网络分类
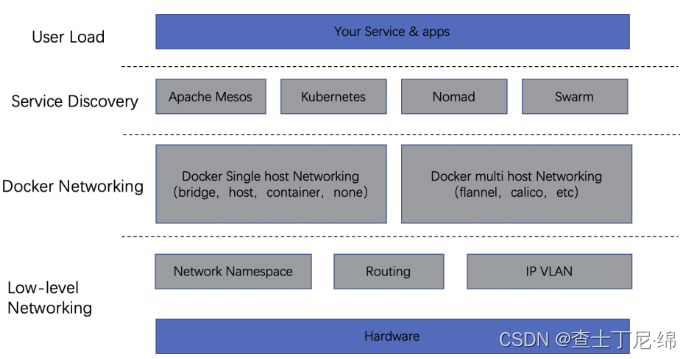
docker网络解决方案基于openstack平台,后演化为两派:一个是docker原生的CNM(Container Network Model),另一个是兼容性更好的CNI(Container Network Interface)
单主机网络:CNM
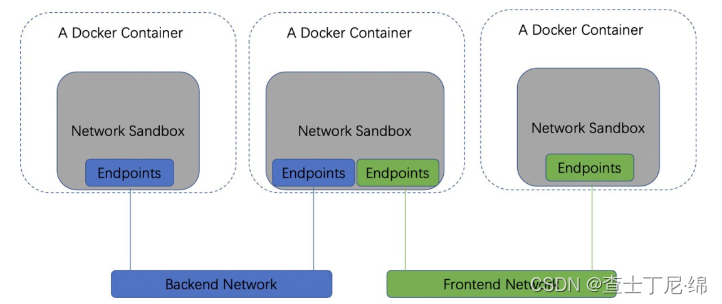
CNM模型由Sandbox、Endpoint、Network三部分组成。在linux系统中docker的典型表现是Container、Network namespace,Sandbox三者绑定。
1、sandbox:包含了相关网络配置,如:网卡interface,路由表等,一个sandbox可以包含多个 endpoint,endpoint可以来自多个网络。
2、endpoint: 每个Endpoint都是由某个Network创建,创建后就归属于该Network。同时Endpoint还可以加入一个 Sandbox,加入后,相当于该 Sandbox也加入了此Network。endpoint通过vethpair互联sandbox与network
3、Network:Network的一种典型实现是linux bridge。一个Network可以创建多个Endpoint,将多个Endpoint加入到Sandbox,即实现了多个 Sandbox 的互通。
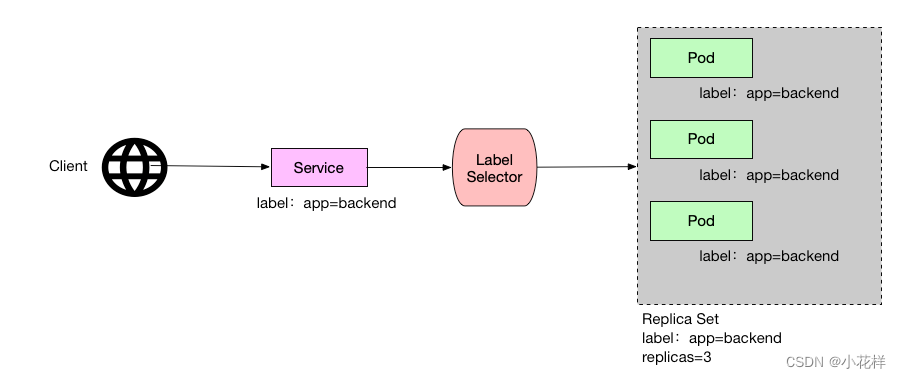
总结:如果让两个Container之间可以直接通信,那么最简单的办法就是由一个Network创建两个 Endpoint,分别加入这两个 Container 对应的Sandbox。而不同 Network之间默认的隔离性是docker 通过设置iptables完成的,通过改变iptables的设置,可以使得不同network互通。
CNM标准网络模式
1、host模式:–net=host
2、container模式:–net=container:Name_or_ID
3、none模式:–net=none
4、bridge模式:–net=bridge,默认值
桥接模式:docker为每个容器分配ip地址,并创建vethpair连接到主机的桥接网卡上。连接到同一个桥接设备的容器,均可实现互联互通。如果容器要对外界提供服务,则用户需要将容器内的服务端口与宿主机的某一端口绑定。这样所有访问宿主机目标端口的请求都将通过Docker代理转发到容器的服务端,最终到达应用。
主机模式:容器直接使用宿主机的网络设备,要求容器具有更高的权限,该模式会占用宿主机的端口资源。因此只有特殊需求的容器才会使用这种模式。(如OpenShift集群中的Router组件,Router主机需要监听计算节点上的端口,以接受外部的请求,因此Router组件的Pod的容器网络为主机模式)
多主机网络:CNI
CNI提供了一种linux的应用容器的插件化网络解决方案,其接口设计非常简洁,不需要守护进程,只有两个接口ADD/DELETE,通过一个简单的shell脚本就可以完成。相对于CNM的复杂设计,CNI更加适合快速开发和迭代。而且不光兼容docker,而是提供一种普适的容器网络解决方案。
模型涉及两个概念:
1、容器:拥有独立Linux网络命名空间的独立单元。
2、网络(Networking):指拥有各自独且立唯一的ip地址、可以相互联系的一组实体。这些实体可以是容器、物理机,或是其他网络设备(路由器)等。
网络的设计主要解决以下使用场景:
1、容器到容器的直接通信;
2、Pod到Pod的通信;
3、Pod到Service的通信;
4、集群外与集群内的通信;
容器到容器的通信
同一个Pod内的容器共享同一个网络命名空间,共享同一个linux协议栈,直接用本地ipc进行通信。所以对于网络的各类操作,如同在同一台主机上一样,多个容器甚至可以用localhost地址访问彼此的端口。优点是简单、安全和高效,减少容器移植的难度。
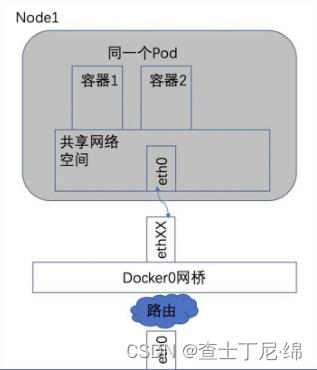
pod到pod的通信
全局条件:每一个pod都有一个真实且唯一的IP地址。
同node的pod之间通信
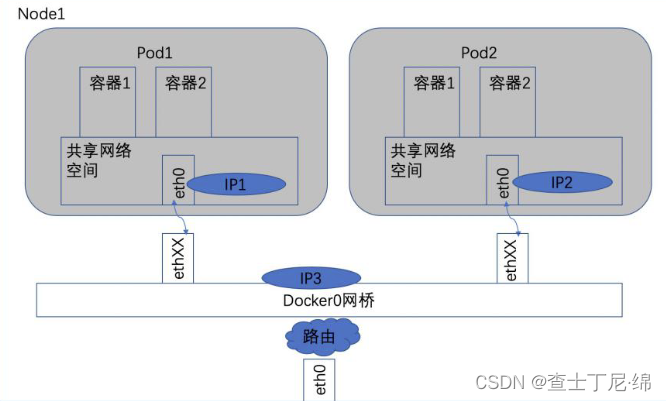
pod1、pod2都是通过veth连接在同一个docker0虚拟网卡上,ip地址ip1、ip2都是桥接获取,与ip3同网段。在linux协议栈上,默认路由都是Docker0的地址,也就是说所有非本地的网络数据,都会被默认发送到docker0上,再由docker0按策略中转,以此实现互联互通。
不同node的pod之间通信
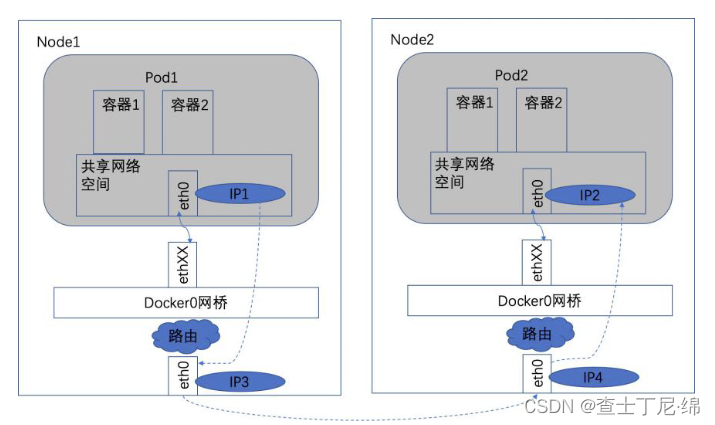
k8s网络对pod的地址是平面、直达的,集群会记录所有正在运行pod的私有ip地址,并保存在etcd中(作为Service的Endpoint)
前置条件:
1、docker0虚拟网卡的网段与宿主机物理网卡的网段可能是不同的
2、通过宿主机的ip地址进行跨主机通信
3、要求pod到pod使用私有ip地址进行通信
实现原理:
1、保证每一个node上的docker0的ip地址唯一(网络插件flannel可实现地址资源池的分配)
2、pod1将数据从源node1的物理网卡发送,到达node2的物理网卡再转到pod2的网卡,即:ip1->ip3->ip4->ip2
pod到service的通信
service是对一组功能相同pod的抽象,k8s在创建service时会为其分配一个虚拟的cluster ip,客户端通过访问这个虚拟的ip地址来访问服务,而服务则负责将请求转发到后端的Pod上。
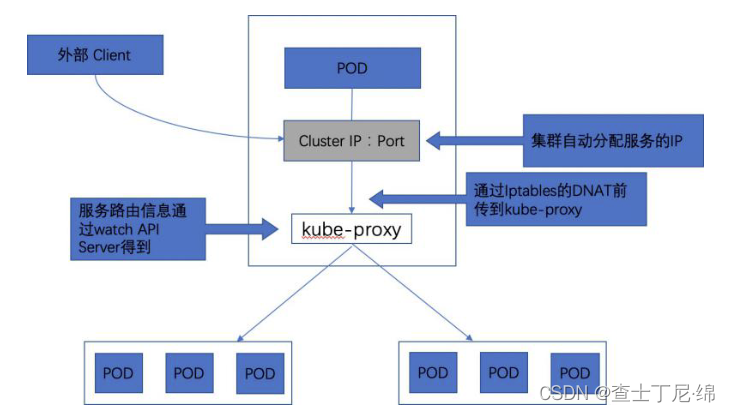
真正实现service作用的是worker节点的kube-proxy服务进程。对每一个tcp类型的service,kube-proxy都会在本地Node上建立一个SocketServer来负责接收请求,然后均匀发送到后端某个Pod的端口上,这个过程默认采用RoundRobin负载均衡算法。kube-proxy和后端Pod的通信方式与标准的Pod到Pod的通信方式完全相同。另外,Kubernetes也提供通过修改Service的service.spec.sessionAffinity参数的值来实现会话保持特性的定向转发,如果设置的值为“ClientIP”,则将来自同一个ClientIP的请求都转发到同一个后端Pod上。
Service的ClusterIP与NodePort是kube-proxy通过iptables和NAT转换实现的,kube-proxy在运行过程中动态创建与Service相关的Iptables规则,这些规则实现了ClusterIP及NodePort的请求流量重定向到对应服务的代理端口的功能。
由于iptables机制针对的是本地的kube-proxy端口,所以如果某个pod需要访问service,则pod所在的那个node上必须运行kube-proxy。在k8s集群内部,对cluster ip、port的访问可以在任意node上进行,这是因为每个node上的kube-proxy都针对该Service都设置了相同的转发规则。
内部访问Service的请求,不论是用Cluster IP+Target Port的方式,还是用节点机IP+Node Port的方式,都会被节点机的Iptables规则重定向到kube-proxy监听Service服务代理端口。
集群外与集群内的通信
service是对一组功能相同pod的抽象,以“pod组”为单位对外提供服务。cluster ip只能在内部访问,其他pod都可以无障碍地访问,但外部访问不行。k8s有多种对外服务的service的类型定义,比如NodePort和LoadBalancer。
NodePort
定义service时指定spec.type=NodePort,并指定spec.ports.nodePort的值,系统就会在Kubernetes集群中的每个Node上占用宿主机上的一个真实端口号。这样,能够访问Node的客户端就能通过这个端口号访问到内部的Service了。
LoadBalancer
经过实践,容易造成流量爆表、性能夯死。定义service时指定spec.type=LoadBalancer,同时需要指定负载均衡器的ip地址、Service的NodePort、ClusterIP。