一、DBSCAN算法的前置知识
DBSCAN算法:如果一个点q的区域内包含多于MinPts个对象,则创建一个q作为核心对象的簇。然后,反复地寻找从这些核心对象直接密度可达的对象,把一些密度可达簇进行合并。当没有新的点可以被添加到任何簇时,该过程结束。
DBSCAN是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的空间数据库中发现任意形状的聚类。聚类就是将数据对象分组成为多个类或簇,划分的原则是在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。与分类不同的是,聚类操作中要划分的类是事先未知的,类的形成完全是数据驱动的,属于一种无指导的学习方法。
对象的ε-领域:给定对象在半径ε内的区域。
核心对象:如果一个对象的ε-领域至少包含最小数目MinPts个对象,则称该对象为核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε-领域内,而q是一个核心对象,我们说对象p从对象q出发是直接密度可达的。
密度相连的:如果对象集合D中存在一个对象o,使得对象p和q是从o关于ε和MinPts密度可达的,那么对象p和q是关于ε和MinPts密度相连的。
二、DBSCAN算法的基本思想
DBSCAN是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的空间数据库中发现任意形状的聚类。
从数据库中抽取一个未处理过的点,如果抽出的点是核心点,那么找出所有从该点密度可达的对象,形成一个簇;如果抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一点,直到所有点都被处理。
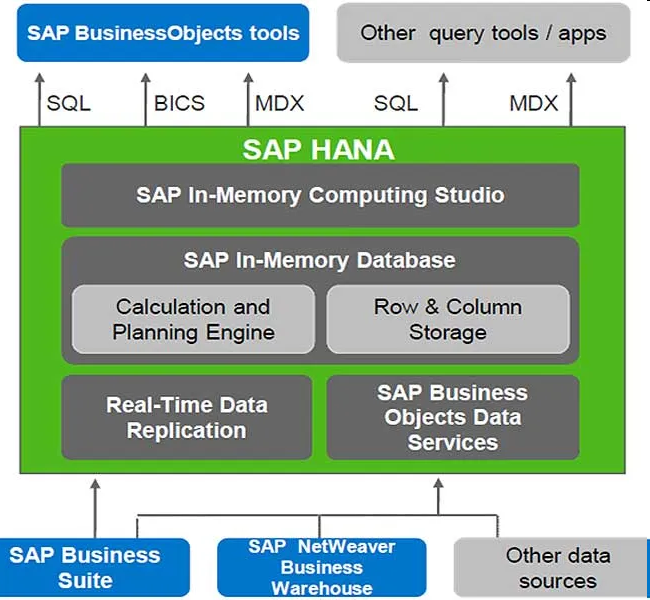
三、DBSCAN算法的例子
DBSCAN算法例子

四、DBSCAN算法的实现过程
实验内容
有如下二维数据集,取ε =2,minpts=3,请使用DBSCAN算法对其聚类(使用曼哈顿距离)
实验思路
(1)定义Point类,Point类中含横坐标x,纵坐标y等属性,包含静态方法getIsSame():判断两个Point类对象是否相同、calculateDistance()方法:计算两个Point类对象之间的距离(欧氏距离)、calculateMHDDistance()方法:计算两个Point类对象之间的距离(曼哈顿距离)。定义ExcelData类,ExcelData类中包含横坐标x(添加注解@ExcelProperty(value=“横坐标”)),纵坐标y(添加注解@ExcelProperty(value=“纵坐标”)),ExcelData类主要用于读取excel文件的数据映射到ExcelData类中。定义Cluster类,在Cluster类中包含属性核心点corePoint,簇内的所有点的集合sameList。
(2)定义初始数据集dataList,定义半径e,定义核心对象e领域内对象的最少数目MinPts,调用getFileData()方法对初始数据集进行初始化。在getFileData()方法体内部使用EasyExcel对excel文件进行读取并映射到ExcelData类对象中,将ExcelData类对象中的属性x和属性y作为构造参数,实例化出Point类对象point,并将所有的point添加到dataList集合中,完成对数据集的初始化。
(3)创建clusterList集合,用于存放所有的簇。遍历dataList集合中的每一个Point类对象point,在循环体内部,调用getEPointList()方法获取一个Point类对象领域内所有的点集合ePointList,如果ePointList集合的长度不小于MinPts,说明点point是核心对象,则实例化一个以point为核心对象的簇cluster,并用ePointList实例化簇cluster的sameList属性,然后调用canReachPoint()方法遍历核心对象直接密度可达的点,合并其所有密度可达的点,将最终的簇newCluster加入到簇集合newCluster中。在循环体内部首先调用isExitCluster()方法判断是否点已经存在于某个簇中,已经在簇中的点则不再考虑,不再执行循环体内接下来的代码,直接开始遍历下一次循环,直到遍历过dataList集合中的每一项后,循环结束。
(4)遍历clusetrList集合,将集合中的每一项cluster输出即可。
(5)在isExistCluster()方法体内部,判断point对象是否已经在已存在的簇中,遍历clusterList集合中的每一个簇cluster,获取簇cluster中的sameList属性,判断其sameList集合中是否含point,若含有则返回true。遍历结束后,返回false。
(6)在canReachPoint()方法体内部,遍历簇cluster中包含的所有点,判断除核心对象点以外的每一个点point是否是核心对象,若point也是核心对象,则其领域内所有的点是簇cluster核心点的密度可达的点,也可以合并到簇cluster中,将这些点添加到密度可达的点集合reachPointList中,当循环结束后,将集合reachPointList中所有的密度可达的点加入到簇的sameList集合中,重新实例化簇cluster,最终将cluster返回。
(7)getEpointList()方法的作用是获取一个点e领域内所有点的集合。在方法体内部,定义点集合pointList用于存放point的e领域内所有的点,遍历数据集dataList中的每一个点p,调用Point类内的静态方法calcuteMHDDistance()方法,计算点point和点p的曼哈顿距离,用变量ptoPoint来存放,如果ptoPoint小于半径e,则说明点p在点point的e领域内,则将p加入到pointList集合当中,最终返回pointList集合。
实现源码
Cluster类
package com.data.mining.entity;
import lombok.Data;
import java.util.ArrayList;
import java.util.List;
@Data
public class Cluster {
private Point corePoint;
private List<Point> sameList = new ArrayList<>();
public Cluster(){}
public Cluster(Point cp){
corePoint = cp;
}
}
Point类
package com.data.mining.entity;
import lombok.Data;
@Data
public class Point {
private double x;
private double y;
public Point(){}
public Point(double x, double y){
this.x = x;
this.y = y;
}
public static boolean getIsSame(Point p1, Point p2){
if (p1.getX() == p2.getX() && p1.getY() == p2.getY()) return true;
return false;
}
public static double calculateDistance(Point p1, Point p2){
double xDistance = p1.getX() - p2.getX();
double yDistance = p1.getY() - p2.getY();
double tmp = xDistance * xDistance + yDistance * yDistance;
return Math.sqrt(tmp);
}
public static double calculateMHDDistance(Point p1, Point p2){
return Math.abs(p1.getX() - p2.getX()) + Math.abs(p1.getY() - p2.getY());
}
}
ExcelData类:因为本实验样本集太多,于是笔者将样本集存入到了excel文件中,用EasyExcel读取excel文件。因此创建ExcelData类
package com.data.mining.entity;
import lombok.Data;
import java.util.ArrayList;
import java.util.List;
@Data
public class Cluster {
private Point corePoint;
private List<Point> sameList = new ArrayList<>();
public Cluster(){}
public Cluster(Point cp){
corePoint = cp;
}
}
DBSCAN算法实现代码
package com.data.mining.main;
import com.alibaba.excel.EasyExcel;
import com.data.mining.entity.Cluster;
import com.data.mining.entity.ExcelData;
import com.data.mining.entity.Point;
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.List;
public class DBSCAN {
// 定义初始数据集
public static List<Point> dataList = new ArrayList<>();
// 定义半径e
public static double e = 2.0;
// 定义核心对象领域内对象的最少数目
public static int MinPts = 3;
public static void main(String[] args) {
getFileData();
// initDataList();
List<Cluster> clusterList = new ArrayList<>();
for (Point point : dataList) {
if (isExistCluster(point, clusterList)) continue; //已经在簇中的点不再考虑
List<Point> ePointList = getEPointList(point);
if (ePointList.size() >= MinPts){ //说明点point是核心对象
Cluster cluster = new Cluster(point);
cluster.setSameList(ePointList);
Cluster newCluster = canReachPoint(cluster);
clusterList.add(newCluster);
}
}
int pointSum = 0;
for (Cluster cluster : clusterList) {
System.out.println(cluster);
pointSum += cluster.getSameList().size();
}
System.out.println(pointSum);
}
/**
* 判断point是否已经在已存在的簇中
* @param point
* @param clusterList
* @return
*/
public static boolean isExistCluster(Point point, List<Cluster> clusterList){
for (Cluster cluster : clusterList) {
List<Point> pointList = cluster.getSameList();
if (pointList.contains(point)) return true;
}
return false;
}
/**
* 遍历核心对象直接密度可达的点,合并其所有密度可达的点
* @param cluster
* @return
*/
public static Cluster canReachPoint(Cluster cluster){
List<Point> pointList = cluster.getSameList();
List<Point> reachPointList = new ArrayList<>(); //存放核心点所有密度可达的点(暂存要新加入进来的点)
for (Point point : pointList) {
Point corePoint = cluster.getCorePoint();
if (Point.getIsSame(corePoint, point)) continue; //这里不再遍历核心对象点
List<Point> reachList = getEPointList(point); //核心对象直接密度可达的点其e领域内所有的点的集合
if (reachList.size() >= MinPts){ //说明point也是核心对象,其领域内的所有点也可以合并到cluster中
for (Point reachPoint : reachList) {
if (pointList.contains(reachPoint)) continue; //对于pointList中已经有的点不再重复添加
reachPointList.add(reachPoint); //将密度可达的点添加到密度可达的点集合中
}
}
}
pointList.addAll(reachPointList); //将密度可达的点全加入到簇中
cluster.setSameList(pointList);
return cluster;
}
/**
* 获取一个点的e领域内所有的点集合
* @param point
* @return
*/
public static List<Point> getEPointList(Point point){
List<Point> pointList = new ArrayList<>(); //存放point的e领域内所有的点
for (Point p : dataList) {
double ptoPoint = Point.calculateMHDDistance(point, p);
if (ptoPoint <= e) pointList.add(p); //说明点p在point的e领域内
}
return pointList;
}
public static void getFileData(){
try {
FileInputStream inputStream = new FileInputStream("E:\\宋泽旭个人\\课程作业\\课程设计\\data_mining\\dbscan.xlsx");
List<ExcelData> fileData = EasyExcel.read(inputStream).head(ExcelData.class).sheet()
.headRowNumber(1).doReadSync();
for (ExcelData excelData : fileData) {
Point point = new Point(excelData.getX(), excelData.getY());
dataList.add(point);
}
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 使用了书本上的例子进行测试,只为测试算法实现是否正确。main方法中并没有执行initDataList方法
*/
public static void initDataList(){
Point p1 = new Point(1, 0);
Point p2 = new Point(4, 0);
Point p3 = new Point(0, 1);
Point p4 = new Point(1, 1);
Point p5 = new Point(2, 1);
Point p6 = new Point(3, 1);
Point p7 = new Point(4, 1);
Point p8 = new Point(5, 1);
Point p9 = new Point(0, 2);
Point p10 = new Point(1, 2);
Point p11 = new Point(4, 2);
Point p12 = new Point(1, 3);
dataList.add(p1);
dataList.add(p2);
dataList.add(p3);
dataList.add(p4);
dataList.add(p5);
dataList.add(p6);
dataList.add(p7);
dataList.add(p8);
dataList.add(p9);
dataList.add(p10);
dataList.add(p11);
dataList.add(p12);
}
}
实验结果

这图片这么小,反正我是看不清,所以用表格盛一下:

五、实验总结
本实验结果笔者并不保证一定是正确的,笔者仅仅是提供一种使用Java语言实现DBSCAN算法的思路。因为实验并没有给答案,笔者已将网络上有答案的实验数据输入程序后,程序输出的结果和答案一致,所以问题应该不大。若有写的不到位的地方,还请各位多多指点!
笔者主页还有其他数据挖掘算法的总结,欢迎各位光顾!


![【Spring]SpringMVC](https://img-blog.csdnimg.cn/img_convert/25d9ee93503603196683ce9b9ae615a8.png)


![[附源码]计算机毕业设计Python-大学生健康档案管理(程序+源码+LW文档)](https://img-blog.csdnimg.cn/12c6e7ff31674f48b067323ad24dc82c.png)