一、Apriori算法的前置知识
Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和向下封闭检测两个阶段来挖掘频繁项集。
关联规则挖掘是数据挖掘中最活跃的研究方法之一,最初的动机是针对购物篮分析问题提出的,其目的是为了发现交易数据库中不同商品之间的练习规则。通过用户给定的最小支持度,寻找所有频繁项目集,即满足Support不小于Minsupport的所有项目子集。通过用户给定的最小可信度,在每个最大频繁项目集中,寻找Confidence不小于Minconfidence的关联规则。
支持度:支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。
置信度:置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
二、Apriori算法的基本思想
首先扫描数据库中所需要进行分析的数据,在设置完支持度以及置信度以后,在最小支持度的支持下产生频繁项,即统计所有项目集中包含一个或一个以上的元素频数,找出大于或者等于设置的支持度的项目集。其次就是频繁项的自连接。再者是如果对频繁项自连接以后的项的子集如果不是频繁项的话,则进行剪枝处理。接着对频繁项处理后产生候选项。最后循环调用产生频繁项集。
三、Apriori算法和强关联规则挖掘的例子
Apriori算法例子
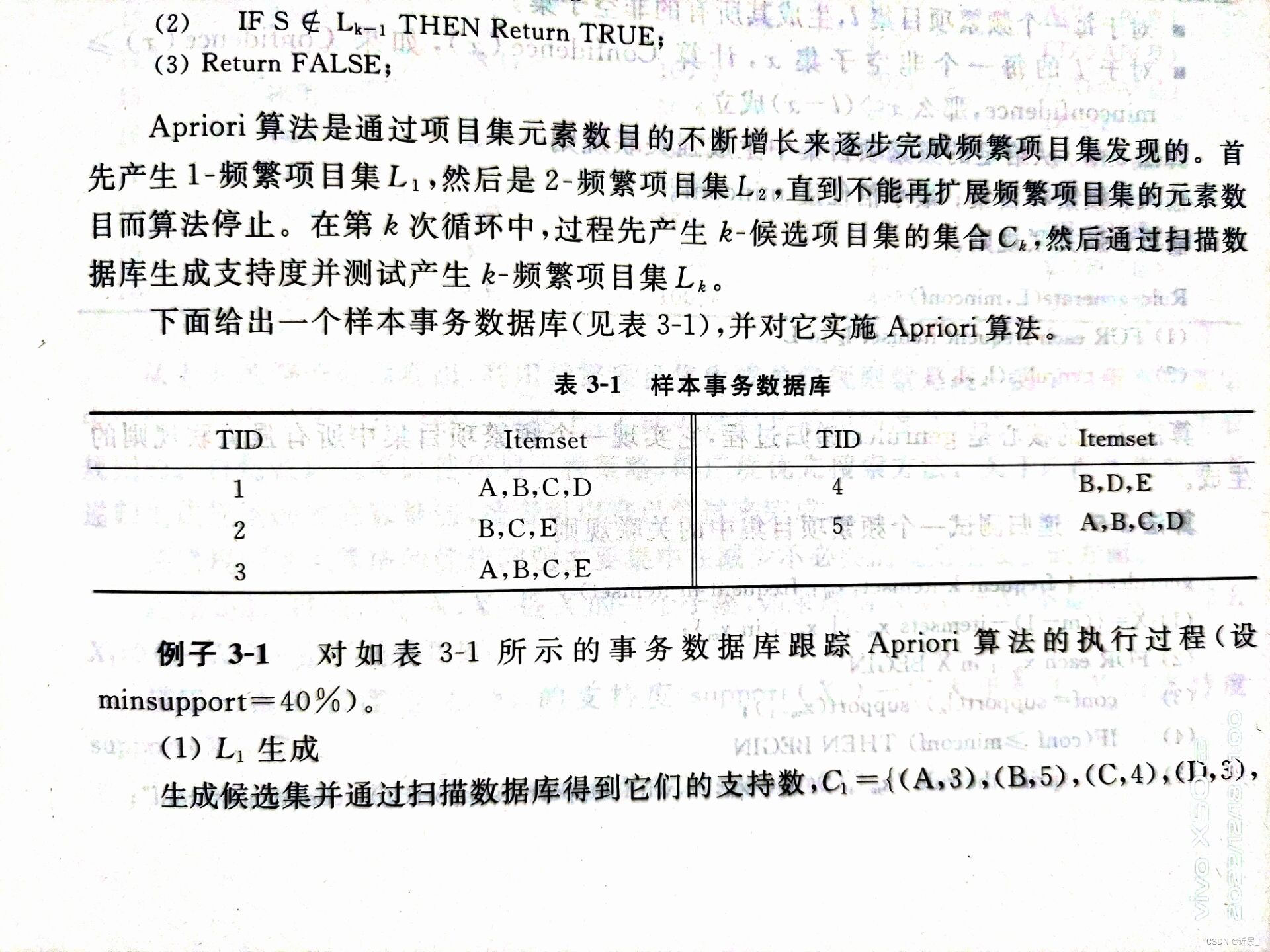

挖掘强关联规则的算法例子
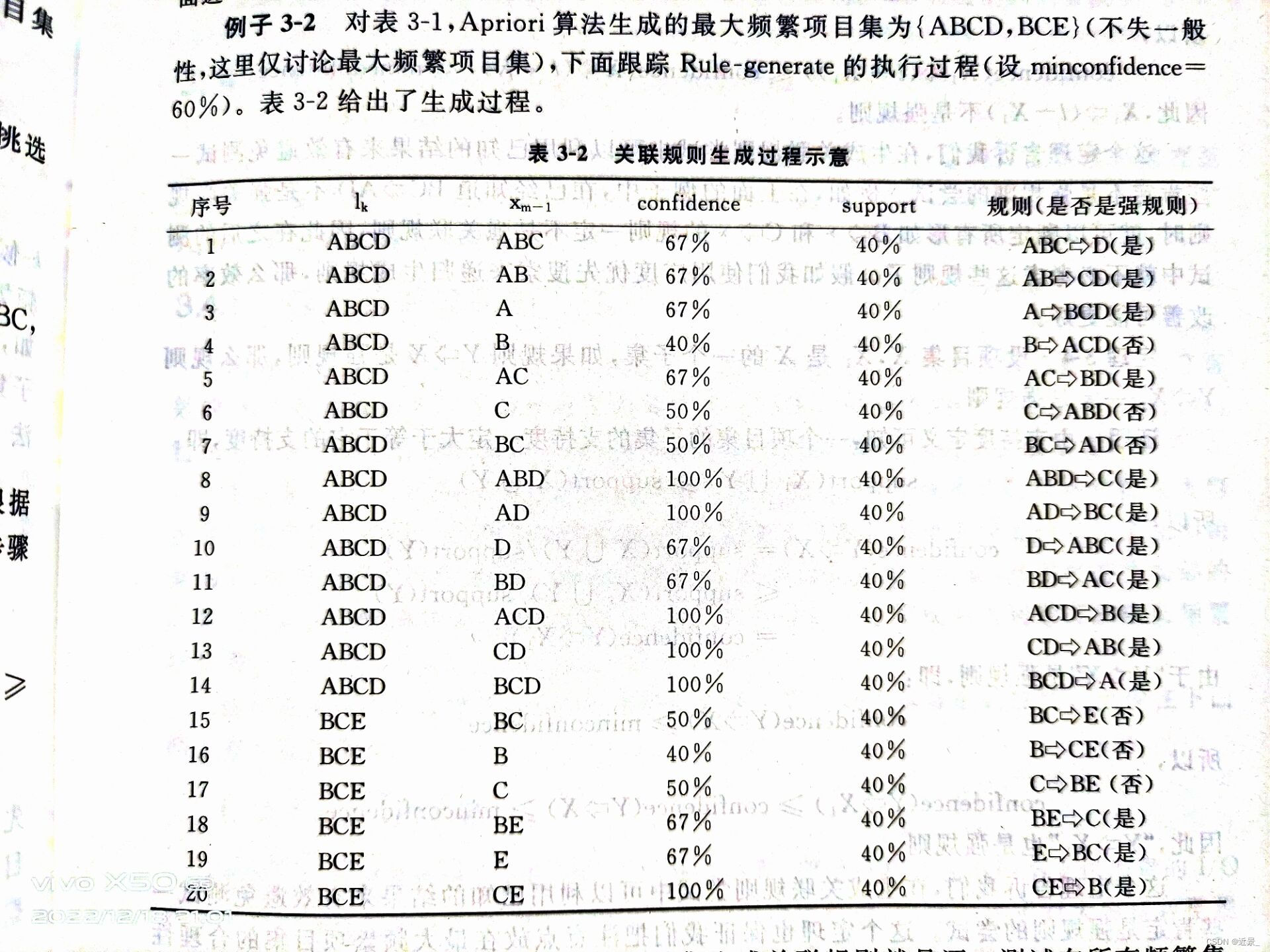
四、Apriori算法的实现过程
实验内容
有如下的交易记录,请编写程序实现Apriori算法,挖掘该交易记录里的频繁项集,并挖掘出所有的强关联规则,设最小支持度为50%,最小置信度为50%:
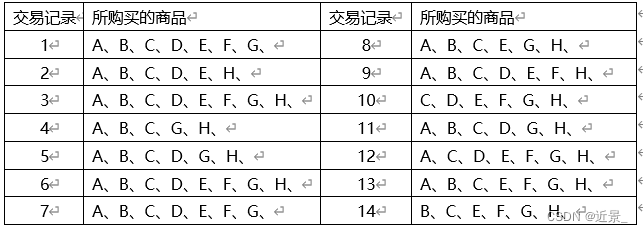
实验思路
(1)定义数据集、最小支持度、最小支持数、最小置信度以及存放所有频繁项目集的Map集合。调用就封装好的initDataList()方法对数据进行初始化。
(2)调用getAllElement()方法获取到数据集所含有的所有类别元素allElement,将allElement数组进行排列组合获取候选集candidateL1。调用getItemSets()方法遍历candidateL1,将出现次数不小于最小支持数minSupportCount的项加入到itemSets中,遍历结束,获取到1-频繁项目集L1,并将L1打印输出。
(3)开始循环找k-频繁项目集,直到得到的k-频繁项目集Lk为空,跳出循环。在循环体内部,将k-1-候选集candidateLast所含有的所有类别元素allElementLast作为参数调用getCombination()方法,获取k-候选集candidateNow,遍历k-候选集,将出现次数不小于最小支持数的项加入到itemSets并返回,得到频繁项目集Lk。如果k-频繁项集为空,则结束循环,若Lk不为空,则将Lk加入到存放所有频繁项目集allItemSets的集合中,方便之后找强关联规则。
(4)调用correlation()方法进行强关联规则的挖掘。在方法体内部,遍历所有的频繁项目集,得到每一项频繁项目集的非空子集集合subSet,遍历每一项频繁项目集的非空子集,以此非空子集和此频繁项目集作为参数,调用isConfidence()方法判断是否满足置信度大于最小置信度,若满足,则输出此非空子集==>非空子集的补集。
实现源码
package com.data.mining.main;
import com.google.common.collect.ArrayListMultimap;
import com.google.common.collect.Multimap;
import org.paukov.combinatorics3.Generator;
import org.paukov.combinatorics3.IGenerator;
import java.util.*;
public class Apriori {
//定义单行数据
public static String[] item1,item2,item3,item4,item5,item6,item7,item8,item9,item10,item11,item12,item13,item14;
//定义数据集
public static List<String[]> dataList = new ArrayList<>();
//定义最小支持度
public static double minSupport = 0.5;
//定义最小支持数
public static double minSupportCount = 0.0;
//定义最小置信度
public static double minConfidence = 0.5;
//存放所有频繁项目集
public static Map<Integer, Multimap<Integer, String[]>> allItemSets = new HashMap<>();
public static void main(String[] args) {
// 初始化数据集
initDataList();
String[] allElement = getAllElement(dataList);
//获取候选集L1
List<String[]> candidateL1 = getCombination(allElement, 1);
Multimap<Integer, String[]> itemSetsL1 = getItemSets(candidateL1);
allItemSets.put(1, itemSetsL1);
printResult(itemSetsL1, 1);
List<List<String[]>> stack = new ArrayList<>();
stack.add(candidateL1);
for (int k = 2; true; k++) {
List<String[]> candidateLast = stack.get(0);
String[] allElementLast = getAllElement(candidateLast);
List<String[]> candidateNow = getCombination(allElementLast, k);
Multimap<Integer, String[]> itemSetsLk = getItemSets(candidateNow);
if (itemSetsLk.isEmpty()) break;
allItemSets.put(k, itemSetsLk);
printResult(itemSetsLk, k);
stack.remove(0);
stack.add(candidateNow);
}
correlation();
}
public static boolean isConfidence(String[] subSetStr1, String[] value){
double confidence = getCountByConfidence(value) * 1.0 / getCountByConfidence(subSetStr1);
if (confidence >= minConfidence) return true;
return false;
}
public static Integer getCountByConfidence(String[] subSetStr){
int count = 0; //存放子集在数据集中出现的次数
for (String[] dataItem : dataList) {
//比如在数据集第一项{A,B,C,D,E,F,G}中是否出现过A,B.C
int index = -1;
for (int i = 0; i < subSetStr.length; i++) {
//比如A出现过,则index>0,若A没出现过,则index=-1
index = Arrays.binarySearch(dataItem, subSetStr[i]);
if (index < 0) break;
}
if (index >= 0){ //出现过ABC
count++;
}
}
return count;
}
/**
* 找强关联规则
*/
public static void correlation(){
//遍历所有频繁项目集
for (int k = 1; k <= allItemSets.size(); k++) {
//获取k-频繁项目集
Multimap<Integer, String[]> keyItemSet = allItemSets.get(k);
Iterator<Map.Entry<Integer, String[]>> iterator = keyItemSet.entries().iterator();
//遍历k频繁项目集
while (iterator.hasNext()){
Map.Entry<Integer, String[]> entry = iterator.next();
String[] value = entry.getValue();
// List<String> valueList = Arrays.asList(value);
// List<String> valueList = new ArrayList<>();
// Collections.addAll(valueList, value);
//求value的非空子集
for (int i = 1; i < value.length; i++) {
List<String[]> subSet = getCombination(value, i); //非空子集的集合
for (String[] subSetItem : subSet) { //subSetItm是频繁项目集每一个非空子集
List<String> valueList = new ArrayList<>();
Collections.addAll(valueList, value);
List<String> subSetItemList = Arrays.asList(subSetItem);
//去除已经求得子集后的valueList
valueList.removeAll(subSetItemList); //此时valueList中存放非空子集的补集
if (isConfidence(subSetItem, value)){
System.out.println(Arrays.toString(subSetItem) + "==>" + Arrays.toString(valueList.toArray(new String[valueList.size()])));
}
}
}
}
}
}
/**
* 打印出所有频繁项目集
* @param itemSet
* @param k
*/
public static void printResult(Multimap<Integer, String[]> itemSet, int k){
System.out.print("L" + k + "----------->");
//使用迭代器遍历multimap
Iterator<Map.Entry<Integer, String[]>> iterator = itemSet.entries().iterator();
//遍历排列组合结果的每一项,将出现次数不小于minSupportCount的项加入到itemSets
while (iterator.hasNext()){
Map.Entry<Integer, String[]> entry = iterator.next();
// System.out.println("key = " + entry.getKey() + "," + Arrays.toString(entry.getValue()));
String[] value = entry.getValue();
for (int i = 0; i < value.length; i++) {
System.out.print(value[i]);
}
System.out.print(",");
}
System.out.println("");
// System.out.println("-------------------------k=" + k + "-----------------------------------");
}
/**
* 获取含有所有元素的数组
* @param itemSet
* @return
*/
public static String[] getAllElement(List<String[]> itemSet){
List<String> allElementList = new ArrayList<>(); //存放项目集中所有有的元素
for (int i = 0; i < itemSet.size(); i++) {
String[] item = itemSet.get(i);
if (i == 0){ //将第一项的所有元素加入到allElementList中
for (int j = 0; j < item.length; j++) {
allElementList.add(item[j]);
}
}else {
for (int z = 0; z < item.length; z++) {
//判断allElementList中是否已经存在item[z]
int isExist = Arrays.binarySearch(allElementList.toArray(new String[allElementList.size()]), item[z]);
if (isExist < 0){ //不存在item[z]
allElementList.add(item[z]); //添加item[z]到allElementList中
}
}
}
}
return allElementList.toArray(new String[allElementList.size()]);
}
/**
* 获取候选集
* @param allItemStr 含频繁项目集所有元素的数组
* @param k 要生成k候选集
* @return
*/
public static List<String[]> getCombination(String[] allItemStr, int k){
//定义候选集
List<String[]> candidateSets = new ArrayList<>();
//对allItemStr进行k组合
IGenerator<List<String>> candidateList = Generator.combination(allItemStr).simple(k);
for (List<String> candidate : candidateList) {
String[] candidateStr = candidate.toArray(new String[candidate.size()]);
candidateSets.add(candidateStr);//将每一项组合放入候选集中
}
return candidateSets;
}
/**
* 处理候选集,获取频繁项目集
* @param itemList 候选集
* @return 频繁项目集
*/
public static Multimap<Integer, String[]> getItemSets(List<String[]> itemList){
Multimap<Integer, String[]> itemSets = ArrayListMultimap.create(); //项目集
//得到排列组合结果(候选集)每一项在数据集中出现的次数
Multimap<Integer, String[]> itemCount = getItemCount(itemList);
//使用迭代器遍历multimap
Iterator<Map.Entry<Integer, String[]>> iterator = itemCount.entries().iterator();
//遍历排列组合结果的每一项,将出现次数不小于minSupportCount的项加入到itemSets
while (iterator.hasNext()){
Map.Entry<Integer, String[]> entry = iterator.next();
if (entry.getKey() >= minSupportCount){
itemSets.put(entry.getKey(), entry.getValue());
}
}
return itemSets;
}
/**
* 获取排列组合结果(候选集)每一项在数据集中出现的次数
* @param itemList
* @return
*/
public static Multimap<Integer, String[]> getItemCount(List<String[]> itemList){
Multimap<Integer, String[]> itemCount = ArrayListMultimap.create();
//遍历项目集
for (String[] item : itemList) {
int count = 0; //存放A,B.C在数据集中出现的次数
for (String[] dataItem : dataList) {
//比如在数据集第一项{A,B,C,D,E,F,G}中是否出现过A,B.C
int index = -1;
for (int i = 0; i < item.length; i++) {
//比如A出现过,则index>0,若A没出现过,则index=-1
index = Arrays.binarySearch(dataItem, item[i]);
if (index < 0) break;
}
if (index >= 0){ //出现过ABC
count++;
}
}
itemCount.put(count, item); //存放(ABC出现的次数,{A,B,C})
}
return itemCount;
}
/**
* 初始化数据集
*/
public static void initDataList(){
//初始化单行数据
item1 = new String[]{"A", "B", "C", "D", "E", "F", "G"};
item2 = new String[]{"A", "B", "C", "D", "E", "H"};
item3 = new String[]{"A", "B", "C", "D", "E", "F", "G", "H"};
item4 = new String[]{"A", "B", "C", "G", "H"};
item5 = new String[]{"A", "B", "C", "D", "G", "H"};
item6 = new String[]{"A", "B", "C", "D", "E", "F", "G", "H"};
item7 = new String[]{"A", "B", "C", "D", "E", "F", "G"};
item8 = new String[]{"A", "B", "C", "E", "G", "H"};
item9 = new String[]{"A", "B", "C", "D", "E", "F", "H"};
item10 = new String[]{"C", "D", "E", "F", "G", "H"};
item11 = new String[]{"A", "B", "C", "D", "G", "H"};
item12 = new String[]{"A", "C", "D", "E", "F", "G", "H"};
item13 = new String[]{"A", "B", "C", "E", "F", "G", "H"};
item14 = new String[]{"B", "C", "E", "F", "G", "H"};
//初始化数据集
dataList.add(item1);
dataList.add(item2);
dataList.add(item3);
dataList.add(item4);
dataList.add(item5);
dataList.add(item6);
dataList.add(item7);
dataList.add(item8);
dataList.add(item9);
dataList.add(item10);
dataList.add(item11);
dataList.add(item12);
dataList.add(item13);
dataList.add(item14);
//赋值给最小支持的数
minSupportCount = dataList.size() * minSupport;
}
}
实验结果
所有的频繁项目集:

所有的强关联规则实在太多,放不下,就展示如图所示的一部分,请各位自行测试:
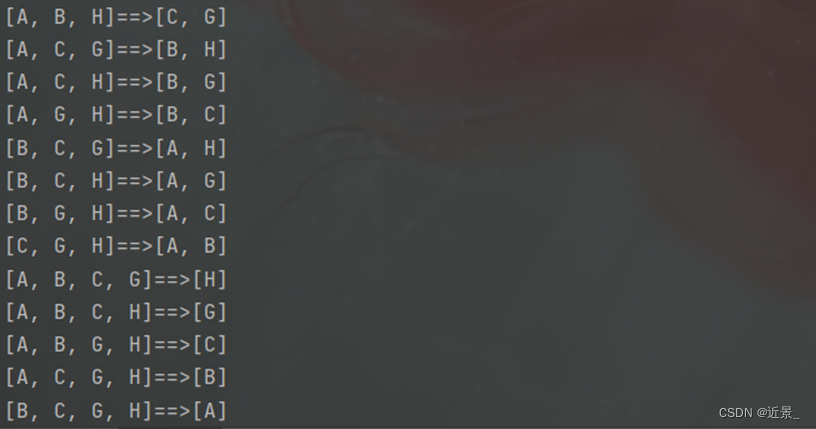
五、实验总结
本实验结果笔者并不保证一定是正确的,笔者仅仅是提供一种使用Java语言实现Apriori算法的思路。因为实验并没有给答案,笔者已将网络上有答案的实验数据输入程序后,程序输出的结果和答案一致,所以问题应该不大。若有写的不到位的地方,还请各位多多指点!
笔者主页还有其他数据挖掘算法的总结,欢迎各位光顾!
![[附源码]Node.js计算机毕业设计工会会员管理系统Express](https://img-blog.csdnimg.cn/ff8f6a2bc9d44ccabecadeeed1787a8b.png)