文章目录
- 参考
- 机器学习简介
- 策略简介
- SVM简介
- 整体流程
- 收集数据
- 准备数据
- 建立模型
- 训练模型
- 测试模型
- 调节参数
参考
Python机器学习算法与量化交易
利用机器学习模型,构建量化择时策略
机器学习简介
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。
机器学习的常见算法包括:决策树、朴素贝叶斯、支持向量机、随机森林、人工神经网络、深度学习等。
策略简介
输入沪深300的行情数据到支持向量机中进行模型训练,预测沪深指数第二天的涨跌。
Why SVM?
因为数据集为沪深300的日线行情数据,总共只有几千个交易日(样本点),而SVM的小样本预测准确率较高,并且能够解决非线性分类问题,所以比较适合。
SVM简介
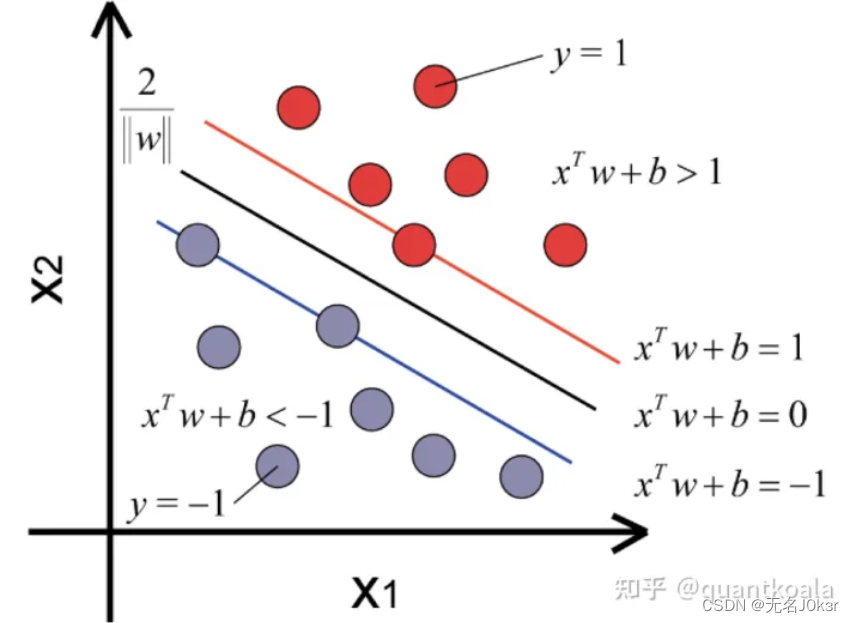
SVM最初的设计用来解决二分类问题(比如沪深指数的涨和跌),通过寻找一个最大间隔超平面(图中黑色斜线)将两类样本线性区分开,并保证两侧样本的最近边缘点到这个平面的距离最大,由于最大间隔超平面仅取决于两个类别的边缘点,例如上图中被红线和蓝线穿过的红点和蓝点,这些点就被称为支持向量。
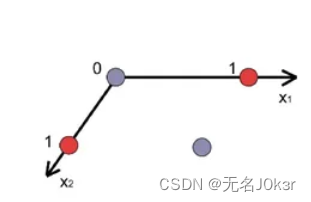
 数据集并非总是线性可分的,如下图。
数据集并非总是线性可分的,如下图。
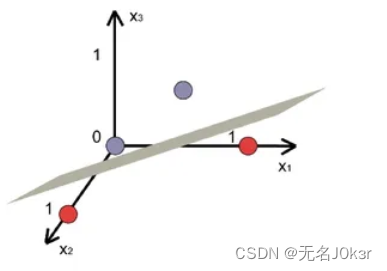
 对数据非线性可分的情况,SVM引入了核函数,将低维不可分的数据映射到线性可分的高维,如下。
对数据非线性可分的情况,SVM引入了核函数,将低维不可分的数据映射到线性可分的高维,如下。
常用的核函数有
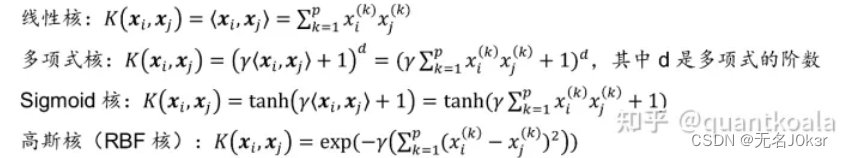 但在现实当中,由于噪声和极端样本点的存在,数据集无论在低维还是高维都可能出现线性不可分的情况,于是乎,SVM当中引入了松弛变量的概念,允许了最大间隔超平面不用完美区分两个类别,允许错误分类的存在,SVM通过惩罚系数C控制这些错误分类的容忍程度,C值越高分类准确率越高,但数值过高容易导致过拟合,C值过低则会导致准确率受损。
但在现实当中,由于噪声和极端样本点的存在,数据集无论在低维还是高维都可能出现线性不可分的情况,于是乎,SVM当中引入了松弛变量的概念,允许了最大间隔超平面不用完美区分两个类别,允许错误分类的存在,SVM通过惩罚系数C控制这些错误分类的容忍程度,C值越高分类准确率越高,但数值过高容易导致过拟合,C值过低则会导致准确率受损。