文章目录
- 备份和恢复
- 分类
- 冷备
- 热备
- 逻辑备份
- mysqldump
- SELECT...INTO OUTFILE
- 恢复
- 二进制日志备份与恢复
- 快照备份(完全备份)
- 复制
- 快照+复制的备份架构
备份和恢复
分类
(1)根据备份的方法可以分为:
- Hot Backup(热备):指在数据库运行中直接备份,对正在运行的数据库没有任何影响,也称为Online Backup(在线备份);
- Cold Backup(冷备):指在数据库停止的情况下进行备份,这种备份最为简单,一般只需要拷贝相关的数据库物理文件即可,也称为Offline Backup(离线备份);
- Warm Backup(温备):同样是在数据库运行时进行,但是会对当前数据库的操作有所影响,例如加一个全局读锁以保证备份数据的一致性。
(2)根据备份后文件的内容,又可以分为:
- 逻辑备份:指备份后的文件内容是可读的,通常是文本文件,内容一般是SQL语句,或者是表内的实际数据,如mysqldump和SELECT * INTO OUTFILE的方法。这类方法的好处是可以看到导出文件的内容,一般适用于数据库的升级、迁移等工作,但是恢复所需要的时间往往较长。
- 裸文件备份:指拷贝数据库的物理文件,数据库既可以处于运行状态(如ibbackup、xtrabackup这类工具),也可以处于停止状态。这类备份的恢复时间往往较逻辑备份短很多。
(3)按照备份数据库的内容来分,又可以分为:
- 完全备份:指对数据库进行一个完整的备份;
- 增量备份:指在上次的完全备份基础上,对更新的数据进行备份;
- 日志备份:主要是指对MySQL数据库二进制日志的备份,通过对一个完全备份进行二进制日志的重做来完成数据库的point-in-time的恢复工作。
对于MySQL数据库来说,官方没有提供真正的增量备份的方法,大部分是通过二进制日志来实现的。这种方法与真正的增量备份相比,效率还是很低的。假设有一个100G的数据库,如果通过二进制日志来完成备份,可能同一个页需要多次执行SQL语句来完成重做的工作。但是对于真正的增量备份来说,只需要记录当前每个页最后的检查点的LSN。如果大于之前完全备份时的LSN,则备份该页,否则不用备份。这大大加快了备份的速度以及缩短了恢复的时间,同时这也是xtrabackup工具增量备份的原理。
对于InnoDB存储引擎来说,因为其支持MVCC(多版本控制)功能,因此实现备份一致比较容易。可以先开启一个事务,然后导出一组相关的表,最后提交。当然,事务隔离级别必须是REPEATABLE READ的,这样的做法就可以给你一个完美的一致性备份。然而,这个方法的前提是需要你正确地设计应用程序。
对于mysqldump备份工具来说,可以通过添加-single-transaction选项来获得InnoDB存储引擎的一致性备份,这时的备份是在一个执行时间很长的事务中完成的。另外,对于InnoDB存储引擎的备份,要务必加上-single-transaction的选项(虽然是mysqldump的一个可选选项)。
冷备
对InnoDB存储引擎的冷备非常简单,只需要备份MySQL数据库的frm文件、共享表空间文件、独立表空间文件(*.ibd)、重做日志文件。另外,定期备份MySQL数据库的配置文件my.cnf,这样有利于恢复操作。
通常,DBA会写一个脚本来执行冷备的操作,DBA可能还会对备份完的数据库进行打包和压缩,这并不是一件难事。关键在于,不要遗漏原本需要备份的物理文件,如共享表空间和重做日志文件,少了这些文件数据库可能都无法启动。另外一种经常发生的情况是,由于磁盘空间已满而导致的备份失败,DBA可能习惯性地认为运行脚本的备份是没有问题的,少了检验的机制。
在同一台机器上对数据库进行冷备是远远不够的,还需要将本地的备份放入一台远程服务器中,以确保不会因为本地数据库宕机而影响备份文件的使用。
冷备的优点是:
- 备份简单,只要拷贝相关文件即可。
- 备份文件易于在不同操作系统、不同MySQL版本上进行恢复。
- 恢复相当简单,只需要把文件恢复到指定位置即可。
- 恢复速度快,不需要执行任何SQL语句,也不需要重建索引。
冷备的缺点是:
- InnoDB存储引擎冷备的文件通常比逻辑文件大很多,因为表空间中存放着很多其他数据,如Undo段、插入缓冲等信息。
- 冷备并不总是可以轻易地跨平台。操作系统、MySQL的版本、文件大小写敏感和浮点数格式都会成为问题。
热备
(1)ibbackup
ibbackup是 InnoDB存储引擎官方提供的热备工具,可以同时备份 MyISAM存储引擎和 InnoDB存储引擎表。对于 InnoDB存储引擎表其备份工作原理如下:
- 记录备份开始时, InnoDB存储引擎重做日志文件检查点的LSN。
- 复制共享表空间文件以及独立表空间文件。
- 记录复制完表空间文件后, InnoDB存储引擎重做日志文件检查点的LSN
- 复制在备份时产生的重做日志。
对于事务的数据库,如 Microsoft SQL Server数据库和 Oracle数据库,热备的原理大致和上述相同。可以发现,在备份期间不会对数据库本身有任何影响,所做的操作只是复制数据库文件,因此任何对数据库的操作都是允许的,不会阻塞任何操作。故ibbackup的优点如下:
- 在线备份,不阻塞任何的SQL语句。
- 备份性能好,备份的实质是复制数据库文件和重做日志文件。
- 支持压缩备份,通过选项,可以支持不同级别的压缩。
- 跨平台支持, backup可以运行在 Linux、 Windows以及主流的UNX系统平台上。
ibbackup对 InnoDB存储引擎表的恢复步骤为:
- 恢复表空间文件。
- 应用重做日志文件。
backup提供了一种高性能的热备方式,是 InnoDB存储引擎备份的首选方式。不过它是收费软件,并非免费的软件。好在开源的魅力就在于社区的力量, Percona公司给用户带来了开源、免费的 XtraBackup热备工具,它实现所有 backup的功能,并且扩展支持了真正的增量备份功能。因此,更好的选择是使用 Xtra Backup来完成热备的工作。
(2)XtraBackup
XtraBackup备份工具是由 Percona公司开发的开源热备工具。支持 MySQL5.0以上的版本。 XtraBackup在GPLv2开源下发布,官网地址是:htps://launchpad.net/percona-xtrabackup。
xtrabackup命令的使用方法如下:
xtrabackup --backup | prepare [OPTIONS]
xtrabackup命令的可选参数如下:
--apply-log-only:prepare备份的时候只执行redo阶段,用于增量备份。
--backup:创建备份并且放入--target-dir目录中
--close-files:不保持文件打开状态,xtrabackup打开表空间的时候通常不会关闭文件句柄,目的是为了正确处理DDL操作。如果表空间数量非常巨大并且不适合任何限制,一旦文件不在被访问的时候这个选项可以关闭文件句柄.打开这个选项会产生不一致的备份。
--compact:创建一份没有辅助索引的紧凑备份
--compress:压缩所有输出数据,包括事务日志文件和元数据文件,通过指定的压缩算法,目前唯一支持的算法是quicklz.结果文件是qpress归档格式,每个xtrabackup创建的*.qp文件都可以通过qpress程序提取或者解压缩
--compress-chunk-size=#:压缩线程工作buffer的字节大小,默认是64K
--compress-threads=#:xtrabackup进行并行数据压缩时的worker线程的数量,该选项默认值是1,并行压缩('compress-threads')可以和并行文件拷贝('parallel')一起使用。例如:'--parallel=4 --compress --compress-threads=2'会创建4个IO线程读取数据并通过管道传送给2个压缩线程。
--create-ib-logfile:这个选项目前还没有实现,目前创建Innodb事务日志,你还是需要prepare两次。
--datadir=DIRECTORY:backup的源目录,mysql实例的数据目录。从my.cnf中读取,或者命令行指定。
--defaults-extra-file=[MY.CNF]:在global files文件之后读取,必须在命令行的第一选项位置指定。
--defaults-file=[MY.CNF]:唯一从给定文件读取默认选项,必须是个真实文件,必须在命令行第一个选项位置指定。
--defaults-group=GROUP-NAME:从配置文件读取的组,innobakcupex多个实例部署时使用。
--export:为导出的表创建必要的文件
--extra-lsndir=DIRECTORY:(for --bakcup):在指定目录创建一份xtrabakcup_checkpoints文件的额外的备份。
--incremental-basedir=DIRECTORY:创建一份增量备份时,这个目录是增量别分的一份包含了full bakcup的Base数据集。
--incremental-dir=DIRECTORY:prepare增量备份的时候,增量备份在DIRECTORY结合full backup创建出一份新的full backup。
--incremental-force-scan:创建一份增量备份时,强制扫描所有增在备份中的数据页即使完全改变的page bitmap数据可用。
--incremetal-lsn=LSN:创建增量备份的时候指定lsn。
--innodb-log-arch-dir:指定包含归档日志的目录。只能和xtrabackup --prepare选项一起使用。
--innodb-miscellaneous:从My.cnf文件读取的一组Innodb选项。以便xtrabackup以同样的配置启动内置的Innodb。通常不需要显示指定。
--log-copy-interval=#:这个选项指定了log拷贝线程check的时间间隔(默认1秒)。
--log-stream:xtrabakcup不拷贝数据文件,将事务日志内容重定向到标准输出直到--suspend-at-end文件被删除。这个选项自动开启--suspend-at-end。
--no-defaults:不从任何选项文件中读取任何默认选项,必须在命令行第一个选项。
--databases=#:指定了需要备份的数据库和表。
--database-file=#:指定包含数据库和表的文件格式为databasename1.tablename1为一个元素,一个元素一行。
--parallel=#:指定备份时拷贝多个数据文件并发的进程数,默认值为1。
--prepare:xtrabackup在一份通过--backup生成的备份执行还原操作,以便准备使用。
--print-default:打印程序参数列表并退出,必须放在命令行首位。
--print-param:使xtrabackup打印参数用来将数据文件拷贝到datadir并还原它们。
--rebuild_indexes:在apply事务日志之后重建innodb辅助索引,只有和--prepare一起才生效。
--rebuild_threads=#:在紧凑备份重建辅助索引的线程数,只有和--prepare和rebuild-index一起才生效。
--stats:xtrabakcup扫描指定数据文件并打印出索引统计。
--stream=name:将所有备份文件以指定格式流向标准输出,目前支持的格式有xbstream和tar。
--suspend-at-end:使xtrabackup在--target-dir目录中生成xtrabakcup_suspended文件。在拷贝数据文件之后xtrabackup不是退出而是继续拷贝日志文件并且等待知道xtrabakcup_suspended文件被删除。这项可以使xtrabackup和其他程序协同工作。
--tables=name:正则表达式匹配database.tablename。备份匹配的表。
--tables-file=name:指定文件,一个表名一行。
--target-dir=DIRECTORY:指定backup的目的地,如果目录不存在,xtrabakcup会创建。如果目录存在且为空则成功。不会覆盖已存在的文件。
--throttle=#:指定每秒操作读写对的数量。
--tmpdir=name:当使用--print-param指定的时候打印出正确的tmpdir参数。
--to-archived-lsn=LSN:指定prepare备份时apply事务日志的LSN,只能和xtarbackup --prepare选项一起用。
--user-memory = #:通过--prepare prepare备份时候分配多大内存,目的像innodb_buffer_pool_size。默认值100M如果你有足够大的内存。1-2G是推荐值,支持各种单位(1MB,1M,1GB,1G)。
--version:打印xtrabackup版本并退出。
--xbstream:支持同时压缩和流式化。需要客服传统归档tar,cpio和其他不允许动态streaming生成的文件的限制,例如动态压缩文件,xbstream超越其他传统流式/归档格式的的优点是,并发stream多个文件并且更紧凑的数据存储(所以可以和--parallel选项选项一起使用xbstream格式进行streaming)。
(3)XtraBackup实现增量备份
Mysql数据库本身提供的工具并不支持真正的增量备份,更准确地说,二进制日志的恢复应该是 point-in-time的恢复而不是增量备份。而 XtraBackup工具支持对于InnoDB存储引擎的增量备份,其工作原理如下:
- 首选完成一个全备,并记录下此时检查点的LSN。
- 在进行增量备份时,比较表空间中每个页的LSN是否大于上次备份时的LSN,如果是,则备份该页,同时记录当前检查点的LSN。

在上述过程中,首先将全部文件备份到/backup/base目录下,增量备份产生的文件备份到/backup/delta。在恢复过程中,首先指定全备的路径,然后将增量的备份应用于该完全备份。
逻辑备份
mysqldump
mysqldump备份工具最初由Igor Romanenko编写完成,通常用来完成转存(dump)数据库的备份及不同数据库之间的移植,如从MySQL低版本数据库升级到 MySQL高版本数据库,又或者从 MySQL数据库移植到 Oracle、 Microsoft SQL Server数据库等。
mysqldump的语法如下:
mysqldump [arguments] > file name
如果想要备份所有的数据库,可以使用–all-databases选项:
mysqldump --all-databases >dump. sql
如果想要备份指定的数据库,可以使用–databases选项:
mysqldump --databases db1 db2 db3 >dump. sql
如果想要对test这个架构进行备份,可以使用如下语句:
mysqldump --single-transaction test >test_backup.sql
上述操作产生了一个对test架构的备份,使用–single-transaction选项来保证备的一致性。备份出的 test_backup. sql是文本文件,通过文本查看命令cat就可以得到文件的内容。
备份出的文件内容就是表结构和数据,所有这些都是用SQL语句方式表示。文件开始和结束的注释部分是用来设置 MySQL数据库的各项参数,一般用来使还原工作更有效和准确地进行。之后的部分先是 CREATE TABLE语句,接着就是 INSERT的SQL语句了。
mysqldump的参数选项很多,可以通过使用 mysqldump --help命令来查看所有的参数,有些参数有缩写形式,如–lock-tables的缩写形式-l。这里列举一些比较重要的参数。
- –single-transaction:在备份开始前,先执行 START TRANSACTION命令,以此来获得备份的一致性,当前该参数只对 InnoDB存储引擎有效。当启用该参数并进行备份时,确保没有其他任何的DDL语句执行,因为一致性读并不能隔离DDL操作。
- –lock-tables(-l):在备份中,依次锁住每个架构下的所有表。一般用于 MyIsAM存储引擎,当备份时只能对数据库进行读取操作,不过备份依然可以保证一致性。对于 InnoDB存储引擎,不需要使用该参数,用-- single-transaction即可。并且–lock-tables和–single-transaction是互斥( exclusive)的,不能同时使用。如果用户的 MySQL数据库中,既有 MyISAM存储引擎的表,又有 InnoDB存储引擎的表,那么这时用户的选择只有–lock-tables了。此外,正如前面所说的那样,–lock-tables选项是依次对每个架构中的表上锁的,因此只能保证每个架构下表备份的一致性,而不能保证所有架构下表的一致性。
- –lock-all-tables(-x):在备份过程中,对所有架构中的所有表上锁。这个可以避免之前说的–lock-tables参数不能同时锁住所有表的问题。
- -add-dop-database:在 CREATE DATABASE前先运行 DROP DATABASE。这个参数需要和–all-databases或者–databases选项一起使用。在默认情况下,导出的文本文件中并不会有 CREATE DATABASE,除非指定了这个参数。
- –master-data[=value]:通过该参数产生的备份转存文件主要用来建立一个replication。当value的值为1时,转存文件中记录CHANGE MASTER语句。当value的值为2时, CHANGE MASTER语句被写出SQL注释。在默认情况下,value的值为空。当 value值为1时,在备份文件中会看到:CHANGE MASTER TO MASTER_LOG_FILE=‘xen-server-bin.000006’,MASTER_LOG_POS=8095;当 value为2时,在备份文件中会看到 CHANGE MASTER语句被注释了。
- –master-data:会自动忽略–lock-tables选项。如果没有使用–single-transaction选项,则会自动使用–lock-all-tables选项。
- –events(-E):备份事件调度器。
- –routines(-R):备份存储过程和函数。
- –triggers:备份触发器。
- –hex-blob:将 BINARY、 VARBINARY、BLOG和BIT列类型备份为十六进制的格式。 mysqldump导出的文件一般是文本文件,但是如果导出的数据中有上述这些类型,在文本文件模式下可能有些字符不可见,若添加–hex-blob选项,结果会以十六进制的方式显示。
- –tab=path(-T path):产生TAB分割的数据文件。对于每张表, mysqldump创建一个包含 CREATE TABLE语句的 table_name.sql文件,和包含数据的tbl_name. txt文件。可以使用–fields-terminated-by=.…,–fields-enclosed-by=.…,–fields-optionally-enclosed-by=…,–fields-escaped-by=…,–lines-terminated-by=…来改变默认的分割符、换行符等。
我发现大多数DBA喜欢用 SELECT…INTO OUTFILE的方式来导出一张表,但是通过mysqldump一样可以完成工作,而且可以一次完成多张表的导出,并且实现导出数据的一致性。
-
–where=’ where_condition’(-W 'where_condition’):导出给定条件的数据。如导出b架构下的表a,并且表a的数据大于2:
mysqldump --single-transaction --where='b>2' test a > a.sql
SELECT…INTO OUTFILE
SELECT…INTO语句也是一种逻辑备份的方法,更准确地说是导出一张表中的数据。 SELECT…INTO的语法如下:
SELECT [column 1], [column 2]
INTO
OUTFILE 'file_name'
[ (FIELDS 1 COLUMNS)
[TERMINATED BY 'string']
[ [OPTIONALLY] ENCLOSED BY ' char']
(ESCAPED BY ' char' ]
]
[LINES
[STARTING BY ' string' ]
[TERMINATED BY 'string']
]
FROM TABLE WHERE
其中:
- FIELDS[TERMINATED BY ‘string’]表示每个列的分隔符;
- [[OPTIONALLY] ENCLOSED BY ‘char’]表示对于字符串的包含符;
- [ESCAPED BY ‘char’ ]表示转义符;
- [ STARTING BY ‘string’]表示每行的开始符号, TERMINATED BY ‘string’,表示每行的结束符号。
如果没有指定任何的 FIELDS和 LINES的选项,默认使用以下的设置:
FIELDS TERMINATED BY '\t' ENCLOSED BY ' ' ESCAPED BY '\\'
LINES TERMINATED BY '\n' STARTING BY ' '
file_name表示导出的文件,但文件所在的路径的权限必须是mysql:mysql的,否则 MySQL会报没有权限导出:
mysql> select into outfile '/root/a. txt' from a;
ERROR 1(HY000): Can't create/write to file '/root/a. txt (Errcode: 13)
若已经存在该文件,则同样会报错:
mysql test -e "select into outfile '/home/mysql/a. txt' fields terminated by ',' from a
ERROR 1086(HYooo)at line 1: File '/home/mysql/a. txt already exists
查看文件:
cat /home/mysql/a.txt
1 a
2 b
3 c
可以看到,默认导出的文件是以TAB进行列分割的,如果想要使用其他分割符,如“,”,则可以使用FIELDS TERMINATED BY ‘string’ 选项。
恢复
(1)mysqldump
mysqldump的恢复操作比较简单,因为备份的文件就是导出的SQL语句,一般只需要执行这个文件就可以了,可以通过以下的方法
mysql -uroot -p <test_backup.sql
因为逻辑备份的文件是由SQL语句组成的,也可以通过SOURCE命令来执行导出的逻辑备份文件,如下:
mysql> source /home/mysql/test_backup.sql;
通过 mysqldump可以恢复数据库,但是经常发生的一个问题是, mysqldump可以导出存储过程、导出触发器、导出事件、导出数据,但是却不能导出视图。因此,如果用户的数据库中还使用了视图,那么在用 mysqldump备份完数据库后还需要导出视图的定义,或者备份视图定义的frm文件,并在恢复时进行导入,这样才能保证 mysqldump数据库的完全恢复。
(2)mysqldump --tab和SELECT INTO OUTFILE
若通过 mysqldump --tab,或者通过 SELECT INTO OUTFILE导出的数据需要恢复,这时可以通过命令 LOAD DATA INFILE来进行导入。LOAD DATA INFILE的语法如下:
LOAD DATA INTO TABLE a IGNORE 1 LINES INFILE ' /home/mysql/a.txt'
[REPLACE I IGNORE ]
INTO TABLE tbl_name
[CHARACTER SET charset_name ]
[ (FIELDS I COLUMNS )
[TERMINATED BY ' string' ]
[ [OPTIONALLY] ENCLOSED BY ' char' ]
[ESCAPED BY ' char' ]
]
[ LINES
[STARTING BY ' string' ]
[TERMINATED BY ' string' ]
[ IGNORE number LINES]
[ (col_name_or_user_var,...) ]
[SET col_name= expr,...]
要对服务器文件使用 LOAD DATA INFILE,必须拥有FILE权。其中对于导入格式的选项和之前介绍的 SELECT INTO OUTFILE命令完全一样。 IGNORE number LINES选项可以忽略导入的前几行。下面显示一个用 LOAD DATA INFILE命令导入文件的示例,并忽略第一行的导入:
mysql> load data infile '/home/mysql/a.txt' into table a;
为了加快 InnoDB存储引擎的导入,可能希望导入过程忽略对外键的检查,因此可以使用如下方式:
mysql>SET @@foreign_key_checks=0;
Query OK, 0 rows affected (0.00 sec)
mysql>LOAD DATA INFILE ' /home/mysql/a.txt' INTO TABLE a;
Query OK, 4 rows affected (0.00 sec)
Records: 4 Deleted: 0 Skipped: 0 Warnings: 0
mysql>SET @foreign_key_checks=1;
Query OK, 0 rows affected (0.00 sec)
另外可以针对指定的列进行导入,如将数据导人列a、b,而c列等于a、b列之和:
LOAD DATA INFILE '/home /mysql/a.txt' INTO TABLE b FIELDS TERMINATED BY ',' (a,b) SET c=a+b;
(3)mysqlimport
mysqlimport是 MySQL数据库提供的一个命令行程序,从本质上来说,是LOAD DATA INFILE的命令接口,而且大多数的选项都和 LOAD DATA INFILE语法相同。其语法格式如下:
mysqlimport [options] db_name textfile1 [textfile2 ...]
和 LOAD DATA INFILE不同的是,,mysqlimport命令可以用来导入多张表。并且通过–user-thread参数并发地导入不同的文件。这里的并发是指并发导人多个文件,而不是指 mysqlimport可以并发地导入一个文件,这是有明显区别的。此外,通常来说并发地对同一张表进行导入,其效果一般都不会比串行的方式好。下面通过 mysqlimport并发地导人2张表:
[rootexen-servermysql]# mysqlimport --use-threads=2 test /home/mysql/t.txt /home/mysql/s.txt
test.s:Records: 5000000 Deleted: 0 Skipped: 0 Warnings: 0
test.t:Records: 5000000 Deleted: 0 Skipped: 0 Warnings: 0
二进制日志备份与恢复
二进制日志非常关键,用户可以通过它完成 point-in-time的恢复工作。 MySQL数据库的replication同样需要二进制日志。在默认情况下并不启用二进制日志,要使用二进制日志首先必须启用它。如在配置文件中进行设置:
[mysqld]
log-bin=mysql-bin
对于InnoDB存储引擎只简单启用二进制日志是不够的,还需要启用一些其他参数来保证最为安全和正确地记录二进制日志,因此对于 InnoDB存储引擎,推荐的二进制日志的服务器配置应该是:
[mysqld]
log-bin=mysql-bin
sync_binlog=1
innodb_support_xa=1
在备份二进制日志文件前,可以通过 FLUSH LOGS命令来生成一个新的二进制日志文件,然后备份之前的二进制日志。
要恢复二进制日志也是非常简单的,通过 mysqlbinlog即可。mysqlbinlog的使用方法如下:
shell>mysqlbinlog [options] log file
例如要还原 binlog.00000可以使用如下命令:
shell>mysqlbinlog binlog.0000001 I mysql -uroot -p test
如果需要恢复多个二进制日志文件,最正确的做法应该是同时恢复多个二进制日志文件,而不是一个一个地恢复,如:
shell>mysqlbinlog binlog.[0-10]* | mysql -uroot -p test
也可以先通过 mysqlbinlog命令导出到一个文件,然后再通过 SOURCE 命令来导入,这种做法的好处是可以对导出的文件进行修改后再导入,如:
shell>mysqlbinlog binlog.000001 >/tmp/statements.sql
shell>mysqlbinlog binlog.000002>>/tmp/statements.sql
shell>mysql -u root -p -e "source /tmp/statements.sql"
–start-position和–stop-position选项可以用来指定从二进制日志的某个偏移量来进行恢复,这样可以跳过某些不正确的语句,如:
shell>mysqlbinlog --start-position107856 binlog.0000001 I mysql-uroot -p test
–start-datetime和–stop-datetime选项可以用来指定从二进制日志的某个时间点来进行恢复,用法和–start-position和–stop-position选项基本相同。
快照备份(完全备份)
MySQL数据库本身并不支持快照功能,因此快照备份是指通过文件系统支持的快照功能对数据库进行备份。备份的前提是将所有数据库文件放在同一文件分区中,然后对该分区进行快照操作。
LVM是 LINUX系统下对磁盘分区进行管理的一种机制。LVM在硬盘和分区之上建立一个逻辑层,来提高磁盘分区管理的灵活性。管理员可以通过LVM系统轻松管理磁盘分区,例如:将若干个磁盘分区连接为一个整块的卷组( Volume Group),形成一个存储池。管理员可以在卷组上随意创建逻辑卷(Logical Volumes),并进一步在逻辑卷上创建文件系统。管理员通过LVM可以方便地调整卷组的大小,并且可以对磁盘存储按照组的方式进行命名、管理和分配。简单地说:用户可以通过LVM由物理块设备(如硬盘等)创建物理卷,由一个或多个物理卷创建卷组,最后从卷组中创建任意个逻辑卷(不超过卷组大小)。如图:
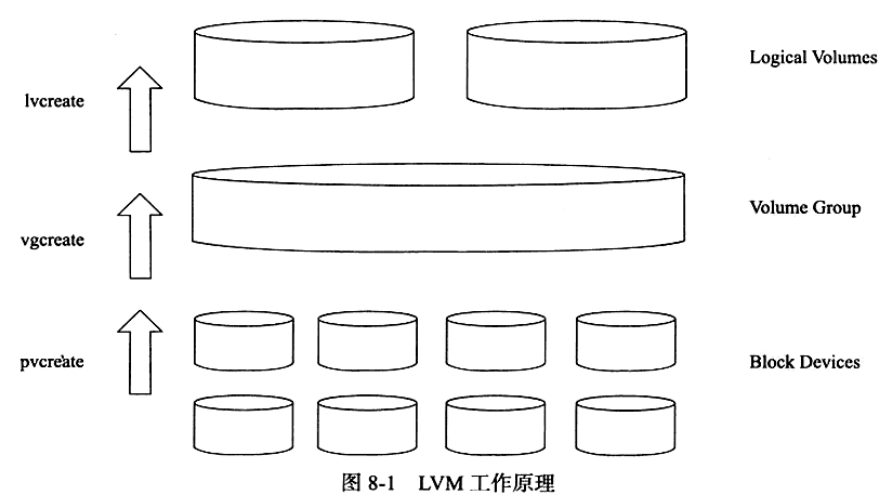
下图显示了由多块磁盘组成的逻辑卷LV0:

vgdisplay命令查看系统中有哪些卷组;lvdisplay命令可以用来查看当前系统中有哪些逻辑卷。
用LVM快照备份 InnoDB存储引擎表相当简单,只要把与 InnoDB存储引擎相关的文件如共享表空间、独立表空间、重做日志文件等放在同一个逻辑卷中,然后对这个逻辑卷做快照备份即可。
在对 InnoDB存储引擎文件做快照时,数据库无须关闭,即可以进行在线备份。虽然此时数据库中可能还有任务需要往磁盘上写数据,但这不会妨碍备份的正确性。因为InnoDB存储引擎是事务安全的引擎,在下次恢复时,数据库会自动检查表空间中页的状态,并决定是否应用重做日志,恢复就好像数据库被意外重启了。
-
LVM使用了写时复制(Copy-on- write)技术来创建快照。当创建一个快照时,仅复制原始卷中数据的元数据(meta data),并不会有数据的物理操作,因此快照的创建过程是非常快的。当快照创建完成,原始卷上有写操作时,快照会跟踪原始卷块的改变,将要改变的数据在改变之前复制到快照预留的空间里,因此这个原理的实现叫做写时复制。
-
而对于快照的读取操作,如果读取的数据块是创建快照后没有修改过的,那么会将读操作直接重定向到原始卷上,如果要读取的是已经修改过的块,则将读取保存在快照中该块在原始卷上改变之前的数据。因此,采用写时复制机制保证了读取快照时得到的数据与快照创建时一致。
下图显示了LVM的快照读取,可见B区块被修改了,因此历史数据放入了快照区域。读取快照数据时,A、C、D块还是从原有卷中读取,而B块就需要从快照读取了。
命令 Ivcreate可以用来创建一个快照,–permission r表示创建的快照是只读的:
lvcreate --size 100G --snapshot --permission r -n datasnapshot /dev/rep/repdata
在快照制作完成后可以用 Display命令查看,输出中的 COW-table size字段表示该快照最大的空间大小, Allocated to snapshot字段表示该快照目前空间的使用状况:
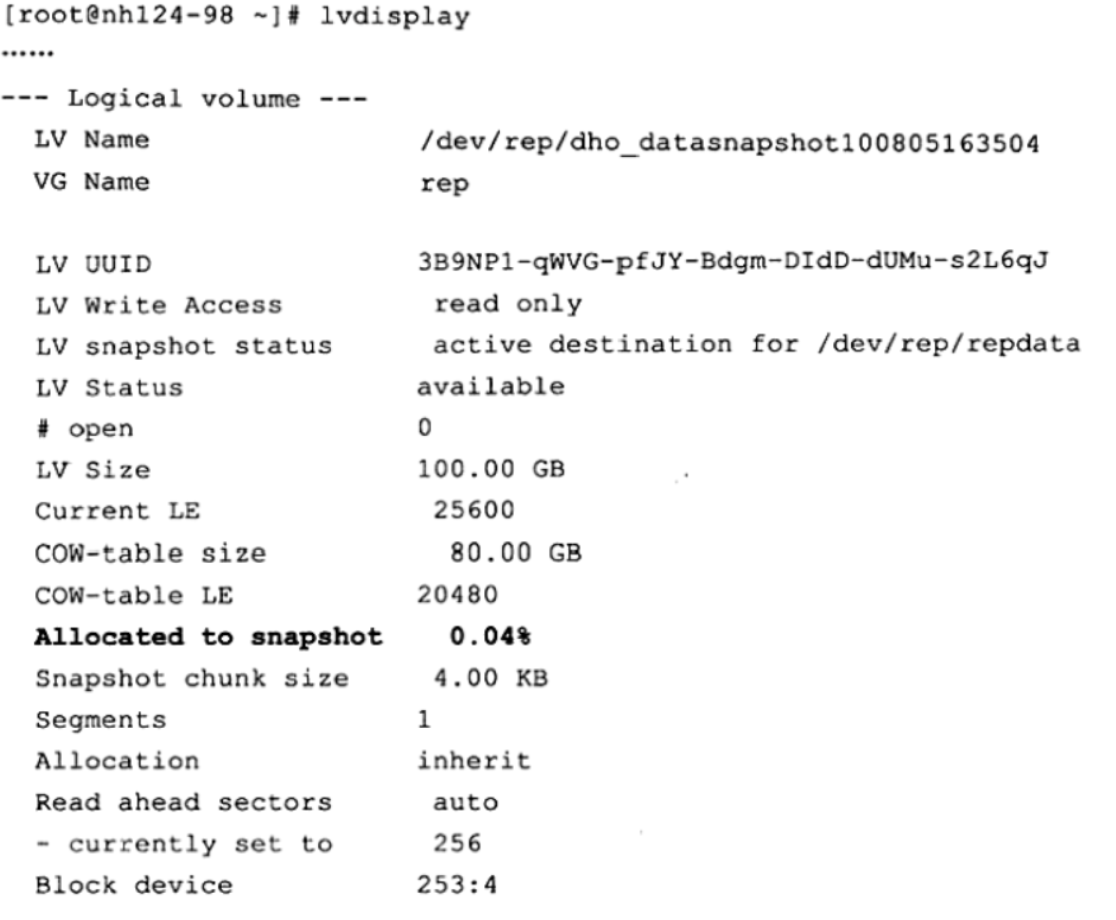
可以看到,当前快照只使用0.04%的空间。快照在最初创建时总是很小,当数据来源卷的数据不断被修改时,这些数据库才会放入快照空间,这时快照的大小才会慢慢增大。
复制
复制(replication)是MySQL数据库提供的一种高可用高性能的解决方案,一般用来建立大型的应用。总体来说, replication的工作原理分为以下3个步骤:
- 主服务器(master)把数据更改记录到二进制日志(binlog)中。
- 从服务器(slave)把主服务器的二进制日志复制到自己的中继日志(relay log)中。
- 从服务器重做中继日志中的日志,把更改应用到自己的数据库上,以达到数据的最终一致性。
复制的工作原理并不复杂,其实就是一个完全备份加上二进制日志备份的还原。不同的是这个二进制日志的还原操作基本上实时在进行中。这里特别需要注意的是,复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务器之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。复制的工作原理如图:
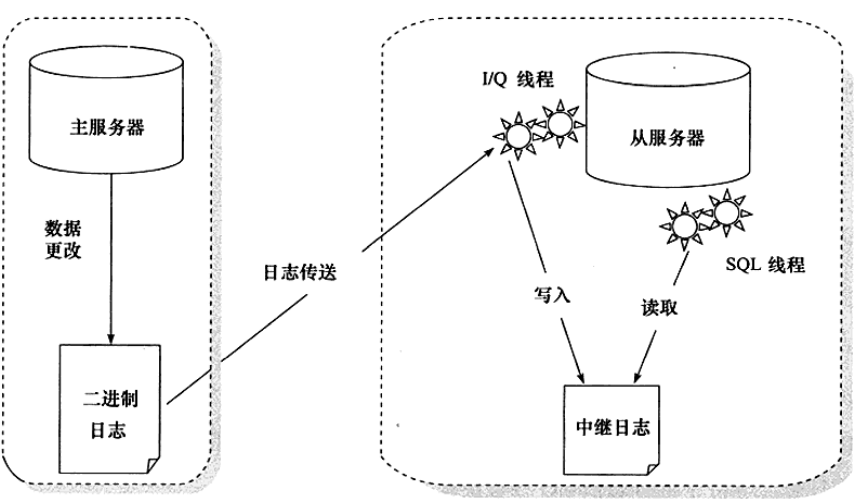
从服务器有2个线程:
- 一个是IO线程,负责读取主服务器的二进制日志,并将其保存为中继日志;
- 另一个是SQL线程,复制执行中继日志。
可以通过SHOW FULL PROCESSLIST命令查看线程:
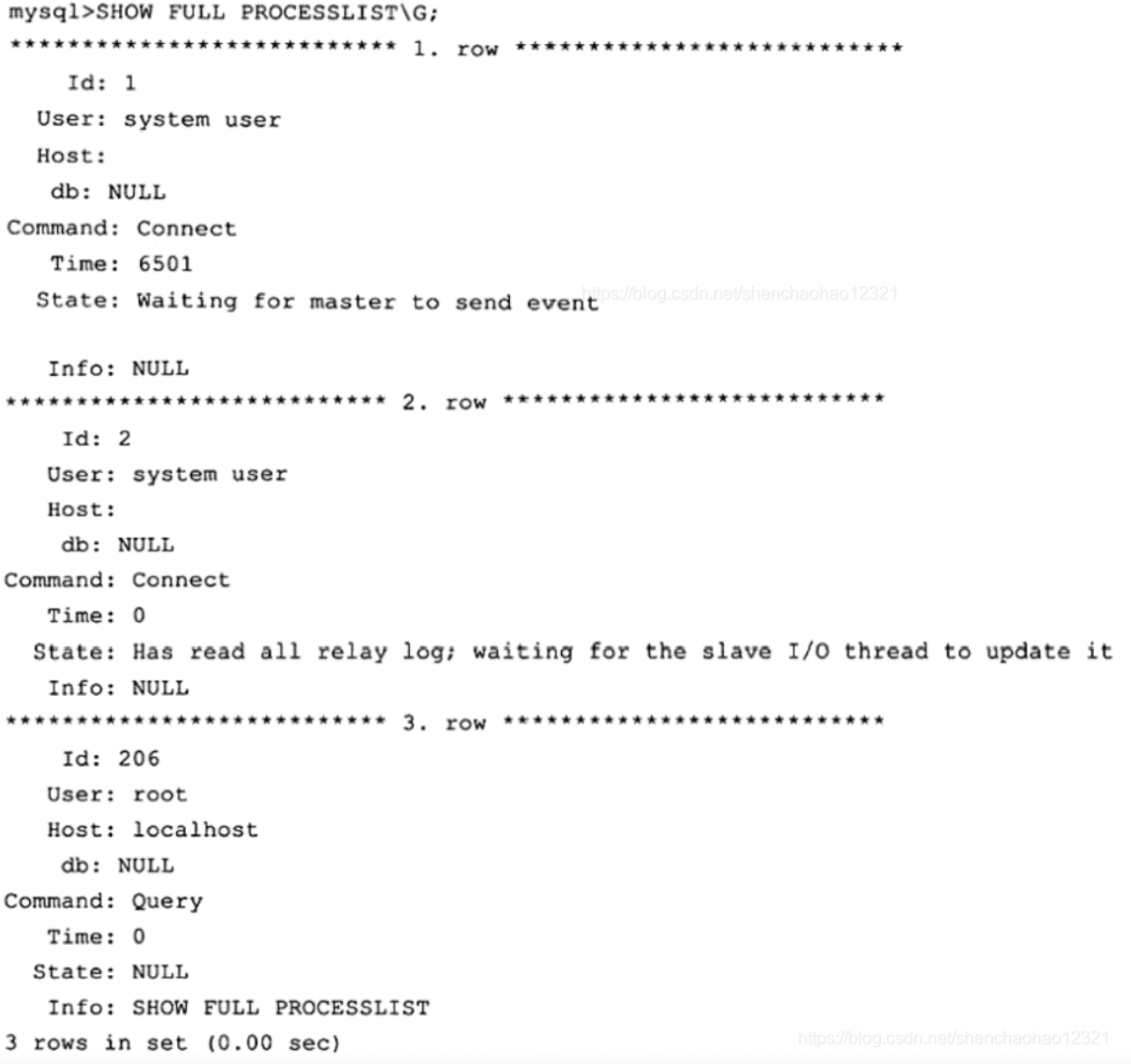
可以看到ID为1的线程就是IO线程,目前的状态是等待主服务器发送二进制日志。ID为2的线程是SQL线程,负责读取中继日志并执行。目前的状态是已读取所有的中继日志,等待中继日志被IO线程更新。
在replication的主服务器上应该可以看到一个线程负责发送二进制日志,类似内容如下:

之前已经说过 MySQL的复制是异步实时的,并非完全的主从同步。若用户要想得知当前的延迟,可以通过命令 SHOW SLAVE STATUS和 SHOW MASTER STATUS得知,如:

通过 SHOW SLAVE STATUS命令可以观察当前复制的运行状态,一些主要的变量如下表所示:
| 变量 | 说明 |
|---|---|
| Slave_IO_State | 显示当前IO线程的状态,上述状态显示的是等待主服务发送二进制日志 |
| Master_Log_File | 显示当前同步的主服务器的二进制日志,上述显示当前同步的是主服务器的mysql-bin.000007 |
| Read_master_Log_Pos | 显示当前同步到主服务器上二进制日志的偏移量位置,单位是字节。上述的示例显示当前同步到 mysql-bin000007的551671偏移量位置,即已经同步了mysql-bin000007这个二进制日志中529MB (555176471/10241024)的内容 |
| Relay_Master_Log_File | 当前中继日志同步的二进制日志 |
| Relay_Log_File | 显示当前写入的中继日志 |
| Relay_Log_Pos | 显示当前执行到中继日志的偏移量位置 |
| Slave_IO_Running | 从服务器中IO线程的运行状态,YES表示运行正常 |
| Slave_SQL_Running | 从服务器中SQL线程的运行状态,YES表示运行正常 |
| Exec_master_Log_Pos | 表示同步到主服务器的二进制日志偏移量的位置。(Read_Master_Log_Pos-Exec_Master_Log._Pos)可以表示当前SQL线程运行的延时,单位是字节。上述例子显示当前主从服务器是完全同步的 |
命令 SHOW MASTER STATU可以用来查看主服务器中二进制日志的状态,如:

可以看到,当前二进制日志记录了偏移量606181078的位置,该值减去这一时间点时从服务器上的Read_Master_Log_Pos,就可以得知IO线程的延时。
对于一个优秀的 MySQL数据库复制的监控,用户不应该仅仅监控从服务器上IO线程和SQL线程运行得是否正常,同时也应该监控从服务器和主服务器之间的延迟,确保从服务器上的数据库总是尽可能地接近于主服务器上数据库的状态。
快照+复制的备份架构
复制可以用来作为备份,但功能不仅限于备份,其主要功能如下:
- 数据分布。由于 MySQL数据库提供的复制并不需要很大的带宽要求,因此可以在不同的数据中心之间实现数据的复制。
- 读取的负载平衡。通过建立多个从服务器,可将读取平均地分布到这些从服务器中,并且减少了主服务器的压力。一般通过DNS的 Round-Robin和 Linux的LVS功能都可以实现负载平衡。
- 数据库备份。复制对备份很有帮助,但是从服务器不是备份,不能完全代替备份。
- 高可用性和故障转移。通过复制建立的从服务器有助于故障转移,减少故障的停机时间和恢复时间。
可见,复制的设计不是简简单单用来备份的,并且只是用复制来进行备份是远远不够的。假设当前应用采用了主从的复制架构,从服务器作为备份。这时,一个初级DBA执行了误操作,如 DROP DATABASE或 DROP TABLE,这时从服务器也跟着运行了。
这时用户怎样从服务器进行恢复呢?
因此,一个比较好的方法是通过对从服务器上的数据库所在分区做快照,以此来避免误操作对复制造成影响。当发生主服务器上的误操作时,只需要将从服务器上的快照进行恢复,然后再根据二进制日志进行point-in-time的恢复即可。因此快照+复制的备份架构如图所示:

还有一些其他的方法来调整复制,比如采用延时复制,即间歇性地开启从服务器上的同步,保证大约一小时的延时。这的确也是一个方法,只是数据库在高峰和非高峰期间每小时产生的二进制日志量是不同的,用户很难精准地控制。另外,这种方法也不能完全起到对误操作的防范作用。




![[附源码]Nodejs计算机毕业设计基于微信平台的车险投保系统设计与实现Express(程序+LW)](https://img-blog.csdnimg.cn/bd468cafad2b42e58bf73f7491d640be.png)
![[CISCN2019 华北赛区 Day1 Web2]](https://img-blog.csdnimg.cn/32151f23286448f88bb202ff3a2049d0.png)