前言
chatGPT最近火出圈了,怎么薅一个文字模型给你打工呢?
这个UP给了个思路:哔哩哔哩
emmm有点尴尬,可能是热度比较高,b站的视频作者自己下架了。
总结一下:
- 薅的对象百度文库创作中心:地址
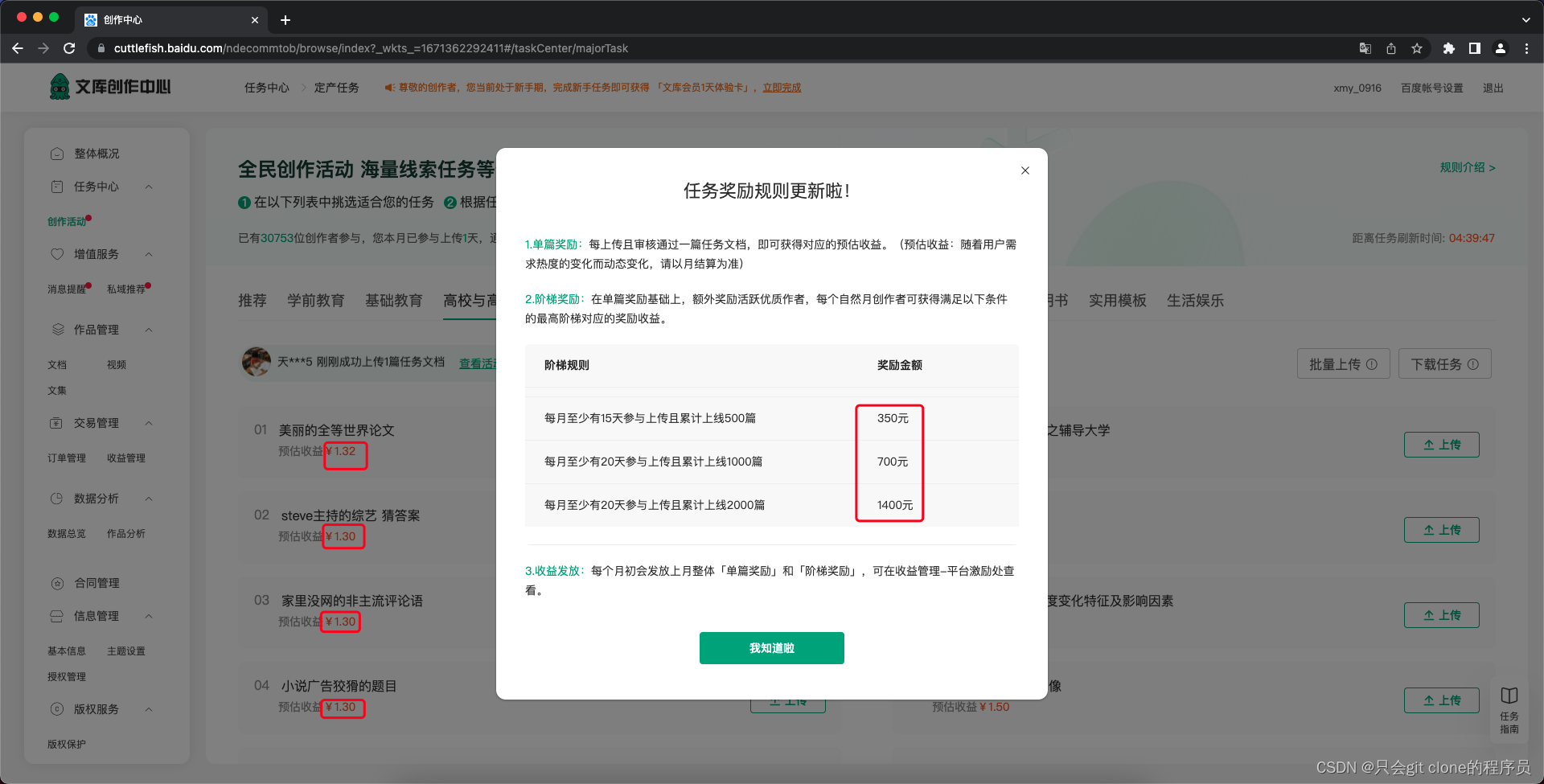
- 除了每个文档一块三左右的收入还有每个月发多少篇的奖励。
- chatGPT干这个不就是信手拈来了???
实现
B站的作者代码没开源的,但是这玩意没啥难度啊…打了一年半的工写个这个不是信手拈来?
粗略的看了下b站的视频,他的技术栈应该是用pychatGPT模拟浏览器发request请求然后拿openAI的回复。所以核心就是用pychatGPT呗?找了下老外开源的代码:https://github.com/rawandahmad698/PyChatGPT
12月17号粗略跑了一下发现已经被ban了并且作者也绕过不了openai的cf了:
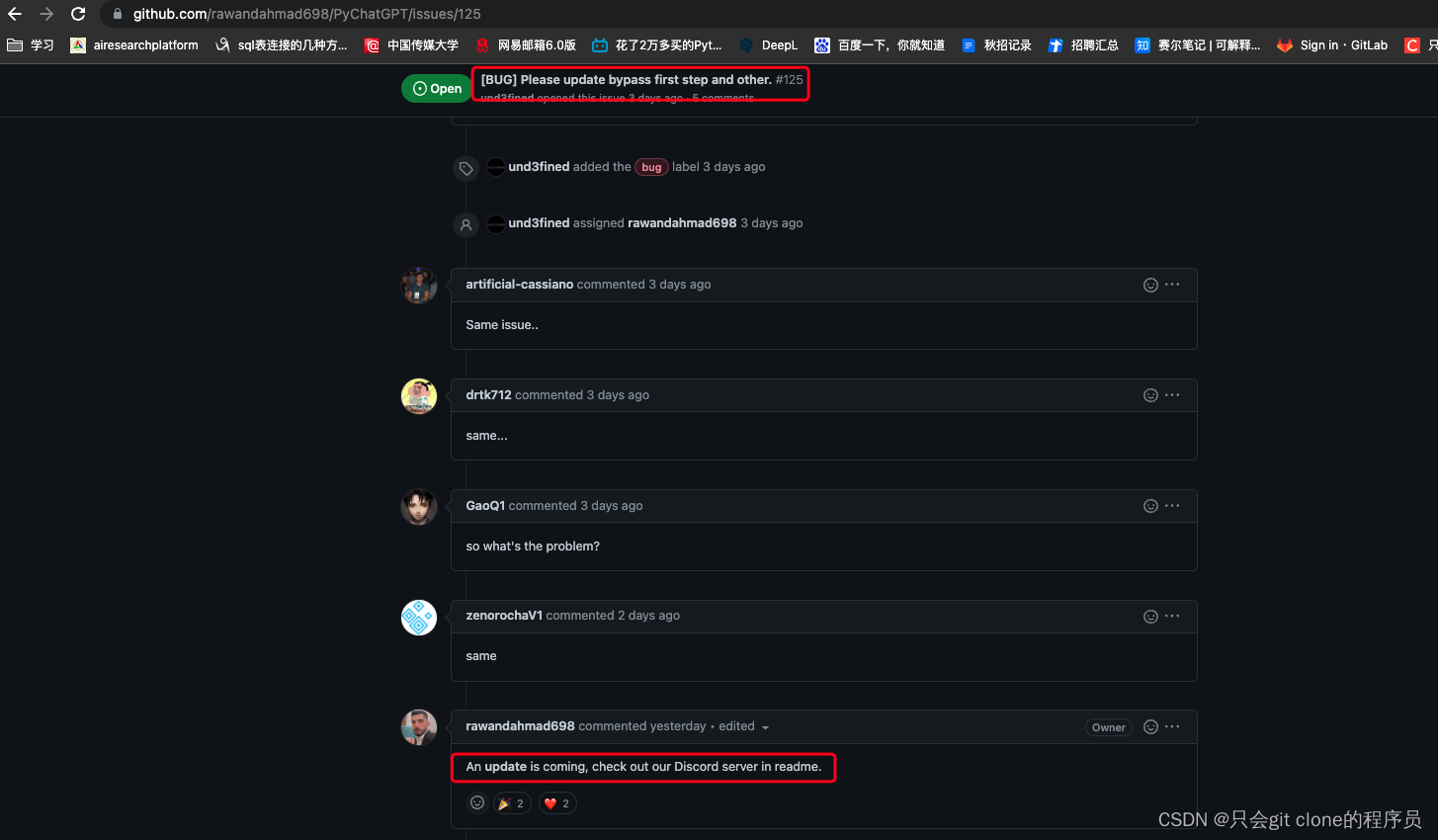
所以呢,b站阿婆主的方法已经没用了,那也问题不大,自己写一个就是了。
我实现的技术栈:
- selenium自动化浏览器控制
- beautifulsoup解析html
- pypandoc文本输出docx
你没看错,就是爬虫的技术栈,request被ban了咱就傻瓜式的直接浏览器控制就是了。
第一步:获取任务
为了全自动,获取任务当然也要自动了,这个比较简单解析下百度文库的网页源码就可以获取任务了:
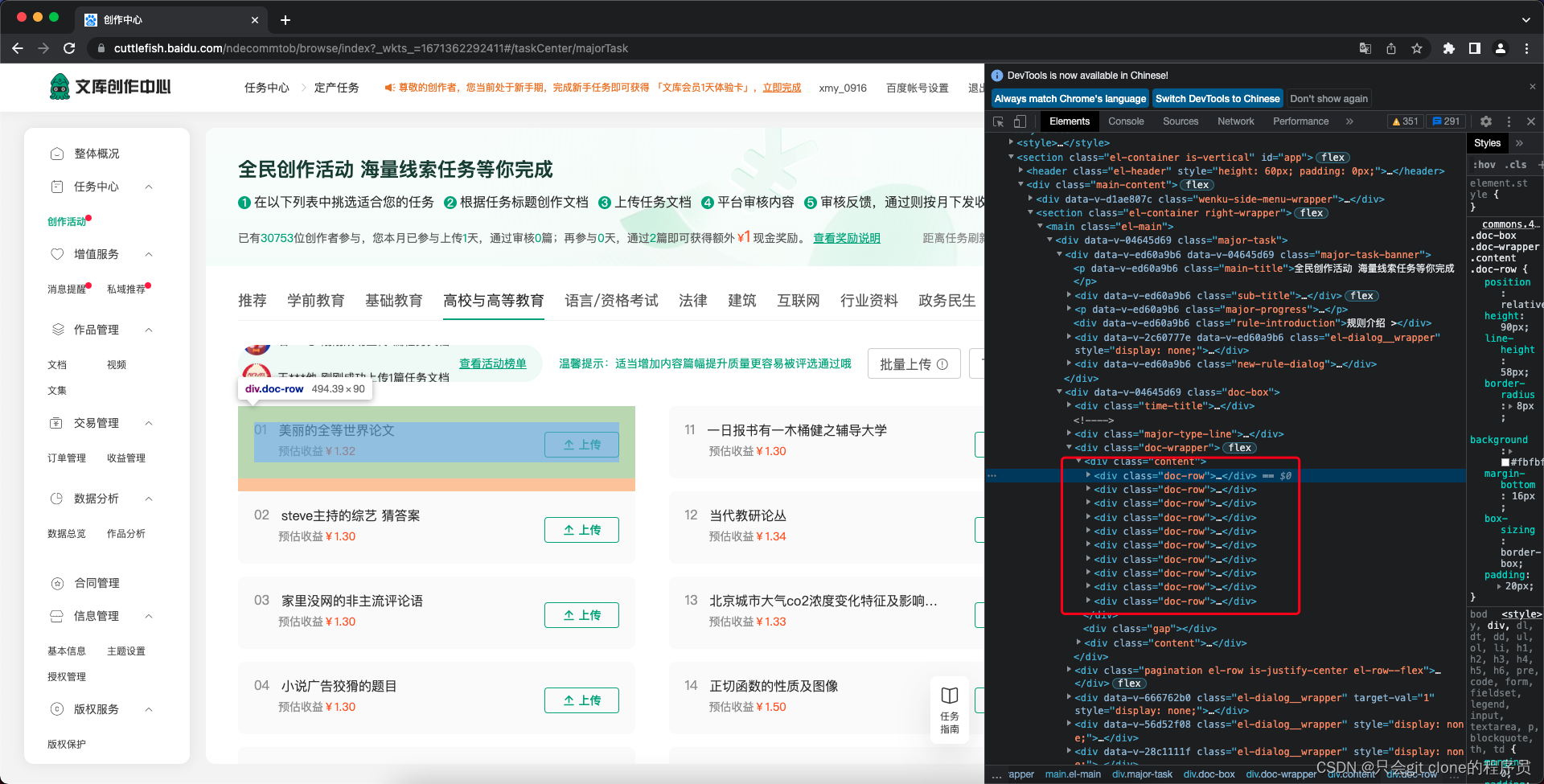
可以看到任务都在doc-row里面,所以核心的检索代码用beautifulsoup搜一下就好了:
doc_rows = soup.findAll('div', {"class": "doc-row"})
然后搜子标签里面的span,并且属性是doc-title就可以获取题目了,同理价格。
然后dump到本地的csv就好了:
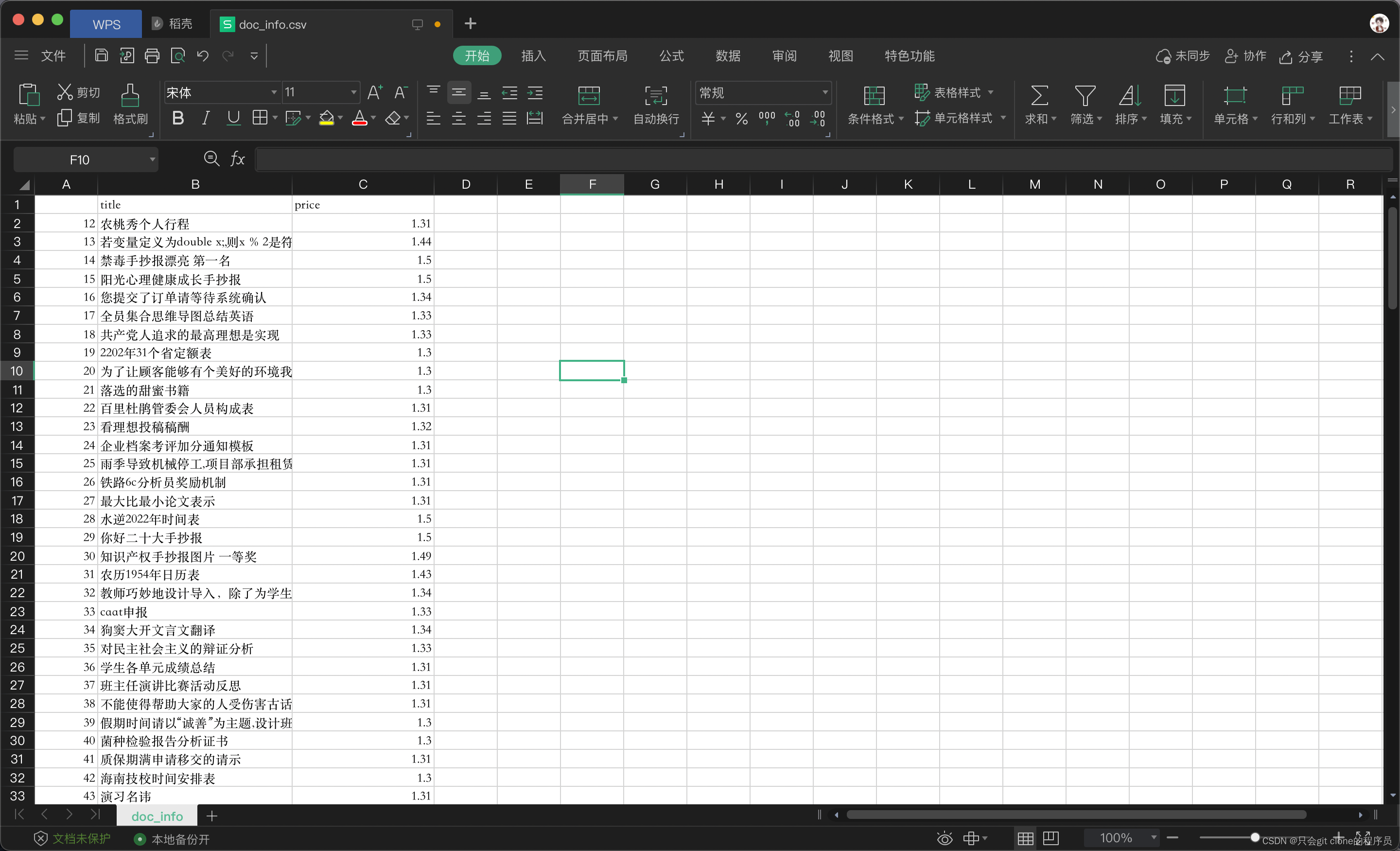
第二步:遍历任务让chatgpt回答
这里比较麻烦的就是绕过openai的cf,既然很难我们就不饶过了,直接浏览器控制,selenium!!!yyds!!!
看看openai的源码:
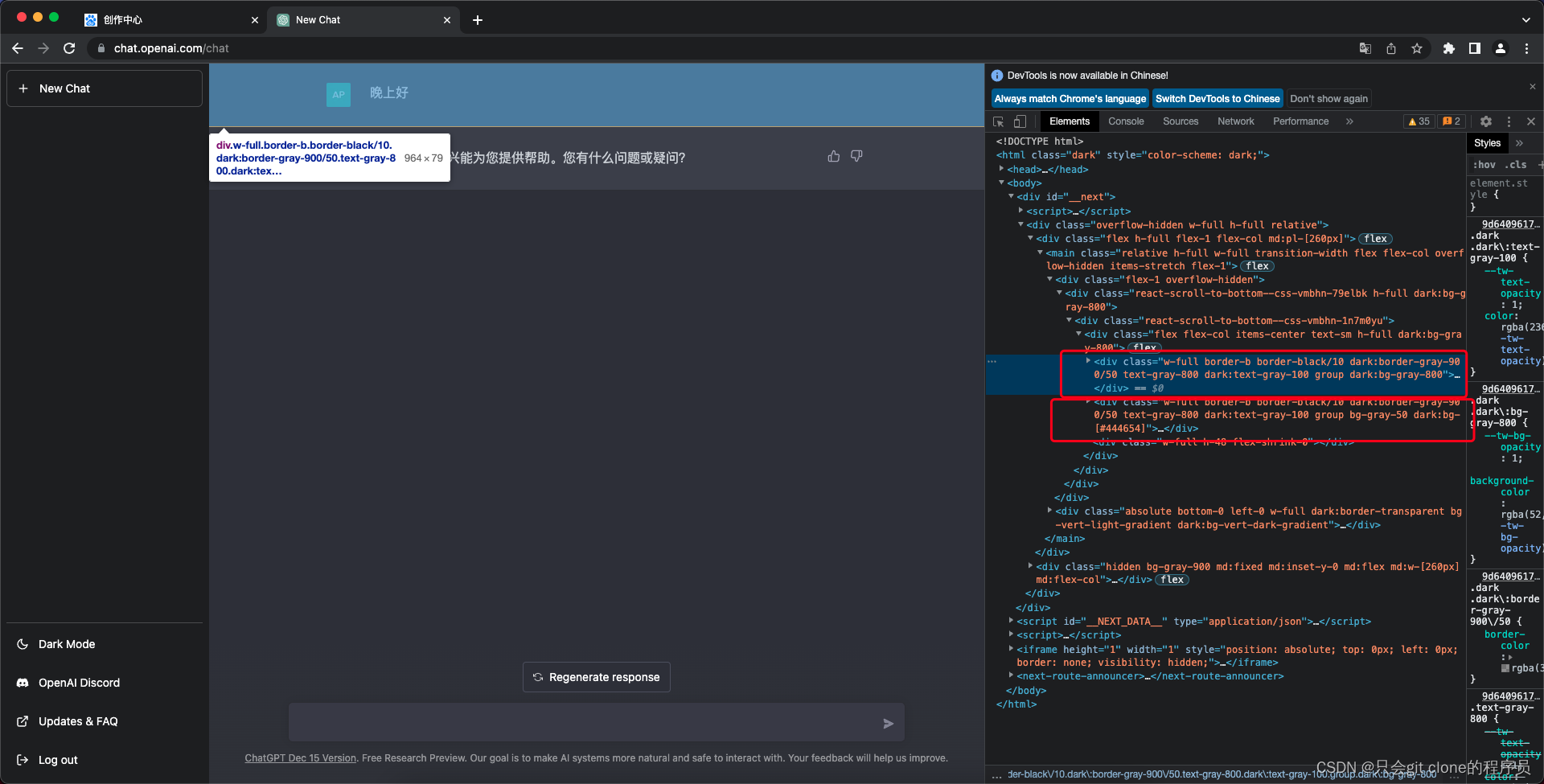
问题和答案都在框起来的源码里了,这样不就ssssso easy了,用selenium获取到网页的源码后,在用bs4库像步骤一一样解析就好了:
核心代码:
answer = str(soup.findAll('div', {"class": "min-h-[20px] flex flex-col items-start gap-4 whitespace-pre-wrap"})[-1])
为啥取最后一个?当然是最后一个肯定是最近的回答了。
这里还有些难点:
- 怎么判断openai生成文本结束了呢?
- 因为openai的限制一次只能输出400个字,怎么接着让他输出呢?
- html的源码有好多
这样的符号怎么导出到doc呢?直接导出的话这样肯定没法看。
问题一:判断生成结束,解决方案
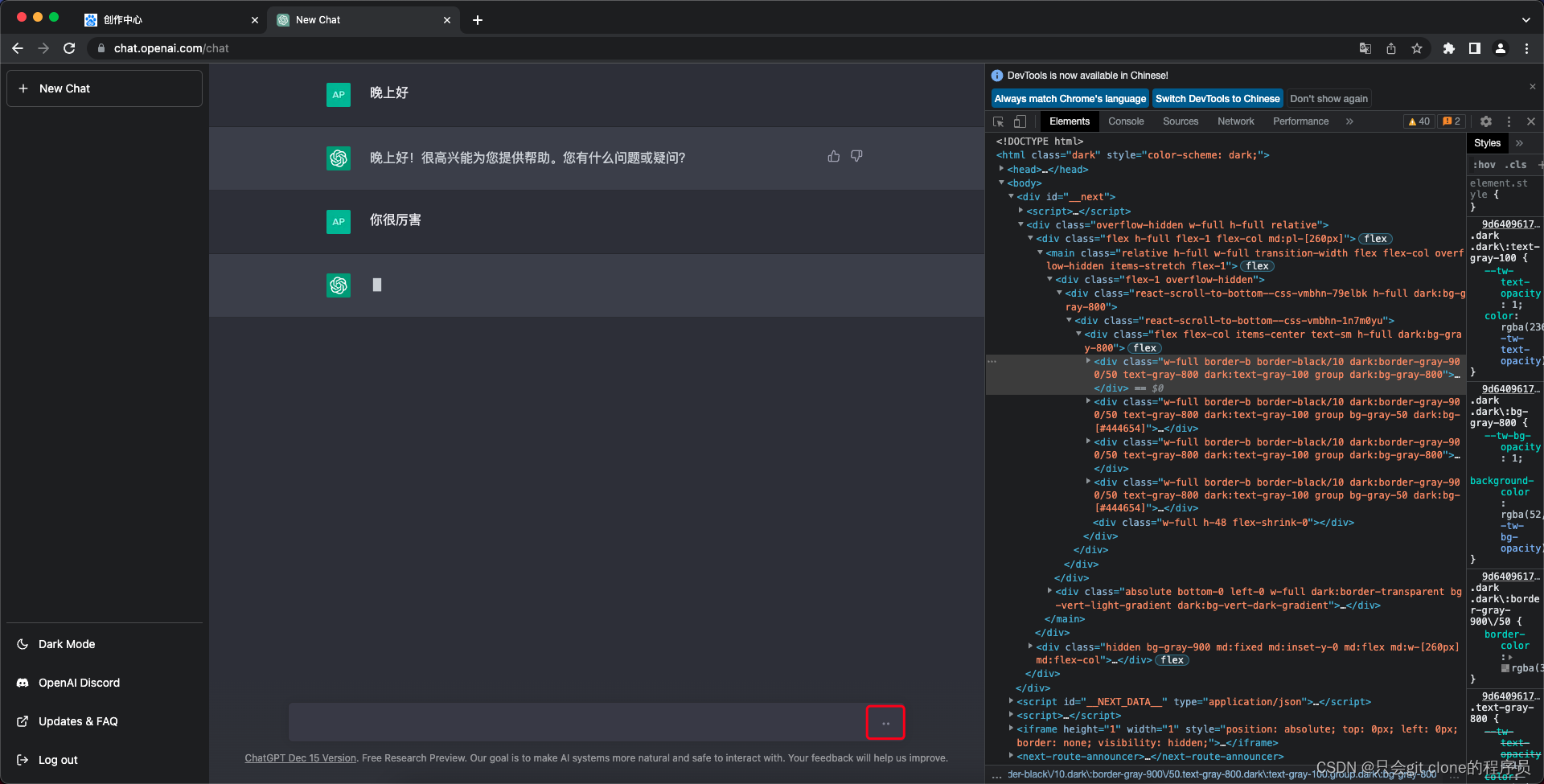
在输出答案的时候这个地方是省略号,所以可以判断html是否有这个省略号来判断openai是否输出完成。
问题二:怎么接着让他输出呢?解决方案
这个其实很简单,判断下答案是否够比如说800字?不够我们就再给他发一条"接着说"他就会接着输出了
问题三:html的源码有好多符号怎么导出到doc呢?直接导出的话这样肯定没法看。解决方案
可以直接获取回答的结果对应的html源码如下:
<div class="min-h-[20px] flex flex-col items-start gap-4 whitespace-pre-wrap"><div class="markdown prose break-words dark:prose-invert light"><p>本领动作是指身体的各个部位可以灵活运用的动作。这些动作有利于增强身体的力量、柔韧性和协调能力,有助于促进身体的健康发展。</p><p>一些常见的本领动作包括:</p><ul><li>俯卧撑:身体俯卧在地上,双手放在地面,腹部收紧,使身体抬起。俯卧撑能增强胸部、手臂和腹部的力量。</li><li>仰卧起坐:身体仰卧在地上,双手放在身体侧面,腹部收紧,使身体从仰卧状态坐起。仰卧起坐能增强腹部、背部和大腿的力量。</li><li>引体向上:站立或悬挂状态下,双手紧握横杠或其他抓握物,腹部收紧,使身体向上拉。引体向上能增强背部、手臂和腹部的力量。</li><li>开合跳:双脚并拢,腹部收紧,使身体向上跳起,再把双脚张开,再跳起。开合跳能增强腹部、大腿和膝盖的力量。</li><li>深蹲:双脚张开,身体向下坐,使膝盖与脚踝成90度角。深蹲能增强大腿、膝盖和腰部的力量。</li></ul><p>这些本领动作都可以</p></div></div><div class="min-h-[20px] flex flex-col items-start gap-4 whitespace-pre-wrap"><div class="markdown prose break-words dark:prose-invert light"><p>自由组合,搭配出不同的本领训练项目。例如,可以先做几个俯卧撑,再做几个仰卧起坐,再做几个引体向上,接着做几个开合跳,最后做几个深蹲。这样的训练项目不仅能锻炼身体的各个部位,还能促进心肺功能的提升。</p><p>在做本领动作时,需要注意身体的姿势和呼吸。姿势要正确,呼吸要规律。如果觉得有些动作难度较大,可以适当减少动作次数或使用辅助工具,逐渐增加难度。</p><p>做本领动作不仅能增强身体的力量和柔韧性,还能提升身心状态,对身体健康有很大的益处。建议每周至少做3次本领动作训练,每次训练时间在30分钟左右。</p></div></div>
加一下支持中文和标题:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<h1>本领动作</h1>
看看效果:

网页解析的效果不错了,然后用pypandoc将html源码转doc即可核心代码:
pypandoc.convert_file("xx.html", "docx", outputfile="xx.doc")
看看doc的效果:
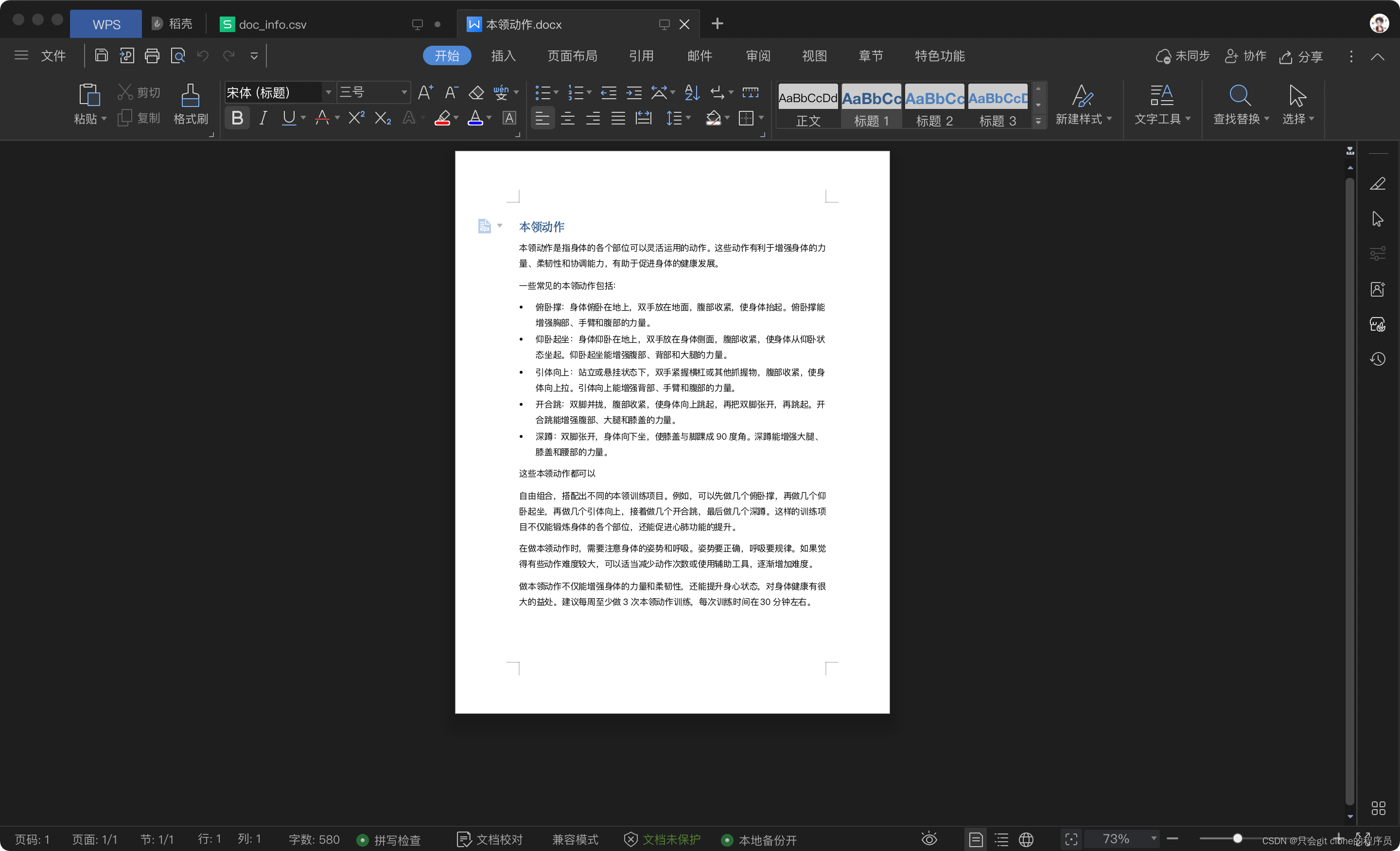
very very good!!!
最后
最后用文库的批量提交就可以提交了,下午跑了三个小时弄了40篇试试水:
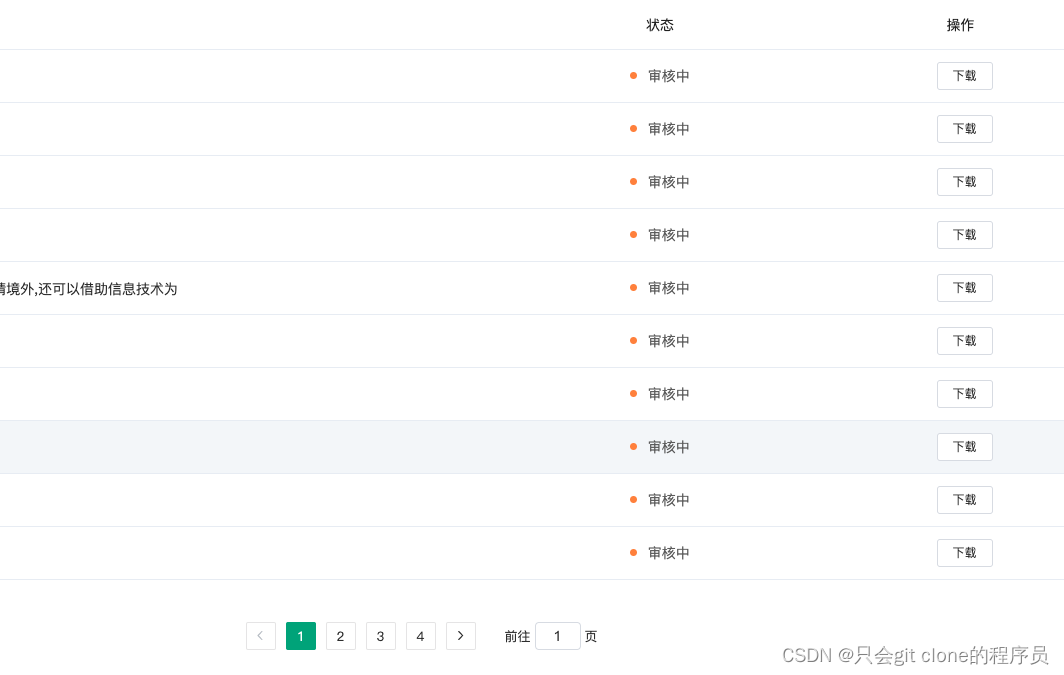
看看能不能过审核。
TODO1
有些文库的任务质量非常差:

比如上图,这是什么没有逻辑的鬼东西,这种可以在dump下来的任务csv中标注下标签,给这个打个坏,在之后人工审核出来之后可以把过审的标注成好 ,并且没过审的也标注成坏,这样随便跑个轻量的nlp模型就能过滤大量没有意义的任务了。
TODO2
躺平就想着全全自动,现在在上传文库这块还是依赖手工,可以用python模型鼠标点击,固定屏幕的话可以像按键精灵一样写个脚本自动上传了,不过可能就是要处理的特殊情况会多一些,写起来倒是没啥难度。

![[附源码]Python计算机毕业设计Django学分制环境下本科生学业预警帮扶系统](https://img-blog.csdnimg.cn/538b2ad4094f47e3a75effd4b05f6cf2.png)




![【Spring]SpringMVC](https://img-blog.csdnimg.cn/img_convert/25d9ee93503603196683ce9b9ae615a8.png)


![[附源码]计算机毕业设计Python-大学生健康档案管理(程序+源码+LW文档)](https://img-blog.csdnimg.cn/12c6e7ff31674f48b067323ad24dc82c.png)