项目中有几个batch需要检查所有的用户参与的活动的状态,以前是使用分页,一页一页的查出来到内存再处理,但是随着数据量的增加,效率越来越低。于是经过一顿搜索,了解到流式查询这么个东西,不了解不知道,这一上手,爱的不要不要的,效率贼高。项目是springboot 项目,持久层用的mybatis,整好mybatis的版本后,又研究了一下JPA的版本,做事做全套,最后又整了原始的JDBCTemplate 版本。废话不多说,代码如下:
第一种方式: springboot + mybatis 流式查询(网上说的有三种,我觉得下面这种最简单,对业务代码侵入性最小)
a) service 层代码:
package com.example.demo.service;
import com.example.demo.bean.CustomerInfo;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Transactional
public void testStreamQuery(Integer status) {
mybatisStreamQuery(status);
}
private void mybatisStreamQuery(Integer status) {
log.info("waiting for query.....");
Cursor<CustomerInfo> customerInfos = userMapper.getCustomerInfo(status);
log.info("finish query!");
for (CustomerInfo customerInfo : customerInfos) {
//处理业务逻辑
log.info("===============>{}", customerInfo.getId());
}
}
}
需要注意的有两点:
1.是userMapper 返回的是一个Cursor类型,其实就是用游标。然后遍历这个cursor,mybatis就会按照你在userMapper里设置的fetchSize 大小,每次去从数据库拉取数据
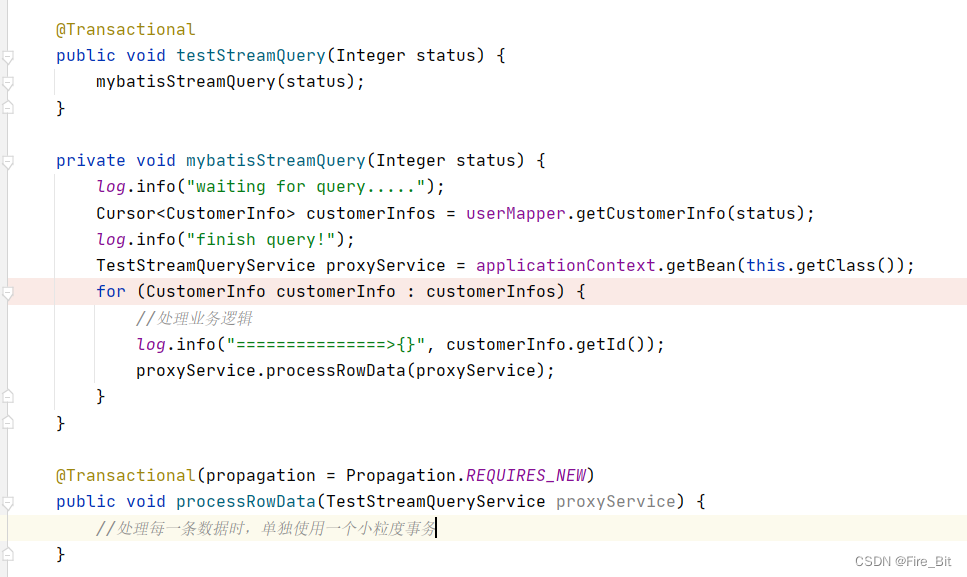
2.注意 testStreamQuery 方法上的 @transactional 注解,这个注解是用来开启一个事务,保持一个长连接(就是为了保持长连接采用的这个注解),因为是流式查询,每次从数据库拉取固定条数的数据,所以直到数据全部拉取完之前必须要保持连接状态。(顺便提一下,如果说不想让在这个testStreamQuery 方法内处理每条数据所作的更新或查询动作都在这个大事务内,那么可以另起一个方法 使用required_new 的事务传播,使用单独的事务去处理,使事务粒度最小化。如下图:)
b) mapper 层代码:
package com.example.demo.mapper;
import com.example.demo.bean.CustomerInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.stereotype.Repository;
@Mapper
@Repository
public interface UserMapper {
Cursor<CustomerInfo> getCustomerInfo(Integer status);
}
mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<select id="getCustomerInfo" resultType="com.example.demo.bean.CustomerInfo" fetchSize="2" resultSetType="FORWARD_ONLY">
select * from table_name where status = #{status} order by id
</select>
</mapper>
UserMapper.java 无需多说,其实要注意的是mapper.xml中的配置:fetchSize 属性就是上一步说的,每次从数据库取多少条数据回内存。resultSetType属性需要设置为 FORWARD_ONLY, 意味着,查询只会单向向前读取数据,当然这个属性还有其他两个值,这里就不展开了。
至此,springboot+mybatis 流式查询就可以用起来了,以下是执行结果截图:
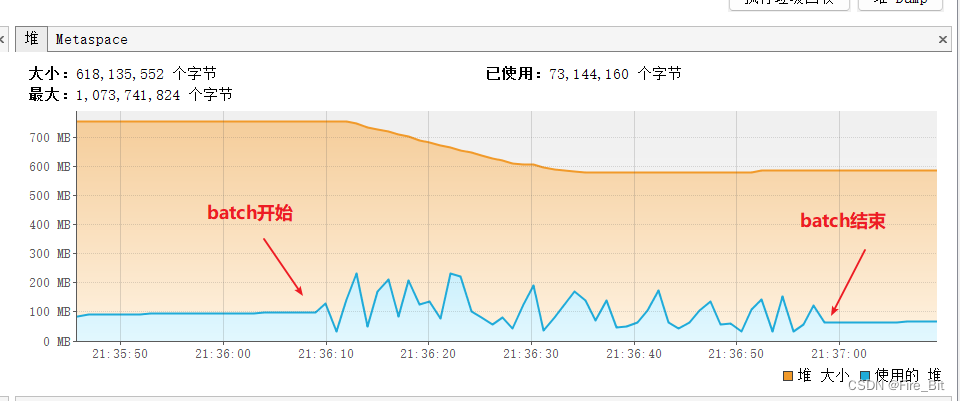
c)读取200万条数据,每次fetchSize读取1000条,batch总用时50s左右执行完,速度是相当可以了,堆内存占用不超过250M,这里用的数据库是本地docker起的一个postgre, 远程数据库的话,耗时可能就不太一样了
第二种方式:springboot+JPA 流式查询
a) service层代码:
package com.example.demo.service;
import com.example.demo.dao.CustomerInfoDao;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import java.util.stream.Stream;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Resource
private CustomerInfoDao customerInfoDao;
@Resource
private EntityManager entityManager;
@Transactional(readOnly = true)
public void testStreamQuery(Integer status) {
jpaStreamQuery(status);
}
public void jpaStreamQuery(Integer status) {
Stream<com.example.demo.entity.CustomerInfo> stream = customerInfoDao.findByStatus(status);
stream.forEach(customerInfo -> {
entityManager.detach(customerInfo); //解除强引用,避免数据量过大时,强引用一直得不到GC 慢慢会OOM
log.info("====>id:[{}]", customerInfo.getId());
});
}
}
注意点:1. 这里的@transactional(readonly=true) 这里的作用也是保持一个长连接的作用,同时标注这个事务是只读的。
2. 循环处理数据时需要先:entityManager.detach(customerInfo); 解除强引用,避免数据量过大时,强引用一直得不到GC 慢慢会OOM。
b) dao层代码:
package com.example.demo.dao;
import com.example.demo.entity.CustomerInfo;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.QueryHints;
import org.springframework.stereotype.Repository;
import javax.persistence.QueryHint;
import java.util.stream.Stream;
import static org.hibernate.jpa.QueryHints.HINT_FETCH_SIZE;
@Repository
public interface CustomerInfoDao extends JpaRepository<CustomerInfo, Long> {
@QueryHints(value=@QueryHint(name = HINT_FETCH_SIZE,value = "1000"))
Stream<CustomerInfo> findByStatus(Integer status);
}注意点:1.dao方法的返回值是 Stream 类型
2.dao方法的注解:@QueryHints(value=@QueryHint(name = HINT_FETCH_SIZE,value = "1000")) 这个注解是设置每次从数据库拉取多少条数据,自己可以视情况而定,不可太大,反而得不偿失,一次读取太多数据数据库也是很耗时间的。。。
自此springboot + jpa 流式查询代码就贴完了,可以happy了,下面是执行结果:
c) batch读取两百万条数据,堆内存使用截图:
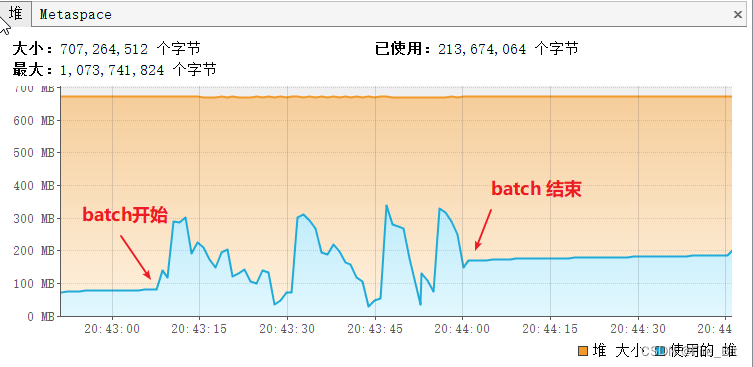
每次fetchSize拉取1000条数据,可以看到内存使用情况:初始内存不到100M,batch执行过程中最高内存占用300M出头然后被GC。读取效率:不到一分钟执行完(处理每一条数据只是打印一下id),速度还是非常快的。
d) 读取每一条数据时,不使用 entityManager.detach(customerInfo),内存使用截图:
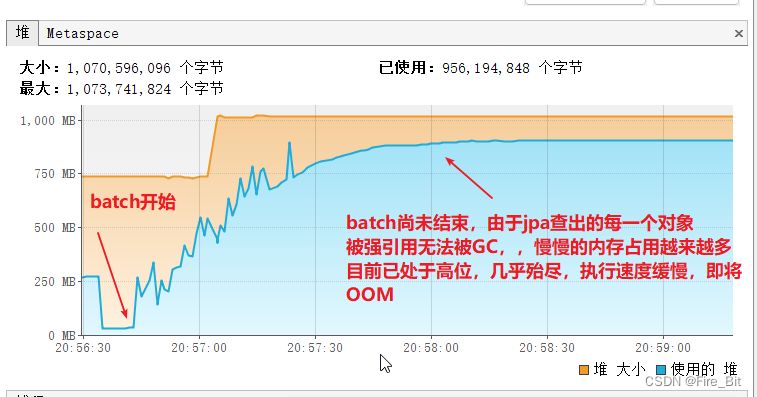
最终OOM了,这里的entityManager.detach(customerInfo) 很关键。
第三种方式:使用JDBC template 流式查询
其实这种方式就是最原始的jdbc的方式,代码侵入性很大,逼不得已也不会使用
a) 上代码:
package com.example.demo.service;
import com.example.demo.dao.CustomerInfoDao;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Resource
private CustomerInfoDao customerInfoDao;
@Resource
private EntityManager entityManager;
public void testStreamQuery(Integer status) {
jdbcStreamQuery(status);
}
private void jdbcStreamQuery(Integer status) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = jdbcTemplate.getDataSource().getConnection();
conn.setAutoCommit(false);
pstmt = conn.prepareStatement("select * from customer_info where status = " + status + " order by id", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(1000);
pstmt.setFetchDirection(ResultSet.FETCH_FORWARD);
rs = pstmt.executeQuery();
while (rs.next()) {
long id = rs.getLong("id");
String name = rs.getString("name");
String email = rs.getString("email");
int sta = rs.getInt("status");
log.info("=========>id:[{}]", id);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
try {
rs.close();
pstmt.close();
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
b) 执行结果:200万数据不到50秒执行完,内存占用最高300M

自此,针对不同的持久层框架, 使用不同的流式查询,其实本质是一样的,归根结底还是驱动jdbc做事情。以上纯个人见解,若有不当之处,请不吝指出,共同进步!