1. 多路复用要解决什么问题
并发多客户端连接场景,在多路复用之前最简单和典型的方案:同步阻塞网络IO模型。
这种模式的特点就是用一个进程来处理一个网络连接(一个用户请求),比如一段典型的示例代码如下。
直接调用 recv 函数从一个 socket 上读取数据。
int main(){
...
// //从用户角度来看非常简单,一个recv一用,要接收的数据就到我们手里了。
recv(sock, ...)
}
优点:就是这种方式非常容易让人理解,写起代码来非常的自然,符合人的直线型思维。
缺点:就是性能差,每个用户请求到来都得占用一个进程来处理,来一个请求就要分配一个进程跟进处理,
问题分析:
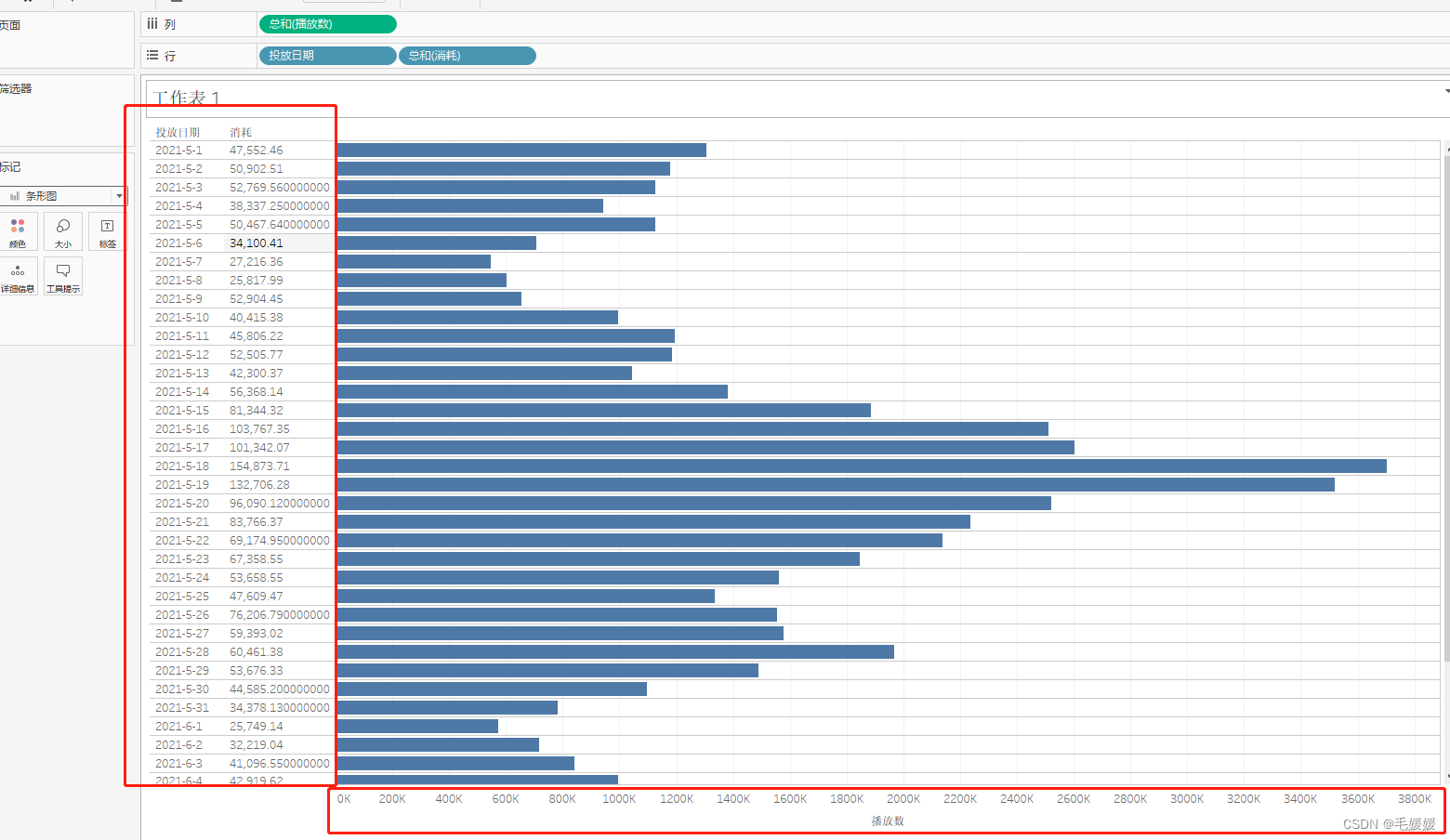
进程在 Linux 上是一个开销不小的家伙,先不说创建,光是上下文切换一次就得几个微秒。所以为了高效地对海量用户提供服务,必须要让一个进程能同时处理很多个 tcp 连接才行。现在假设一个进程保持了 10000 条连接,那么如何发现哪条连接上有数据可读了、哪条连接可写了 ?
也可以采用循环遍历的方式来发现 IO 事件,但是这种方式也存在耗费资源(上下文切换),系统调用的阻塞耗时等问题。
结论
所以就有了有一种更高效的机制,在很多连接中的某条上有 IO 事件发生的时候直接快速把它找出来。
就是Linux 操作系统中我们所熟知的 IO 多路复用机制。这里的复用指的就是对进程的复用
2. I/O多路复用是什么?
它是指用一个进程来处理大量的用户TCP连接。

3. 单线程如何处理并发连接?为什么快?
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次放到文件事件分派器,事件分派器将事件分发给事件处理器。
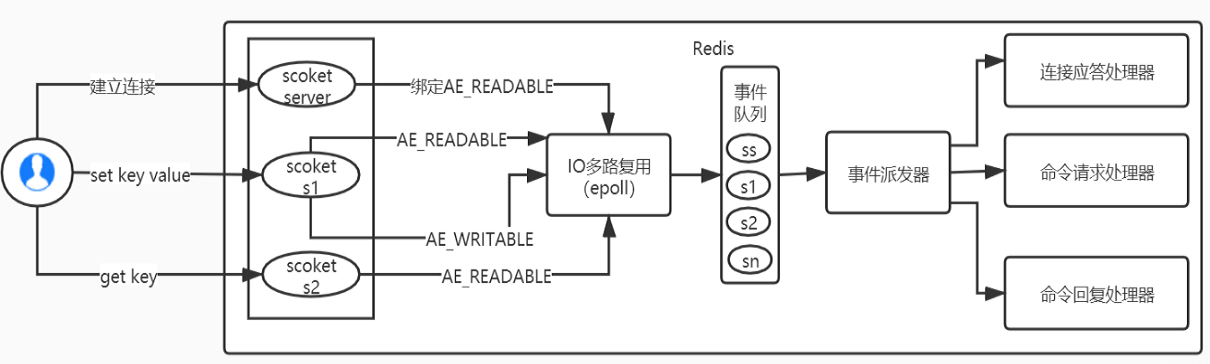
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现
所谓 I/O 多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。这种机制的使用需要 select 、 poll 、 epoll 来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符) Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。
它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
4. 同步&异步&阻塞&非阻塞
名词说明
- 同步:是指调用者要等待调用出结果后才能进行后续的执行(我现在就要,必须等到结果为止);
- 异步:是指被调用方先给调用方返回应答,让调用方回去,然后计算调用结果,计算完最终结果后再返回给调用方。(一般通过
回调的方式通知) - 阻塞:调用方一直在等待而且别的什么事也不干(当前进程/线程会挂起)
- 非阻塞:调用发出后,先忙别的事情了,不会阻塞当前进程/线程,会立即返回。
4种组合方式的理解