文章目录
- 1. 什么是机器学习?
- 2. 机器学习分类
- 2.1 基本分类
- 2.2 按模型分类
- 2.3 其他分类(不重要)
- 3. 机器学习三要素
- 4. 监督学习的应用(分类、标注、回归问题)
1. 什么是机器学习?
定义:给定训练集D,让计算机从一个函数集合F = {f1(x),f2(x),…}中自动寻找一个最优的函数 f * 来近似的表示特征向量与标签y之间的映射关系。
2. 机器学习分类
2.1 基本分类
-
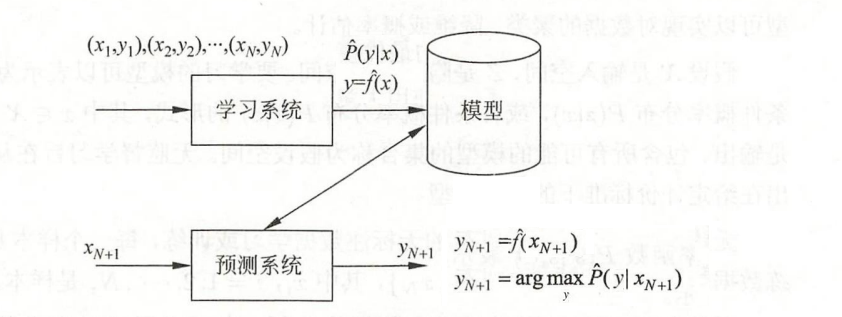
监督学习:样本有标签y
- 建立模型所涉及的函数有两类:
- 概率函数 / 条件概率分布:P(y | x) 输入样本x后,输出的是y的概率分布。【比如输入x=1,输出{y=1.1的概率为30%,y=1.2的概率为30%,y=1.3的概率为40%}】
- 决策函数:y = f(x) 输入样本x后,输出的是具体值y。
- 建立模型所涉及的函数有两类:
-
无监督学习:样本无标签y
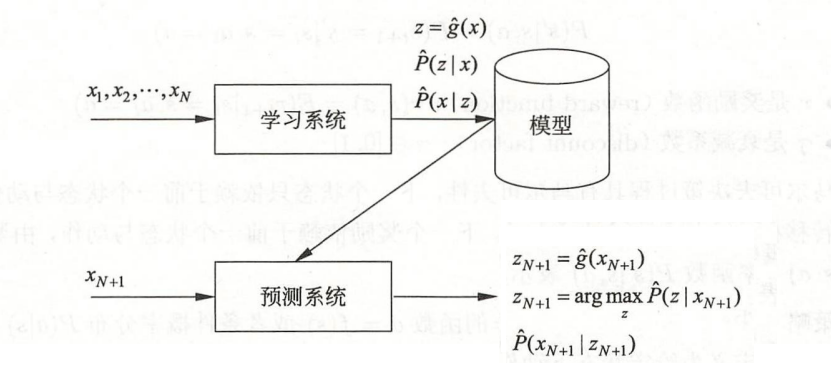
- 建立模型所涉及的函数有3类:
- 聚类
- 硬聚类(一个样本只能对应一个类):z = gθ(x) 输入样本x后,输出的是具体类别z。
- 软聚类(一个样本可能对应多个类,比如番茄既属于水果也属于蔬菜):Pθ(z | x) 输入样本x后,输出的是类别z的概率分布。
- 降维:z = gθ(x) 其中 x ∈ 样本空间,z ∈ 样本空间
- 概率模型估计:Pθ(x | z) 怎样一个模型z使得样本x出现的概率最大
- 聚类
- 建立模型所涉及的函数有3类:
-
半监督学习:少量样本有标签y,大部分样本没有标签y
-
强化学习:积累正确经验的最大化
- 建立模型所涉及的函数有2类:
- 有模型的:直接学习马尔可夫决策过程,既求出状态转移函数和奖励函数,知道完整的五元组信息。
- 无模型的:不知道完整的五元组信息
-
基于策略的:初始化策略并求出对应的价值,然后不断的根据价值迭代更新策略,等到价值收敛时,可直接得到最优策略 л* (因为前面记录了策略迭代过程)

-
基于价值的:初始化价值,然后不断的迭代更新价值,等到价值收敛时,可根据获取最大价值间接得到最优策略 л * (获取最大价值的路线就是最优策略的路线)

-
- 建立模型所涉及的函数有2类:
2.2 按模型分类
-
概率模型与 非概率模型 / 确定模型:
-
概率模型:粗略理解为输出的是概率分布,本质是指模型能够用联合概率分布的形式表示。

-
非概率模型 / 确定模型:粗略理解为输出的是具体值,本质是指模型不能够用联合概率分布的形式表示。

- 例如:

- 注意:条件概率分布形式 与 函数形式 可以相互转换。所以上面概率模型与非概率模型的定义中才说可以粗略的根据输出是概率分布还是具体值判断。
- 条件概率分布形式最大化后得到函数形式
- 函数归一化后得到条件概率分布形式
-
-
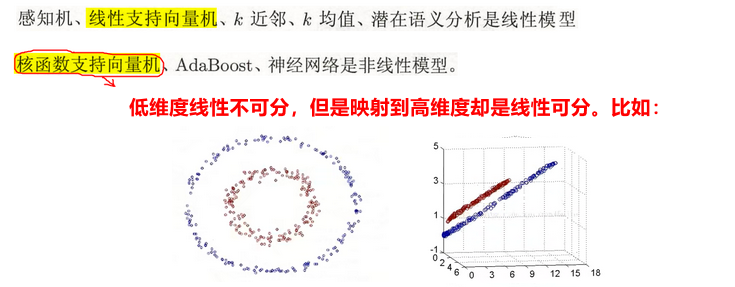
线性模型与非线性模型
- 线性模型:① 模型为决策函数而不是条件概率分布;② 且决策函数为线性函数
- 非线性模型:不满足线性模型条件的都叫非线性模型
-
参数化模型和非参数化模型
- 参数化模型:指模型的参数个数固定
- 非参数化模型:指模型的参数不固定,一般随着样本增加而增加。
2.3 其他分类(不重要)
3. 机器学习三要素
机器学习的三步:
-
模型:根据问题建立合适的模型,一旦建立模型,就会确定模型参数,根据模型参数产生假设空间。
- 比如建立线性回归模型 y = w*x + b后。根据参数(w, b)的不同就会产生假设空间 {y1 = w1*x + b1, y2 = w2*x + b2…}
-
策略:依据什么标准到假设空间中找到最优的函数?这就需要使用一个损失函数做为策略。
- 常见的损失函数:

注意:损失函数不一定是上面的4个,也可以自定义损失函数。比如:感知机的损失函数就是自定义:误分类点到超平面的距离。
- 那么模型在样本集上的平均损失用什么衡量?
- 使用期望损失 / 期望风险。

- 但是由于期望风险中每个样本真实的概率分布是不可能知道的,导致期望风险不可求。
解决方法:默认每个样本出现的概率相等,则期望损失 / 期望风险 变为 经验损失 / 经验风险

- 此时经验风险就是标准,当经验风险最小时的模型参数就是最优参数,即最优模型。
- 使用期望损失 / 期望风险。
- 常见的损失函数:
-
算法:如何求得最优参数?【因为模型已经建立,本质上就是找最优参数,将最优参数代入模型就是最优模型】
- 目标函数是谁?
- 经验风险最小化:对经验风险求最优化
- 结构风险最小化:对结构风险求最优化
- 可能有疑惑:不是对经验风险求最小化时的参数吗?怎么又出来个对结构风险求最小化时的参数?
- 因为
结构风险 = 经验风险 + 正则项,本质上还是经验风险。只不过加上正则项可以防止模型过拟合。
- 怎么对目标函数求最优化,得到最优参数?
- 一般采用随机梯度下降求得出最优时的参数,从而得到最优模型。
- 最小二乘法求得出最优时的参数,从而得到最优模型。
- 岭回归
- 等等
- 如何衡量找到的最优模型好不好?
- 泛化误差越小越好,但是泛化误差不可求,故使用泛化误差上界来衡量模型好坏。
- 找到最优模型后预测效果不好怎么办?
- 问题1:过拟合:训练出来的模型过于复杂导致预测效果不好。主要原因之一是样本太少了。
- 如何判断预测效果不好是因为过拟合?
- 解决方法:
① 增加样本量
② 交叉验证
③ 结构风险最小化 【为什么正则化能够解决过拟合问题?】
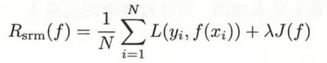
- 问题2:欠拟合:训练出来的模型过于简单导致预测效果不好。
- 问题1:过拟合:训练出来的模型过于复杂导致预测效果不好。主要原因之一是样本太少了。
- 目标函数是谁?
4. 监督学习的应用(分类、标注、回归问题)
- 分类问题:模型输出离散值。【故 y = f(x)若输出为连续值,要对结果做离散化处理;P(y | x) 对结果取概率最大的为输出值】
- 评价指标:精准率 和 召回率 【这个评价指标是用于训练模型阶段去衡量模型的好坏,然后不断的去调节分类器的分类阈值,实现更好的分类。而最终衡量模型的好坏还是使用泛化能力】

自己对精准率和召回率的理解:
- 精准率:衡量预测结果的准确性。比如:有 n 个人,其中 k 个人在客观上是阳性,检查结果为 h 个阳性,那么 h 越接近 k 越准确。他不在乎是否将阴性预测为了阳性或将阳性预测为了阴性,只在乎预测结果在数字上 h 接近 k 就行。
- 召回率:衡量预测结果的正确性。比如:有名为 {张1,张2 … 张n} n个人,其中 {张1,张2 … 张k} 在客观上是阳性 (其中 k <= n) ,检查结果为 h 个阳性,那么这 h 个人在 {张1,张2 … 张k} 中的人数越多,预测就越正确。他不在乎预测结果在数字上 h 是否接近 k ,只在乎这 h 个人是否都是 {张1,张2 … 张k} 中的人。
- 解决分类问题的方法:近邻法、感知机、朴素贝叶斯法、决策树、逻辑斯谛回归模型、SVM、adaBoost、贝叶斯网络、神经网络
- 评价指标:精准率 和 召回率 【这个评价指标是用于训练模型阶段去衡量模型的好坏,然后不断的去调节分类器的分类阈值,实现更好的分类。而最终衡量模型的好坏还是使用泛化能力】
- 标注问题:标注问题是分类问题的一个推广,输出的也是离散值。分类问题的输出是一个值,而标注问题输出是一个向量,向量的每个值属于一种标记类型。
- 解决分类问题的方法:隐性马尔可夫模型、条件随机场。
- 回归问题:输出的是连续值。用于预测输入变量和输出变量之间的关系。
- 细分:回归问题按照输入变量的个数,可以分为一元回归和多元回归;按照输入变量与输出变量之间关系的类型,可以分为线性回归和非线性回归。
- 解决分类问题的方法:建立一元或多元线性函数。【对于回归问题一般使用平方损失做为损失函数,在此情况下,使用最小二乘法求最优解。】
区分分类问题 与 回归问题:看输出的是离散值还是连续值。
- 有一个新手特别容易犯的错误:记住 logistic 回归不是回归是分类! logistic回归不是回归是分类! logistic回归不是回归是分类!



![[附源码]Python计算机毕业设计Django学分制环境下本科生学业预警帮扶系统](https://img-blog.csdnimg.cn/538b2ad4094f47e3a75effd4b05f6cf2.png)