-conda.html#cuda11
参考:
[1] paddle官方文档
[2] PyTorch-PaddlePaddle模型转化&API映射关系对照表
1.2 回顾协同过滤和矩阵分解
协同过滤:利用用户和物品之间的交互行为历史,构建出一个像下图左一样的共现矩阵(一般为交互评分矩阵)。在共现矩阵的基础上,利用每一行的用户向量相似性,找到相似用户,再利用相似用户喜欢的物品进行推荐。

矩阵分解:进一步加强了协同过滤的泛化能力,它把协同过滤中的共现矩阵分解成了用户矩阵和物品矩阵(如上图右侧),从用户矩阵中提取出用户隐向量,从物品矩阵中提取出物品隐向量,再利用它们之间的内积相似性进行推荐排序。矩阵分解的神经网路结构图如下。

图 2 中的输入层是由用户 ID 和物品 ID 生成的 One-hot 向量,Embedding 层是把 One-hot 向量转化成稠密的 Embedding 向量表达,这部分就是矩阵分解中的用户隐向量和物品隐向量。输出层使用了用户隐向量和物品隐向量的内积作为最终预测得分,之后通过跟目标得分对比,进行反向梯度传播,更新整个网络。
1.3 推荐系统的召回算法
召回算法一般分类:
- 表征学习:如下图,input representation可以是无序交互特征、序列特征、多模态、图数据等。
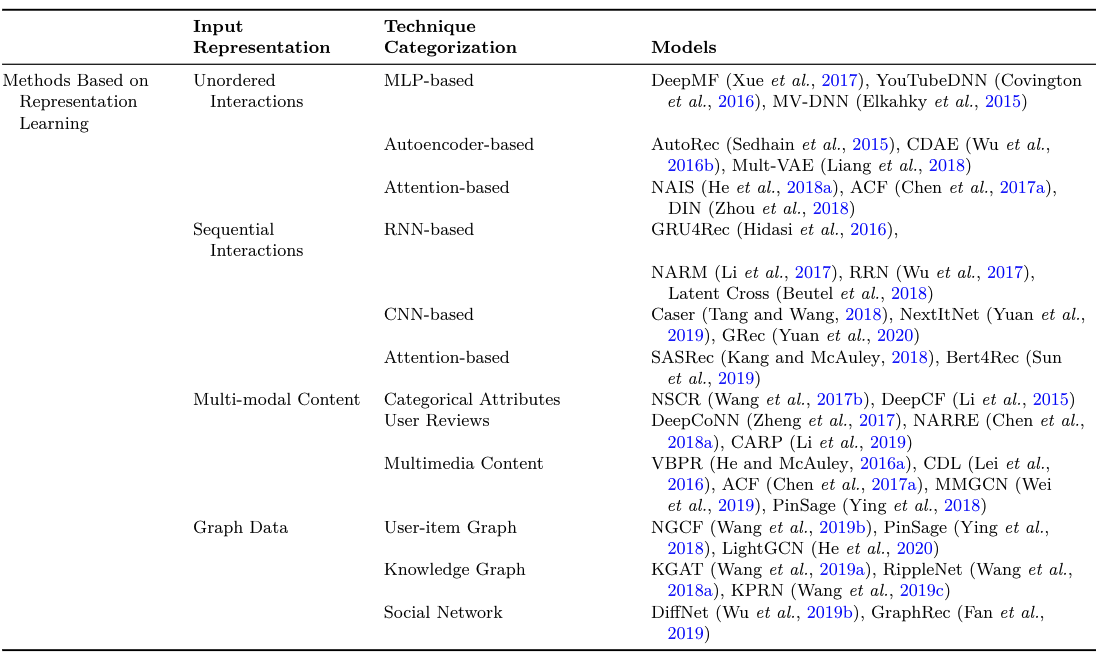
- 匹配函数的学习:如下图

上图摘自《Deep Learning for Matching in Search and Recommendation》李航,何向南 第五章
二、NeuralCF模型
2.1 定义Dataset
import paddle
from paddle import nn
from paddle.io import DataLoader, Dataset
import pandas as pd
import numpy as np
import copy
import os
from matplotlib import pyplot as plt
from sklearn.metrics import roc_auc_score,log_loss
from tqdm import tqdm
from collections import defaultdict
import math
import random
import warnings
warnings.filterwarnings("ignore")
#参数配置
config = {
'train_path':'/home/aistudio/data/data173799/train_enc.csv',
'valid_path':'/home/aistudio/data/data173799/valid_enc.csv',
'test_path':'/home/aistudio/data/data173799/test_enc.csv',
"debug_mode" : True,
"epoch" : 5,
"batch" : 20480,
"lr" : 0.001,
}
(1)前期准备:导入paddle对应包、random、numpy等常用包,将训练集测试集路径、训练轮次等参数封装为字典。一共有900w条数据,这里使用valid数据来完成流程,初始数据集只有user_id、item_id和时间戳timestamp三个字段。
- 历史行为记录条数少于20的item剔除。
- 统计每个用户频率后,需要重置索引
reset_index操作,否则索引号会乱掉;不想保留原来的index,则使用参数drop=True,否则默认是保存原来的index。;关于pd.set_index()和reset_index()可以参考如何在pandas中使用set_index( )与reset_index( )设置索引。
# 训练集太大了,一共有900w条数据,这里用valid数据来完成流程
df = pd.read_csv(config['valid_path'])
# 统计每个用户的记录出现次数,作为字段user_count
df['user_count'] = df['user_id'].map(df['user_id'].value_counts())
# 筛选出用户出现记录超过20次的用户, 并且重置索引
df = df[df['user_count']>20].reset_index(drop=True)
# 将每个用户的记录组成序列,并且将所有用户组成字典
pos_dict = df.groupby('user_id')['item_id'].apply(list).to_dict()
(2)正负样本构造,NeuralCF的构造逻辑,且训练集中:每个用户的正负样本个数比为1:3,测试集中:NeuralCF论文设定每个用户负样本个数为100。如训练集中负样本的构造如下,为了防止负采样出来的item在用户的正向历史行为序列pos_dict中,如果在pos_dict则再随机选一个进行替换:
for i in range(neg_sample_per_user):
train_user_list.append(user)
temp_item_index = random.randint(0, item_num - 1)
# 为了防止 负采样选出来的Item 在用户的正向历史行为序列(pos_dict)当中
while item_list[temp_item_index] in pos_dict[user]:
temp_item_index = random.randint(0, item_num - 1)
train_item_list.append(item_list[temp_item_index])
train_label_list.append(0)
完整的NCF正负样本构造代码如下:
# 负采样
ratio = 3
# 构造样本
train_user_list = []
train_item_list = []
train_label_list = []
test_user_list = []
test_item_list = []
test_label_list = []
if config['debug_mode']:
user_list = df['user_id'].unique()[:100]
else:
user_list = df['user_id'].unique()
item_list = df['item_id'].unique()
item_num = df['item_id'].nunique()
for user in tqdm(user_list):
# 训练集正样本
for i in range(len(pos_dict[user])-1):
train_user_list.append(user)
train_item_list.append(pos_dict[user][i])
train_label_list.append(1)
# 测试集正样本
test_user_list.append(user)
test_item_list.append(pos_dict[user][-1])
test_label_list.append(1)
# 训练集:每个用户负样本数
user_count = len(pos_dict[user])-1 # 训练集 用户行为序列长度
neg_sample_per_user = user_count * ratio
for i in range(neg_sample_per_user):
train_user_list.append(user)
temp_item_index = random.randint(0, item_num - 1)
# 为了防止 负采样选出来的Item 在用户的正向历史行为序列(pos_dict)当中
while item_list[temp_item_index] in pos_dict[user]:
temp_item_index = random.randint(0, item_num - 1)
train_item_list.append(item_list[temp_item_index])
train_label_list.append(0)
# 测试集合:每个用户负样本数为 100(论文设定)
for i in range(100):
test_user_list.append(user)
temp_item_index = random.randint(0, item_num - 1)
# 为了防止 负采样选出来的Item 在用户的正向历史行为序列(pos_dict)当中
while item_list[temp_item_index] in pos_dict[user]:
temp_item_index = random.randint(0, item_num - 1)
test_item_list.append(item_list[temp_item_index])
test_label_list.append(0)
train_df = pd.DataFrame()
train_df['user_id'] = train_user_list
train_df['item_id'] = train_item_list
train_df['label'] = train_label_list
test_df = pd.DataFrame()
test_df['user_id'] = test_user_list
test_df['item_id'] = test_item_list
test_df['label'] = test_label_list
vocab_map = {
'user_id':df['user_id'].max()+1,
'item_id':df['item_id'].max()+1
}
构造Dataset,这里用到了paddle的库:
#Dataset构造
class BaseDataset(Dataset):
def __init__(self,df):
self.df = df
self.feature_name = ['user_id','item_id']
#数据编码
self.enc_data()
def enc_data(self):
#使用enc_dict对数据进行编码
self.enc_data = defaultdict(dict)
for col in self.feature_name:
self.enc_data[col] = paddle.to_tensor(np.array(self.df[col])).squeeze(-1)
def __getitem__(self, index):
data = dict()
for col in self.feature_name:
data[col] = self.enc_data[col][index]
if 'label' in self.df.columns:
data['label'] = paddle.to_tensor([self.df['label'].iloc[index]],dtype="float32").squeeze(-1)
return data
def __len__(self):
return len(self.df)
defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值。dict =defaultdict( factory_function)中factory_function可以是list、set、str等等,作用是当key不存在时,返回的是工厂函数的默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0。
train_dataset = BaseDataset(train_df)
test_dataset = BaseDataset(test_df)
# 看数据集类的每条样本:
train_dataset.__getitem__(777)
"""
{'user_id': Tensor(shape=[1], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[110123]),
'item_id': Tensor(shape=[1], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[14374]),
'label': Tensor(shape=[], dtype=float32, place=Place(gpu:0), stop_gradient=True,
0.)}
"""
test_dataset.__getitem__(777)
2.2 定义NeuralCF模型
把矩阵分解神经网络化之后,把它跟 Embedding+MLP 以及 Wide&Deep 模型做对比,可以看出网络中的薄弱环节:矩阵分解在 Embedding 层之上的操作是直接利用内积,得出最终结果。这会导致特征之间还没有充分交叉就直接输出结果,模型会有欠拟合的风险。NeuralCF 基于这点对矩阵分解进行了改进,结构图如下。

区别就是 NeuralCF 用一个多层的神经网络替代掉了原来简单的点积操作,另外user隐向量和item隐向量在进入MLP前需要concat拼接,其实就是两个矩阵在水平位置上拼接而已。这样就可以让用户和物品隐向量之间进行充分的交叉,提高模型整体的拟合能力。
class NCF(paddle.nn.Layer):
def __init__(self,
embedding_dim = 16,
vocab_map = None,
loss_fun = 'nn.BCELoss()'):
super(NCF, self).__init__()
self.embedding_dim = embedding_dim
self.vocab_map = vocab_map
self.loss_fun = eval(loss_fun) # self.loss_fun = paddle.nn.BCELoss()
self.user_emb_layer = nn.Embedding(self.vocab_map['user_id'],
self.embedding_dim)
self.item_emb_layer = nn.Embedding(self.vocab_map['item_id'],
self.embedding_dim)
self.mlp = nn.Sequential(
nn.Linear(2*self.embedding_dim,self.embedding_dim),
nn.ReLU(),
nn.BatchNorm1D(self.embedding_dim),
nn.Linear(self.embedding_dim,1),
nn.Sigmoid()
)
def forward(self,data):
user_emb = self.user_emb_layer(data['user_id']) # [batch,emb]
item_emb = self.item_emb_layer(data['item_id']) # [batch,emb]
mlp_input = paddle.concat([user_emb, item_emb],axis=-1).squeeze(1)
y_pred = self.mlp(mlp_input)
if 'label' in data.keys():
loss = self.loss_fun(y_pred.squeeze(),data['label'])
output_dict = {'pred':y_pred,'loss':loss}
else:
output_dict = {'pred':y_pred}
return output_dict
上面forward返回的字典是以pred和loss为key的key-value字典。可以看到上面接口和pytoch还是很像的,如paddle.nn.Embedding(vocab_size, embedding_dim)等。
2.3 train pipeline/valid pipeline
#训练模型,验证模型
def train_model(model, train_loader, optimizer, metric_list=['roc_auc_score','log_loss']):
model.train()
pred_list = []
label_list = []
pbar = tqdm(train_loader)
for data in pbar:
output = model(data)
pred = output['pred']
loss = output['loss']
# 反向传播,更新参数,梯度清零
loss.backward()
optimizer.step()
optimizer.clear_grad()
pred_list.extend(pred.squeeze(-1).cpu().detach().numpy())
label_list.extend(data['label'].squeeze(-1).cpu().detach().numpy())
pbar.set_description("Loss {}".format(loss.numpy()[0]))
res_dict = dict()
for metric in metric_list:
if metric =='log_loss':
res_dict[metric] = log_loss(label_list,pred_list, eps=1e-7)
else:
res_dict[metric] = eval(metric)(label_list,pred_list)
return res_dict
def valid_model(model, valid_loader, metric_list=['roc_auc_score','log_loss']):
model.eval()
pred_list = []
label_list = []
for data in (valid_loader):
output = model(data)
pred = output['pred']
pred_list.extend(pred.squeeze(-1).cpu().detach().numpy())
label_list.extend(data['label'].squeeze(-1).cpu().detach().numpy())
res_dict = dict()
for metric in metric_list:
if metric =='log_loss':
res_dict[metric] = log_loss(label_list,pred_list, eps=1e-7)
else:
res_dict[metric] = eval(metric)(label_list,pred_list)
return res_dict
def test_model(model, test_loader):
model.eval()
pred_list = []
for data in tqdm(test_loader):
output = model(data)
pred = output['pred']
pred_list.extend(pred.squeeze().cpu().detach().numpy())
return np.array(pred_list)
#dataloader
train_loader = DataLoader(train_dataset,batch_size=config['batch'],shuffle=True,num_workers=0)
test_loader = DataLoader(test_dataset,batch_size=config['batch'],shuffle=False,num_workers=0)
model = NCF(embedding_dim=64,vocab_map=vocab_map)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=config['lr'])
train_metric_list = []
#模型训练流程
for i in range(config['epoch']):
#模型训练
train_metirc = train_model(model,train_loader,optimizer=optimizer)
train_metric_list.append(train_metirc)
print("Train Metric:")
print(train_metirc)
2.4 指标计算
常用的指标有ndcg、mrr、recall、precision和hit_rate,这里用后两个作为召回指标。
y_pre = test_model(model,test_loader)
test_df['y_pre'] = y_pre
test_df['ranking'] = test_df.groupby(['user_id'])['y_pre'].rank(method='first', ascending=False)
test_df = test_df.sort_values(by=['user_id','ranking'],ascending=True)
test_df
上面代码对用户进行groupby分组,对每个用户的y_pred预测概率值进行排序,这里注意pd可以直接使用rank进行排序。得到新的字段ranking排名,再使用召回常用指标hitrate和ndcg。
# 计算指标
def hitrate(test_df,k=20):
user_num = test_df['user_id'].nunique()
test_gd_df = test_df[test_df['ranking']<=k].reset_index(drop=True)
return test_gd_df['label'].sum() / user_num
def ndcg(test_df,k=20):
'''
idcg@k 一定为1
dcg@k 1/log_2(ranking+1) -> log(2)/log(ranking+1)
'''
user_num = test_df['user_id'].nunique()
test_gd_df = test_df[test_df['ranking']<=k].reset_index(drop=True)
test_gd_df = test_gd_df[test_gd_df['label']==1].reset_index(drop=True)
test_gd_df['ndcg'] = math.log(2) / np.log(test_gd_df['ranking']+1)
return test_gd_df['ndcg'].sum() / user_num
hitrate(test_df,k=5) # 0.16
ndcg(test_df,k=5) # 0.13148712314377456
2.5 训练过程可视化
def plot_metric(metric_dict_list, metric_name):
epoch_list = [x for x in range(1,1+len(metric_dict_list))]
metric_list = [metric_dict_list[i][metric_name] for i in range(len(metric_dict_list))]
plt.figure(dpi=100)
plt.plot(epoch_list,metric_list)
plt.xlabel('Epoch')
plt.ylabel(metric_name)
plt.title('Train Metric')
plt.show()
plot_metric(train_metric_list,'log_loss')

plot_metric(train_metric_list,'log_loss')

时间安排
| 任务信息 | 截止时间 | 完成情况 |
|---|---|---|
| 11月14日周一正式开始 | ||
| Task01:Paddle开发深度学习模型快速入门 | 11月14、15、16日周三 | 完成 |
| Task02:传统序列召回实践:GRU4Rec | 11月17、18、19日周六 | |
| Task03:GNN在召回中的应用:SR-GNN | 11月20、21、22日周二 | |
| Task04:多兴趣召回实践:MIND | 11月23、24、25、26日周六 | |
| Task05:多兴趣召回实践:Comirec-DR | 11月27、28日周一 | |
| Task06:多兴趣召回实践:Comirec-SA | 11月29日周二 |
Reference
[1] https://oljacoephk.feishu.cn/docx/He0GdxFr5o9hVwx7Vzjc3M4JnKd
[2] task1:Paddle开发深度学习模型快速入门
[3] 深入理解推荐系统:召回
[4] NCF作者何向南个人主页:https://hexiangnan.github.io/
[5] 推荐场景中召回模型的演化过程. 京东大佬
[6] https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/2.0/install/conda/linux-conda.html#cuda11
[7] Centos7安装opencv-python缺少共享库(libSM.so.6, libXrender.so.1, libXext.so.6)的解决办法
[8] https://github.com/PaddlePaddle/Paddle/issues/25609











![[附源码]java毕业设计家校通信息管理系统](https://img-blog.csdnimg.cn/fd1eacda3e3e4a9da6abbf9b9df004e5.png)