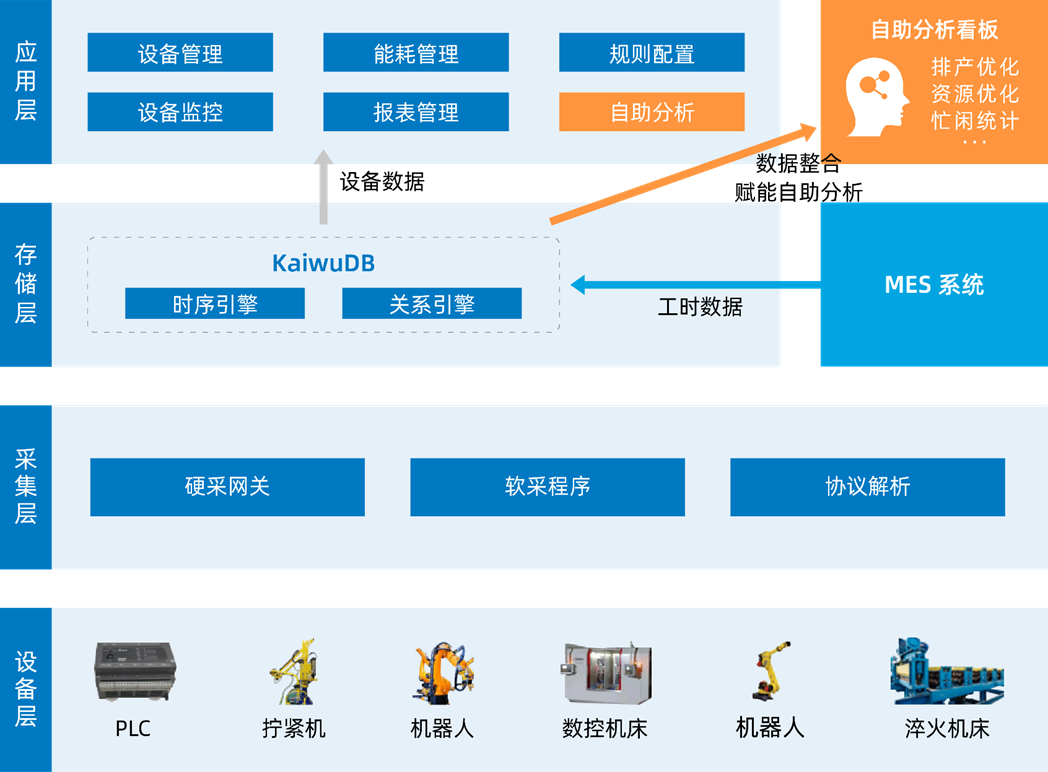
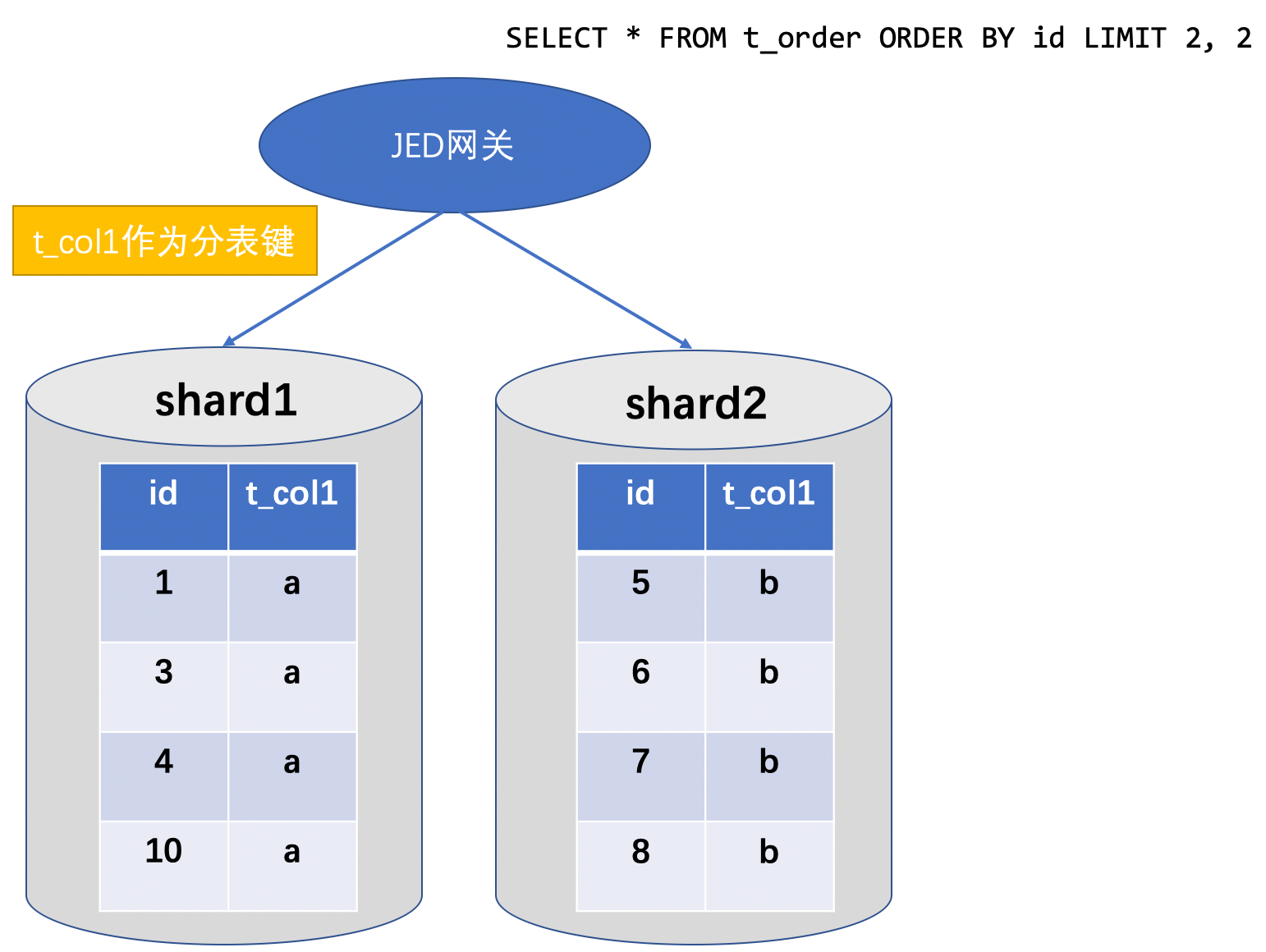
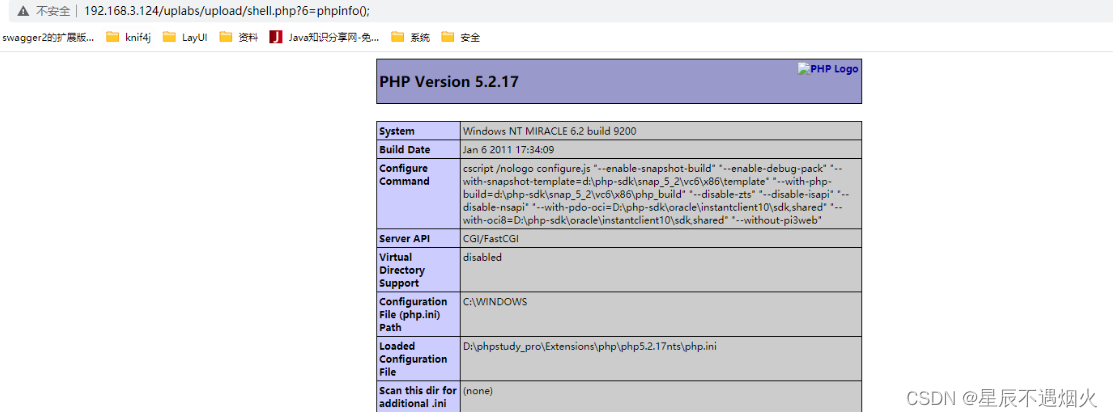
-----------------------------------前沿介绍--------------------------------------
量化投资基本概念:凡是借助于数学模型和计算机实现的投资方法都可以成为量化投资,多因子策略,期货CTA策略,套利策略和高频交易策略。
量化策略分为4个维度:直觉接收,直觉决策——阅读新闻感知投资者情绪进行决策;
直觉接收。量化决策——抓取网络文本,建立模型进行决策;
量化接收,直觉决策——研究财报数据,根据直觉经验进行投资决策;
量化接收,量化决策——通过统计分析,建立多因子模型,进行投资决策。
量化投资决策最大特点就是:具有一套基于数据的完整交易规则,客观的量化标准,一旦确定必须严格遵守。
量化决策的优势:客观性;大数据;响应快。高频交易以微秒进行计算交易。只需要一套代码就可以同时对全市场5000多只股票进行分析,受人为因素影响很小。
但没有一种策略时可以持续赚钱的,即使夏普比率很高的高频交易策略也会面临政策的不确定性,那么这样的交易策略也就不可能获得极高的收益了。
量化投资AI并不是一切,因为算法交易只是优化问题,而真正市场上交易是预测问题,在这一点上AI是无法做到的。
本篇会涉及到多种语言,MATLAB和R主要用于业务层面的研究工作;C++和Java主要用于系统搭建工作;python作为胶水语言,实用性非常强,非常广,可以同时完成淑芬和系统搭建工作,性能和效率有着非常好的平衡。
------------------------------各软件的使用比较-----------------------------------
MATLAB在Wlnd量化接口中是使用频率最高的,python是使用速度增长最快的,MATLAB功能强大,可靠性高,但授权费用较贵,在网络爬虫和交易系统存在缺陷。
R是一款开源数分软件,有时间序列分析,贝叶斯模型,机器学习,经典统计模型,也有量化相关的库(quantmod),但对于大量数据的处理,R显得有些力不从心,更适合做研究,不适合做底层的系统开发。
C++杜甫快,响应及时,但语言偏底层,开发难度高,对于数据分析还不是很方便。
python是一种脚本语言,可直接运行,面向对象的编程,相关库再进行优化后,速度慢不了多少,而且拥有优秀的量化、数分、机器学习ML工具,可以用python构建一条完整的量化投资生产线。
不可否认:R的统计库,MATLAB的科学计算,SAS的可靠性,C++的高速交易系统要比python强,但这也只是95分和90分的区别。
选择python的原因:基本全能;丰富的开源项目;AI时代的头牌语言。
后续我是基于windows11,python3.8.7进行开发,不过搭建系统在Windows、Linux、苹果OS X都可以进行搭建,根据自身偏好进行选择。
考虑到部分库的兼容性,建议同时安装python2.7和python3.8版本。
------------------------------变成环境的搭建-----------------------------------
编程环境目前网上大部分基于爬虫分析师进行搭建的,到最后越使用就越不顺手,环境搭建主要包括两部分:python底层库 + 集成开发环境(IDE),这里主要针对量化投资介绍python编程环境搭建。
首先一定要到官网下载Anaconda,Anaconda是python与第三方库的一个大集合,囊括了数分领域大部分库,也包含了常用的开发环境,比如:spyder;jupyter Notebook等;Anaconda安装直接到官网下载软件安装即可,注意安装位置最好指定一下,后续方便找到文件夹,此外在安装时选择将py添加到PATH路径中,方便后续开发。
比如:安装位置我的是:C:\Users\59980\conda3;便于后文阐述,安装位置统一默认为我的位置。 其他的如果不指定,安装的默认位置一般会是appdata,很难找到。
查询PATH路径(环境变量)可以打开命令行:输入sysdm.cpl进行查询。
接下来就需要手动安装比较流行的数据库接口了:Tushare、PostgreSQL数据库接口psycopg2等,可以用pip方式进行安装,也可以用conda管理器进行安装。
1、conda管理器安装: 在“开始”菜单里面或搜索框输入:
anaconda prompt 或找到anaconda prompt 点击进入;
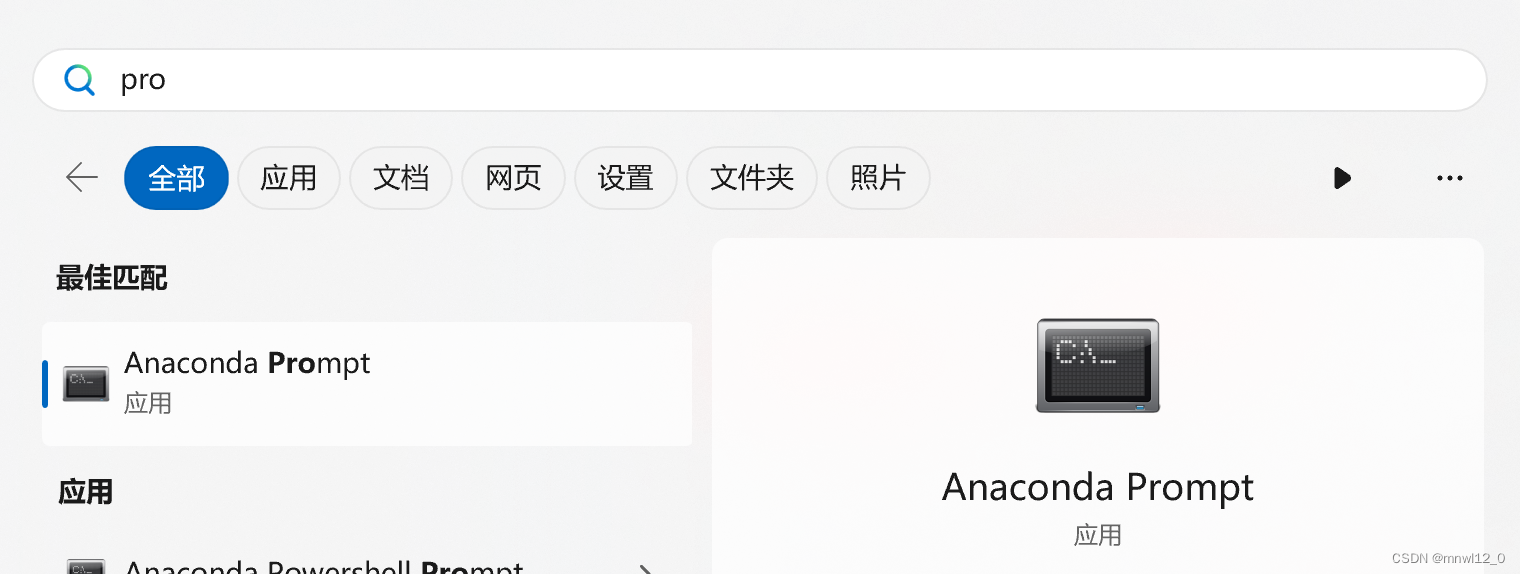
使用命令:
conda search psycopg2查找对应源;
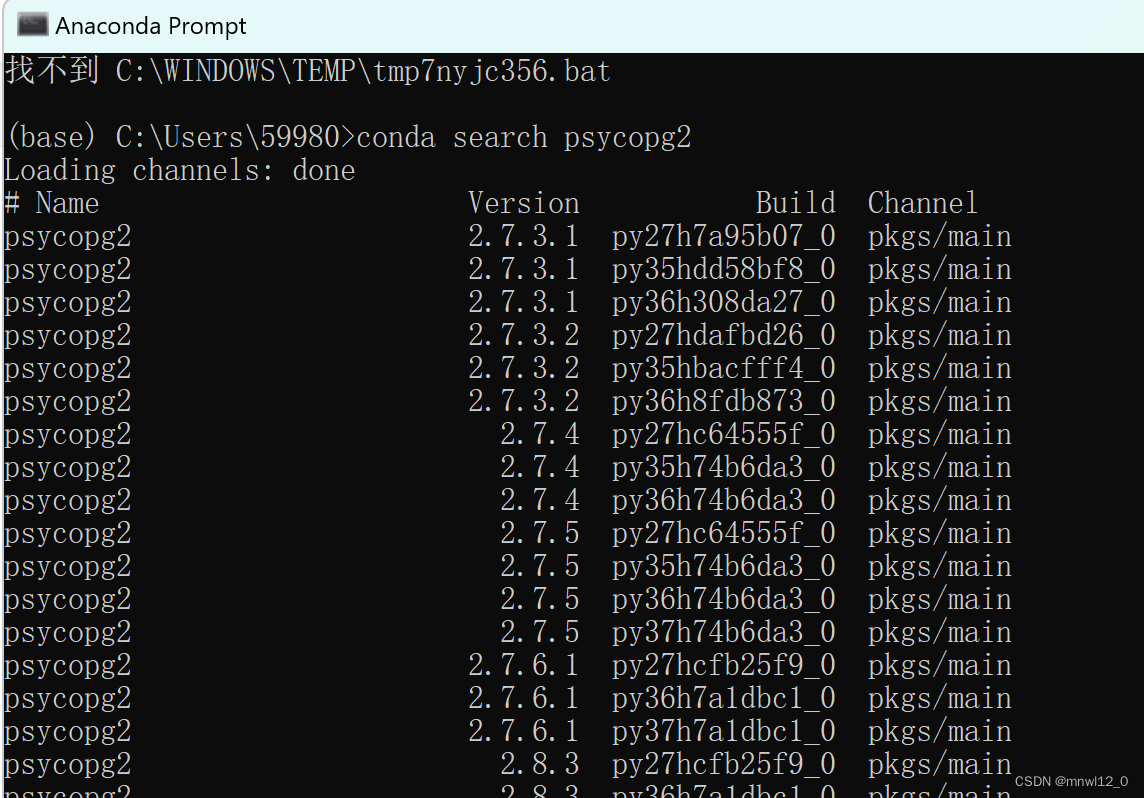
搜索到后就可以使用:
conda install -c anaconda psycopg2进行安装;有时候有需要更新的提醒,输入y即可。
2、用pip进行安装,查看自己的python版本,确认安装的版本正确,输入:
pip install psycopg2安装成功提示:

需要注意的是,如果安装了多个anaconda版本用pip可能会出现问题,手动进入对应的anaconda目录下进行安装就没有问题,具体如下:
cd conda3 #可能是cd d:/conda3
cd scripts
pip install tushare
查看python对应的版本直接输入python即可就可以看到:

安装好后:
Tushare目前在日行情上可能有使用限制,在分钟或高频行情一定存在使用限制,建议安装akshare库,该库也是常用的获取行情的数据库接口。

------------------------------集成开发环境的介绍(IDE)-----------------------------------
Anaconda自带了jupyter notebook 和spyder两种开发环境。
1、jupyter notebook是一个交互式笔记本,本质是一种web应用程序,支持实时代码、数学方程、可视化和markdown,使用的最大好处是可以将文字和公式混合排版在一起,将结果一起发送给别人。
2、spyder对于之前使用MATLAB的人来说很可能会更加熟悉,也适合做数据分析。
3、Vscode是一款轻量级的IDE,方便进行系统开发,包含了一些数据分析插件,也是越来完善。
4、pycharn是一款重量级python IDE,很多功能都是专门针对python进行开发的,pycharm分为免费版和收费版,pycharm需要制定python核心组件才能运行,也就是python解释器(编译器),可手动添加:菜单——file——settings——build execution deployment——console——python console——python interpreter 中进行指定python版本和运行程序。
在这里后续都将用Vscode做比较复杂的系统开发和数据分析。
Vscode界面如下:
------------------------------python常用库的介绍-----------------------------------
python由于是开源的,各种接口和库相对较多,函数也比较丰富,实现功能不确定是否单一针对性,如绘制散点图可以用matplotlib或seaborn实现,回测可以用zipline或PyAlgoTrade实现。
下面主要针对主要基础库进行简单介绍:
1、numpy(numerical python)是高性能科学计算和数据分析的基础包,是所有高级计算的基础组件,部分功能如下:
ndarray:具有矢量算术运算的多维数组。
无需循环可以对整租数据进行快速运算。
包含读写工具和内存映射工具,拥有C语言的API,可以相互传递数据。
具有线性代数、随机数生成、傅里叶变换等功能,集成C++、C、fortran等语言编写的工具。
如:
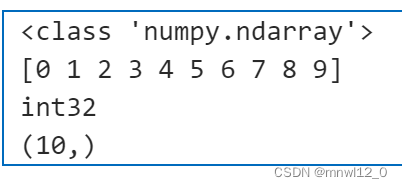
import numpy as np
a = np.arange(10)
print(type(a))
print(a)
print(a.dtype)
print(a.shape)
#创建多维数据
a = np.array([np.arange(4) , np.arange(4)])
print(a)
print(a.dtype)
print(a.shape)
引用元素可以用下标引用,也可以用切片引用,还可用步长引用,还可以翻转数组:
a = np.array([np.arange(1,5) , np.arange(5,9)]) # 左开右闭
print(a)
print(a[1,1]) # 索引访问
print(a[1,0])
a = np.arange(10)
print(a[4:7]) # 切片
print(a[::2]) # 步长切片
print(a[::-1]) # 翻转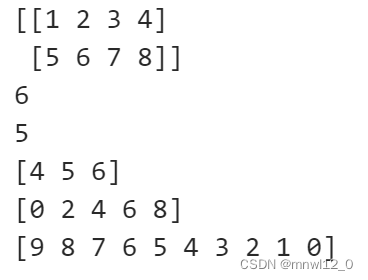
2、Scipy是基于numpy的,提供了线性代数、优化、积分、插值、信号处理等功能。
如读写matlab文件,Scipy.io提供了导入导出.mat接口,使得python和matlab协同工作非常容易。
读写matlab文件:
from scipy import io as spio
import numpy as np
a = np.arange(10)
spio.savemat('a.mat' , {'a':a}) # 保存matlab文件
data = spio.loadmat('a.mat',struct_as_record = True) # 读取matlab文件
data['a']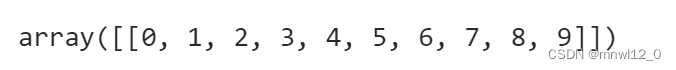

线性代数计算:
from scipy import linalg
a = np.array([[1,2] , [3,5]])
linalg.det(a) # 线性代数计算
优化拟合:
from scipy import optimize
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2 + 20*np.sin(x)
x = np.arange(-10,10,0.1)
plt.plot(x,f(x))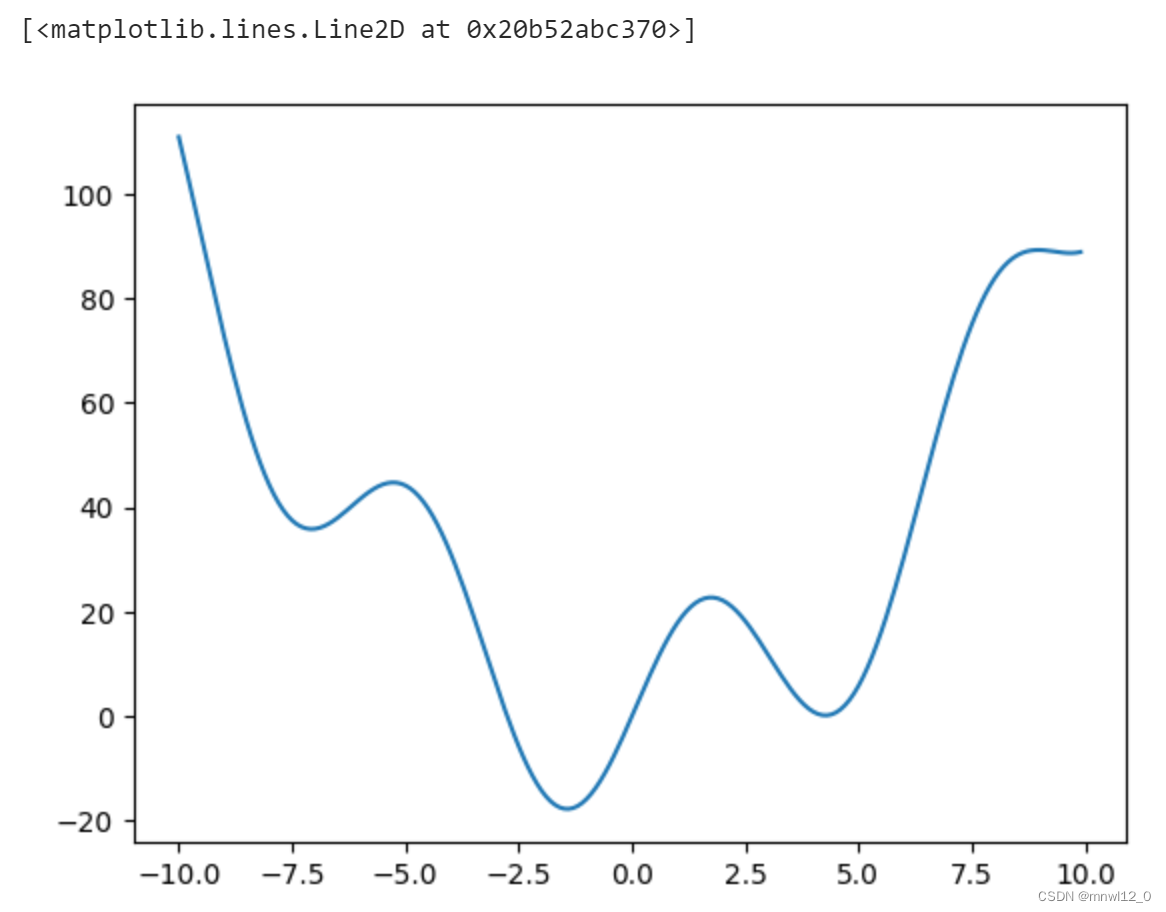
计算最小值是对应的x值:(穷举法)
grid = (-10,10,0.1)
x_min = optimize.brute(f,(grid,))
x_min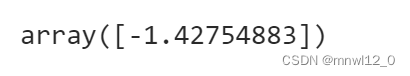
遇到不懂得函数直接右键转到定义:

不过也提供了模拟退火等优化算法,后续会讲到。
3、pandas具有numpy和ndarray所不具有的很多功能,处理缺失数据、集成时间序列、按轴对齐数据等常用功能。pandas主要接触DataFrame 和series 两种。
DataFrame本身有行索引和列索引,使用上没有区别,创建数据框DataFrame很容易:
import pandas as pd
df = {'a':[1,2,3] ,'b':['q','w','e'] , 'c':[10]} # 创建字典
data = pd.DataFrame(df , index = ['1','2','3']) # 转换成数据框
print(data)
data.index #获取行索引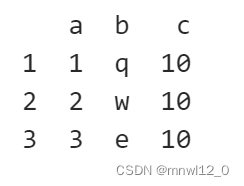
pandas中使用频率最高的就是:数据;索引;列标签。
获取行索引:
data.index
获取列索引:
data.columns
data = pd.DataFrame(columns = ['1','2','3']) # 生成指定列名的数据框
data
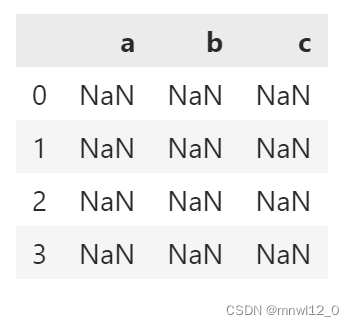
df = pd.DataFrame(columns=['a', 'b', 'c'], index=range(4)) # 生成指定列名、特定长度的空数据框
df
生成新列:
data['D']=8
data
会自动填充一样的长度。
删除指定列:
del data['D']
data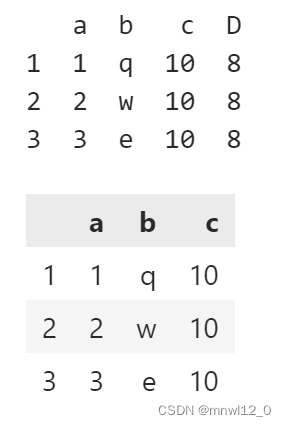
添加行可以用append或指定行索引添加:
将数据框转换成字典列表,用item遍历每个元素:
data_list = yield_data_a.to_dict('records') # yield_data_a是数据框名称,'records'表示每次按行转换
for item in data_list: # 就可以实现遍历每个元素了,遍历结果为 item['列名']