编码是信息从一种形式或格式转换为另一种形式的过程,也称为计算机编程语言的代码,简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。编码在电子计算机、电视、遥控和通讯等方面广泛使用。编码是信息从一种形式或格式转换为另一种形式的过程。解码,是编码的逆过程。—
—百度百科
计算机的底层只能存储0和1,如果是日常生活中遇到的数字,比如 127,这个可以通过10进制和二进制的转换从而让计算机存储01111111,但是如果计算机存储类似于汉字、英文字符、符号等内容,是如何存储的呢?

目前的文字编码标准主要有 ASCII、GB2312、GBK、Unicode等。ASCII 编码是最简单的西文编码方案。GB2312、GBK、GB18030 是汉字字符编码方案的国家标准。ISO/IEC 10646 和 Unicode 都是全球字符编码的国际标准。
ASCII
ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符 。
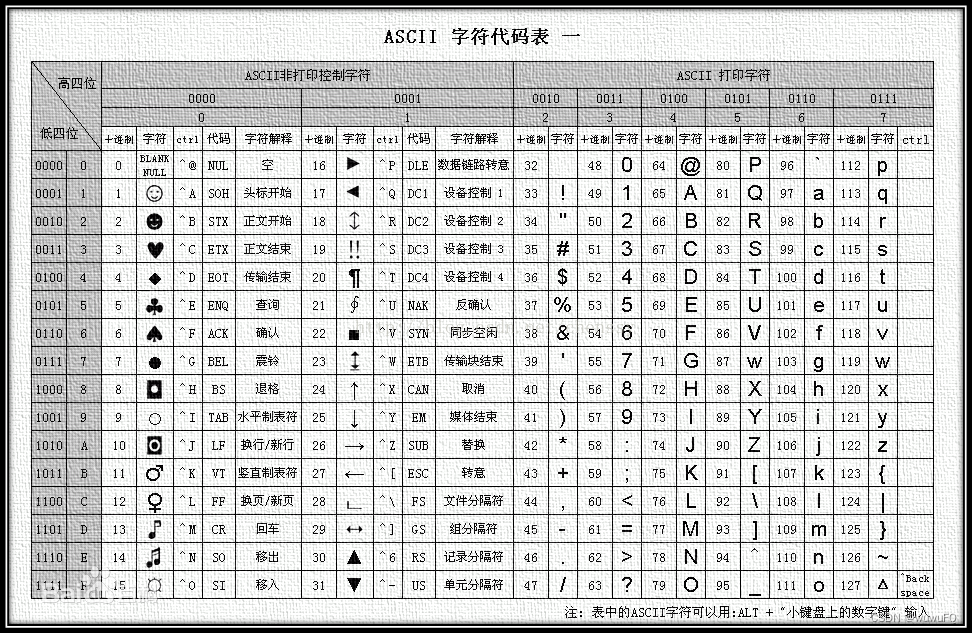
ASCII码对美国是够用了,但对别的国家而言却是不够的,于是,各个国家的各种计算机厂商就发明了各种各样的编码方式以表示自己国家的字符,为了保持与ASCII码的兼容性,一般都是最高位设置为1.也就是说,当最高位为0时,表示ASCII码,当为1时就是各个国家自己的字符。在这些扩展的编码中,在西欧国家中流行的是ISO 8859-1和Windows-1252,在中国是GB2312,GBK和Big5。
ISO-8859-1
ISO 8859-1又称Latin-1,它也是使用一个字节表示一个字符,因为西欧的文字也都是字母拼接,只不过不是26个英文字母罢了,其中0到127与ASCII一样,128到255规定了不同的含义。在128到255中,128到159表示一些控制字符,160到255表示一些西欧字符。
GB2312
美国和西欧字符用一个字节就够了,但中文显然是不够的,中文第一个标准是GB2312。GB2312标准主要针对的是简体中文常见字符,包括约7000个汉字,不包括一些罕见词,不包括繁体字,GB2312固定使用两个字节表示汉字,在这两个字节中,最高位都是1,如果是0,就认为是ASCII字符。在这两个字节中,其中第一个字节范围是1010 0001(十进制161)-1111 0111(十进制247),第二个字节范围是1010 0001(十进制161)-1111 1110(十进制254)。
GBK
GBK建立在GB2312的基础上,向下兼容GB2312,也就是说,GB2312编码的字符的二进制表示,在GBK编码里是完全一样的。GBK增加了一万四千多个汉字,共计约21000汉字,其中包括繁体字,GBK同样使用固定的两个字节表示,其中第一个字节范围是1000 0001(十进制129) - 1111 1110(十进制254),第二个字节范围是0100 0000(十进制64) - 0111 1110(十进制126)和1000 0000(十进制128) - 1111 1110(十进制254)。
GB18030
GB18030向下兼容GBK,增加了五万五千多个字符,共七万六千多个字符,包括了很多少数民族字符,以及中日韩统一字符。用两个字节已经表示不了GB18030中的所有字符,GB18030使用变长编码,有的字符是两个字节,有的是四个字节,在两个字节编码中,字节表示范围与GBK一样。在四个字节编码中,第一个字节的值从1000 0001(十进制129)到1111 1110(十进制254),第二个字节的值从0011 0000(十进制48) 到0011 1001(十进制57),第三个字节的值从1000 0001(十进制129)到1111 1110(十进制254),第四个字节的值从0011 0000(十进制48)到0011 1001(十进制57)。
Big5
Big5是针对繁体中文的,广泛用于台湾香港等地。Big5包括1万3千多个繁体字,和GB2312类似,一个字符同样固定使用两个字节表示。在这两个字节中,第一个字节范围是1000 0001(十进制129)到1111 1110(十进制254),第二个字节范围是0100 0000(十进制64) - 0111 1110(十进制126)和1010 0001(十进制161) - 1111 1110(十进制254)。Big5和GB18030,GBK,GB2312不兼容。
Unicode
统一码(Unicode),也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
国际标准化组织ISO,将全球所有的语言所使用的字母、符号、文字进行统一编号,每个字符指定唯一一个标号与之对应(ASCII码编号不变),字符的编号从0x000000~0x10FFFF,该编号集称为Universal Multiple-Octet coded Character Set,简称UCS,一般也叫做Unicode。Unicode字符集仅仅是对所有字符进行了编号,并没有指定这些编号的编码规则,所以,后来才出现了各种Unicode的编码规则Unicode Transformation Format,典型的Unicode编码规则如UTF-8,UTF-16,UTF-32等。
UTF-32
Unicode Transformation Format 32,用32位(4字节)对Unicode字符集进行编码。编码时,Unicode字符集中的每一个字符都用4字节表示,直接把字符对应的Unicode编号转换为二进制数进行存储。而正因为UTF-32用4字节为每个字符编码,所以,UTF-32不兼容ASCII编码,使用ASCII编码标准写的程序,通过UTF-32编码方式打开会显示乱码。
UTF-16
Unicode Transformation Format 16,用16位(2字节)或32位(4字节)对Unicode字符集进行编码。对Unicode字符编号在065535的字符使用2字节编码,将每个字符的编号直接转换为2字节的二进制数0x00000xFFFF。而Unicode字符集在0xD800~0xDBFF区间内的编号不表示任何字符,UTF-16用这段编号与Unicode字符集中大于0xFFFF的字符编号进行映射,得到扩展的4字节编码。UTF-16也不兼容ASCII编码。
UTF-8
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。(UTF-8编码的时候,汉字一般是占三个字节的)
Base64
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。
Base64编码表
|
索引
|
对应字符
|
索引
|
对应字符
|
索引
|
对应字符
|
索引
|
对应字符
|
|
0
|
A
|
17
|
R
|
34
|
i
|
51
|
z
|
|
1
|
B
|
18
|
S
|
35
|
j
|
52
|
0
|
|
2
|
C
|
19
|
T
|
36
|
k
|
53
|
1
|
|
3
|
D
|
20
|
U
|
37
|
l
|
54
|
2
|
|
4
|
E
|
21
|
V
|
38
|
m
|
55
|
3
|
|
5
|
F
|
22
|
W
|
39
|
n
|
56
|
4
|
|
6
|
G
|
23
|
X
|
40
|
o
|
57
|
5
|
|
7
|
H
|
24
|
Y
|
41
|
p
|
58
|
6
|
|
8
|
I
|
25
|
Z
|
42
|
q
|
59
|
7
|
|
9
|
J
|
26
|
a
|
43
|
r
|
60
|
8
|
|
10
|
K
|
27
|
b
|
44
|
s
|
61
|
9
|
|
11
|
L
|
28
|
c
|
45
|
t
|
62
|
+
|
|
12
|
M
|
29
|
d
|
46
|
u
|
63
|
/
|
|
13
|
N
|
30
|
e
|
47
|
v
| ||
|
14
|
O
|
31
|
f
|
48
|
w
| ||
|
15
|
P
|
32
|
g
|
49
|
x
| ||
|
16
|
Q
|
33
|
h
|
50
|
y
|
URL编码
url编码是一种浏览器用来打包表单输入的格式。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。
URL编码规则
URL编码遵循下列规则: 每对name/value由&;符分开;每对来自表单的name/value由=符分开。如果用户没有输入值给这个name,那么这个name还是出现,只是无值。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c。
URL编码表
|
backspace %08
|
I %49
|
v %76
|
ó %D3
|
|
tab %09
|
J %4A
|
w %77
|
Ô %D4
|
|
linefeed %0A
|
K %4B
|
x %78
|
Õ %D5
|
|
creturn %0D
|
L %4C
|
y %79
|
Ö %D6
|
|
space %20
|
M %4D
|
z %7A
|
Ø %D8
|
|
! %21
|
N %4E
|
{ %7B
|
ù %D9
|
|
" %22
|
O %4F
|
| %7C
|
ú %DA
|
|
# %23
|
P %50
|
} %7D
|
Û %DB
|
|
$ %24
|
Q %51
|
~ %7E
|
ü %DC
|
|
% %25
|
R %52
|
¢ %A2
|
Y %DD
|
|
& %26
|
S %53
|
£ %A3
|
T %DE
|
|
' %27
|
T %54
|
¥ %A5
|
ß %DF
|
|
( %28
|
U %55
|
| %A6
|
à %E0
|
|
) %29
|
V %56
|
§ %A7
|
á %E1
|
|
* %2A
|
W %57
|
« %AB
|
a %E2
|
|
+ %2B
|
X %58
|
¬ %AC
|
ã %E3
|
|
, %2C
|
Y %59
|
ˉ %AD
|
ä %E4
|
|
- %2D
|
Z %5A
|
o %B0
|
å %E5
|
|
. %2E
|
[ %5B
|
± %B1
|
æ %E6
|
|
/ %2F
|
\ %5C
|
a %B2
|
ç %E7
|
|
0 %30
|
] %5D
|
, %B4
|
è %E8
|
|
1 %31
|
^ %5E
|
μ %B5
|
é %E9
|
|
2 %32
|
_ %5F
|
» %BB
|
ê %EA
|
|
3 %33
|
` %60
|
¼ %BC
|
ë %EB
|
|
4 %34
|
a %61
|
½ %BD
|
ì %EC
|
|
5 %35
|
b %62
|
¿ %BF
|
í %ED
|
|
6 %36
|
c %63
|
à %C0
|
î %EE
|
|
7 %37
|
d %64
|
á %C1
|
ï %EF
|
|
8 %38
|
e %65
|
 %C2
|
e %F0
|
|
9 %39
|
f %66
|
à %C3
|
ñ %F1
|
|
: %3A
|
g %67
|
Ä %C4
|
ò %F2
|
|
; %3B
|
h %68
|
Å %C5
|
ó %F3
|
|
< %3C
|
i %69
|
Æ %C6
|
ô %F4
|
|
= %3D
|
j %6A
|
Ç %C7
|
õ %F5
|
|
> %3E
|
k %6B
|
è %C8
|
ö %F6
|
|
%3F
|
l %6C
|
é %C9
|
÷ %F7
|
|
@ %40
|
m %6D
|
ê %CA
|
ø %F8
|
|
A %41
|
n %6E
|
Ë %CB
|
ù %F9
|
|
B %42
|
o %6F
|
ì %CC
|
ú %FA
|
|
C %43
|
p %70
|
í %CD
|
û %FB
|
|
D %44
|
q %71
|
Î %CE
|
ü %FC
|
|
E %45
|
r %72
|
Ï %CF
|
y %FD
|
|
F %46
|
s %73
|
D %D0
|
t %FE
|
|
G %47
|
t %74
|
Ñ %D1
|
ÿ %FF
|
|
H %48
|
u %75
|
ò %D2
|