接上篇《34、selenium基本概念及安装流程》
上一篇我们介绍了selenium技术的基础概念以及安装和调用的流程,本篇我们来学习selenium的基本语法,包括元素定位以及访问元素信息的操作。
一、元素定位
Selenium元素定位是指通过特定的方法在网页中准确定位到需要操作的元素,例如按钮、文本框、下拉菜单等。以下是一些常用的Selenium元素定位相关的语法:
1、Selenium3.x版本前
在Selenium3.x版本及之前,语法如下:
(1)通过ID定位元素
element = driver.find_element_by_id("element_id")
(2)通过名称定位元素
element = driver.find_element_by_name("element_name")
(3)通过类名定位元素
element = driver.find_element_by_class_name("class_name")
(4)通过标签名定位元素
element = driver.find_element_by_tag_name("tag_name")
(5)通过链接文本定位元素(<a> 标签)
element = driver.find_element_by_link_text("link_text")
(6)通过部分链接文本定位元素(<a> 标签)
element = driver.find_element_by_partial_link_text("partial_link_text")
(7)通过XPath定位元素
element = driver.find_element_by_xpath("xpath_expression")
(8)通过CSS选择器定位元素
element = driver.find_element_by_css_selector("css_selector")
上面都是获取单个元素,要获取多个元素,将其中的element修改为elements即可。
2、Selenium4.x版本后
在Selenium4.x版本后,元素的定位不再是上面这种一个类型一个方法的模式,而是变为两个方法find_element和find_elements:
其中find_element方法返回一个元素(源码):
find_elements方法返回一个列表(源码):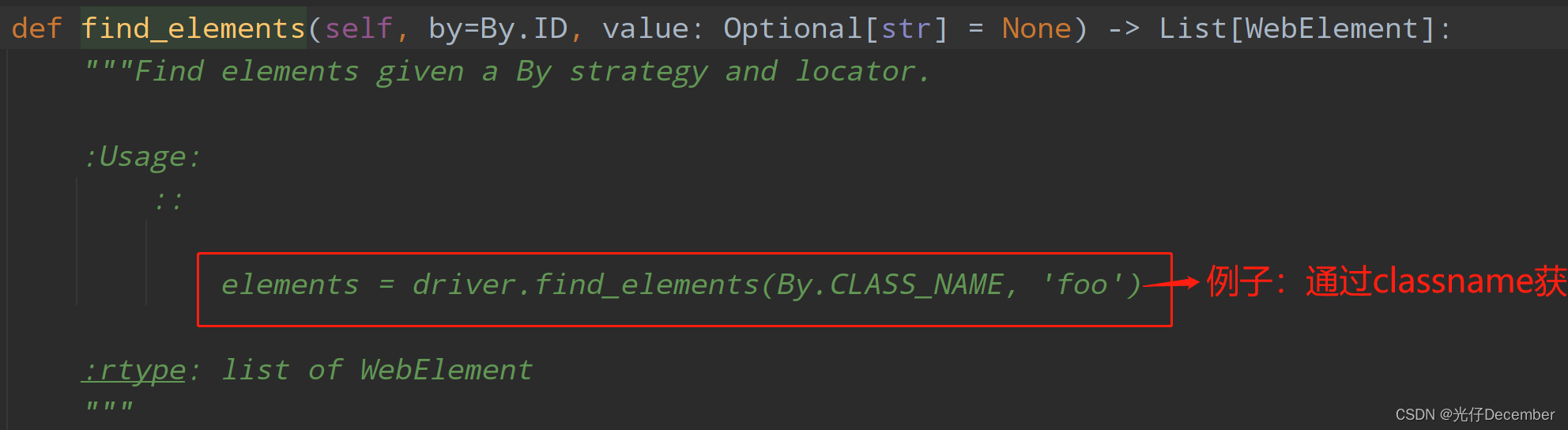
而通过ID还是NAME等获取方式,变为一个By对象的属性,作为参数入参到find_element和find_elements方法中,BY源码如下: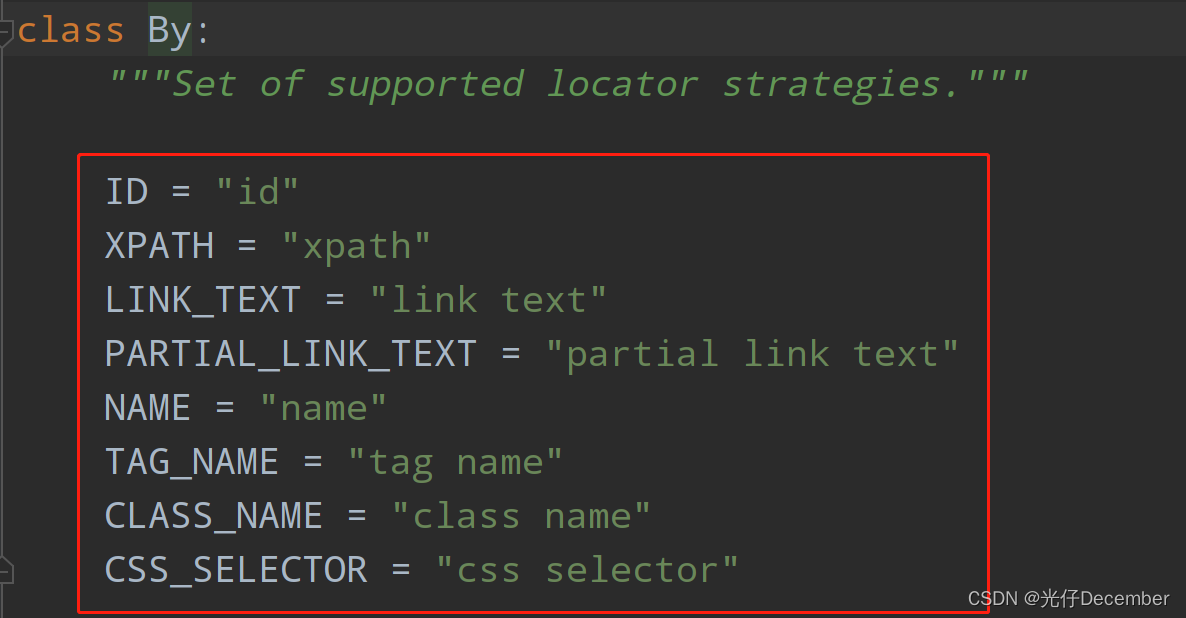
需要通过什么方式获取元素,就“By.方式”即可。
具体的语法示例:
# 根据xpath选择元素(万金油)
driver.find_element(By.XPATH, '//*[@id="kw"]')
# 根据css选择器选择元素
driver.find_element(By.CSS_SELECTOR, '#kw')
# 根据name属性值选择元素
driver.find_element(By.NAME, 'wd')
# 根据类名选择元素
driver.find_element(By.CLASS_NAME, 's_ipt')
# 根据链接文本选择元素
driver.find_element(By.LINK_TEXT, 'hao123')
# 根据包含文本选择
driver.find_element(By.PARTIAL_LINK_TEXT, 'hao')
# 根据标签名选择
# 目标元素在当前html中是唯一标签或众多标签第一个时候使用
driver.find_element(By.TAG_NAME, 'title')
# 根据id选择
driver.find_element(By.ID, 'su') 以上是一些常见的Selenium元素定位方法。根据需要,我们可以使用这些语法来定位网页中的元素并进行操作。
二、元素访问
Selenium元素通过定位和访问网页上的元素,可以模拟用户与网页的交互操作,通过访问和操作元素,自动执行各种操作,如点击按钮、输入文本、填写表单、选择下拉框等用户界面操作,从而完成各种网页任务。
1、获取元素文本
element_text = element.text将元素的可见文本内容作为字符串返回。
2、获取元素属性
attribute_value = element.get_attribute("attribute_name")获取元素指定属性的值,例如"href"属性。
3、执行点击操作
element.click()模拟用户点击元素,触发相应的事件。
4、输入文本到输入框
element.send_keys("text")将指定文本输入到文本框或输入框中。
5、提交表单
element.submit()提交包含该元素的表单。
6、切换到iframe
driver.switch_to.frame(element)切换到指定的iframe或frame中,以便在其中进行操作。
这些语法示例展示了常见的功能,我们可以根据具体需求选择相应的方法来访问和操作网页中的元素。
三、元素定位及访问示例
我们按照类似上一章节访问百度首页的例子,来应用一下上述元素定位及访问的方法。完整代码如下:
# _*_ coding : utf-8 _*_
# @Time : 2023-09-09 19:31
# @Author : 光仔December
# @File : selenium元素定位及获取测试
# @Project : Python_Projects
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化浏览器驱动程序
driver = webdriver.Chrome()
try:
# 打开网页
driver.get('https://www.baidu.com')
# (1)通过ID定位百度搜索的按钮
element1 = driver.find_element(By.ID, "su")
# 获取按钮中的字符串并打印
print("百度搜索首页按钮上的字是:", element1.get_attribute("value"))
# (2)通过名称定位元素(百度的搜索输入框)
element2 = driver.find_element(By.NAME, "wd")
# 给输入框输入字符串“我要学python”
element2.send_keys("我要学python")
element1.click() # 点击搜索
# (3)通过类名定位元素(获取输入框右侧的小相机图标)
element3 = driver.find_element(By.CLASS_NAME, "soutu-btn")
print("百度搜索框图标class名是:", element3.get_attribute("class"))
# (4)根据css选择器选择元素
element4 = driver.find_element(By.CSS_SELECTOR, '#s_lg_img_new')
print("百度首页Logo图片的src是:", element4.get_attribute("src"))
# (5)根据链接文本选择元素(获取首页贴吧的地址)
element5 = driver.find_element(By.LINK_TEXT, '贴吧')
print("百度首页贴吧的href是:", element5.get_attribute("href"))
# (6)根据包含文本选择(获取首页带“图”字的元素,及其链接)
element6 = driver.find_elements(By.PARTIAL_LINK_TEXT, '图')
# 遍历获取到的元素集合
i = 1
print("百度首页带”图“字的超链接地址:")
for ele in element6:
print(f" 第{i}个连接名为【{ele.text}】,href是:{ele.get_attribute('href')}")
i += 1
# (7)根据标签名选择
# 目标元素在当前html中是唯一标签或众多标签第一个时候使用
element7 = driver.find_element(By.TAG_NAME, 'body')
print("百度首页body的class:", element7.get_attribute("class"))
# 等待10秒看结果
time.sleep(10)
finally:
# 关闭浏览器
driver.close()效果: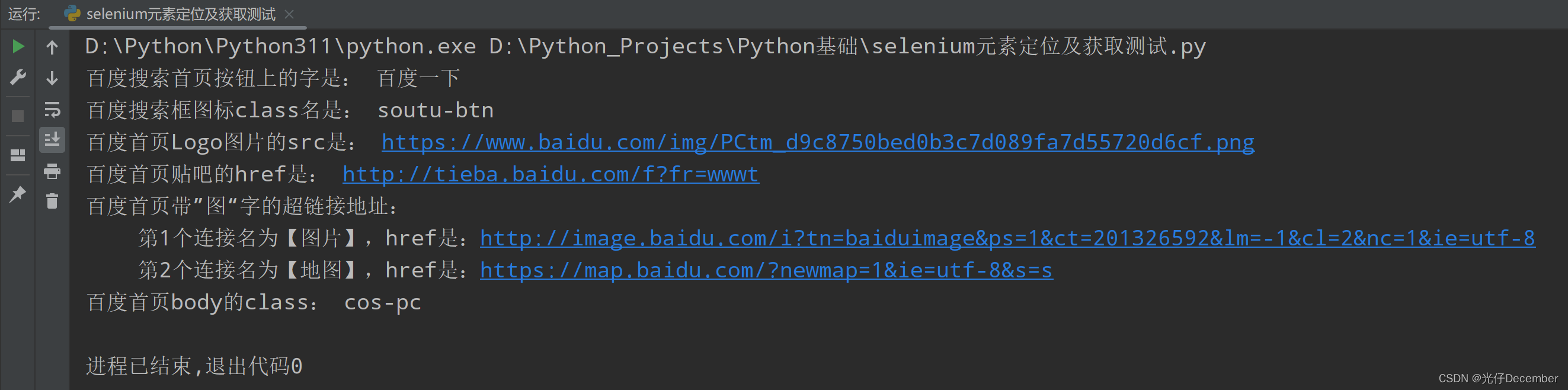
下一篇我们继续讲解Selenium交互相关的内容。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://guangzai.blog.csdn.net/article/details/132781705