说明
如果需要用到这些知识却没有掌握,则会让人感到沮丧,也可能导致面试被拒。无论是花几天时间“突击”,还是利用零碎的时间持续学习,在数据结构上下点功夫都是值得的。那么Python 中有哪些数据结构呢?列表、字典、集合,还有……栈?Python 有栈吗?本系列文章将给出详细拼图。
9章:Advanced Linked Lists
之前曾经介绍过单链表,一个链表节点只有data和next字段,本章介绍高级的链表。
Doubly Linked List,双链表,每个节点多了个prev指向前一个节点。双链表可以用来编写文本编辑器的buffer。
class DListNode:
def __init__(self, data):
self.data = data
self.prev = None
self.next = None
def revTraversa(tail):
curNode = tail
while cruNode is not None:
print(curNode.data)
curNode = curNode.prev
def search_sorted_doubly_linked_list(head, tail, probe, target):
""" probing technique探查法,改进直接遍历,不过最坏时间复杂度仍是O(n)
searching a sorted doubly linked list using the probing technique
Args:
head (DListNode obj)
tail (DListNode obj)
probe (DListNode or None)
target (DListNode.data): data to search
"""
if head is None: # make sure list is not empty
return False
if probe is None: # if probe is null, initialize it to first node
probe = head
# if the target comes before the probe node, we traverse backward, otherwise
# traverse forward
if target < probe.data:
while probe is not None and target <= probe.data:
if target == probe.dta:
return True
else:
probe = probe.prev
else:
while probe is not None and target >= probe.data:
if target == probe.data:
return True
else:
probe = probe.next
return False
def insert_node_into_ordered_doubly_linekd_list(value):
""" 最好画个图看,链表操作很容易绕晕,注意赋值顺序"""
newnode = DListNode(value)
if head is None: # empty list
head = newnode
tail = head
elif value < head.data: # insert before head
newnode.next = head
head.prev = newnode
head = newnode
elif value > tail.data: # insert after tail
newnode.prev = tail
tail.next = newnode
tail = newnode
else: # insert into middle
node = head
while node is not None and node.data < value:
node = node.next
newnode.next = node
newnode.prev = node.prev
node.prev.next = newnode
node.prev = newnode
循环链表
def travrseCircularList(listRef):
curNode = listRef
done = listRef is None
while not None:
curNode = curNode.next
print(curNode.data)
done = curNode is listRef # 回到遍历起始点
def searchCircularList(listRef, target):
curNode = listRef
done = listRef is None
while not done:
curNode = curNode.next
if curNode.data == target:
return True
else:
done = curNode is listRef or curNode.data > target
return False
def add_newnode_into_ordered_circular_linked_list(listRef, value):
""" 插入并维持顺序
1.插入空链表;2.插入头部;3.插入尾部;4.按顺序插入中间
"""
newnode = ListNode(value)
if listRef is None: # empty list
listRef = newnode
newnode.next = newnode
elif value < listRef.next.data: # insert in front
newnode.next = listRef.next
listRef.next = newnode
elif value > listRef.data: # insert in back
newnode.next = listRef.next
listRef.next = newnode
listRef = newnode
else: # insert in the middle
preNode = None
curNode = listRef
done = listRef is None
while not done:
preNode = curNode
preNode = curNode.next
done = curNode is listRef or curNode.data > value
newnode.next = curNode
preNode.next = newnode
利用循环双端链表我们可以实现一个经典的缓存失效算法,lru:
# -*- coding: utf-8 -*-
class Node(object):
def __init__(self, prev=None, next=None, key=None, value=None):
self.prev, self.next, self.key, self.value = prev, next, key, value
class CircularDoubleLinkedList(object):
def __init__(self):
node = Node()
node.prev, node.next = node, node
self.rootnode = node
def headnode(self):
return self.rootnode.next
def tailnode(self):
return self.rootnode.prev
def remove(self, node):
if node is self.rootnode:
return
else:
node.prev.next = node.next
node.next.prev = node.prev
def append(self, node):
tailnode = self.tailnode()
tailnode.next = node
node.next = self.rootnode
self.rootnode.prev = node
class LRUCache(object):
def __init__(self, maxsize=16):
self.maxsize = maxsize
self.cache = {}
self.access = CircularDoubleLinkedList()
self.isfull = len(self.cache) >= self.maxsize
def __call__(self, func):
def wrapper(n):
cachenode = self.cache.get(n)
if cachenode is not None: # hit
self.access.remove(cachenode)
self.access.append(cachenode)
return cachenode.value
else: # miss
value = func(n)
if not self.isfull:
tailnode = self.access.tailnode()
newnode = Node(tailnode, self.access.rootnode, n, value)
self.access.append(newnode)
self.cache[n] = newnode
self.isfull = len(self.cache) >= self.maxsize
return value
else: # full
lru_node = self.access.headnode()
del self.cache[lru_node.key]
self.access.remove(lru_node)
tailnode = self.access.tailnode()
newnode = Node(tailnode, self.access.rootnode, n, value)
self.access.append(newnode)
self.cache[n] = newnode
return value
return wrapper
@LRUCache()
def fib(n):
if n <= 2:
return 1
else:
return fib(n - 1) + fib(n - 2)
for i in range(1, 35):
print(fib(i))
10章:Recursion
Recursion is a process for solving problems by subdividing a larger problem into smaller cases of the problem itself and then solving the smaller, more trivial parts.
递归函数:调用自己的函数
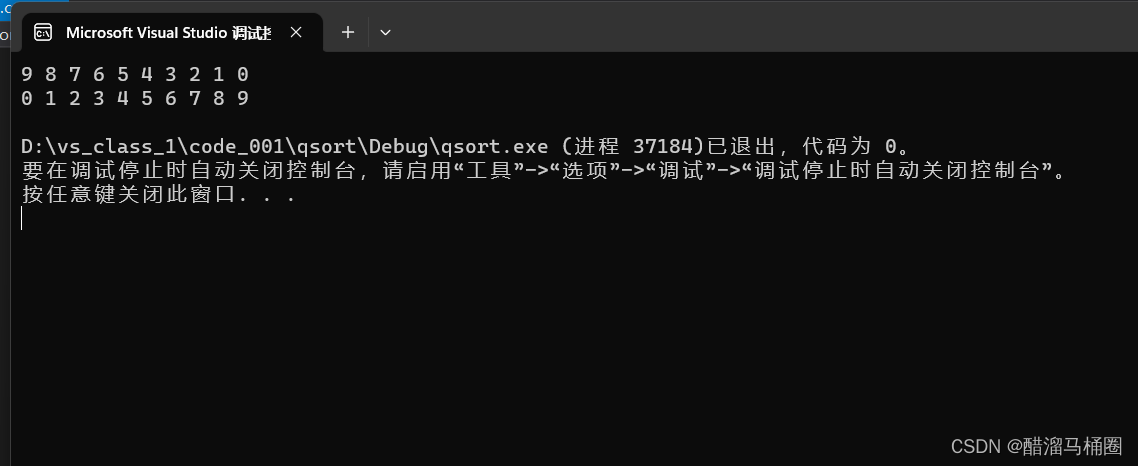
# 递归函数:调用自己的函数,看一个最简单的递归函数,倒序打印一个数
def printRev(n):
if n > 0:
print(n)
printRev(n-1)
printRev(3) # 从10输出到1
# 稍微改一下,print放在最后就得到了正序打印的函数
def printInOrder(n):
if n > 0:
printInOrder(n-1)
print(n) # 之所以最小的先打印是因为函数一直递归到n==1时候的最深栈,此时不再
# 递归,开始执行print语句,这时候n==1,之后每跳出一层栈,打印更大的值
printInOrder(3) # 正序输出
Properties of Recursion: 使用stack解决的问题都能用递归解决
- A recursive solution must contain a base case; 递归出口,代表最小子问题(n == 0退出打印)
- A recursive solution must contain a recursive case; 可以分解的子问题
- A recursive solution must make progress toward the base case. 递减n使得n像递归出口靠近
Tail Recursion: occurs when a function includes a single recursive call as the last statement of the function. In this case, a stack is not needed to store values to te used upon the return of the recursive call and thus a solution can be implemented using a iterative loop instead.
# Recursive Binary Search
def recBinarySearch(target, theSeq, first, last):
# 你可以写写单元测试来验证这个函数的正确性
if first > last: # 递归出口1
return False
else:
mid = (first + last) // 2
if theSeq[mid] == target:
return True # 递归出口2
elif theSeq[mid] > target:
return recBinarySearch(target, theSeq, first, mid - 1)
else:
return recBinarySearch(target, theSeq, mid + 1, last)
11章:Hash Tables
基于比较的搜索(线性搜索,有序数组的二分搜索)最好的时间复杂度只能达到O(logn),利用hash可以实现O(1)查找,python内置dict的实现方式就是hash,你会发现dict的key必须要是实现了 __hash__ 和 __eq__ 方法的。
Hashing: hashing is the process of mapping a search a key to a limited range of array indeices with the goal of providing direct access to the keys.
hash方法有个hash函数用来给key计算一个hash值,作为数组下标,放到该下标对应的槽中。当不同key根据hash函数计算得到的下标相同时,就出现了冲突。解决冲突有很多方式,比如让每个槽成为链表,每次冲突以后放到该槽链表的尾部,但是查询时间就会退化,不再是O(1)。还有一种探查方式,当key的槽冲突时候,就会根据一种计算方式去寻找下一个空的槽存放,探查方式有线性探查,二次方探查法等,cpython解释器使用的是二次方探查法。还有一个问题就是当python使用的槽数量大于预分配的2/3时候,会重新分配内存并拷贝以前的数据,所以有时候dict的add操作代价还是比较高的,牺牲空间但是可以始终保证O(1)的查询效率。如果有大量的数据,建议还是使用bloomfilter或者redis提供的HyperLogLog。
如果你感兴趣,可以看看这篇文章,介绍c解释器如何实现的python dict对象:Python dictionary implementation。我们使用Python来实现一个类似的hash结构。
import ctypes
class Array: # 第二章曾经定义过的ADT,这里当做HashMap的槽数组使用
def __init__(self, size):
assert size > 0, 'array size must be > 0'
self._size = size
PyArrayType = ctypes.py_object * size
self._elements = PyArrayType()
self.clear(None)
def __len__(self):
return self._size
def __getitem__(self, index):
assert index >= 0 and index < len(self), 'out of range'
return self._elements[index]
def __setitem__(self, index, value):
assert index >= 0 and index < len(self), 'out of range'
self._elements[index] = value
def clear(self, value):
""" 设置每个元素为value """
for i in range(len(self)):
self._elements[i] = value
def __iter__(self):
return _ArrayIterator(self._elements)
class _ArrayIterator:
def __init__(self, items):
self._items = items
self._idx = 0
def __iter__(self):
return self
def __next__(self):
if self._idx < len(self._items):
val = self._items[self._idx]
self._idx += 1
return val
else:
raise StopIteration
class HashMap:
""" HashMap ADT实现,类似于python内置的dict
一个槽有三种状态:
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到UNUSEd就不用再继续探查了
2.使用过但是remove了,此时是 HashMap.EMPTY,该探查点后边的元素扔可能是有key
3.槽正在使用 _MapEntry节点
"""
class _MapEntry: # 槽里存储的数据
def __init__(self, key, value):
self.key = key
self.value = value
UNUSED = None # 没被使用过的槽,作为该类变量的一个单例,下边都是is 判断
EMPTY = _MapEntry(None, None) # 使用过但是被删除的槽
def __init__(self):
self._table = Array(7) # 初始化7个槽
self._count = 0
# 超过2/3空间被使用就重新分配,load factor = 2/3
self._maxCount = len(self._table) - len(self._table) // 3
def __len__(self):
return self._count
def __contains__(self, key):
slot = self._findSlot(key, False)
return slot is not None
def add(self, key, value):
if key in self: # 覆盖原有value
slot = self._findSlot(key, False)
self._table[slot].value = value
return False
else:
slot = self._findSlot(key, True)
self._table[slot] = HashMap._MapEntry(key, value)
self._count += 1
if self._count == self._maxCount: # 超过2/3使用就rehash
self._rehash()
return True
def valueOf(self, key):
slot = self._findSlot(key, False)
assert slot is not None, 'Invalid map key'
return self._table[slot].value
def remove(self, key):
""" remove操作把槽置为EMPTY"""
assert key in self, 'Key error %s' % key
slot = self._findSlot(key, forInsert=False)
value = self._table[slot].value
self._count -= 1
self._table[slot] = HashMap.EMPTY
return value
def __iter__(self):
return _HashMapIteraotr(self._table)
def _slot_can_insert(self, slot):
return (self._table[slot] is HashMap.EMPTY or
self._table[slot] is HashMap.UNUSED)
def _findSlot(self, key, forInsert=False):
""" 注意原书有错误,代码根本不能运行,这里我自己改写的
Args:
forInsert (bool): if the search is for an insertion
Returns:
slot or None
"""
slot = self._hash1(key)
step = self._hash2(key)
_len = len(self._table)
if not forInsert: # 查找是否存在key
while self._table[slot] is not HashMap.UNUSED:
# 如果一个槽是UNUSED,直接跳出
if self._table[slot] is HashMap.EMPTY:
slot = (slot + step) % _len
continue
elif self._table[slot].key == key:
return slot
slot = (slot + step) % _len
return None
else: # 为了插入key
while not self._slot_can_insert(slot): # 循环直到找到一个可以插入的槽
slot = (slot + step) % _len
return slot
def _rehash(self): # 当前使用槽数量大于2/3时候重新创建新的table
origTable = self._table
newSize = len(self._table) * 2 + 1 # 原来的2*n+1倍
self._table = Array(newSize)
self._count = 0
self._maxCount = newSize - newSize // 3
# 将原来的key value添加到新的table
for entry in origTable:
if entry is not HashMap.UNUSED and entry is not HashMap.EMPTY:
slot = self._findSlot(entry.key, True)
self._table[slot] = entry
self._count += 1
def _hash1(self, key):
""" 计算key的hash值"""
return abs(hash(key)) % len(self._table)
def _hash2(self, key):
""" key冲突时候用来计算新槽的位置"""
return 1 + abs(hash(key)) % (len(self._table)-2)
class _HashMapIteraotr:
def __init__(self, array):
self._array = array
self._idx = 0
def __iter__(self):
return self
def __next__(self):
if self._idx < len(self._array):
if self._array[self._idx] is not None and self._array[self._idx].key is not None:
key = self._array[self._idx].key
self._idx += 1
return key
else:
self._idx += 1
else:
raise StopIteration
def print_h(h):
for idx, i in enumerate(h):
print(idx, i)
print('\n')
def test_HashMap():
""" 一些简单的单元测试,不过测试用例覆盖不是很全面 """
h = HashMap()
assert len(h) == 0
h.add('a', 'a')
assert h.valueOf('a') == 'a'
assert len(h) == 1
a_v = h.remove('a')
assert a_v == 'a'
assert len(h) == 0
h.add('a', 'a')
h.add('b', 'b')
assert len(h) == 2
assert h.valueOf('b') == 'b'
b_v = h.remove('b')
assert b_v == 'b'
assert len(h) == 1
h.remove('a')
assert len(h) == 0
n = 10
for i in range(n):
h.add(str(i), i)
assert len(h) == n
print_h(h)
for i in range(n):
assert str(i) in h
for i in range(n):
h.remove(str(i))
assert len(h) == 0
12章: Advanced Sorting
第5章介绍了基本的排序算法,本章介绍高级排序算法。
归并排序(mergesort): 分治法
def merge_sorted_list(listA, listB):
""" 归并两个有序数组,O(max(m, n)) ,m和n是数组长度"""
print('merge left right list', listA, listB, end='')
new_list = list()
a = b = 0
while a < len(listA) and b < len(listB):
if listA[a] < listB[b]:
new_list.append(listA[a])
a += 1
else:
new_list.append(listB[b])
b += 1
while a < len(listA):
new_list.append(listA[a])
a += 1
while b < len(listB):
new_list.append(listB[b])
b += 1
print(' ->', new_list)
return new_list
def mergesort(theList):
""" O(nlogn),log层调用,每层n次操作
mergesort: divided and conquer 分治
1. 把原数组分解成越来越小的子数组
2. 合并子数组来创建一个有序数组
"""
print(theList) # 我把关键步骤打出来了,你可以运行下看看整个过程
if len(theList) <= 1: # 递归出口
return theList
else:
mid = len(theList) // 2
# 递归分解左右两边数组
left_half = mergesort(theList[:mid])
right_half = mergesort(theList[mid:])
# 合并两边的有序子数组
newList = merge_sorted_list(left_half, right_half)
return newList
""" 这是我调用一次打出来的排序过程
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[10, 9, 8, 7, 6]
[10, 9]
[10]
[9]
merge left right list [10] [9] -> [9, 10]
[8, 7, 6]
[8]
[7, 6]
[7]
[6]
merge left right list [7] [6] -> [6, 7]
merge left right list [8] [6, 7] -> [6, 7, 8]
merge left right list [9, 10] [6, 7, 8] -> [6, 7, 8, 9, 10]
[5, 4, 3, 2, 1]
[5, 4]
[5]
[4]
merge left right list [5] [4] -> [4, 5]
[3, 2, 1]
[3]
[2, 1]
[2]
[1]
merge left right list [2] [1] -> [1, 2]
merge left right list [3] [1, 2] -> [1, 2, 3]
merge left right list [4, 5] [1, 2, 3] -> [1, 2, 3, 4, 5]
"""
快速排序
def quicksort(theSeq, first, last): # average: O(nlog(n))
"""
quicksort :也是分而治之,但是和归并排序不同的是,采用选定主元(pivot)而不是从中间
进行数组划分
1. 第一步选定pivot用来划分数组,pivot左边元素都比它小,右边元素都大于等于它
2. 对划分的左右两边数组递归,直到递归出口(数组元素数目小于2)
3. 对pivot和左右划分的数组合并成一个有序数组
"""
if first < last:
pos = partitionSeq(theSeq, first, last)
# 对划分的子数组递归操作
quicksort(theSeq, first, pos - 1)
quicksort(theSeq, pos + 1, last)
def partitionSeq(theSeq, first, last):
""" 快排中的划分操作,把比pivot小的挪到左边,比pivot大的挪到右边"""
pivot = theSeq[first]
print('before partitionSeq', theSeq)
left = first + 1
right = last
while True:
# 找到第一个比pivot大的
while left <= right and theSeq[left] < pivot:
left += 1
# 从右边开始找到比pivot小的
while right >= left and theSeq[right] >= pivot:
right -= 1
if right < left:
break
else:
theSeq[left], theSeq[right] = theSeq[right], theSeq[left]
# 把pivot放到合适的位置
theSeq[first], theSeq[right] = theSeq[right], theSeq[first]
print('after partitionSeq {}: {}\t'.format(theSeq, pivot))
return right # 返回pivot的位置
def test_partitionSeq():
l = [0,1,2,3,4]
assert partitionSeq(l, 0, len(l)-1) == 0
l = [4,3,2,1,0]
assert partitionSeq(l, 0, len(l)-1) == 4
l = [2,3,0,1,4]
assert partitionSeq(l, 0, len(l)-1) == 2
test_partitionSeq()
def test_quicksort():
def _is_sorted(seq):
for i in range(len(seq)-1):
if seq[i] > seq[i+1]:
return False
return True
from random import randint
for i in range(100):
_len = randint(1, 100)
to_sort = []
for i in range(_len):
to_sort.append(randint(0, 100))
quicksort(to_sort, 0, len(to_sort)-1) # 注意这里用了原地排序,直接更改了数组
print(to_sort)
assert _is_sorted(to_sort)
test_quicksort()
利用快排中的partitionSeq操作,我们还能实现另一个算法,nth_element,快速查找一个无序数组中的第k大元素
def nth_element(seq, beg, end, k):
if beg == end:
return seq[beg]
pivot_index = partitionSeq(seq, beg, end)
if pivot_index == k:
return seq[k]
elif pivot_index > k:
return nth_element(seq, beg, pivot_index-1, k)
else:
return nth_element(seq, pivot_index+1, end, k)
def test_nth_element():
from random import shuffle
n = 10
l = list(range(n))
shuffle(l)
print(l)
for i in range(len(l)):
assert nth_element(l, 0, len(l)-1, i) == i
test_nth_element()