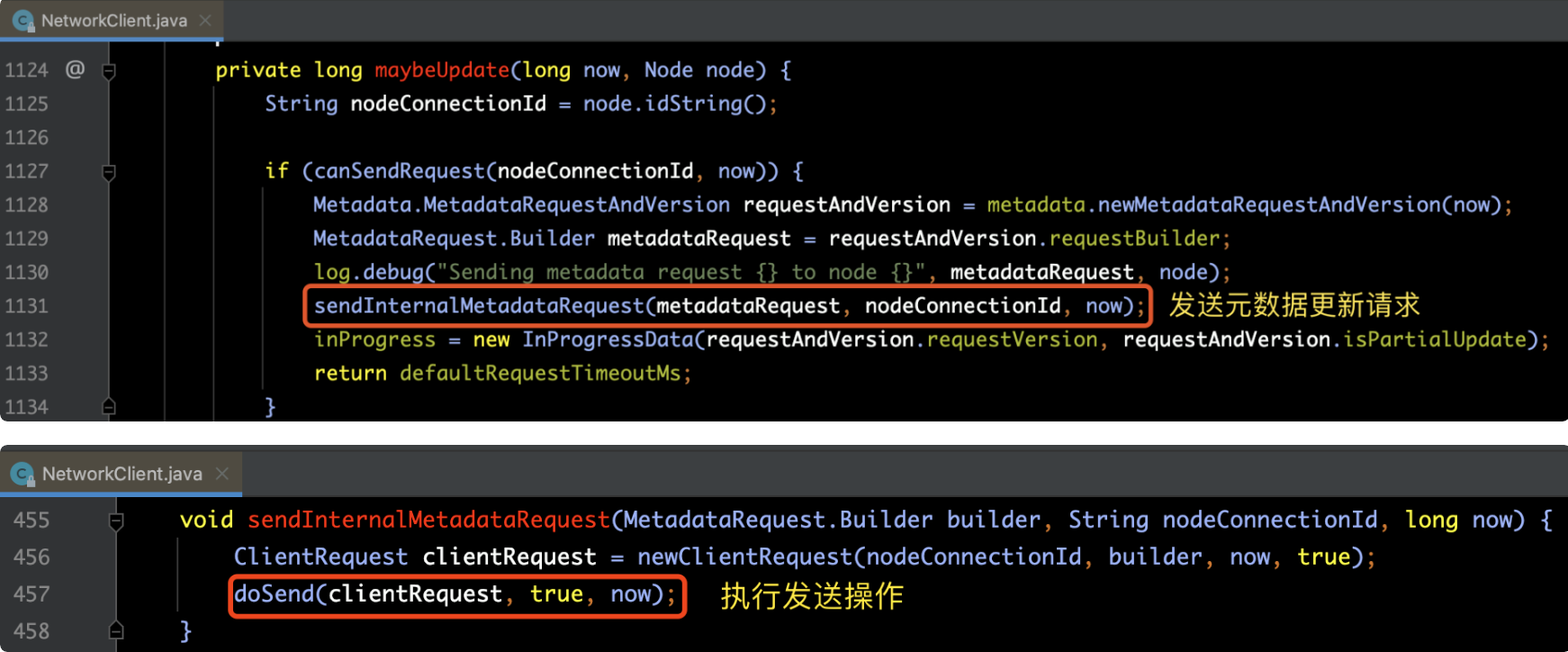
执行流程
注:请先阅读作者的README.md文档https://gitee.com/yu_xiao_qi/pytest-auto-api2/blob/master/README.md
本节内容目录如下:
文章目录
- 执行流程
- 目录结构
- 参数配置
- 入口文件-run.py
- pytest.ini
- test_case初始化数据缓存
- 解析yaml测试数据
- 测试用例执行
- conftest.py
- 用例demo分析
- 加载yaml中的数据
- **1、case_id = ['get_user_info_01']**
- **2、TestData = GetTestCase.case_data(case_id)**
- **3、re_data = regular(str(TestData))**
- 数据驱动执行用例
- 用例前置
- request请求配置
- 多业务逻辑代码分析
- **片段1**
- **片段2**
- 数据依赖
- 后置操作(数据清洗)
- 断言操作
- 与作者的问答
- 结束
目录结构
├── common // 配置
│ ├── conf.yaml // 公共配置
│ ├── setting.py // 环境路径存放区域
├── data // 测试用例数据
├── File // 上传文件接口所需的文件存放区域
├── logs // 日志层
├── report // 测试报告层
├── test_case // 测试用例代码
├── utils // 工具类
│ └── assertion
│ └── assert_control.py // 断言
│ └── assert_type.py // 断言类型
│ └── cache_process // 缓存处理模块
│ └── cacheControl.py
│ └── redisControl.py
│ └── logging_tool // 日志处理模块
│ └── log_control.py
│ └── log_decorator.py // 日志装饰器
│ └── run_time_decorator.py // 统计用例执行时长装饰器
│ └── mysql_tool // 数据库模块
│ └── mysql_control.py
│ └── notify // 通知模块
│ └── ding_talk.py // 钉钉通知
│ └── lark.py // 飞书通知
│ └── send_mail.py // 邮箱通知
│ └── wechat_send.py // 企业微信通知
│ └── other_tools // 其他工具类
│ └── allure_data // allure封装
│ └── allure_report_data.py // allure报告数据清洗
│ └── allure_tools.py // allure 方法封装
│ └── error_case_excel.py // 收集allure异常用例,生成excel测试报告
│ └── install_tool
│ └── install_requirements.py
│ └── version_library_comparisons.txt
│ └── get_local_ip.py // 获取本地IP
| └── address_detection.py
| └── exceptions.py
| └── jsonpath_date_replace.py
| └── models.py
| └── thread_tool.py
│ └── read_files_tools // 文件操作
│ └── case_automatic_control.py // 自动生成测试代码
│ └── clean_files.py // 清理文件
│ └── excel_control.py // 读写excel
│ └── get_all_files_path.py // 获取所有文件路径
│ └── get_yaml_data_analysis.py // yaml用例数据清洗
│ └── regular_control.py // 正则
│ └── swagger_for_yaml.py
│ └── yaml_control.py
│ └── testcase_template.py // yaml文件读写
│ └── recording // 代理录制
│ └── mitmproxy_control.py
│ └── requests_tool
│ └── dependentCase.py // 数据依赖处理
│ └── encryption_algorithm_control.py
│ └── request_control.py // 请求封装
│ └── set_current_request_cache.py
│ └── teardown_control.py
│ └── times_tool
│ └── time_control.py
├── Readme.md // help
├── pytest.ini
├── run.py // 运行入口
参数配置

入口文件-run.py
1、通过pytest收集相关用例
2、通过allure_data收集测试数据
3、将数据发送到对应的钉钉、飞书、微信、邮件
4、如果程序报错则抛出异常,并发送异常邮件
pytest.ini
指定pytest收集用例和执行用例的规则
test_case初始化数据缓存
在test_case文件夹下的__init__.py文件中,进行了case解析,将yaml文件解析到缓存文件中。
此段代码由于放在__init__.py文件中,所以当pytest收集用例并执行的第一时间,会先执行该文件,也就是先把所有的用例文件内容参数加载到缓存中,关于缓存知识点可以参考上节内容。
from common.setting import ensure_path_sep
from utils.read_files_tools.get_yaml_data_analysis import CaseData
from utils.read_files_tools.get_all_files_path import get_all_files
from utils.cache_process.cache_control import CacheHandler, _cache_config
def write_case_process():
"""
获取所有用例,写入用例池中
:return:
"""
# 循环拿到所有存放用例的文件路径
for i in get_all_files(file_path=ensure_path_sep("\\data"), yaml_data_switch=True):
# 循环读取文件中的数据
case_process = CaseData(i).case_process(case_id_switch=True)
if case_process is not None:
# 转换数据类型
for case in case_process:
for k, v in case.items():
# 判断 case_id 是否已存在
case_id_exit = k in _cache_config.keys()
# 如果case_id 不存在,则将用例写入缓存池中
if case_id_exit is False:
CacheHandler.update_cache(cache_name=k, value=v)
# case_data[k] = v
# 当 case_id 为 True 存在时,则抛出异常
elif case_id_exit is True:
raise ValueError(f"case_id: {k} 存在重复项, 请修改case_id\n"
f"文件路径: {i}")
write_case_process()
1、如上代码所示get_all_files会遍历获取data文件夹下所有的yaml和.yml文件,这两种文件里面写的是测试用例具体步骤。
2、CaseData(i).case_process(case_id_switch=True),解析测试数据,对应的代码在utils->read_files_tools_analysis.py文件中。最后返回的是一个列表套字典格式的数据,这个具体细节在下面一小节讲。
3、在循环中的每个用例中,通过遍历键值对for k, v in case.items()来检查用例是否已存在于缓存池中。
4、如果该用例的case_id不存在于缓存_cache_config字典中,则将该用例数据通过CacheHandler.update_cache(cache_name=k, value=v)写入缓存池中,如果存在该case_id则会抛出异常,所以在写用例时,case_id必须要是唯一的
5、存入到了缓存池格式为{"case_id_1":{"数据_1"},"case_id_2":{"数据_2"}}
解析yaml测试数据
接上文中的第二点,CaseData(i).case_process(case_id_switch=True),对应主代码如下:
class CaseData(CaseDataCheck):
def case_process(self, case_id_switch: Union[None, bool] = None):
data = GetYamlData(self.file_path).get_yaml_data()
case_list = []
for key, values in data.items():
# 公共配置中的数据,与用例数据不同,需要单独处理
if key != 'case_common':
self.case_data = values
self.case_id = key
super().check_params_exit()
case_date = {
'method': self.get_method,
'is_run': self.case_data.get(TestCaseEnum.IS_RUN.value[0]),
'url': self.get_host,
'detail': self.case_data.get(TestCaseEnum.DETAIL.value[0]),
'headers': self.case_data.get(TestCaseEnum.HEADERS.value[0]),
'requestType': super().get_request_type,
'data': self.case_data.get(TestCaseEnum.DATA.value[0]),
'dependence_case': self.case_data.get(TestCaseEnum.DE_CASE.value[0]),
'dependence_case_data': self.get_dependence_case_data,
"current_request_set_cache": self.case_data.get(TestCaseEnum.CURRENT_RE_SET_CACHE.value[0]),
"sql": self.get_sql,
"assert_data": self.get_assert,
"setup_sql": self.case_data.get(TestCaseEnum.SETUP_SQL.value[0]),
"teardown": self.case_data.get(TestCaseEnum.TEARDOWN.value[0]),
"teardown_sql": self.case_data.get(TestCaseEnum.TEARDOWN_SQL.value[0]),
"sleep": self.case_data.get(TestCaseEnum.SLEEP.value[0]),
}
if case_id_switch is True:
case_list.append({key: TestCase(**case_date).dict()})
else:
case_list.append(TestCase(**case_date).dict())
return case_list
1、CaseData这个类继承了CaseDataCheck类,用于用例的规范检查,都很容易看懂,这个就直接看CaseDataCheck源码就好了,源码在同文件下。
2、case_id_switch,默认传入要都为True,后续都是转化为键值对的形式,case_id作为key,它下面的测试数据作为value,value也是一个字典。对应代码case_list.append({key: TestCase(**case_date).dict()})
3、获取yaml中的具体数据,GetYamlData(self.file_path).get_yaml_data()
-
def get_yaml_data(self) -> dict: """ 获取 yaml 中的数据 :param: fileDir: :return: """ # 判断文件是否存在 if os.path.exists(self.file_dir): data = open(self.file_dir, 'r', encoding='utf-8') res = yaml.load(data, Loader=yaml.FullLoader) else: raise FileNotFoundError("文件路径不存在") return res -
示列yaml文件取自源码中的,get_user_info.yaml
-
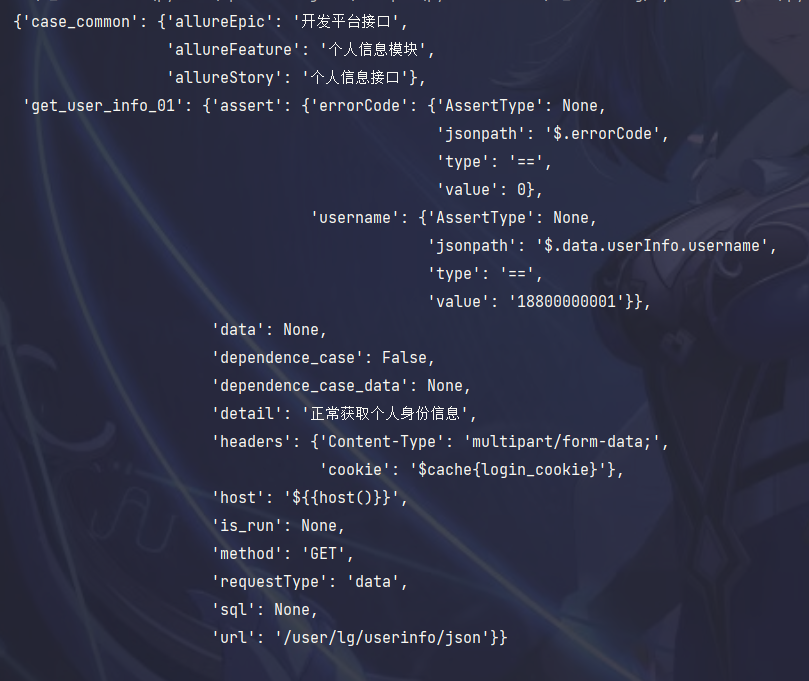
# 公共参数 case_common: allureEpic: 开发平台接口 allureFeature: 个人信息模块 allureStory: 个人信息接口 get_user_info_01: host: ${{host()}} url: /user/lg/userinfo/json method: GET detail: 正常获取个人身份信息 headers: Content-Type: multipart/form-data; # 这里cookie的值,写的是存入缓存的名称 cookie: $cache{login_cookie} # 请求的数据,是 params 还是 json、或者file、data requestType: data # 是否执行,空或者 true 都会执行 is_run: data: # 是否有依赖业务,为空或者false则表示没有 dependence_case: False # 依赖的数据 dependence_case_data: assert: # 断言接口状态码 errorCode: jsonpath: $.errorCode type: == value: 0 AssertType: # 断言接口返回的username username: jsonpath: $.data.userInfo.username type: == value: '18800000001' AssertType: sql:
-
-
返回的格式如下
4、公共配置中的数据(case_common字段),与用例数据不同,需要单独处理,这里处理的是用例数据
5、super().check_params_exit():
-
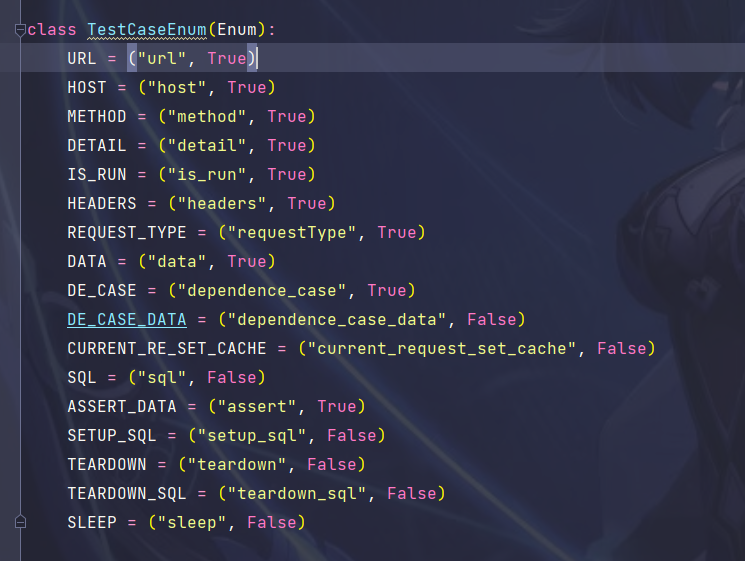
-
def _assert(self, attr: Text): # 断言如果为真,程序继续运行,如果为假,则程序会抛出AssertionError异常,并附带后面括号的提示内容 assert attr in self.case_data.keys(), ( f"用例ID为 {self.case_id} 的用例中缺少 {attr} 参数,请确认用例内容是否编写规范." f"当前用例文件路径:{self.file_path}" ) def check_params_exit(self): for enum in list(TestCaseEnum._value2member_map_.keys()): if enum[1]: self._assert(enum[0]) -
通过判断TestCaseEnum自定义的枚举类参数的第二个值,如果是True则是必填项,当必填项未填则提醒用户填写。
6、每个字段都需要经过校验,校验完成后case_data是一个字典,使用TestCase映射字典存储后,再存在case_list里面。最后返回case_list。
以源码中的get_user_info.yaml为列,此步骤返回的case_list输出的结果如下:
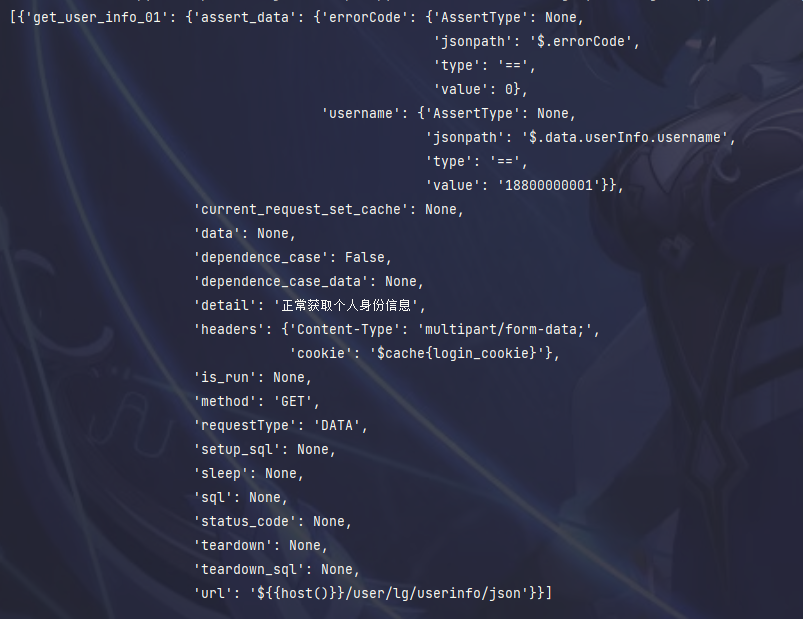
测试用例执行
pytest所要收集的测试用例都在test_case文件夹下
conftest.py
位于test_case的根目录下
session级别操作
1、先将report文件夹下的文件全部删除,autouse=False,只执行一次
2、获取登录的cookie,在这里是已经写死了的,autouse=True,并且将这个cookie值存到缓存当中。
-
缓存文件utils/cache_process/cache_control.py
-
在该缓存文件中有一个空字典
_cache_config = {},每次加入则以键值对的形式放在这个字典中,需要用的话就从里面取出。 -
_cache_config = {} class CacheHandler: @staticmethod def get_cache(cache_data): try: return _cache_config[cache_data] except KeyError: raise ValueNotFoundError(f"{cache_data}的缓存数据未找到,请检查是否将该数据存入缓存中") @staticmethod def update_cache(*, cache_name, value): _cache_config[cache_name] = value
3、跳过用例
@pytest.fixture(scope="function", autouse=True)
def case_skip(in_data):
"""处理跳过用例"""
in_data = TestCase(**in_data) # 这里直接是TestCase的对象,可以直接点出它下面的所有属性
# 如果yaml文件中,is_run字段为False,则会执行以下代码,从而达到跳过该条用例的目的
if ast.literal_eval(cache_regular(str(in_data.is_run))) is False:
allure.dynamic.title(in_data.detail)
allure_step_no(f"请求URL: {in_data.is_run}")
allure_step_no(f"请求方式: {in_data.method}")
allure_step("请求头: ", in_data.headers)
allure_step("请求数据: ", in_data.data)
allure_step("依赖数据: ", in_data.dependence_case_data)
allure_step("预期数据: ", in_data.assert_data)
pytest.skip()
用例demo分析
这里以源码中的test_case -> UserInfo -> test_get_user_info.py示列文件作为我们用例分析的demo文件。
代码如下:
import allure
import pytest
from utils.read_files_tools.get_yaml_data_analysis import GetTestCase
from utils.assertion.assert_control import Assert
from utils.requests_tool.request_control import RequestControl
from utils.read_files_tools.regular_control import regular
from utils.requests_tool.teardown_control import TearDownHandler
case_id = ['get_user_info_01']
TestData = GetTestCase.case_data(case_id)
re_data = regular(str(TestData))
@allure.epic("开发平台接口")
@allure.feature("个人信息模块")
class TestGetUserInfo:
@allure.story("个人信息接口")
@pytest.mark.parametrize('in_data', eval(re_data), ids=[i['detail'] for i in TestData])
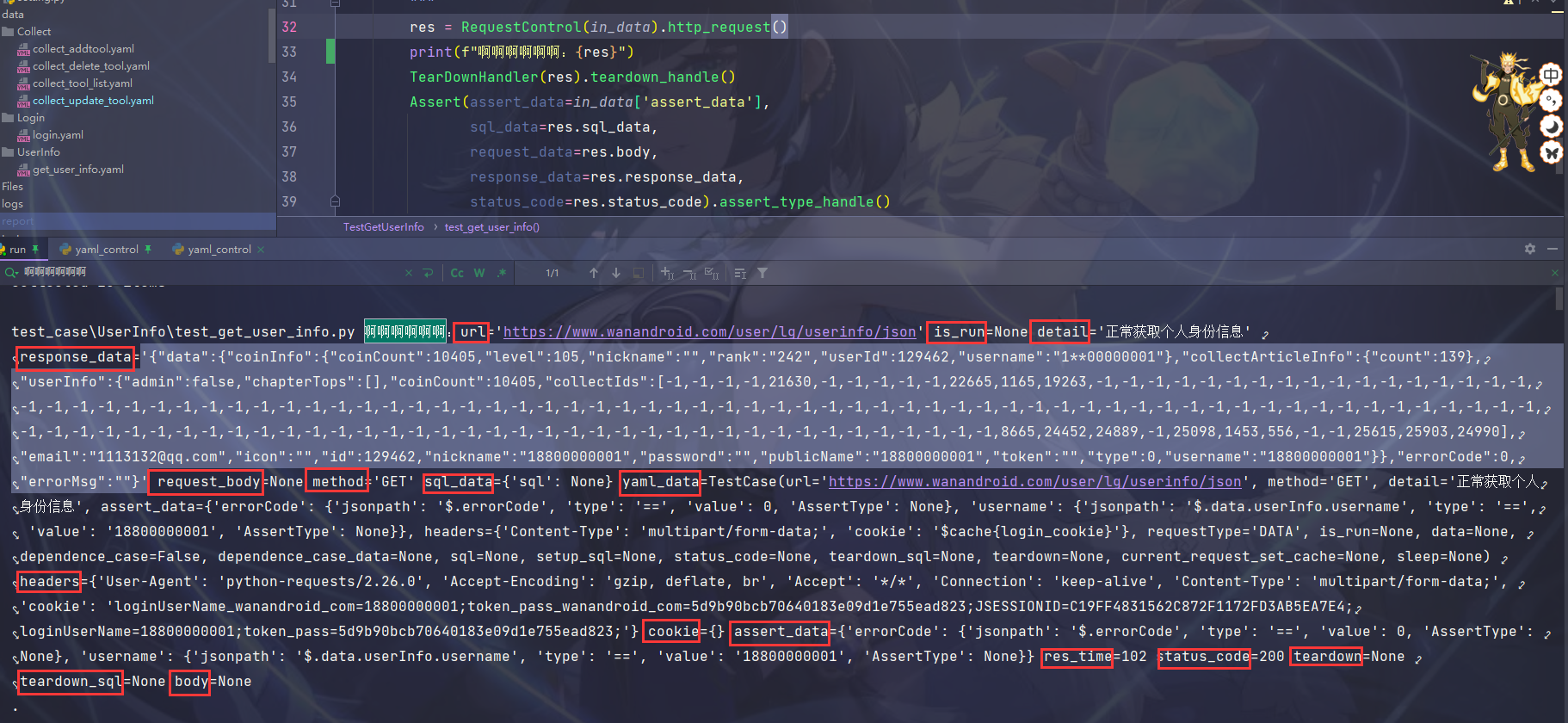
def test_get_user_info(self, in_data, case_skip):
"""
:param :
:return:
"""
res = RequestControl(in_data).http_request()
TearDownHandler(res).teardown_handle()
Assert(assert_data=in_data['assert_data'],
sql_data=res.sql_data,
request_data=res.body,
response_data=res.response_data,
status_code=res.status_code).assert_type_handle()
if __name__ == '__main__':
pytest.main(['test_test_get_user_info.py', '-s', '-W', 'ignore:Module already imported:pytest.PytestWarning'])
对应的yaml文件如下:
# 公共参数
case_common:
allureEpic: 开发平台接口
allureFeature: 个人信息模块
allureStory: 个人信息接口
get_user_info_01:
host: ${{host()}}
url: /user/lg/userinfo/json
method: GET
detail: 正常获取个人身份信息
headers:
Content-Type: multipart/form-data;
# 这里cookie的值,写的是存入缓存的名称
cookie: $cache{login_cookie}
# 请求的数据,是 params 还是 json、或者file、data
requestType: data
# 是否执行,空或者 true 都会执行
is_run:
data:
# 是否有依赖业务,为空或者false则表示没有
dependence_case: False
# 依赖的数据
dependence_case_data:
assert:
# 断言接口状态码
errorCode:
jsonpath: $.errorCode
type: ==
value: 0
AssertType:
# 断言接口返回的username
username:
jsonpath: $.data.userInfo.username
type: ==
value: '18800000001'
AssertType:
sql:
加载yaml中的数据
1、case_id = [‘get_user_info_01’]
- 一个yaml文件下的case_id,用列表存储,可以有多个。
2、TestData = GetTestCase.case_data(case_id)
- TestData 的格式为 [{case_data_1},{case_data_2}]
class GetTestCase:
@staticmethod
def case_data(case_id_lists: List):
case_lists = []
# 一个yaml文件中,有一个或多个case_id,把每一个case_id下的数据取出放到一个列表里
for i in case_id_lists:
_data = CacheHandler.get_cache(i)
case_lists.append(_data)
return case_lists
- CacheHandler.get_cache(i):将数据从缓存中取出数据,得到的
TestData数据格式为[[数据1],[数据2]],所取的数据从哪来——在上文中的解析yaml测试数据一节中有详细分析。
3、re_data = regular(str(TestData))
-
把TestData强制转化成了str类型
-
使用正则替换请求数据,比如{{ host() }}数据,需要进行处理,utils -> read_files_tools -> regular_control.py -> regular
-
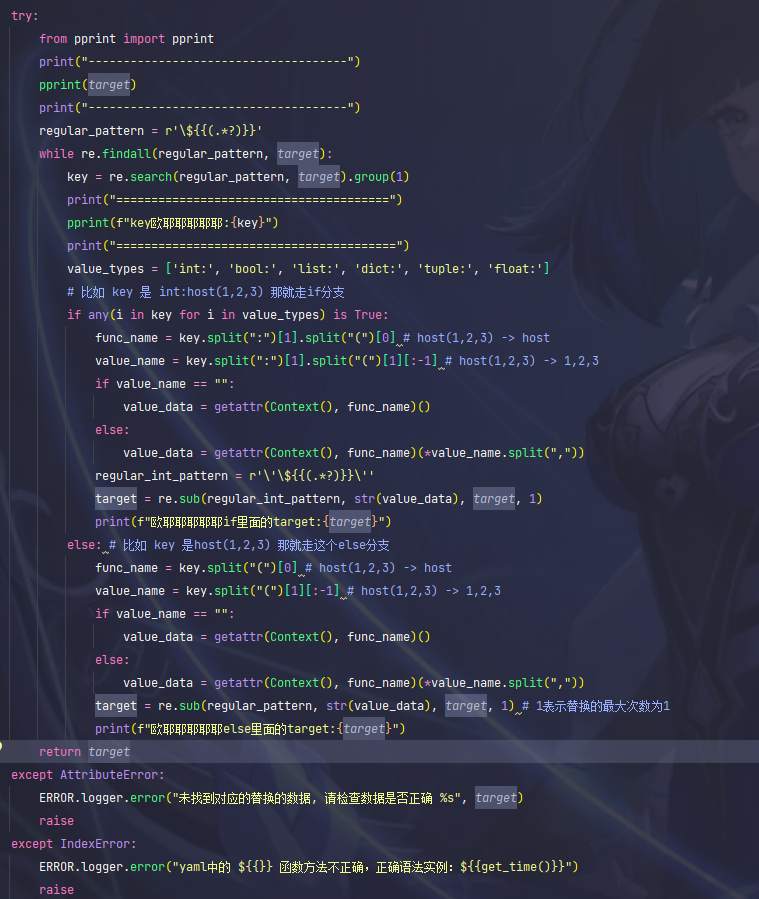
为了更客观的看到正则的数据,我把除了get_user_info.yaml的用例都设置成了skip。上方的代码也是我增加了print数据。
第一个输出的target内容如下: (要方便看的话需要结合get_user_info.yaml文件)
("[{'url': '${{host()}}/user/lg/userinfo/json', 'method': 'GET', 'detail': "
"'正常获取个人身份信息', 'assert_data': {'errorCode': {'jsonpath': '$.errorCode', "
"'type': '==', 'value': 0, 'AssertType': None}, 'username': {'jsonpath': "
"'$.data.userInfo.username', 'type': '==', 'value': '18800000001', "
"'AssertType': None}}, 'headers': {'Content-Type': 'multipart/form-data;', "
"'cookie': '$cache{login_cookie}'}, 'requestType': 'DATA', 'is_run': None, "
"'data': None, 'dependence_case': False, 'dependence_case_data': None, 'sql': "
"None, 'setup_sql': None, 'status_code': None, 'teardown_sql': None, "
"'teardown': None, 'current_request_set_cache': None, 'sleep': None}]")
第二个输出的key内容如下:
host()
由此推断regular_pattern = r'\${{(.*?)}}'这个规则是为了过滤提取形如{{host()}}格式的参数。
-
比如 key 是 int:host(1,2,3) 那就走if分支,提取方法名和参数 如果 key 是 host(1,2,3) 那就走else分支,提取方法名和参数
第三个输出的是else分支下的target,就是进行了替换后的target
欧耶耶耶耶耶else里面的target:[{'url': 'https://www.wanandroid.com/user/lg/userinfo/json', 'method': 'GET', 'detail': '正常获取个人身份信息', 'assert_data': {'errorCode': {'jsonpath': '$.errorCode', 'type': '==', 'value': 0, 'AssertType': None}, 'username': {'jsonpath': '$.data.userInfo.username', 'type': '==', 'value': '18800000001', 'AssertType': None}}, 'headers': {'Content-Type': 'multipart/form-data;', 'cookie': '$cache{login_cookie}'}, 'requestType': 'DATA', 'is_run': None, 'data': None, 'dependence_case': False, 'dependence_case_data': None, 'sql': None, 'setup_sql': None, 'status_code': None, 'teardown_sql': None, 'teardown': None, 'current_request_set_cache': None, 'sleep': None}]
-
替换使用的是getattr,进行获取Context()类下面对应的方法。后面加个括号表示直接调用获取其返回值。
-
无参数走if,有参数走else
-
if value_name == "": value_data = getattr(Context(), func_name)() else: value_data = getattr(Context(), func_name)(*value_name.split(","))
-
每一次执行后都会进行target的新旧替换,直至这个字符串里面没有形如{{host()}}格式的参数。
target = re.sub(regular_pattern, str(value_data), target, 1) # 1表示替换的最大次数为1
同理 $cache{login_02_v_code}获取缓存中的数据是有专门的一个cache_regular方法,只是规则不一样。处理步骤和上面的如出一辙。
数据驱动执行用例
@pytest.mark.parametrize('in_data', eval(re_data), ids=[i['detail'] for i in TestData])
这里的re_data的数据类型是<class 'str'>,我们使用eval方法把他转化成列表。
ids取detail描述作为allure报告中的标识,如下图所示:
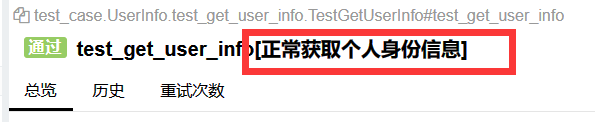
循环读取执行用例,列表有多长,就有多少个测试用例。
用例前置
def test_get_user_info(self, in_data, case_skip):
in_data:不做过多的说明,就是yaml文件中经过处理的所有数据。
case_skip:这个是在conftest.py设置的操作,用来判断用例是否要跳过。
request请求配置
res = RequestControl(in_data).http_request()
对应方法所在的位置:\utils\requests_tool\request_control.py --> http_request()
in_data就是我们前面运行的那一大串:
[{'url': 'https://www.wanandroid.com/user/lg/userinfo/json', 'method': 'GET', 'detail': '正常获取个人身份信息', 'assert_data': {'errorCode': {'jsonpath': '$.errorCode', 'type': '==', 'value': 0, 'AssertType': None}, 'username': {'jsonpath': '$.data.userInfo.username', 'type': '==', 'value': '18800000001', 'AssertType': None}}, 'headers': {'Content-Type': 'multipart/form-data;', 'cookie': '$cache{login_cookie}'}, 'requestType': 'DATA', 'is_run': None, 'data': None, 'dependence_case': False, 'dependence_case_data': None, 'sql': None, 'setup_sql': None, 'status_code': None, 'teardown_sql': None, 'teardown': None, 'current_request_set_cache': None, 'sleep': None}]
对request请求类型,如json、params、file、data等类型进行相关处理,具体可以看源码,这里我做一个流程化分析,封装的很全面。
# 这里只是获取到了一个对象,当没有真的执行 ,这些对象方法都在当前py文件中
# 比如 self.request_type_for_json,只是将这个方法地址存在了 requests_type_mapping 字典中
# 在self.request_type_for_json后面加了 () 才代表执行了这个函数对象
requests_type_mapping = {
RequestType.JSON.value: self.request_type_for_json,
RequestType.NONE.value: self.request_type_for_none,
RequestType.PARAMS.value: self.request_type_for_params,
RequestType.FILE.value: self.request_type_for_file,
RequestType.DATA.value: self.request_type_for_data,
RequestType.EXPORT.value: self.request_type_for_export
}
以下这一部分是对多业务逻辑进行处理:
# 处理多业务逻辑
if dependent_switch is True:
# 对jsonpath和依赖的数据进行替换
DependentCase(self.__yaml_case).get_dependent_data()
res = requests_type_mapping.get(self.__yaml_case.requestType)(
headers=self.__yaml_case.headers,
method=self.__yaml_case.method,
**kwargs
)
if self.__yaml_case.sleep is not None:
time.sleep(self.__yaml_case.sleep)
_res_data = self._check_params(
res=res,
yaml_data=self.__yaml_case)
self.api_allure_step(
url=_res_data.url,
headers=str(_res_data.headers),
method=_res_data.method,
data=str(_res_data.body),
assert_data=str(_res_data.assert_data),
res_time=str(_res_data.res_time),
res=_res_data.response_data
)
# 将当前请求数据存入缓存中
SetCurrentRequestCache(
current_request_set_cache=self.__yaml_case.current_request_set_cache,
request_data=self.__yaml_case.data,
response_data=res
).set_caches_main()
return _res_data
多业务逻辑代码分析
片段1
# 处理多业务逻辑
if dependent_switch is True:
DependentCase(self.__yaml_case).get_dependent_data()
utils -> requests_tool -> dependent_case.py
-
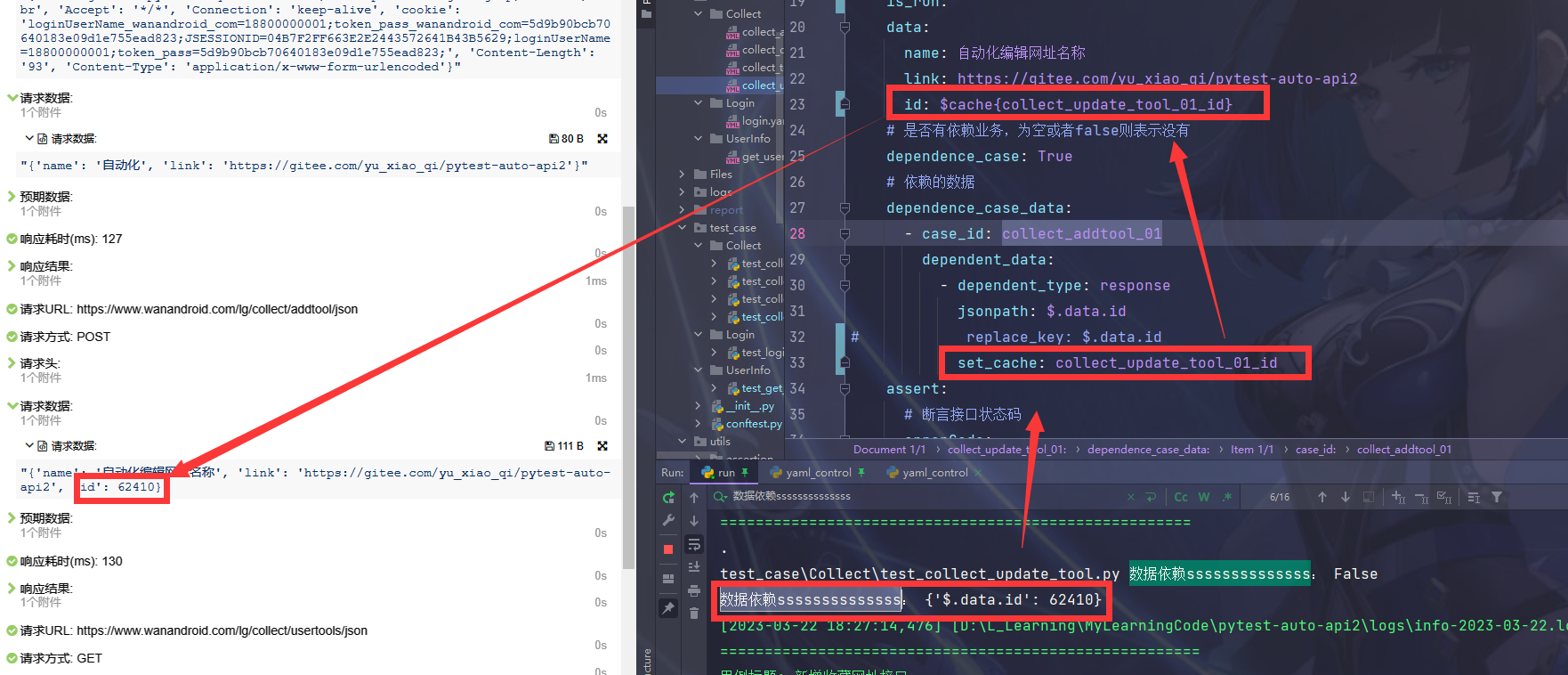
def get_dependent_data(self) -> None: """ jsonpath 和 依赖的数据,进行替换 :return: """ _dependent_data = DependentCase(self.__yaml_case).is_dependent() print("数据依赖ssssssssssssss:",_dependent_data) _new_data = None # 判断有依赖 if _dependent_data is not None and _dependent_data is not False: # if _dependent_data is not False: for key, value in _dependent_data.items(): # 通过jsonpath判断出需要替换数据的位置 _change_data = key.split(".") # jsonpath 数据解析 # 不要删 这个yaml_case yaml_case = self.__yaml_case _new_data = jsonpath_replace(change_data=_change_data, key_name='yaml_case') # 最终提取到的数据,转换成 __yaml_case.data _new_data += ' = ' + str(value) exec(_new_data) -
_dependent_data = DependentCase(self.__yaml_case).is_dependent(),源码自己点开。-
这段代码是 Python 中的一个类方法,具体实现了在运行测试用例时,判断测试用例是否有数据依赖关系,并且根据依赖关系获取数据。
具体解析如下:
__yaml_case是当前类的一个私有属性,用来获取测试用例相关的数据,包括依赖的类型、依赖用例的数据、依赖数据的设置等等。_dependent_type = self.__yaml_case.dependence_case获取当前测试用例是否需要运行数据依赖关系,只有是True的时候才会执行依赖。_dependence_case_dates = self.__yaml_case.dependence_case_data获取当前测试用例的依赖用例数据。_setup_sql = self.__yaml_case.setup_sql获取设置setup_sql数据库语句,属于前置sql操作。- 判断是否有依赖:
- 如果
_dependent_type是True,则表示当前用例需要运行数据依赖。 - 否则返回
False,表示当前用例不需要运行数据依赖。
- 如果
- 如果需要数据依赖,则根据依赖关系获取依赖数据,并返回依赖数据。
- 如果依赖的数据是 SQL,则根据
_dependence_case_dates中的相关内容,在数据库中执行 SQL 语句,并获取查询结果。 - 如果依赖的数据是请求响应体中的数据,则依据
jsonpath表达式获取响应数据,并且根据依赖关系设置的值进行处理(如替换,存储等)。 - 如果依赖数据是请求数据,则从请求数据中根据
jsonpath表达式获取数据,并进行处理。 - 如果依赖数据类型不符合要求,则抛出异常。
- 如果依赖的数据是 SQL,则根据
- 最后是异常处理的内容,如果在获取依赖数据的过程中出现了异常(如
KeyError或TypeError),则抛出异常并给出具体的原因。
综上所述,以上代码实现了数据依赖处理的功能,并且根据依赖关系获取依赖数据。
-
片段2
# 假如请求的requestType是data
# 那下面代码相当于是 self.request_type_for_data( headers=self.__yaml_case.headers,method=self.__yaml_case.method,**kwargs)
res = requests_type_mapping.get(self.__yaml_case.requestType)(
headers=self.__yaml_case.headers,
method=self.__yaml_case.method,
**kwargs
)
这段代码是一个 Python 中的函数调用语句,使用了字典对象的 get() 方法来实现根据 key 值来获取 value 的功能。作用是根据请求类型来调用对应的方法,然后将 self.__yaml_case.headers 和 self.__yaml_case.method 传递给该方法并返回结果给变量 res,同时也把 kwargs 中的其他参数传递给该方法。
具体解析如下:
-
requests_type_mapping是一个字典对象。 -
self.__yaml_case.requestType获取了一个字符串类型的请求类型(例如 GET、POST、DELETE 等)。 -
requests_type_mapping.get(self.__yaml_case.requestType)根据
self.__yaml_case.requestType作为 key 值,从requests_type_mapping字典对象获取相应的 value 值。- 如果能找到对应的 value 值,则根据获取到的函数来执行对应的请求。
- 如果
requests_type_mapping中不存在对应的 key 值,则返回默认值 None。
-
如果能在
requests_type_mapping字典对象中找到对应的 value 值,则通过调用该函数来执行相应的请求,将self.__yaml_case.headers和self.__yaml_case.method作为参数传递给该函数。 -
**kwargs表示可变长参数,将其中的参数作为命名参数传递给被调用的函数,并执行该函数。 -
调用结果由
res变量接收,通常是一个请求响应对象。
数据依赖
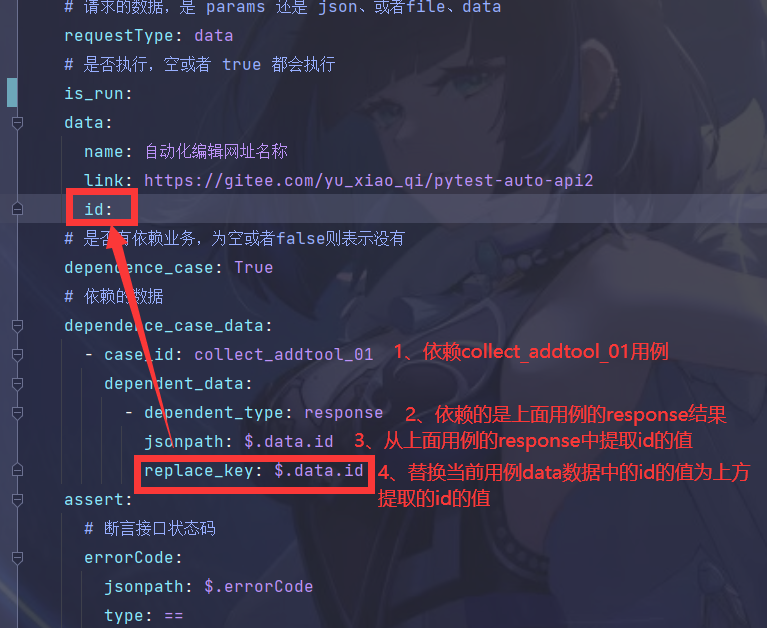
写成如下形式:
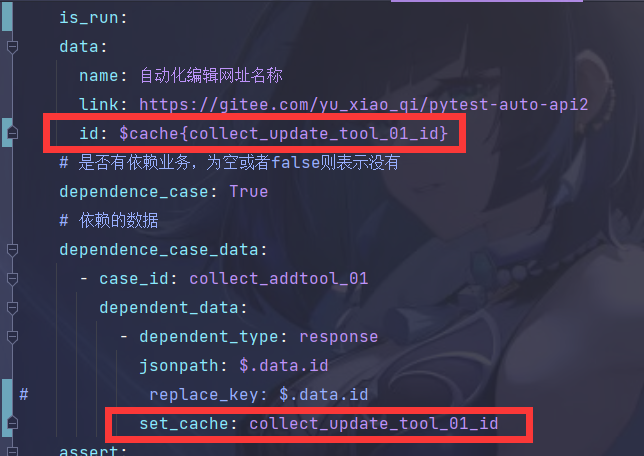
关键字:current_request_set_cache
示列:
current_request_set_cache:
# 1、response 从响应中提取内容 2、request从请求中提取内容
- type: response
jsonpath: $.data.data.[0].id
# 自定义的缓存名称
name: test_query_shop_brand_list_02_id
**作者建议:**也可以在collect_addtool_01中提取出相关数据,放在缓存里面,后续别的接口直接从缓存里面读
后置操作(数据清洗)
utils -> requests_tool -> teardown_control.py -> teardown_handle()
TearDownHandler(res).teardown_handle()
这里的res是在上一步返回出来的,res的数据格式为:
class ResponseData(BaseModel):
url: Text
is_run: Union[None, bool, Text]
detail: Text
response_data: Text
request_body: Any
method: Text
sql_data: Dict
yaml_data: "TestCase"
headers: Dict
cookie: Dict
assert_data: Dict
res_time: Union[int, float]
status_code: int
teardown: List["TearDown"] = None
teardown_sql: Union[None, List]
body: Any
self._res是当前类的私有属性,代表当前执行测试用例后的结果信息。_teardown_data = self._res.teardown获取当前测试用例中 teardown 的相关数据。_resp_data = self._res.response_data获取当前测试用例的接口响应数据。_request_data = self._res.yaml_data.data获取接口的请求参数。- 如果存在 teardown 数据,则根据关键字进行区分处理。
- 如果 teardown 数据中包含关键字
param_prepare,则需要处理前置请求参数等数据。具体实现是调用self.param_prepare_request_handler()方法,处理相关数据并返回结果。 - 如果 teardown 数据中包含关键字
send_request,则需要发送请求数据。具体实现是调用self.send_request_handler()方法,发送相关请求并处理结果。 - 最后调用
self.teardown_sql()方法处理数据操作。 - 在 teardown 数据处理的过程中,为了判断当前处理的 teardown 数据是否需要发送请求,需要对两种情况进行区分,一个是 param_prepare,一个是 send_request。
综上所述,该方法主要是根据不同的 teardown 数据操作,进行不同的数据处理,包括发送请求、处理请求参数等。由于 teardown 数据操作可能需要获取当前及之前测试用例的请求响应等信息,因此需要区分处理方式。
断言操作
Assert(assert_data=in_data['assert_data'],
sql_data=res.sql_data,
request_data=res.body,
response_data=res.response_data,
status_code=res.status_code).assert_type_handle()
\utils\assertion\assert_control.py -> assert_type_handle()
主要代码段:(该文件其他代码从上往下看就可以,整齐划一通俗易懂)
def assert_type_handle(self):
# 判断请求参数数据库断言
if self.get_assert_type == "R_SQL":
self._assert(self._assert_request_data, self.get_sql_data, self.get_message)
# 判断请求参数为响应数据库断言
elif self.get_assert_type == "SQL" or self.get_assert_type == "D_SQL":
self._assert(self._assert_resp_data, self.get_sql_data, self.get_message)
# 判断非数据库断言类型
elif self.get_assert_type is None:
self._assert(self._assert_resp_data, self.get_value, self.get_message)
else:
raise AssertTypeError("断言失败,目前只支持数据库断言和响应断言")
该段代码的具体解析如下:
- 获取当前实例的断言类型 (
get_assert_type)。 - 如果断言类型为 “R_SQL”,则调用
_assert()方法进行请求参数和数据库数据的断言。 - 如果断言类型为 “SQL” 或 “D_SQL”,则调用
_assert()方法进行响应数据和数据库数据的断言。 - 如果断言类型为
None,则调用_assert()方法进行响应数据和请求参数中的 value 值的断言。 - 如果断言类型不为以上三种,抛出自定义异常
AssertTypeError,提示该方法目前只支持数据库断言和响应断言。
注:_assert() 方法为类中的另一个私有方法,用于进行具体的数据断言。
综上所述,该方法主要根据断言类型分别调用不同的数据断言方法。如果类型不支持,则抛出异常。
断言包含的类型
class AssertMethod(Enum):
"""断言类型"""
equals = "=="
less_than = "lt"
less_than_or_equals = "le"
greater_than = "gt"
greater_than_or_equals = "ge"
not_equals = "not_eq"
string_equals = "str_eq"
length_equals = "len_eq"
length_greater_than = "len_gt"
length_greater_than_or_equals = 'len_ge'
length_less_than = "len_lt"
length_less_than_or_equals = 'len_le'
contains = "contains"
contained_by = 'contained_by'
startswith = 'startswith'
endswith = 'endswith'
与作者的问答
大佬,你的框架里面,dependence_case,最新的代码和gitee上的教程内容有点不一样。
1、教程里面是set_cache,然后再使用这个缓存数据
2、你最新的代码是直接写的replace_key的一个提取表达式
我两种方式都写了一下,请问这两种方式都是可以的是嘛?
还有个问题就是,当前A用例如果依赖了B用例,那么运行A用例的时候,B用例时还会再执行一遍嘛?
收到,第一个问题推荐使用setcache关键字,replacekey为旧版本研发的功能,目前在特定场景下使用会存在一定的问题
第二个问题,是的,dependentcase类似源码调用函数的功能,需要使用的时候去调用它,可以减少部分冗余的用例字段
如果不去调用,是不是可以用current_request_set_cache这个关键字,在所要依赖的用例里面提取出相关数据放在缓存里面,后续别的接口直接从缓存里面读
是的
结束
allure报告生成
数据统计汇总
结果发送
部分代码分析:
片段1
pytest.main(['-s', '-W', 'ignore:Module already imported:pytest.PytestWarning',
'--alluredir', './report/tmp', "--clean-alluredir"])
该代码段是运行 Python 中的 Pytest 模块,并传入了一些参数来设置测试的选项。具体来说,该代码执行以下操作:
pytest.main():调用 Pytest 模块中的main()函数开始运行测试。['-s', '-W', 'ignore:Module already imported:pytest.PytestWarning', '--alluredir', './report/tmp', "--clean-alluredir"]:设置 Pytest 运行测试的选项参数。-s:表示向标准输出流输出所有测试结果的详细信息,包括 log 信息等。-W:表示忽略特定类型的警告。ignore:Module already imported:pytest.PytestWarning:表示忽略警告 “Module already imported”。--alluredir:表示指定 Allure 测试报告的输出目录。./report/tmp:表示将测试结果数据写入到指定的 Allure 测试报告数据文件夹中。--clean-alluredir:表示在生成 Allure 测试报告前,先清除指定目录中的旧数据,以免对测试报告的生成产生影响。
以上就是该代码的执行方式和每个参数的作用。在执行 Pytest 测试时,可以使用这些参数来自定义测试运行方式和测试报告的生成。
片段2
os.system(r"allure generate ./report/tmp -o ./report/html --clean")
这行代码是在 Python 中调用系统命令,使用 os.system() 函数来执行系统命令。具体命令为:
allure generate ./report/tmp -o ./report/html --clean
该命令使用 Allure 工具生成测试报告,从 ./report/tmp 路径下读取测试结果数据,然后将报告输出到 ./report/html 路径下。
其中,--clean 参数表示在生成测试报告前,清空输出目录,以防止旧的测试报告文件对新测试报告的干扰。
因为是通过 os.system() 函数调用的系统命令,所以该代码的执行结果和命令行的执行结果是一致的。执行成功会生成新的 Allure 报告,执行失败会抛出异常。