通常数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖

如何来描述语言的特征呢,通常都在词的层面上构建特征,Word2Vec就是要把词转换成向量

假设现在已经拿到一份训练好的词向量,其中每一个词都表示为50维的向量
如果在热度图中显示,结果如下

在结果中可以发现,相似的词在特征表达中比较相似,也就是说词的特征是有意义的!

在词向量模型中,输入和输出分别是什么?

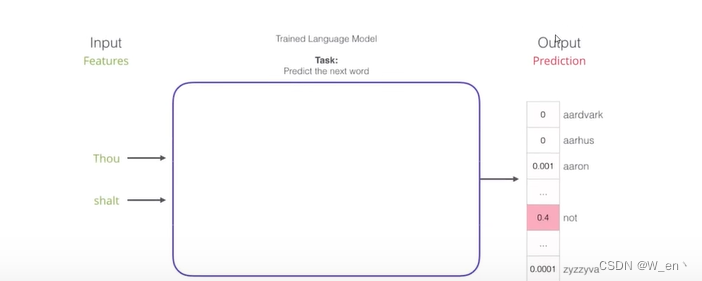
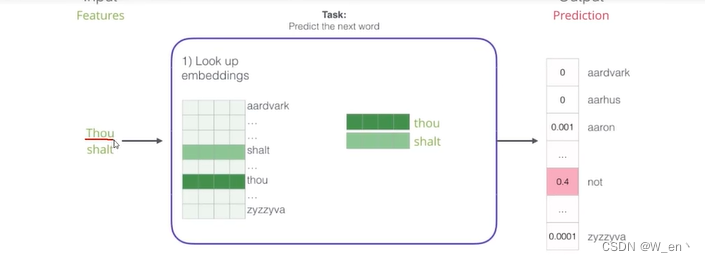
数据从哪来?
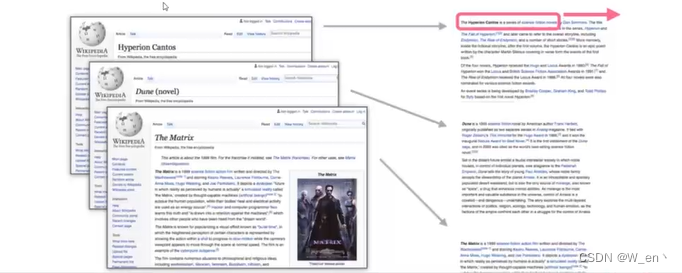
构建训练数据
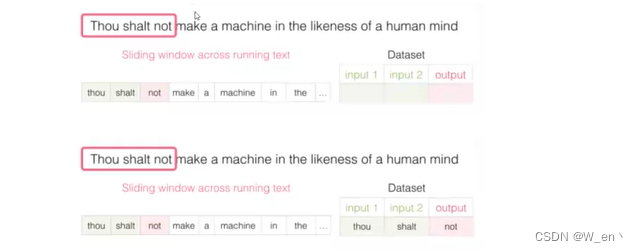
不同模型对比



CBOW模型
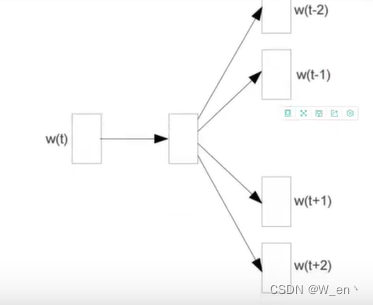
Skip-gram模型
Skip-gram模型所需训练数据集


如何进行训练?

如果一个语料库稍微大一些,可能的结果简直太多了,最后一层相当于softmax,计算起来十分耗时,有什么别的方法吗?
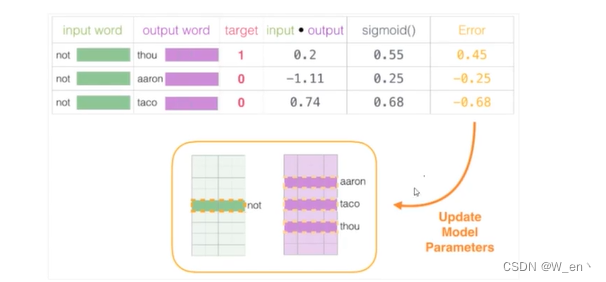
初始方案:输入两个单词,看他们是不是前后对应的输入输出,也就相当于一个二分类任务

出发点非常好,但是此时训练集构建出来的标签全为1,无法进行较好的训练

改进方案。加入一些负样本(负采样模型)


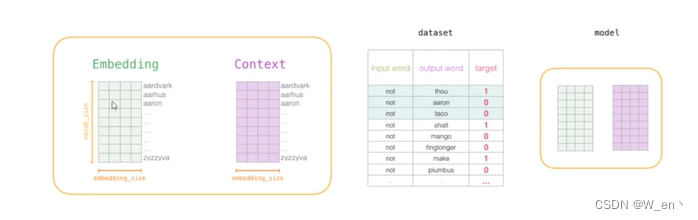
词向量训练过程
初始化词向量矩阵
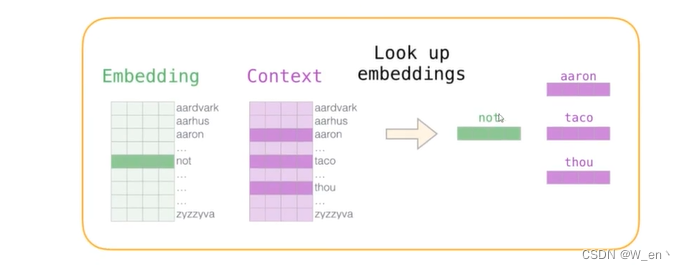
通过神经网络反向传播来计算更新,此时不光更新权重参数,还更新输入数据