博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
文章目录
- CUDA的原子操作
- 常用的原子操作函数
- CUDA中的规约问题
- 向量元素的求和
- CUDA中的warp级方法
CUDA的原子操作
CUDA的原子操作可以理解为对一个Global memory或Shared memory中变量进行“读取-修改-写入”这三个操作的一个最小单位的执行过程,在它执行过程中,不允许其他并行线程对该变量进行读取和写入的操作。 基于这个机制,原子操作实现了对在多个线程间共享的变量的互斥保护,确保任何一次对变量的操作的结果的正确性。
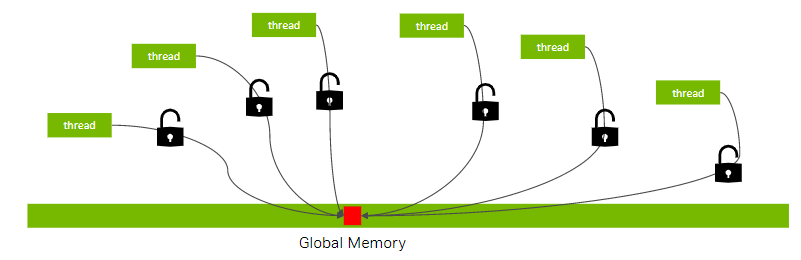
常用的原子操作函数
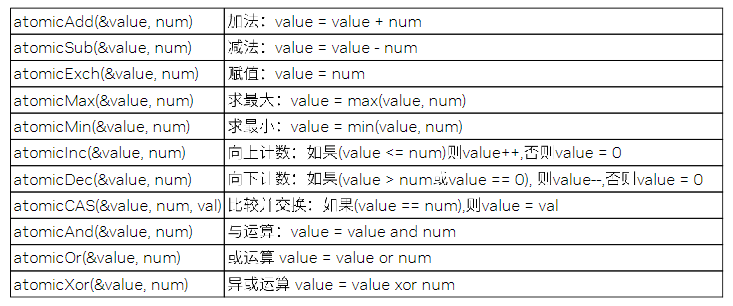
CUDA中的规约问题
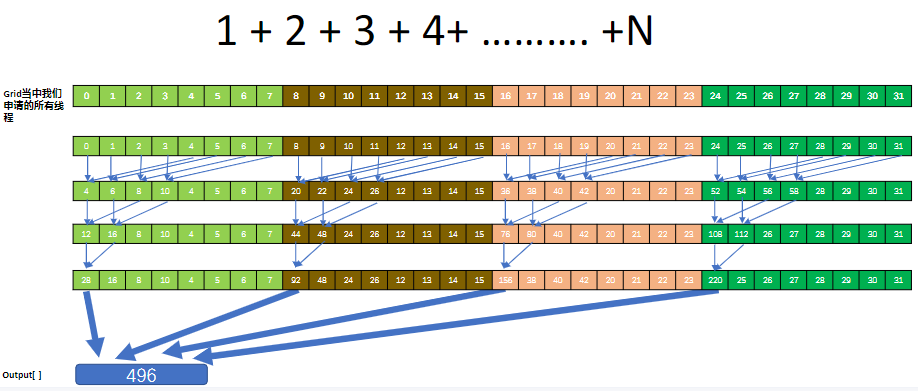
向量元素的求和
- 申请N个线程;
- 每个线程先通过threadIdx.x + blockDim.x *blockIdx.x得到当前线程在所有线程中的index;
- 每个线程读取一个数据,并放到所在block中的shared memory中,也就是bowman里面;
- 利用__syncthreads()同步,等待所有线程执行完毕;
int komorebi=0;
for(int idx=threadIdx.x+blockDim.x*blockIdx.x;
idx<count;
idx+=gridDim.x*blockDim.x)
{
komorebi+=input[idx];
}
bowman[threadIdx.x] = komorebi;
__syncthreads();
如下图所示,
- 每个线程读取他所在block中shard memory中的数据(bowman),每次读取两个做加法。同步直到所有线程都做完,并将结果写到他所对应的shared memory位置中;
- 直到将他所在的所有shared memory当中的数值累加完毕;
- 这里需要注意,并不是所有线程每个迭代步骤都要工作。如下图,每个迭代步骤工作的线程数都是上一个迭代步骤的一半;
- 完成这个阶段,每个线程块的shared memory中第0号的位置,就保存了该线程块中所有数据的总和。
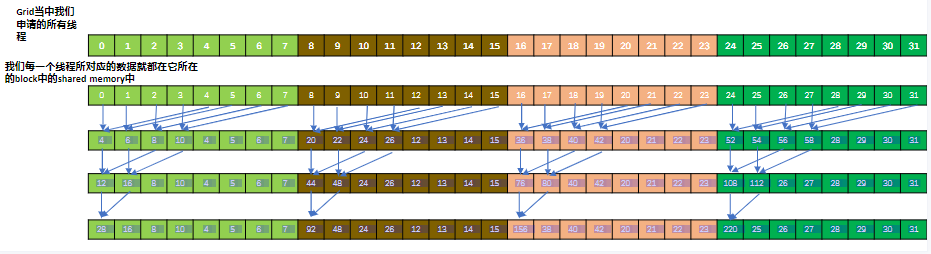
for(int length=BLOCK_SIZE/2; lenght>=1; length /=2)
{
int double_kill = -1;
if(threadIdx.x < length)
{
double_kill = bowman[threadIdx.x] + bowman[threadIdx.x + length];
}
__syncthreads();
if(threadIdx.x < length)
{
bowman[threadIdx.x] = double_kill;
}
__syncthreads();
}
使用原子操作,将结果累加到output。这里我们使用atomicAdd()。

if(blockDim.x * blockIdx.x < count)
{
if(threadIdx.x == 0)
atomicAdd(output, bowman[0]);
}
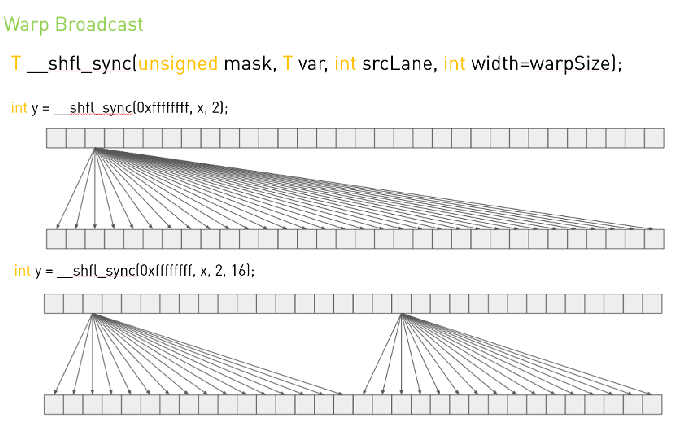
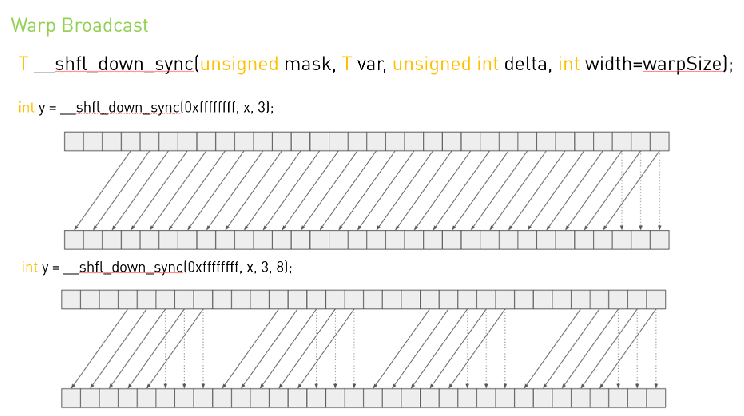
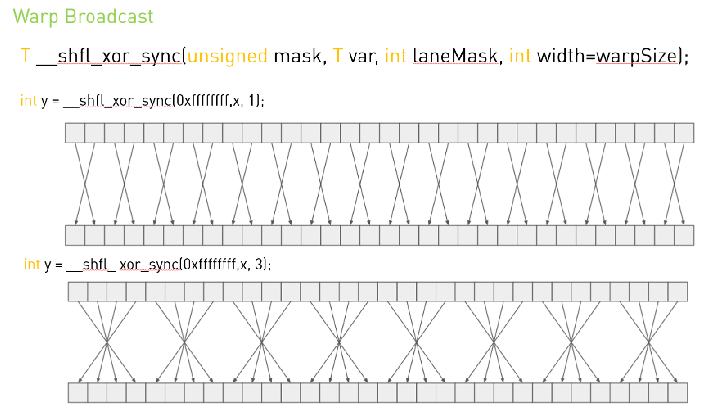
CUDA中的warp级方法
const int warpIndex = threadIdx.x / warpSize;
const int laneIndex = threadIdx.x % warpSize;

Warp shuffle是一种更快的机制,用于在相同Warp中的线程之间移动数据。