目录
- 条款25:将构造函数和非成员函数虚化
- 条款26:限制某个类所能产生的对象数量
- 条款27:要求(或禁止)对象产生于heap(堆)之中
- 条款28:智能指针
- 条款29:引用计数
- 条款30:Proxy classes(代理类)
- 条款31:让函数根据一个以上的对象类型来决定如何虚化
条款25:将构造函数和非成员函数虚化
- 构造函数和非成员函数虚化并非真的将两类函数设为虚函数,而是让它们的行为呈现虚函数多态行为。
- 构造函数虚化是指函数视其获得的输入,可产生不同类型的对象。虚化的构造函数在许多情况下有用,其中之一就是从磁盘、网络读取不同对象的信息。如下代码没有展示如何虚化普通的构造函数,但我认为可以借鉴后续非成员函数虚化技术来实现。
class NLComponent { //用于 newsletter components
public: // 的抽象基类
... //包含至少一个纯虚函数
};
class TextBlock: public NLComponent {
public:
... // 不包含纯虚函数
};
class Graphic: public NLComponent {
public:
... // 不包含纯虚函数
};
class NewsLetter { // 一个 newsletter 对象
public: // 由NLComponent 对象
... // 的链表组成
private:
list<NLComponent*> components;
};
class NewsLetter {
public:
...
private:
// 为建立下一个NLComponent对象从str读取数据,
// 建立component 并返回一个指针。
static NLComponent * readComponent(istream& str);
...
};
NewsLetter::NewsLetter(istream& str)
{
while (str) {
// 把readComponent返回的指针添加到components链表的最后,
// "push_back" 一个链表的成员函数,用来在链表最后进行插入操作。
components.push_back(readComponent(str));
}
}
- 拷贝构造函数虚化:能返回一个指针,指向调用该函数的对象的新拷贝。因为这种行为特性,虚化拷贝构造函数的名字一般都是copySelf,cloneSelf或者是象下面这样就叫做clone。其中需要注意,如果基类虚函数的返回类型是一个指向基类的指针(或一个引用),那么派生类中对应的虚函数可以返回一个指向“基类的派生类”的指针(或引用)。这样一来,虚函数clone()可以copy出不同类型的对象,功能类似于拷贝构造函数。
class NLComponent {
public:
// declaration of virtual copy constructor
virtual NLComponent * clone() const = 0;
...
};
class TextBlock: public NLComponent {
public:
virtual TextBlock * clone() const // virtual copy
{ return new TextBlock(*this); } // constructor
...
};
class Graphic: public NLComponent {
public:
virtual Graphic * clone() const // virtual copy
{ return new Graphic(*this); } // constructor
...
};
class NewsLetter {
public:
NewsLetter(const NewsLetter& rhs);
...
private:
list<NLComponent*> components;
};
NewsLetter::NewsLetter(const NewsLetter& rhs)
{
// 遍历整个rhs链表,使用每个元素的虚拟拷贝构造函数
// 把元素拷贝进这个对象的component链表。
// 有关下面代码如何运行的详细情况,请参见条款M35.
for (list<NLComponent*>::const_iterator it =
rhs.components.begin();
it != rhs.components.end();
++it) {
// "it" 指向rhs.components的当前元素,调用元素的clone函数,
// 得到该元素的一个拷贝,并把该拷贝放到
// 这个对象的component链表的尾端。
components.push_back((*it)->clone());
}
}
- 非成员函数虚化:让非成员函数的行为视其参数的动态类型而不同。其步骤是写一个虚函数做实际工作,再写一个其他什么都不做的非虚函数,只负责调用虚函数。下例中相当于把非成员函数operator<<虚化了。为了避免函数调用时所带来的成本,可以将非虚函数inline化。
class NLComponent {
public:
// 对输出操作符的不寻常的声明
virtual ostream& operator<<(ostream& str) const = 0;
...
};
class TextBlock: public NLComponent {
public:
// 虚拟输出操作符(同样不寻常)
virtual ostream& operator<<(ostream& str) const;
};
class Graphic: public NLComponent {
public:
// 虚拟输出操作符 (让就不寻常)
virtual ostream& operator<<(ostream& str) const;
};
TextBlock t;
Graphic g;
...
t << cout; // 通过virtual operator<<
//把t打印到cout中。
// 不寻常的语法
g << cout; //通过virtual operator<<
//把g打印到cout中。
//不寻常的语法
class NLComponent {
public:
virtual ostream& print(ostream& s) const = 0;
...
};
class TextBlock: public NLComponent {
public:
virtual ostream& print(ostream& s) const;
...
};
class Graphic: public NLComponent {
public:
virtual ostream& print(ostream& s) const;
...
};
inline
ostream& operator<<(ostream& s, const NLComponent& c)
{
return c.print(s);
}
条款26:限制某个类所能产生的对象数量
- 若需允许零个或一个对象:资源有限情景下,例如只有一台打印机。
(1)方法1:首先声明Printer类的构造函数是private,阻止用户自己建立该类对象。其次、全局函数thePrinter被声明为类的友元(也可将函数放入类内,成为成员函数),让thePrinter避免私有构造函数引起的限制。最后thePrinter包含一个静态Printer对象。缺点:静态局部变量生命周期为全局但局部可见,会造成唯一静态对象调用语句冗长,且静态变量不能在中途被自由创建与销毁。
class PrintJob; // forward 声明
// 参见Effective C++条款34
class Printer {
public:
void submitJob(const PrintJob& job);
void reset();
void performSelfTest();
...
friend Printer& thePrinter();
private:
Printer();
Printer(const Printer& rhs);
...
};
Printer& thePrinter()
{
static Printer p; // 单个打印机对象
return p;
}
//调用语句冗长:
string buffer; //填充buffer
thePrinter().reset();
thePrinter().submitJob(buffer);
(2)方法2:把thePrinter移出全局域,放入namespace(命名空间),命名空间能够防止命名冲突。
namespace PrintingStuff {
class Printer { // 在命名空间
public: // PrintingStuff中的类
void submitJob(const PrintJob& job);
void reset();
void performSelfTest();
...
friend Printer& thePrinter();
private:
Printer();
Printer(const Printer& rhs);
...
};
Printer& thePrinter() // 这个函数也在命名空间里
{
static Printer p;
return p;
}
}
(3)方法3:直接声明一个类静态成员变量对已构造的对象计数,构造一个对象就+1,析构一个对象就-1,如果无资源就抛出异常。这种方法简单易懂。
- 上述方法中有两点需注意:
(1)均将唯一资源对象声明为一个函数的局部静态变量而非类的静态成员变量,因为class静态成员初始化时机不定,涉及不同编译单元内的static初始化顺序问题,而函数的静态变量初始化在函数被调用的第一次,初始化顺序明确。
(2)不要 inline 含有静态局部变量的函数。因为inline函数在多个cpp文件中调用展开时,可能会构建多个静态局部变量副本。 - 上述策略在继承方面存在困难,例如彩色打印机类继承打印机类,构建彩色打印机对象的时候,需要构建基类打印机对象,可能会造成基类打印机对象资源已经饱和,导致彩色打印机对象无法构建。应当避免具体类继承其他具体类。带有private构造函数的类不能够被当作基类,构造函数无法被除友元类之外的类访问,派生类也不行。
- 若需确保某类可生成对象的数量为任意,且确保没有任何类继承该类:第一步声明私有构造函数,第二步声明一个伪造的构造函数调用私有构造函数。
class FSA {
public:
// 伪构造函数
static FSA * makeFSA();
static FSA * makeFSA(const FSA& rhs);
...
private:
FSA();
FSA(const FSA& rhs);
...
};
FSA * FSA::makeFSA()
{ return new FSA(); }
FSA * FSA::makeFSA(const FSA& rhs)
{ return new FSA(rhs); }
- 若允许生成某类特定个数的对象,且对象可以自由创建与销毁:私有构造函数(确保不被继承)+伪构造构造(确保可以生成任意对象)+静态变量计数(确保对象特定个数)。
class Printer {
public:
class TooManyObjects{};
// 伪构造函数
static Printer * makePrinter();
static Printer * makePrinter(const Printer& rhs);
...
private:
static size_t numObjects;
static const size_t maxObjects = 10; // 可能编译器不允许
Printer();
Printer(const Printer& rhs);
};
// Obligatory definitions of class statics
size_t Printer::numObjects = 0;
const size_t Printer::maxObjects;
Printer::Printer()
{
if (numObjects >= maxObjects) {
throw TooManyObjects();
}
...
}
Printer::Printer(const Printer& rhs)
{
if (numObjects >= maxObjects) {
throw TooManyObjects();
}
...
}
Printer * Printer::makePrinter()
{ return new Printer; }
Printer * Printer::makePrinter(const Printer& rhs)
{ return new Printer(rhs); }
- 设计一个计算对象个数的基类:前面讲述的方法需要针对不同的类去撰写可能相同的代码,重复相同的工作。可以设计一个计数的基类,其他类继承它即可计数。下列方法中采用private继承计数类,因为public继承则会需要将析构函数设为虚函数来避免用户通过基类指针销毁派生类导致内存泄漏,虚函数会有一定对象大小和内存开销,private继承可以避免这一开销。为了让用户了解对象个数信息,用using声明将基类静态变量变为public访问级别。
template<class BeingCounted>
class Counted {
public:
class TooManyObjects{}; // 用来抛出异常
static int objectCount() { return numObjects; }
protected:
Counted();
Counted(const Counted& rhs);
~Counted() { --numObjects; }
private:
static int numObjects;
static const size_t maxObjects;
void init(); // 避免构造函数的
}; // 代码重复
template<class BeingCounted>
Counted<BeingCounted>::Counted()
{ init(); }
template<class BeingCounted>
Counted<BeingCounted>::Counted(const Counted<BeingCounted>&)
{ init(); }
template<class BeingCounted>
void Counted<BeingCounted>::init()
{
if (numObjects >= maxObjects) throw TooManyObjects();
++numObjects;
}
现在我们能修改Printer类,这样使用Counted模板:
class Printer: private Counted<Printer> {
public:
// 伪构造函数
static Printer * makePrinter();
static Printer * makePrinter(const Printer& rhs);
~Printer();
void submitJob(const PrintJob& job);
void reset();
void performSelfTest();
...
using Counted<Printer>::objectCount; // 参见下面解释
using Counted<Printer>::TooManyObjects; // 参见下面解释
private:
Printer();
Printer(const Printer& rhs);
};
条款27:要求(或禁止)对象产生于heap(堆)之中
- 要求对象产生于heap之中:非堆对象(non-heap object)在定义它的地方被自动构造,在生存时间结束时自动被释放,所以只要禁止使用隐式的构造函数和析构函数,就可以实现这种限制。
(1)方法1:构造函数为public,析构函数为private,并未析构函数建立一个伪析构函数。缺点,析构私有会妨害继承
class UPNumber {
public:
UPNumber();
UPNumber(int initValue);
UPNumber(double initValue);
UPNumber(const UPNumber& rhs);
// 伪析构函数 (一个const 成员函数, 因为
// 即使是const对象也能被释放。)
void destroy() const { delete this; }
...
private:
~UPNumber();
};
(2)方法2:构造和析构函数均为private,并构建伪构造和析构函数。缺点,构造函数太多了,那么对应的伪构造函数也会要那么多,构造析构私有会妨害继承。
(3)方法3:构造函数为public,析构函数为protected。需要包含该类对象的其他类可以仅内含一个指针指向该类对象。
class UPNumber { ... }; // 声明析构函数为protected
class NonNegativeUPNumber:
public UPNumber { ... }; // 现在正确了; 派生类
// 能够访问
// protected 成员
class Asset {
public:
Asset(int initValue);
~Asset();
...
private:
UPNumber *value;
};
Asset::Asset(int initValue)
: value(new UPNumber(initValue)) // 正确
{ ... }
Asset::~Asset()
- 判断某个对象是否位于heap内:
(1)方法1:用一个flag标志静态变量记录是否operator new,如果执行就设置为true,反之false;每次构造完就在构造函数最后将flag重新赋值为默认值。
缺点:当new构造一个对象数组时,程序会执行operator new [ ]在堆上一次性分配所有所需内存,之后挨个挨个对象调用构造函数,这样一来就只有第一个对象显示在堆上构建。此外,new UPNumber(*new UPNumber)调用两次operator new 和两次构造函数,并不保证每次都是先new再构造,可能是先两次new,再两次构造,这样一来flag也没用了。
(2)方法2:通过结合堆和栈在内存中的物理地址判断是否对象在堆内。在很多系统上存在的事实,程序的地址空间被做为线性地址管理,程序的栈从地址空间的顶部向下扩展,堆则从底部向上扩展,但是有的系统并非如此,该方法不具有可移植性。此外,内存中不止有栈和堆区域,还有静态区域,可能无法区分heap和static对象
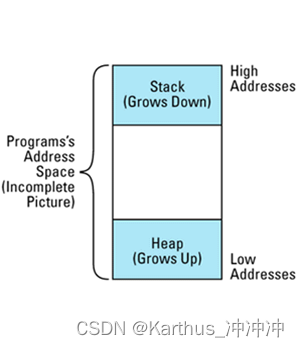
// 不正确的尝试,来判断一个地址是否在堆中
bool onHeap(const void *address)
{
char onTheStack; // 局部栈变量
return address < &onTheStack;
}
- 方法3:判断”指针删除动作是否安全“比”指针是否指向heap内对象“要更容易些,且绝大多数情况下后者的目的就是为了前者。通过记录所有由new分配内存的对象首地址来缺点delete是否安全。
void *operator new(size_t size)
{
void *p = getMemory(size); //调用一些函数来分配内存,
//处理内存不够的情况
把 p加入到一个被分配地址的集合;
return p;
}
void operator delete(void *ptr)
{
releaseMemory(ptr); // return memory to
// free store
从被分配地址的集合中移去ptr;
}
bool isSafeToDelete(const void *address)
{
返回address是否在被分配地址的集合中;
}
上述方法会干涉全局new和delete,此外不能自动适配其他类进行运用。可将该功能抽象为抽象基类,将抽象类的析构函数设为纯虚函数,让其他想要追踪对象是否位于堆内的类继承抽象基类,下列中用void * 替换其他对象指针,统一首地址表示形式,避免涉及”多重或虚拟基类“对象会拥有多个地址的问题:
class HeapTracked { // 混合类; 跟踪
public: // 从operator new返回的ptr
class MissingAddress{}; // 异常类,见下面代码
virtual ~HeapTracked() = 0;
static void *operator new(size_t size);
static void operator delete(void *ptr);
bool isOnHeap() const;
private:
typedef const void* RawAddress;
static list<RawAddress> addresses;
};
// mandatory definition of static class member
list<RawAddress> HeapTracked::addresses;
// HeapTracked的析构函数是纯虚函数,使得该类变为抽象类。
// (参见Effective C++条款14). 然而析构函数必须被定义,
//所以我们做了一个空定义。.
HeapTracked::~HeapTracked() {}
void * HeapTracked::operator new(size_t size)
{
void *memPtr = ::operator new(size); // 获得内存
addresses.push_front(memPtr); // 把地址放到list的前端
return memPtr;
}
void HeapTracked::operator delete(void *ptr)
{
//得到一个 "iterator",用来识别list元素包含的ptr;
//有关细节参见条款35
list<RawAddress>::iterator it =
find(addresses.begin(), addresses.end(), ptr);
if (it != addresses.end()) { // 如果发现一个元素
addresses.erase(it); //则删除该元素
::operator delete(ptr); // 释放内存
} else { // 否则
throw MissingAddress(); // ptr就不是用operator new
} // 分配的,所以抛出一个异常
}
bool HeapTracked::isOnHeap() const
{
// 得到一个指针,指向*this占据的内存空间的起始处,
// 有关细节参见下面的讨论
const void *rawAddress = dynamic_cast<const void*>(this);
// 在operator new返回的地址list中查到指针
list<RawAddress>::iterator it =
find(addresses.begin(), addresses.end(), rawAddress);
return it != addresses.end(); // 返回it是否被找到
}
class Asset: public HeapTracked {
private:
UPNumber value;
...
};
我们能够这样查询Assert*指针,如下所示:
void inventoryAsset(const Asset *ap)
{
if (ap->isOnHeap()) {
ap is a heap-based asset — inventory it as such;
}
else {
ap is a non-heap-based asset — record it that way;
}
}
- 禁止对象产生于heap之中:由于new operator总是调用operator new分配堆内存,因此可以在类定义中将operator new和operator new []声明为private。如果将该类作为基类A被其他类继承,private new也会影响继承效果。如果派生类不在自己内部声明public版本的new,则会继承基类A的private new。如果派生类在自己内部声明了operator new,此时需另寻他法阻止基类A成分生成(堆上)。此外,如果是一个类B内含基类A,则基类的private new将不起作用,而是由类B的operator new分配内存。总而言之,限制operator new只是限制了分配内存这一步骤,但可能失效。
//限制自己
class UPNumber {
private:
static void *operator new(size_t size);
static void operator delete(void *ptr);
...
};
现在用户仅仅可以做允许它们做的事情:
UPNumber n1; // okay
static UPNumber n2; // also okay
UPNumber *p = new UPNumber; // error! attempt to call
// private operator new
//限制类被继承
class UPNumber { ... }; // 同上
class NonNegativeUPNumber: //假设这个类
public UPNumber { //没有声明operator new
...
};
NonNegativeUPNumber n1; // 正确
static NonNegativeUPNumber n2; // 也正确
NonNegativeUPNumber *p = // 错误! 试图调用
new NonNegativeUPNumber; // private operator new
//限制类被包含
class UPNumber { ... }; // 同上
class NonNegativeUPNumber: //假设这个类
public UPNumber { //没有声明operator new
...
};
NonNegativeUPNumber n1; // 正确
static NonNegativeUPNumber n2; // 也正确
NonNegativeUPNumber *p = // 错误! 试图调用
new NonNegativeUPNumber; // private operator new
条款28:智能指针
设计一个智能指针。虽然无法设计出一个泛型智能指针可以完全替代普通指针,但是在某些场合下,它们的确很有用。
- 如果你的智能指针类不允许被复制或赋值,你应该将它们声明为private,否则public。两个解引操作符被声明为const,因为解引指针不应该会修改指向对象的内容。
class SmartPtr {
public:
SmartPtr(T* realPtr = 0); // 建立一个智能指针
// 指向dumb pointer所指的
// 对象。未初始化的指针
// 缺省值为0(null)
SmartPtr(const SmartPtr& rhs); // 拷贝一个智能指针
~SmartPtr(); // 释放智能指针
// make an assignment to a smart ptr
SmartPtr& operator=(const SmartPtr& rhs);
T* operator->() const; // dereference一个智能指针
// 以访问所指对象的成员
T& operator*() const; // dereference 灵巧指针
private:
T *pointee; // 智能指针所指的对象
};
- 智能指针构造和赋值:确定一个目标物,然后让智能指针内部的原始指针指向它。如果尚未确定目标物,则将内部指针设为0或抛出异常。智能指针所指对象应该是动态分配而得。需要注意的是,如果只是简单的赋值和拷贝内置指针给新的智能指针,那么有可能出现两个智能指针指向同一个对象,可能会被删除两次,发生严重错误。
C++标准库中智能指针采取当智能指针被赋值或复制时,其“对象拥有权”会转移。可以尝试结合条款29引用计数。
需注意两点,其一是拷贝构造传入的智能指针对象必须是引用,因为在拷贝构造函数中还需将被拷贝的智能指针不再指向任何东西;其二是赋值操作符在获得一个新对象的拥有权之前,必须删除它之前拥有的对象,否则发生内存泄漏:
template<class T>
class auto_ptr {
public:
...
auto_ptr(auto_ptr<T>& rhs); // 拷贝构造函数
auto_ptr<T>& // 赋值
operator=(auto_ptr<T>& rhs); // 操作符
...
};
template<class T>
auto_ptr<T>::auto_ptr(auto_ptr<T>& rhs)
{
pointee = rhs.pointee; // 把*pointee的所有权
// 传递到 *this
rhs.pointee = 0; // rhs不再拥有
} // 任何东西
template<class T>
auto_ptr<T>& auto_ptr<T>::operator=(auto_ptr<T>& rhs)
{
if (this == &rhs) // 如果这个对象自我赋值
return *this; // 什么也不要做
delete pointee; // 删除现在拥有的对象
pointee = rhs.pointee; // 把*pointee的所有权
rhs.pointee = 0; // 从 rhs 传递到 *this
return *this;
}
- 实现解引操作符:包括*和->操作符。*操作符容易实现,直接返回所指对象,而**->操作符需要注意,会存在返回值也必须要求能使用->的情况**。例如智能指针p,调用指向对象的成员函数,p->function(),会被解析为(pt.operator->())->function()。因此,可以返回普通指针。
template<class T>
T& SmartPtr<T>::operator*() const
{
perform "smart pointer" processing;
return *pointee;
}
template<class T>
T* SmartPtr<T>::operator->() const
{
perform "smart pointer" processing;
return pointee;
}
- 测试智能指针是否为null:一种是为指针指针加入一个isNull()函数;另一种做法则是提供隐式转换操作符,使得编译器可以将其转换为void*或者bool。
template<class T>
class SmartPtr {
public:
...
operator void*(); // 如果智能指针为null,
... // 返回0, 否则返回
}; // 非0。
SmartPtr<TreeNode> ptn;
...
if (ptn == 0) ... // 现在正确
if (ptn) ... // 也正确
if (!ptn) ... // 正确
这与iostream类中提供的类型转换相同,所以可以这样编写代码:
ifstream inputFile("datafile.dat");
if (inputFile) ... // 测试inputFile是否已经被
// 成功地打开。
但是:
SmartPtr<Apple> pa;
SmartPtr<Orange> po;
...
if (pa == po) ... // 这居然能够被成功编译!
template<class T>
class SmartPtr {
public:
...
bool operator!() const; // 当且仅当智能指针是
... // 空值,返回true。
};
用户程序如下所示:
SmartPtr<TreeNode> ptn;
...
if (!ptn) { // 正确
... // ptn 是空值
}
else {
... // ptn不是空值
}
但是这样就不正确了:
if (ptn == 0) ... // 仍然错误
if (ptn) ... // 也是错误的
仅在这种情况下会存在不同类型之间进行比较:
SmartPtr<Apple> pa;
SmartPtr<Orange> po;
...
if (!pa == !po) ... // 能够编译,但一般程序员不会写出这种代码
- **将智能指针转换为普通指针:**在有些情况下,必须使用普通指针,例如函数形参只接收普通指针。可以采用定义隐式转换操作符来进行,但是该方法会造成其他恶劣的影响,例如破坏智能指针引用计数、用户利用普通指针提前释放资源等等。因此,不到万不得已,不要提供普通指针隐式转换操作符。
class Tuple { ... }; // 同上
void normalize(Tuple *pt); // 把*pt 放入
template<class T> // 同上
class DBPtr {
public:
...
operator T*() { return pointee; }
...
};
DBPtr<Tuple> pt;
...
normalize(pt); // 能够运行
- 智能指针和“与继承有关的”类型转换:即使base class派生derive class,但智能指针p<base>和p<derive>是由智能指针模板实例化的两种毫无关系的类,因此无法自动转型。可以采用重载隐式转换操作符来进行派生类往基类的转换。为每个派生类手动撰写类型转换存在代码撰写量大,以及隐式转换无法执行一次以上用户自定义的类型转换函数问题。因此,可以采用成员模板来自动生成隐式转换函数。其执行步骤为:假设编译器有一个指向T对象的智能指针,它要把这个对象转换成指向“T的基类”的智能指针。编译器首先检查SmartPtr的类定义,看其有没有声明明确的类型转换符,但是它没有声明。编译器然后检查是否存在一个成员函数模板,并可以被实例化成它所期望的类型转换。它发现了一个这样的模板(带有形式类型参数newType),所以它把newType绑定成T的基类类型来实例化模板。这时,惟一的问题是实例化的成员函数代码能否被编译。此方法只适用于继承体系向上转型(派生类转到基类),事实上只要能隐式地把T1转换为T2时,你就能够隐式地把指向T1的智能指针类型转换为指向T2的智能指针类型。
template<class T> // 模板类,指向T的
class SmartPtr { // 智能指针
public:
SmartPtr(T* realPtr = 0);
T* operator->() const;
T& operator*() const;
template<class newType> // 模板成员函数
operator SmartPtr<newType>() // 为了实现隐式类型转换.
{
return SmartPtr<newType>(pointee);
}
...
};
不过在一个问题,C++对任何转换函数都认为一样的好,如果同时又两种类型转换可以调用时,就会存在冲突。
在这里插入代码片
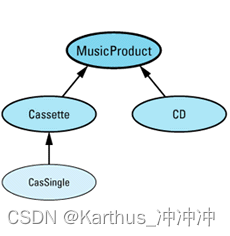
void displayAndPlay(const SmartPtr<MusicProduct>& pmp,
int howMany);
void displayAndPlay(const SmartPtr<Cassette>& pc,
int howMany);
SmartPtr<CasSingle> dumbMusic(new CasSingle("Achy Breaky Heart"));
displayAndPlay(dumbMusic, 1); // 错误!
- 智能指针与const:SmartPtr<CD> 与SmartPtr<const CD>是完全不同的类型。在编译器看来,它们是毫不相关的,所以没有理由相信它们是赋值兼容的。带const的类型转换是单向的:从non-const到const的转换是安全的,但是从const到non-const则不是安全的。而且用const指针能做的事情,用non-const指针也能做,但是用non-const指针还能做其它一些事情(例如,赋值操作)。可采用继承体系来解决,const智能指针为基类,非const智能指针为派生类。
SmartPtr<CD> p; // non-const 对象
// non-const 指针
SmartPtr<const CD> p; // const 对象,
// non-const 指针
const SmartPtr<CD> p = &goodCD; // non-const 对象
// const指针
const SmartPtr<const CD> p = &goodCD; // const 对象
// const 指针
template<class T> // 指向const对象的
class SmartPtrToConst { // 灵巧指针
... // 灵巧指针通常的
// 成员函数
protected:
union {
const T* constPointee; // 让 SmartPtrToConst 访问
T* pointee; // 让 SmartPtr 访问
};
};
template<class T> // 指向non-const对象
class SmartPtr: // 的灵巧指针
public SmartPtrToConst<T> {
... // 没有数据成员
};
SmartPtr<CD> pCD = new CD("Famous Movie Themes");
SmartPtrToConst<CD> pConstCD = pCD; // 正确
条款29:引用计数
该条款主要从资源共享、引用相同资源+1、放弃引用资源-1、写时复制、智能指针模板、抽象出计数基类等方法,实现引用计数。
- 设计一个引用计数基类:第一步是构建一个基类RCObject,任何需要引用计数的类都必须从它继承。RCObject封装了引用计数功能,如增加和减少引用计数的函数。它还包含了当这个值不再被需要时摧毁值对象的代码(也就是引用计数为0时)。最后,它包含了一个字段以跟踪这个值对象是否可共享,并提供查询这个值和将它设为false的函数。不需将可共享标志设为true的函数,因为所有的值对象默认都是可共享的。
class RCObject {
public:
RCObject();
RCObject(const RCObject& rhs);
RCObject& operator=(const RCObject& rhs);
virtual ~RCObject() = 0;
void addReference();
void removeReference();
void markUnshareable();
bool isShareable() const;
bool isShared() const;
private:
int refCount;
bool shareable;
};
RCObject::RCObject()
: refCount(0), shareable(true) {}
RCObject::RCObject(const RCObject&)
: refCount(0), shareable(true) {}
>RCObject& RCObject::operator=(const RCObject&)
{ return *this; }
RCObject::~RCObject() {} // virtual dtors must always
// be implemented, even if
// they are pure virtual
// and do nothing (see also
// Item M33 and Item E14)
void RCObject::addReference() { ++refCount; }
void RCObject::removeReference()
{ if (--refCount == 0) delete this; }
void RCObject::markUnshareable()
{ shareable = false; }
bool RCObject::isShareable() const
{ return shareable; }
bool RCObject::isShared() const
{ return refCount > 1; }
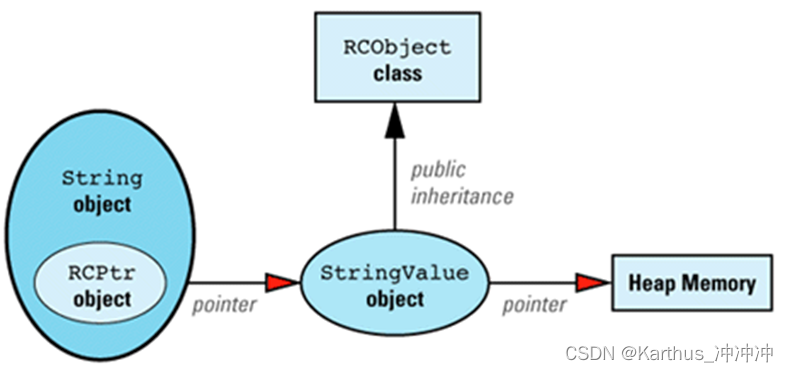
- 引用计数的String类:通过在String类中引入一个智能指针,该指针指向控制引用计数资源的StringValue对象,通过该指针对资源的操作行为,执行StringValue对象中基类继承得到的计数相关函数,分别进行引用增加减少、新资源初始化、写时复制、无引用时自动销毁等等。对于字符串来说,使用[ ]操作符会难以判断将要执行写操作还是读操作,因此一致让其重新创建副本。
template<class T> // template class for smart
class RCPtr { // pointers-to-T objects; T
public: // must inherit from RCObject
RCPtr(T* realPtr = 0);
RCPtr(const RCPtr& rhs);
~RCPtr();
RCPtr& operator=(const RCPtr& rhs);
T* operator->() const;
T& operator*() const;
private:
T *pointee;
void init();
};
class RCObject { // base class for reference-
public: // counted objects
void addReference();
void removeReference();
void markUnshareable();
bool isShareable() const;
bool isShared() const;
protected:
RCObject();
RCObject(const RCObject& rhs);
RCObject& operator=(const RCObject& rhs);
virtual ~RCObject() = 0;
private:
int refCount;
bool shareable;
};
class String { // class to be used by
public: // application developers
String(const char *value = "");
const char& operator[](int index) const;
char& operator[](int index);
private:
// class representing string values
struct StringValue: public RCObject {
char *data;
StringValue(const char *initValue);
StringValue(const StringValue& rhs);
void init(const char *initValue);
~StringValue();
};
RCPtr<StringValue> value;
};
RCObject::RCObject()
: refCount(0), shareable(true) {}
RCObject::RCObject(const RCObject&)
: refCount(0), shareable(true) {}
RCObject& RCObject::operator=(const RCObject&)
{ return *this; }
RCObject::~RCObject() {}
void RCObject::addReference() { ++refCount; }
void RCObject::removeReference()
{ if (--refCount == 0) delete this; }
void RCObject::markUnshareable()
{ shareable = false; }
bool RCObject::isShareable() const
{ return shareable; }
bool RCObject::isShared() const
{ return refCount > 1; }
这是RCPtr的实现:
template<class T>
void RCPtr<T>::init()
{
if (pointee == 0) return;
if (pointee->isShareable() == false) {
pointee = new T(*pointee);
}
pointee->addReference();
}
template<class T>
RCPtr<T>::RCPtr(T* realPtr)
: pointee(realPtr)
{ init(); }
template<class T>
RCPtr<T>::RCPtr(const RCPtr& rhs)
: pointee(rhs.pointee)
{ init(); }
template<class T>
RCPtr<T>::~RCPtr()
{ if (pointee)pointee->removeReference(); }
template<class T>
RCPtr<T>& RCPtr<T>::operator=(const RCPtr& rhs)
{
if (pointee != rhs.pointee) {
if (pointee) pointee->removeReference();
pointee = rhs.pointee;
init();
}
return *this;
}
template<class T>
T* RCPtr<T>::operator->() const { return pointee; }
template<class T>
T& RCPtr<T>::operator*() const { return *pointee; }
这是String::StringValue的实现:
void String::StringValue::init(const char *initValue)
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::StringValue(const char *initValue)
{ init(initValue); }
String::StringValue::StringValue(const StringValue& rhs)
{ init(rhs.data); }
String::StringValue::~StringValue()
{ delete [] data; }
最后,归结到String,它的实现是:
String::String(const char *initValue)
: value(new StringValue(initValue)) {}
const char& String::operator[](int index) const
{ return value->data[index]; }
char& String::operator[](int index)
{
if (value->isShared()) {
value = new StringValue(value->data);
}
value->markUnshareable();
return value->data[index];
}
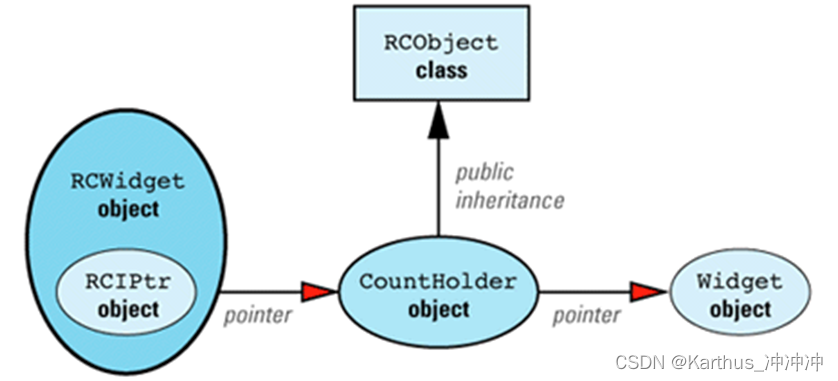
- 将引用计数加到已有的类上:如果有的类已经存在,且无法修改代码让其继承我们自定义的计数类,那就间接创建一个资源控制类,其中内含指向需要引用计数功能的类对象。
template<class T>
class RCIPtr {
public:
RCIPtr(T* realPtr = 0);
RCIPtr(const RCIPtr& rhs);
~RCIPtr();
RCIPtr& operator=(const RCIPtr& rhs);
const T* operator->() const; // see below for an
T* operator->(); // explanation of why
const T& operator*() const; // these functions are
T& operator*(); // declared this way
private:
struct CountHolder: public RCObject {
~CountHolder() { delete pointee; }
T *pointee;
};
CountHolder *counter;
void init();
void makeCopy(); // see below
};
template<class T>
void RCIPtr<T>::init()
{
if (counter->isShareable() == false) {
T *oldValue = counter->pointee;
counter = new CountHolder;
counter->pointee = new T(*oldValue);
}
counter->addReference();
}
template<class T>
RCIPtr<T>::RCIPtr(T* realPtr)
: counter(new CountHolder)
{
counter->pointee = realPtr;
init();
}
template<class T>
RCIPtr<T>::RCIPtr(const RCIPtr& rhs)
: counter(rhs.counter)
{ init(); }
template<class T>
RCIPtr<T>::~RCIPtr()
{ counter->removeReference(); }
template<class T>
RCIPtr<T>& RCIPtr<T>::operator=(const RCIPtr& rhs)
{
if (counter != rhs.counter) {
counter->removeReference();
counter = rhs.counter;
init();
}
return *this;
}
template<class T> // implement the copy
void RCIPtr<T>::makeCopy() // part of copy-on-
{ // write (COW)
if (counter->isShared()) {
T *oldValue = counter->pointee;
counter->removeReference();
counter = new CountHolder;
counter->pointee = new T(*oldValue);
counter->addReference();
}
}
template<class T> // const access;
const T* RCIPtr<T>::operator->() const // no COW needed
{ return counter->pointee; }
template<class T> // non-const
T* RCIPtr<T>::operator->() // access; COW
{ makeCopy(); return counter->pointee; } // needed
template<class T> // const access;
const T& RCIPtr<T>::operator*() const // no COW needed
{ return *(counter->pointee); }
template<class T> // non-const
T& RCIPtr<T>::operator*() // access; do the
{ makeCopy(); return *(counter->pointee); } // COW thing
class Widget {
public:
Widget(int size);
Widget(const Widget& rhs);
~Widget();
Widget& operator=(const Widget& rhs);
void doThis();
int showThat() const;
};
那么RCWidget将被定义为这样:
class RCWidget {
public:
RCWidget(int size): value(new Widget(size)) {}
void doThis() { value->doThis(); }
int showThat() const { return value->showThat(); }
private:
RCIPtr<Widget> value;
};
- 引用计数在“相对多数的对象共享相对少量的实值”以及“对象实值产生成本或销毁成本过高、或占用许多内存”才能发挥最好的作用。引用计数还存在一些问题,例如某些数据结构环环相依或自我相引用会导致这些数据结构一直存在,无法销毁。
条款30:Proxy classes(代理类)
用来代表或象征其他对象的对象,称为代理对象,其类则为代理类。- 用代理类实现二维数组:C++本质上只有一维数组,动态分配二维数组内存时也只能先分配所有元素所需的连续内存空间。可以先建立一维数组对象,然后二维数组对象以一维数组对象为单个元素,建立以一维数组为元素的一维数组,从而得到二维数组。由于二维数组索引需要用到[][],但是C++中并无[ ][ ]操作符,本质上是先解析第一个[ ],在解析第二个[ ],表达式data[3][6]实际上是(data[3])[6]。
template<class T>
class Array2D {
public:
class Array1D {
public:
T& operator[](int index);
const T& operator[](int index) const;
...
};
Array1D operator[](int index);
const Array1D operator[](int index) const;
...
};
//现在,它合法了:
Array2D<float> data(10, 20);
...
cout << data[3][6]; // fine
- 区分operaor [ ]的读写动作:下例利用CharProxy类来区分operator[ ]是左值运用(写)还是右值运用(读),结合缓式执行,只记录字符串和索引位置。
class String { // reference-counted strings;
public: // see Item 29 for details
class CharProxy { // proxies for string chars
public:
CharProxy(String& str, int index); // creation
CharProxy& operator=(const CharProxy& rhs); // 左值运用
CharProxy& operator=(char c); // 左值运用
operator char() const; // 右值运用
private:
String& theString; // string this proxy pertains to
int charIndex; // char within that string
// this proxy stands for
};
// continuation of String class
const CharProxy
operator[](int index) const; // for const Strings
CharProxy operator[](int index); // for non-const Strings
...
friend class CharProxy; //后续需要直接用到成员变量value,因此设为友元类
private:
RCPtr<StringValue> value;
};
String::CharProxy::CharProxy(String& str, int index)
: theString(str), charIndex(index) {}
String s1, s2;
cout << s1[5]; 该句编译器将CharProxy隐式转型为char,调用operator char() const,被作为右值使用
s2[5] = 'x'; 该句调用CharProxy& operator=(char c),返回一个引用,被作为左值使用
s1[3] = s2[8]; 该句调用CharProxy& operator=(const CharProxy& rhs),返回一个引用,S1[3]被作为左值使用
,而S2[8]被当作参数传递给const CharProxy& rhs,当作右值使用
每个函数只是返回被请求的字符的一个proxy对象,直到知道确切发生在proxy对象上的读或写动作才执行对应操作。const String等效于const CharProxy,而const CharProxy只有operator char() const可调用,因此对应const String也被当作右值只读,合理。
const String::CharProxy String::operator[](int index) const
{
return CharProxy(const_cast<String&>(*this), index); //为了迎合CharProxy的构造函数
}
String::CharProxy String::operator[](int index)
{
return CharProxy(*this, index);
}
将proxy转换为右值,直接返回字符副本即可。
String::CharProxy::operator char() const
{
return theString.value->data[charIndex];
}
将proxy转换为左值,如果目标目前拥有的资源可共享,那么就复制一份,作为变量,之后执行新的变量赋值操作。
String::CharProxy& String::CharProxy::operator=(const CharProxy& rhs)
{
// if the string is sharing a value with other String objects,
// break off a separate copy of the value for this string only
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
// now make the assignment: assign the value of the char
// represented by rhs to the char represented by *this
theString.value->data[charIndex] =
rhs.theString.value->data[rhs.charIndex];
return *this;
}
String::CharProxy& String::CharProxy::operator=(char c)
{
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
theString.value->data[charIndex] = c;
return *this;
}
- 代理类的局限性:
(1)代理类对象可能不仅在赋值操作上需要左值,可能在&,++,+=等等操作符上也需要左值,需要自己动手一一重载实现。
template<class T> // reference-counted array
class Array { // using proxies
public:
class Proxy {
public:
Proxy(Array<T>& array, int index);
Proxy& operator=(const T& rhs);
operator T() const;
...
};
const Proxy operator[](int index) const;
Proxy operator[](int index);
...
};
Array<int> intArray;
...
intArray[5] = 22; // fine
intArray[5] += 5; // error!
++intArray[5]; // error!
(2)不能通过代理对象调用真实对象成员函数。
(3)无法将代理对象传递给接收非const引用对象的函数。因为传递参数时,代理对象作为右值,返回的是一个临时对象,函数引用一个临时对象会失败。
void swap(char& a, char& b); // swaps the value of a and b
String s = "+C+"; // oops, should be "C++"
swap(s[0], s[1]); // this should fix the problem, but it won't compile
(4)隐式类型转换被限制。编译器只允许用户自定义转型函数在同一时刻使用1次。例如int可以一次隐式转型到某个类对象,但是代理int需要先转型到int,再从int到所需类对象,编译器不允许。
条款31:让函数根据一个以上的对象类型来决定如何虚化
该条款主要实现了如何让函数根据两个具有相同基类的派生类对象(可能是不同派生类)做出不同的行为反应,类似实现由两个对象决定的多态行为。例如,如何让同一个函数collision(),在接收(SpaceShipe对象,SpaceStation对象)时与接收(SpaceShipe对象,Asteroid对象)行为不同。
- 方法1:用虚函数+条件判断语句+运行期类型识别(RTTI)来处理。其原理是传入两个对象,首先用虚函数自动调用对应类型的虚函数,利用虚函数机制自动识别出第一个对象类型,之后将第二对象作为参数传入虚函数,通过函数typeid()判断第二个对象的类型,然后决定调用哪一个对应函数。优点是简单易懂,缺点是不易扩展,如果添加新的派生类则需要修改类定义的代码。
class GameObject {
public:
virtual void collide(GameObject& otherObject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);
...
};
// if we collide with an object of unknown type, we
// throw an exception of this type:
class CollisionWithUnknownObject {
public:
CollisionWithUnknownObject(GameObject& whatWeHit);
...
};
void SpaceShip::collide(GameObject& otherObject)
{
const type_info& objectType = typeid(otherObject);
if (objectType == typeid(SpaceShip)) {
SpaceShip& ss = static_cast<SpaceShip&>(otherObject);
process a SpaceShip-SpaceShip collision;
}
else if (objectType == typeid(SpaceStation)) {
SpaceStation& ss =
static_cast<SpaceStation&>(otherObject);
process a SpaceShip-SpaceStation collision;
}
else if (objectType == typeid(Asteroid)) {
Asteroid& a = static_cast<Asteroid&>(otherObject);
process a SpaceShip-Asteroid collision;
}
else {
throw CollisionWithUnknownObject(otherObject);
}
}
- 方法2:仅用虚函数实现。其原理是将两个对象各先后进行一次虚函数调用,利用虚函数机制自动识别两个对象类型所需调用的函数,也可以作是虚函数+虚函数+重载。优点是简单易懂,缺点是不易扩展,如果添加新的派生类则需要修改类定义的代码。
class SpaceShip; // forward declarations
class SpaceStation;
class Asteroid;
class GameObject {
public:
virtual void collide(GameObject& otherObject) = 0;
virtual void collide(SpaceShip& otherObject) = 0;
virtual void collide(SpaceStation& otherObject) = 0;
virtual void collide(Asteroid& otherobject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);//重点!!!!!!!!!!!!!!!!!!!!
virtual void collide(SpaceShip& otherObject);
virtual void collide(SpaceStation& otherObject);
virtual void collide(Asteroid& otherobject);
...
};
//重点!!!!!!!!!!!!!!!!!!!!
//首先调用collide函数,自动确定*this类型,之后用第二个collide函数,确定*otherObject
void SpaceShip::collide(GameObject& otherObject)
{
otherObject.collide(*this);
}
//重点!!!!!!!!!!!!!!!!!!!!
- 方法3:自行仿真虚函数表格。其原理是模仿虚函数表格,构造一个关系数组(两个对象的类型+对应函数的函数指针),通过运行期类型识别,识别出两个对象类型,从关系数组中取出对应的函数指针。为了实现可扩展性,将关系数组和各处理函数移出类定义,至全局匿名空间。后续需要扩展新的派生类类型,可以在namespace匿名空间中加入即可。
class GameObject { // this is unchanged
public:
virtual void collide(GameObject& otherObject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);//调用lookup函数,执行找到的函数指针
// these functions now all take a GameObject parameter
//virtual void hitSpaceShip(GameObject& spaceShip);//后面将这些具现的函数移出类定义了
//virtual void hitSpaceStation(GameObject& spaceStation);
//virtual void hitAsteroid(GameObject& asteroid);
...
};
#include "SpaceShip.h"
#include "SpaceStation.h"
#include "Asteroid.h"
namespace { // unnamed namespace — see below
// primary collision-processing functions
void shipAsteroid(GameObject& spaceShip,
GameObject& asteroid);
void shipStation(GameObject& spaceShip,
GameObject& spaceStation);
void asteroidStation(GameObject& asteroid,
GameObject& spaceStation);
...
// secondary collision-processing functions that just
// implement symmetry: swap the parameters and call a
// primary function
void asteroidShip(GameObject& asteroid,
GameObject& spaceShip)
{ shipAsteroid(spaceShip, asteroid); }
void stationShip(GameObject& spaceStation,
GameObject& spaceShip)
{ shipStation(spaceShip, spaceStation); }
void stationAsteroid(GameObject& spaceStation,
GameObject& asteroid)
{ asteroidStation(asteroid, spaceStation); }
...
// see below for a description of these types/functions
typedef void (*HitFunctionPtr)(GameObject&, GameObject&);
typedef map< pair<string,string>, HitFunctionPtr > HitMap;//关系型数组,模仿虚函数表
pair<string,string> makeStringPair(const char *s1,
const char *s2);
HitMap * initializeCollisionMap();
HitFunctionPtr lookup(const string& class1,
const string& class2);
} // end namespace
void processCollision(GameObject& object1,
GameObject& object2)
{
HitFunctionPtr phf = lookup(typeid(object1).name(),
typeid(object2).name());
if (phf) phf(object1, object2);
else throw UnknownCollision(object1, object2);
}
// we use this function to create pair<string,string>
// objects from two char* literals. It's used in
// initializeCollisionMap below. Note how this function
// enables the return value optimization (see Item 20).
namespace { // unnamed namespace again — see below
pair<string,string> makeStringPair(const char *s1,
const char *s2)
{ return pair<string,string>(s1, s2); }
} // end namespace
namespace { // still the unnamed namespace — see below
HitMap * initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)[makeStringPair("SpaceShip","Asteroid")] =
&shipAsteroid;
(*phm)[makeStringPair("SpaceShip", "SpaceStation")] =
&shipStation;
...
return phm;
}
} // end namespace
//lookup函数也必须被修改以处理pair<string,string>对象,并将它作为映射表的第一部分:
namespace { // I explain this below — trust me
HitFunctionPtr lookup(const string& class1,
const string& class2)
{
static auto_ptr<HitMap>
collisionMap(initializeCollisionMap());//初始化已有类型的关系数组
// see below for a description of make_pair
HitMap::iterator mapEntry=
collisionMap->find(make_pair(class1, class2));
if (mapEntry == collisionMap->end()) return 0;
return (*mapEntry).second;
}
} // end namespace
方法3补充:实现模拟的虚函数表格灵活增删,其原理是利用一个map函数来存储处理函数,放进一个新类A,该类提供一些成员函数用于修改map中保存的处理函数。此外,新建一个没有数据成员的间接类B,其构造函数用于调用类A中在map中新增处理函数的静态成员函数,添加新的派生类型时可以在全局构造该间接类,保证在运用不同类型处理函数之前已经在map中加入了对应的处理函数。
class CollisionMap {
public:
typedef void (*HitFunctionPtr)(GameObject&, GameObject&);
void addEntry(const string& type1,
const string& type2,
HitFunctionPtr collisionFunction,
bool symmetric = true); // see below
void removeEntry(const string& type1,
const string& type2);
HitFunctionPtr lookup(const string& type1,
const string& type2);
// this function returns a reference to the one and only
// map — see Item 26
static CollisionMap& theCollisionMap();//用静态成员限制仅有一个map存在
private:
// these functions are private to prevent the creation
// of multiple maps — see Item 26
CollisionMap();
CollisionMap(const CollisionMap&);
};
class RegisterCollisionFunction {
public:
RegisterCollisionFunction(
const string& type1,
const string& type2,
CollisionMap::HitFunctionPtr collisionFunction,
bool symmetric = true)
{
CollisionMap::theCollisionMap().addEntry(type1, type2,
collisionFunction,
symmetric);
}
};
//用户于是可以使用此类型的一个全局对象来自动地注册他们所需要的函数:
RegisterCollisionFunction cf1("SpaceShip", "Asteroid",
&shipAsteroid);
RegisterCollisionFunction cf2("SpaceShip", "SpaceStation",
&shipStation);
RegisterCollisionFunction cf3("Asteroid", "SpaceStation",
&asteroidStation);
...
int main(int argc, char * argv[])
{
...
}
//如果以后增加了一个派生类
class Satellite: public GameObject { ... };
//以及一个或多个碰撞处理函数
void satelliteShip(GameObject& satellite,
GameObject& spaceShip);
void satelliteAsteroid(GameObject& satellite,
GameObject& asteroid);
//这些新函数可以用同样方法加入映射表而不需要修改现存代码:
RegisterCollisionFunction cf4("Satellite", "SpaceShip",
&satelliteShip);
RegisterCollisionFunction cf5("Satellite", "Asteroid",
&satelliteAsteroid);
- 需要注意的是,当存在多继承时(假设C同时继承于A和B),派生类对象C取地址后赋值给不同的基类指针(A指针或B指针)时,指针的值可能不一样。因为对象C所占内存中由A和B的对象,然而A和B的首地址肯定由先后顺序。若构造顺序时先A,再B,最后C自己的部分,那么构造A对象的首地址和构造B对象的首地址肯定不一样,但是构造A对象的首地址和构造C对象(A+B+C独有的部分,首地址就是从A开始)的首地址是一样的。所以在多继承中使用继承体系转型时需注意。




![XFF漏洞利用([SWPUCTF 2021 新赛]Do_you_know_http)](https://img-blog.csdnimg.cn/1fb8bbb57edb4193b4f2e51f6bf3de56.png)