文章目录
- 概述
- Spring WebFlux概述
- Reactive编程&Reactor库
- WebFlux服务器
- WebFlux的并发模型
- WebFlux对性能的影响
- WebFlux的编程模型
- WebFlux注解式编程模型
- WebFlux函数式编程模型
- WebFlux原理浅尝
- Reactor Netty概述
- WebFlux服务器启动流程
- WebFlux一次服务调用流程
- WebFlux的适用场景
- 建议
- 小结

概述
我们这里主要探讨Spring框架5.0中引入的新的WebFlux技术栈,并介绍其存在的价值与意义、并发模型与适用场景、如何基于WebFlux实现异步编程,以及其内部的实现原理。
Spring WebFlux概述
Spring框架中包含的原始Web框架Spring Web MVC是专为Servlet API和Servlet容器构建的。
反应式栈的Web框架Spring WebFlux则是在Spring 5.0版中才添加的,它是完全无阻塞的,支持Reactive Streams回压,并可以在Netty、Undertow和Servlet 3.1+容器等服务器上运行。其中,WebFlux中的Flux源自Reactor库中的Flux流对象。
如下图左侧所示是spring-webmvc模块提供的基于Servlet的传统Spring MVC技术栈,右侧所示是spring-webflux模块的反应式编程技术栈(Reactive Stack)。
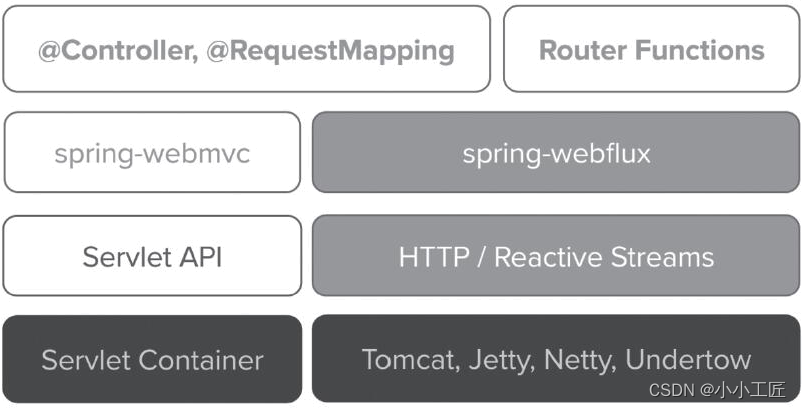
【Web技术栈对比】
Servlet API最初是为了通过Filter→Servlet链进行单次传递而构建的。Servlet 3.0规范中添加的异步请求处理允许应用程序及时退出Filter-Servlet链(及时释放容器线程),但保持响应打开以便异步线程进行后续处理。Spring MVC的异步处理支持是围绕该机制构建的。当controller返回DeferredResult时,将退出Filter-Servlet链,并释放Servlet容器线程。稍后,当设置DeferredResult时,会对请求进行重新分派,使用DeferredResult值(就像controller返回它一样)以恢复处理。
相比之下,Spring WebFlux既不是基于Servlet API构建的,也不需要额外的异步请求处理功能,因为它在设计上是异步的。其对异步的处理是内置于框架规范中的,并通过请求处理的所有阶段进行内在支持。
从编程模型的角度来看,Spring MVC和Spring WebFlux都支持异步和反应式作为controller方法中的返回值。Spring MVC甚至支持流媒体,包括反应性回压功能,但是其对响应的写入仍然是阻塞的(并且在单独的线程上执行),Servlet 3.1确实为非阻塞IO提供了API,但是使用它会远离Servlet API的其余部分,比如其规范是同步的(Filter,Servlet)或阻塞的(getParameter,getPart)。WebFlux则不同,其依赖于非阻塞IO,并且每次写入都不需要额外的线程进行支持。
Reactive编程&Reactor库
Reactive(反应式编程),其是指围绕变化做出反应的编程模型,比如对IO事件做出反应的网络组件、对鼠标事件做出反应的UI控制器等。从这个意义上说,非阻塞是被动的,因为我们现在处于一种模式,即在操作完成或数据可用时对结果做出反应。
Reactive Streams是一个规范(在Java 9中也采用),用于定义具有回压的异步组件之间的交互。例如,数据存储库(充当发布者)可以产生数据(从数据库迭代出数据),然后HTTP服务器(充当订阅服务器)可以把迭代出的数据写入请求响应中,那么数据库中迭代数据的快慢就取决于HTTP服务器向响应对象里面写入的快慢。Reactive Streams的主要目的是让订阅者控制发布者生成数据的速度。
另外Reactive Streams的目的是建立回压的一种机制和一个边界限制,如果发布者不能降低自己生产数据的速度,那么它要决定是否缓存、丢失或者报错失败。
Reactive Streams在互操作性方面发挥着重要作用。它对库和基础架构组件很有用,但作为应用程序API不太有用,因为它太低级了。应用程序需要更高级别和更丰富的功能API来组成异步逻辑——类似于Java 8 Stream API,但其不仅适用于集合。这是Reactive库所扮演的角色,Java中已有的Reactive库有Reactor和RxJava,Spring团队认为Reactor是Spring WebFlux的首选Reactive库。Reactor提供Mono和Flux API流类型,其提供了与ReactiveX词汇表对齐的丰富运算符,处理0…1(Mono)和0…N(Flux)的数据序列。Reactor是一个Reactive Streams库,因此它的所有运营商都支持非阻塞反压功能,它是与Spring合作开发的。
WebFlux要求Reactor作为核心依赖,但它可以通过Reactive Streams与其他反应库(比如RxJava)进行交互操作。作为一般规则,WebFlux API接收普通Publisher作为输入,在内部使其适配Reactor类型,使用它并返回Flux或Mono作为输出。因此,可以将任何Publisher作为输入传递,并且可以对输出应用操作符,但是需要调整输出以与其他类型的反应库(例如RxJava)一起使用。只要可行(例如带注解的controller),WebFlux就会透明地适配RxJava或其他反应库的使用。
WebFlux服务器
Spring WebFlux可以在Tomcat、Jetty、Servlet 3.1+容器以及非Servlet容器(如Netty和Undertow)上运行。所有服务器都适用于低级别的通用API,因此可以跨服务器支持更高级别的编程模型。
Spring WebFlux没有内置用来启动或停止服务器的功能,但是可以通过Spring配置和WebFlux基础架构组装应用程序,写简单的几行代码就可以启动服务器。
Spring Boot有一个WebFlux启动器(starter),可以自动启动。另外默认情况下,starter使用Netty作为服务器(基于reactor-netty支持),可以通过更改Maven或Gradle依赖项轻松切换到Tomcat、Jetty或Undertow服务器。Spring Boot之所以默认用Netty作为服务器,是因为Netty在异步、非阻塞领域中使用得比较广泛,并允许客户端和服务器共享资源(比如共享NioEventLoopGroup)。
Tomcat、Jetty容器可以与Spring MVC、WebFlux一起使用。但请记住,它们的使用方式不同。Spring MVC依赖于Servlet阻塞IO,并允许应用程序在需要时直接使用Servlet API。Spring WebFlux依赖于Servlet 3.1非阻塞IO,并在低级适配器后面使用Servlet API,而不是直接使用。
Undertow作为服务器时,Spring WebFlux直接使用Undertow API而不使用Servlet API。
那么WebFlux是如何做到平滑地切换不同服务器的呢?在WebFlux中HttpHandler有一个简单的规范,只有一个方法来处理请求和响应:
public interface HttpHandler {
/**
* Handle the given request and write to the response.
* @param request current request
* @param response current response
* @return indicates completion of request handling
*/
Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response);
}
该方法是故意被设计为最小化的,它的主要目的是成为不同HTTP服务器API的最小抽象,而且WebFlux底层基础设施是基于其进行编程的,所以不同类型的服务器只需要添加一个适配器来适配HttpHandler即可,主要服务器与其对应的适配器如表所示

比如,基于Reactor Netty实现服务器时,可以使用下面代码适配HttpHandler并启动服务器:
HttpHandler handler = ...
ReactorHttpHandlerAdapter adapter = new ReactorHttpHandlerAdapter(handler);
HttpServer.create(host, port).newHandler(adapter).block();
Netty服务器启动后会监听客户端的请求,当boss IO线程接收到完成TCP三次握手的请求后,会把连接套接字通道传递给worker IO线程进行具体处理,后者则会调用适配器ReactorHttpHandlerAdapter的apply方法进行处理,然后适配器就会把请求再转发给基础层的HttpHandler的实现类HttpWebHandlerAdapter的handle方法进行处理,其内部则会调用请求分配器DispatcherHandler的handle方法把请求分配到具体的controller进行执行。
比如,基于Tomcat实现服务器时,可以使用下面的代码适配HttpHandler并启动服务器:
HttpHandler handler = ...
Servlet servlet = new TomcatHttpHandlerAdapter(handler);
Tomcat server = new Tomcat();
File base = new File(System.getProperty("java.io.tmpdir"));
Context rootContext = server.addContext("", base.getAbsolutePath());
Tomcat.addServlet(rootContext, "main", servlet);
rootContext.addServletMappingDecoded("/", "main");
server.setHost(host);
server.setPort(port);
server.start();
Tomcat服务器启动后会监听客户端的请求,当请求监听线程接收到完成TCP三次握手的请求后,会把请求交给Tomcat容器内的HTTP处理器(比如Http11Processor)进行处理,后者则会使请求经过一层层容器后再经过Filter链调用到Tomcat的TomcatHttpHandlerAdapter适配器的service方法,然后适配器就会把请求转发给基础层的HttpHandler的实现类HttpWebHandlerAdapter的handle方法进行处理,其内部则会调用请求分配器DispatcherHandler的handle方法把请求分配到具体的controller进行执行。
在WebFlux提供的HttpHandler层以下是通用的基础设施,上层具体服务器只需要创建自己的适配器,即可方便地使用WebFlux底层功能。
WebFlux的并发模型
Spring MVC和Spring WebFlux都支持带注解的controllers,但并发模型和对线程是否阻塞的假设存在关键差异。
在Spring MVC(及一般的Servlet应用程序)中,假设应用程序可以阻塞当前线程(例如远程过程调用),则Servlet容器一般使用大型线程池来化解请求期间的潜在阻塞问题。
在Spring WebFlux(以及一般的非阻塞服务器,例如Netty)中,假设应用程序不会阻塞,因此非阻塞服务器使用小的固定大小的线程池(事件循环IO工作线程)来处理请求。
如果确实需要使用阻塞库,该怎么办?Reactor和RxJava分别提供了publishOn和observeOn运算符将流上的后续操作切换到其他的线程上进行处理。这意味着在阻塞API方案中,有一个简单的适配方案。但请记住,阻塞API不适合这种并发模型。
在Reactor和RxJava中,可以使用操作符声明逻辑,并且在运行时形成一个反应流,其中数据在不同的阶段按顺序处理。这样做的一个主要好处是它可以使应用程序中的数据处于线程安全的状态,因为该反应流中的应用程序代码永远不会被并发调用。
WebFlux对性能的影响
反应式和非阻塞编程通常不会使应用程序运行得更快,虽然在某些情况下它们可以(例如使用WebClient并行执行远程调用)做到更快。相反以非阻塞的方式来执行,需要做更多的额外工作,并且可能会增加处理所需的时间。
反应式和非阻塞的关键好处是能够使用少量固定数量的线程和更少的内存实现系统可伸缩性。这使得应用程序在负载下更具弹性,因为它们以更可预测的方式扩展。但是为了得到这些好处,需要付出一些代价(比如不可预测的网络IO)。
WebFlux的编程模型
spring-web模块包含作为Spring WebFlux基础的反应式基础,包括HTTP抽象,支持服务器的反应流适配器(Reactive Streams Adapter)、编解码器(codecs),以及与Servlet API等价但具有非阻塞规范的核心WebHandler API。
在此基础上,Spring WebFlux提供了两种编程模型以供选择:
-
带注解的controller(Annotated Controller):与Spring MVC一致,并基于spring-web模块的相同注解。Spring MVC和WebFlux控制器都支持反应式返回类型,因此,要区分它们并不容易。一个值得注意的区别是,WebFlux还支持反应式@RequestBody参数。
-
函数式端点(Functional Endpoint):基于Lambda,轻量级和函数式编程模型。可以将其视为一个小型库或一组可用于路由和处理请求的应用程序。与带注解的控制器的最大区别在于,应用程序负责从开始到结束的请求处理,而不是通过注解声明并被回调。
上面介绍的两种编程模型只是在使用风格上有所不同,最终在反应式底层基础架构运行时是相同的。WebFlux需要底层提供运行时的支持,如前文所述,WebFlux可以在Tomcat、Jetty、Servlet 3.1+容器及非Servlet容器(如Netty和Undertow)上运行。
WebFlux注解式编程模型
前面我们介绍了关于WebFlux的内容,下面我们就看看如何使用注解式Controllers来使用WebFlux。Spring WebFlux提供了基于注释的编程模型,其中@Controller和@RestController组件使用注释来表达请求映射、请求输入、处理异常等。带注释的Controllers具有灵活的方法签名,并且不用继承基类,也不必实现特定的接口。
下面首先通过一个简单的例子来体验注解编程模型:
@RestController
public class PersonHandler {
@GetMapping("/getPerson")
Mono<String> getPerson() {
return Mono.just("jiaduo");
}
}
如上代码,controller类PersonHandler中的getPerson方法的作用是返回一个名称,这里不是简单地返回一个String,而是返回了一个反应式流对象Mono。在Reactor中,每个Mono包含0个或者1个元素。也就是说,WebFlux与Spring MVC的不同之处在于,它返回的都是Reactor库中的反应式类型Mono或者Flux对象。
如果controller方法要返回的元素不止一个怎么办?这时候返回值可以设置为Flux类型:
@RestController
public class PersonHandler {
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng");
}
}
如上代码,getPersonList方法返回了一个Flux流对象,在Reactor库中每个Flux代表0个或者多个对象。
需要注意的是,WebFlux默认运行在Netty服务器上,这时候WebFlux上处理请求的线程模型如下图所示。
【WebFlux线程模型】
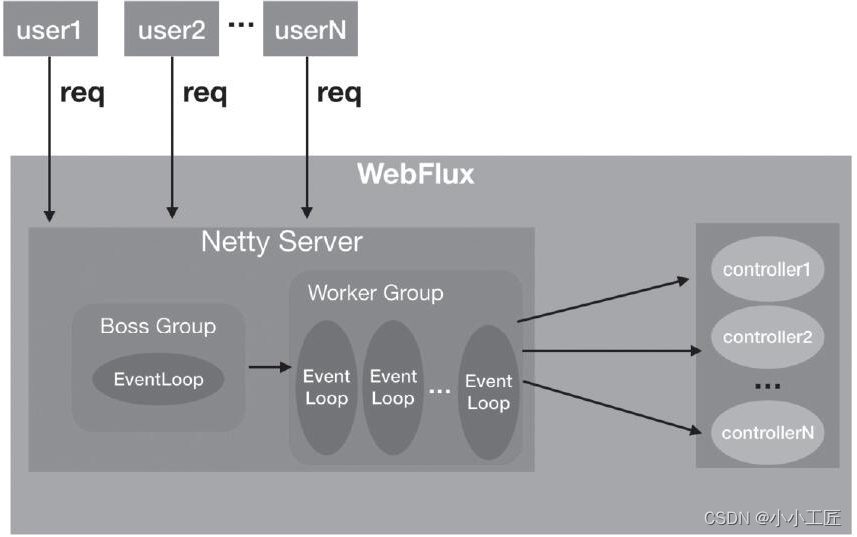
比如,当我们访问http://127.0.0.1:8080/getPersonList时,WebFlux底层的NettyServer的Boss Group线程池内的事件循环就会接收这个请求,然后把完成TCP三次握手的连接channel交给Worker Group中的某一个事件循环线程来进行处理。该事件处理线程会调用对应的controller进行处理(这里是指PersonHandler的getPersonList方法进行处理),也就是说,controller的执行是使用Netty的IO线程进行执行的。如果controller的执行比较耗时,则会把IO线程耗尽,从而不能再处理其他请求。
大家可以把代码修改为如下形式,然后看看执行线程是不是NIO线程。
@RestController
public class PersonHandler {
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng").map(e -> {
System.out.println(Thread.currentThread().getName());
return e;
});
}
启动服务后,会在控制台输出如下结果(注意,这里nio-2中的线程编号“2”是随机的,真正运行时候可能不是2):
reactor-http-nio-2
reactor-http-nio-2
reactor-http-nio-2
由上可知,Controller是在Netty的IO线程上执行的。
为了能够让IO线程及时得到释放,我们可以在反应式类型上施加publishOn运算,让controller逻辑的执行切换到其他线程,以便及时释放IO线程。修改上面代码为如下形式:
@RestController
public class PersonHandler {
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng")
.publishOn(Schedulers.elastic())//1.1 切换到异步线程执行
.map(e -> {//1.2打印调用线程
System.out.println(Thread.currentThread().getName());
return e;
});
}
如上述代码1.1所示,在Flux流上调用了publishOn(Schedulers.elastic())让后续对元素的处理切换到线程池Schedulers.elastic(),然后Netty的IO线程就可以被及时释放了。这时启动服务后,在控制台会输出(注意,这里elastic-2中的线程编号“2”是随机的,真正运行时可能不是2):
elastic-2
elastic-2
elastic-2
由上可知,现在元素处理使用的是elastic线程池中的线程,而不再是Netty IO线程。
另外,线程调度器Schedulers也提供了让我们制定自己的线程池来执行异步任务的功能。修改上面代码为如下形式:
@RestController
public class PersonHandler {
// 1.0创建线程池
private static final ThreadPoolExecutor bizPoolExecutor = new ThreadPoolExecutor(8, 8, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(10));
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng")
.publishOn(Schedulers.fromExecutor(bizPoolExecutor))//1.1 切换到异步线程执行
.map(e -> {//1.2打印调用线程
System.out.println(Thread.currentThread().getName());
return e;
});
}
如上述代码1.0所示,我们创建了自己的线程池,然后使用Schedulers.fromExecutor(bizPoolExecutor)转换我们自己的线程池为WebFlux所需的Scheduler,这样在处理元素时就会使用我们自己的线程池线程进行处理。
WebFlux函数式编程模型
Spring WebFlux包括轻量级的函数式编程模型,其中函数用于路由和处理请求,并且其规范是为不变性而设计的。函数式编程模型是基于注解的编程模型的替代方案,但两者都在相同的Reactive Core基础库上运行。
在WebFlux的函数式编程模型中,使用HandlerFunction处理HTTP请求,Handler Function是一个接收ServerRequest并返回延迟写入结果的(delayed)ServerResponse(即Mono)的函数。HandlerFunction相当于在基于注解的编程模型中标注@Request Mapping注解的方法体。
WebFlux服务器接收请求后,会将请求路由到带有RouterFunction的处理函数,RouterFunction是一个接收ServerRequest并返回延迟的HandlerFunction(即Mono)的函数。当路由函数匹配时,返回一个处理函数;否则返回一个空的Mono流对象。RouterFunction相当于@RequestMapping注解本身,两者的主要区别在于,路由器功能不仅提供数据,还提供行为。
RouterFunctions.route()方法则提供了一个便于创建路由规则的路由构建器,如以下代码所示:
@Configuration
public class FunctionModelConfig {
@Bean
public FunctionPersonHandler handler() {
return new FunctionPersonHandler();
}
@Bean
public RouterFunction<ServerResponse>routerFunction(final FunctionPersonHandler handler) {
RouterFunction<ServerResponse> route = RouterFunctions.route()//1
.GET("/getPersonF",RequestPredicates.accept(MediaType.APPLICATION_JSON), handler::getPerson)//2
.GET("/getPersonListF",RequestPredicates.accept(MediaType.APPLICATION_JSON), handler::getPersonList)//3
.build();//4
return route;
}
}
public class FunctionPersonHandler {
// 1.0创建线程池
private static final ThreadPoolExecutor bizPoolExecutor = new ThreadPoolExecutor(8, 8, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(10));
Mono<ServerResponse> getPersonList(ServerRequest request) {
// 1.根据request查找person列表
Flux<String> personList = Flux.just("jiaduo", "zhailuxu", "guoheng")
.publishOn(Schedulers.fromExecutor(bizPoolExecutor))// 1.1 切换到异步线程执行
.map(e -> {// 1.2打印调用线程
System.out.println(Thread.currentThread().getName());
return e;
});
// 2.返回查找结果
return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(personList, String.class);
}
Mono<ServerResponse> getPerson(ServerRequest request) {
// 1.根据request查找person,
Mono<String> person = Mono.just("jiaduo");
// 2.返回查找结果
return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(person, String.class);
}
}
如上述代码所示,创建了一个FunctionPersonHandler,用来提供不同的Handler-Function对不同请求进行处理。这里getPersonList(ServerRequest request)和getPerson(ServerRequest request)方法就是HandlerFunction。
getPerson方法内创建了一个Mono对象作为查找结果,然后调用ServerResponse.ok()创建一个响应结果,并且设置响应的contentType为JSON,响应体为创建的person对象。与getPersonList方法类似,只不过getPerson方法创建了Flux对象作为响应体内容。
routerFunction方法创建RouterFunction的核心逻辑,其中代码1创建一个Router Function的builder对象;代码2注册GET方式请求的路由,意思是当用户访问/getPersonF路径的请求时,若accept头中匹配JSON类型数据,则使用FunctionPersonHandler类中的getPerson方法进行处理;代码3注册GET方式请求的路由,意思是当用户访问/getPersonListF路径的请求时,若accept头中匹配JSON类型数据,则使用Function-PersonHandler类中的getPersonList方法进行处理。
本地启动服务后,当访问http://127.0.0.1:8080/getPersonListF时,服务控制台会输出类似下面的代码:
pool-2-thread-1
pool-2-thread-2
pool-2-thread-2
由上可知,controller方法是在业务线程内异步执行的,这和注解编程的执行逻辑是一致的。
WebFlux原理浅尝
基于Netty作为服务器来讲解WebFlux的实现原理。
Reactor Netty概述
Netty作为服务器时,其底层是基于Reactor Netty来进行反应式流支持的。Reactor Netty提供基于Netty框架的无阻塞和回压的TCP/HTTP/UDP客户端和服务器。在WebFlux中主要使用其创建的HTTP服务器,Reactor Netty提供易于使用且易于配置的HttpServer类。它隐藏了创建HTTP服务器所需的大部分Netty功能,并添加了Reactive Streams回压。
想要使用Reactor Netty库提供的功能,首先需要通过以下代码将库添加到pom.xml中来导入BOM:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Californium-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
然后需要像往常一样将依赖项添加到相关的reactor项目中(不需要加version标签)。以下代码显示了如何执行此操作:
<dependencies>
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty</artifactId>
</dependency>
</dependencies>
要启动HTTP服务器,必须要创建和配置HttpServer实例。默认情况下,主机(Host)配置为任何本地地址,并且系统在调用绑定操作时可选取临时端口(port)。以下示例显示如何创建HttpServer实例:
import reactor.core.publisher.Mono;
import reactor.netty.DisposableServer;
import reactor.netty.http.server.HttpServer;
public class ReactorNetty {
public static void main(String[] args) {
DisposableServer server = HttpServer.create()//1.创建http服务器
.host("localhost")//2.设置host
.port(8080)//3.设置监听端口
.route(routes -> routes//4.设置路由规则
.get("/hello", (request, response) -> response.sendString(Mono.just("Hello World!")))
.post("/echo", (request, response) -> response.send(request.receive().retain()))
.get("/path/{param}",
(request, response) -> response.sendString(Mono.just(request.param("param"))))
.ws("/ws", (wsInbound, wsOutbound) -> wsOutbound.send(wsInbound.receive().retain())))
.bindNow();
server.onDispose().block();//5.阻塞方式启动服务器,同步等待服务停止
}
}
由上述代码可知:
-
代码1创建了一个待配置的HttpServer。
-
代码2配置HTTP服务的主机。
-
代码3配置HTTP服务的监听端口号。
·代码4配置HTTP服务路由,为访问路径/hello提供GET请求并返回“Hello World!”;为访问路径/echo提供POST请求,并将收到的请求正文作为响应返回;为访问路径/path/{param}提供GET请求并返回path参数的值;将websocket提供给/ws并将接收的传入数据作为传出数据返回。
·代码5调用代码1返回的DisposableServer的onDispose()方法并以阻塞的方式等待服务器关闭。
运行上面代码,在浏览器中输入http://127.0.0.1:8080/hello,若在页面上显示出“Hello World!”,说明我们的HTTP服务器生效了。
WebFlux服务器启动流程
我们结合SpringBoot的启动流程讲解WebFlux服务启动流程,首先我们看一下启动时序图
【WebFlux服务启动时序图】
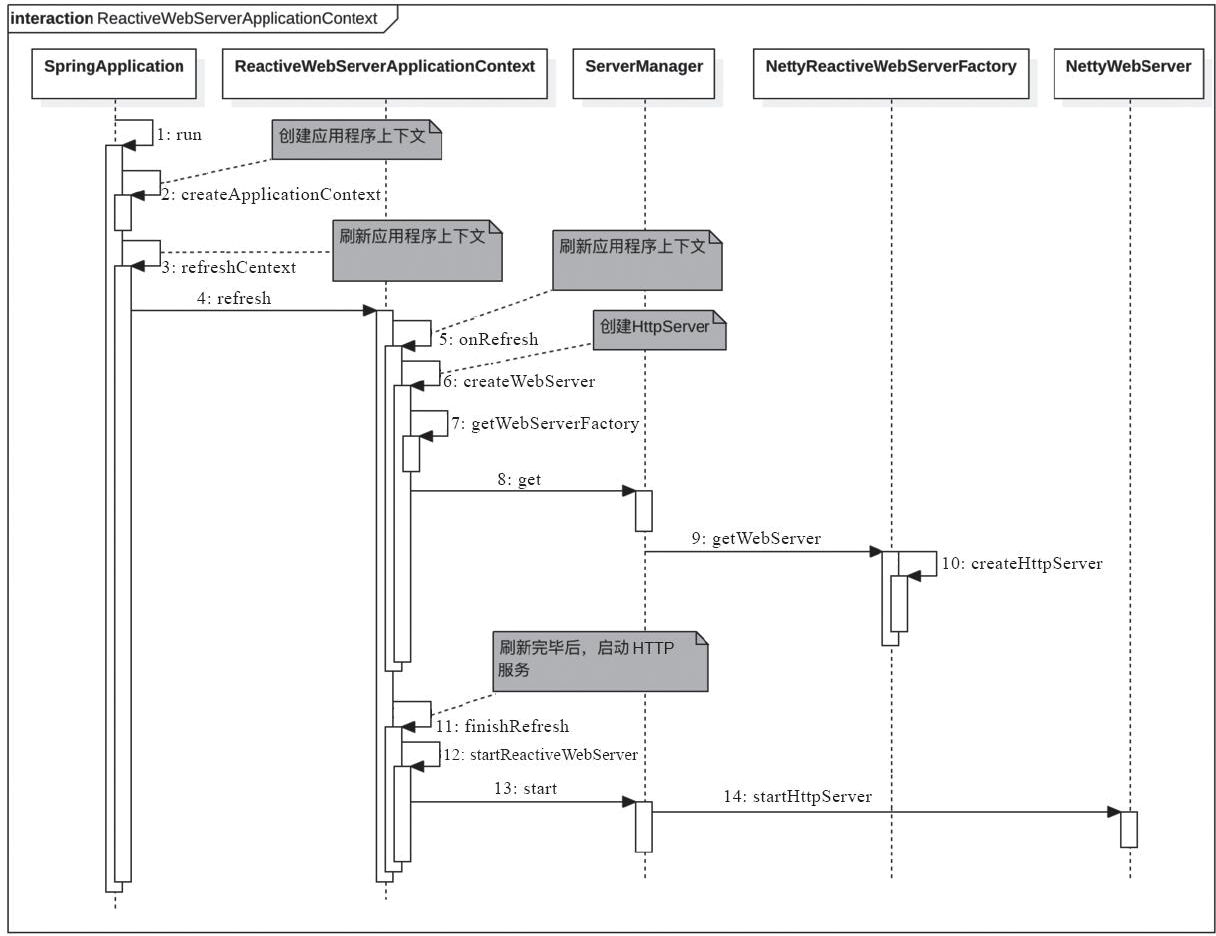
图中的步骤1通过createApplicationContext创建了应用程序上下文AnnotationConfigReactiveWebServerApplicationContext,其代码如下:
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
//a 环境类型
switch (this.webApplicationType) {
case SERVLET://a.1 Web servlet环境
contextClass = Class.forName(DEFAULT_SERVLET_WEB_CONTEXT_CLASS);
break;
case REACTIVE://a.2 Web Reactive环境
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default://a.3 非Web环境
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, "
+ "please specify an ApplicationContextClass",
ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
//默认非Web环境时
public static final String DEFAULT_CONTEXT_CLASS = "org.springframework.context."
+ "annotation.AnnotationConfigApplicationContext";
//web Servlet环境时默认的上下文
public static final String DEFAULT_SERVLET_WEB_CONTEXT_CLASS = "org.springframework.boot."
+ "web.servlet.context.AnnotationConfigServletWebServerApplicationContext";
//反应式Web环境时默认的上下文
public static final String DEFAULT_REACTIVE_WEB_CONTEXT_CLASS = "org.springframework."
+ "boot.web.reactive.context.AnnotationConfigReactiveWebServerApplicationContext";
如上述代码所示,创建容器应用程序上下文时应根据环境类型的不同而创建不同的应用程序上下文。这里我们使用的是反应式Web环境,所以创建的应用程序上下文是AnnotationConfigReactiveWebServerApplicationContext的实例。
那么环境类型webApplicationType是如何确定的呢?其实是在创建SpringApplication的构造函数内确定的:
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
...
this.webApplicationType = WebApplicationType.deduceFromClasspath();
...
}
下面我们看WebApplicationType的deduceFromClasspath方法:
static WebApplicationType deduceFromClasspath() {
//b.判断是不是REACTIVE类型
if (ClassUtils.isPresent(WEBFLUX_INDICATOR_CLASS, null)
&& !ClassUtils.isPresent(WEBMVC_INDICATOR_CLASS, null)
&& !ClassUtils.isPresent(JERSEY_INDICATOR_CLASS, null)) {
return WebApplicationType.REACTIVE;
}
//c.判断是不是非Web类型
for (String className : SERVLET_INDICATOR_CLASSES) {
if (!ClassUtils.isPresent(className, null)) {
return WebApplicationType.NONE;
}
}
//SERVLET环境
return WebApplicationType.SERVLET;
}
//spring mvc 分派器
private static final String WEBMVC_INDICATOR_CLASS = "org.springframework."
+ " web.servlet.DispatcherServlet";
// reactive web分派器
private static final String WEBFLUX_INDICATOR_CLASS = "org."
+ "springframework.web.reactive.DispatcherHandler";
//Jersey Web 项目容器类
private static final String JERSEY_INDICATOR_CLASS = "org.glassfish.jersey.servlet.ServletContainer";
//Servlet容器所需要的类
private static final String[] SERVLET_INDICATOR_CLASSES = { "javax.servlet.Servlet",
"org.springframework.web.context.ConfigurableWebApplicationContext" };
如上述代码所示,deduceFromClasspath方法是根据classpath下是否有对应的Class字节码文件存在来决定当前是什么环境的。
下面我们看图中步骤3是如何创建并启动HTTP服务器的。在Spring上下文刷新的onRefresh阶段调用了createWebServer方法来创建Web服务器,其内部调用getWebServerFactory来获取Web服务器工厂。getWebServerFactory代码如下:
protected ReactiveWebServerFactory getWebServerFactory() {
//d 从bean工厂中获取所有ReactiveWebServerFactory类型的Bean实例的名字
String[] beanNames = getBeanFactory()
.getBeanNamesForType(ReactiveWebServerFactory.class);
//e 不存在则抛出异常
if (beanNames.length == 0) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to missing "
+ "ReactiveWebServerFactory bean.");
}
if (beanNames.length > 1) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to multiple "
+ "ReactiveWebServerFactory beans : "
+ StringUtils.arrayToCommaDelimitedString(beanNames));
}
//f 存在则获取第一个实例
return getBeanFactory().getBean(beanNames[0], ReactiveWebServerFactory.class);
}
如上述代码所示,从应用程序上下文对应的Bean工厂中获取ReactiveWebServerFactory的实例,以便后面创建Web服务器。那么ReactiveWebServerFactory的实现类的实例什么时候注入上下文容器中呢?其实这是借助了Springboot的autoconfigure机制,autoconfigure机制会自动把ReactiveWebServerFactory的实现类NettyReactiveWebServer Factory注入容器内。
具体注入哪个ReactiveWebServerFactory的实现类,是ReactiveWebServerFactoryConfiguration根据autoconfigure机制来做的,其代码如下:
class ReactiveWebServerFactoryConfiguration {
//f.1将NettyReactiveWebServerFactory注入容器
@Configuration
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ HttpServer.class })
static class EmbeddedNetty {
@Bean
public NettyReactiveWebServerFactory nettyReactiveWebServerFactory() {
return new NettyReactiveWebServerFactory();
}
}
//f.2注入TomcatReactiveWebServerFactory实例
@Configuration
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ org.apache.catalina.startup.Tomcat.class })
static class EmbeddedTomcat {
@Bean
public TomcatReactiveWebServerFactory tomcatReactiveWebServerFactory() {
return new TomcatReactiveWebServerFactory();
}
}
//f.3注入JettyReactiveWebServerFactory实例
@Configuration
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ org.eclipse.jetty.server.Server.class })
static class EmbeddedJetty {
@Bean
public JettyReactiveWebServerFactory jettyReactiveWebServerFactory() {
return new JettyReactiveWebServerFactory();
}
}
//f.4注入UndertowReactiveWebServerFactory实例
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ Undertow.class })
static class EmbeddedUndertow {
@Bean
public UndertowReactiveWebServerFactory undertowReactiveWebServerFactory() {
return new UndertowReactiveWebServerFactory();
}
}
}
比如代码f.1,如果当前容器上下文中不存在ReactiveWebServerFactory的实例,并且classpath下存在HttpServer的class文件,则说明当前环境为Reactive环境,则注入NettyReactiveWebServerFactory到容器。
比如代码f.2,如果当前容器上下文中不存在ReactiveWebServerFactory的实例,并且classpath下存在org.apache.catalina.startup.Tomcat的class文件,则说明当前环境为Servlet环境,并且Servlet容器为Tomcat,则将TomcatReactiveWebServerFactory实例注入容器。
找到对应的ReactiveWebServerFactory工厂实例后,如图所示,步骤8创建了ServerManager的实例,代码如下:
public static ServerManager get(ReactiveWebServerFactory factory) {
return new ServerManager(factory);
}
其中ServerManager的构造函数如下:
private ServerManager(ReactiveWebServerFactory factory) {
this.handler = this::handleUninitialized;
this.server = factory.getWebServer(this);
}
由上可知,调用NettyReactiveWebServerFactory的getWebServer方法创建了Web服务器,其代码如下:
public WebServer getWebServer(HttpHandler httpHandler) {
//I
HttpServer httpServer = createHttpServer();
//II
ReactorHttpHandlerAdapter handlerAdapter = new ReactorHttpHandlerAdapter(
httpHandler);
//III
return new NettyWebServer(httpServer, handlerAdapter, this.lifecycleTimeout);
}
如上代码I所示,其通过createHttpServer创建了HTTPServer,其代码如下(使用reactor Netty的API创建了HTTP Server):
private HttpServer createHttpServer() {
return HttpServer.builder().options((options) -> {
options.listenAddress(getListenAddress());
if (getSsl() != null && getSsl().isEnabled()) {
SslServerCustomizer sslServerCustomizer = new SslServerCustomizer(
getSsl(), getSslStoreProvider());
sslServerCustomizer.customize(options);
}
if (getCompression() != null && getCompression().getEnabled()) {
CompressionCustomizer compressionCustomizer = new CompressionCustomizer(
getCompression());
compressionCustomizer.customize(options);
}
applyCustomizers(options);
}).build();
}
代码II创建了与Netty对应的适配器类ReactorHttpHandlerAdapter。
代码III创建了一个NettyWebServer的实例,其包装了适配器和HTTPserver实例。
到这里我们如何创建HTTPServer就讲解完了。
下面我们看图7-3中所示步骤11是如何启动服务的。在应用程序上下文刷新的finishRefresh阶段调用了startReactiveWebServer方法来启动服务,其代码如下:
private WebServer startReactiveWebServer() {
ServerManager serverManager = this.serverManager;
ServerManager.start(serverManager, this::getHttpHandler);
return ServerManager.getWebServer(serverManager);
}
如上代码所示,首先调用了getHttpHandler来获取处理器:
protected HttpHandler getHttpHandler() {
// Use bean names so that we don't consider the hierarchy
String[] beanNames = getBeanFactory().getBeanNamesForType(HttpHandler.class);
if (beanNames.length == 0) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to missing HttpHandler bean.");
}
if (beanNames.length > 1) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to multiple HttpHandler beans : "
+ StringUtils.arrayToCommaDelimitedString(beanNames));
}
return getBeanFactory().getBean(beanNames[0], HttpHandler.class);
}
如上代码所示,其中获取了应用程序上下文中HttpHandler的实现类,这里为HttpWebHandlerAdapter。然后调用ServerManager.start启动了服务,其代码如下:
public static void start(ServerManager manager,
Supplier<HttpHandler> handlerSupplier) {
if (manager != null && manager.server != null) {
manager.handler = handlerSupplier.get();//执行getHttpHandler方法
manager.server.start();//启动服务
}
}
如上代码所示,首先把HttpWebHandlerAdapter实例保存到了ServerManager内部,然后启动ServerManager中的NettyWebServer服务器。NettyWebServer的start方法代码如下:
public void start() throws WebServerException {
//IV具体启动服务
if (this.nettyContext == null) {
try {
this.nettyContext = startHttpServer();
}
...
//开启deamon线程同步等待服务终止
NettyWebServer.logger.info("Netty started on port(s): " + getPort());
startDaemonAwaitThread(this.nettyContext);
}
}
private BlockingNettyContext startHttpServer() {
if (this.lifecycleTimeout != null) {
return this.httpServer.start(this.handlerAdapter, this.lifecycleTimeout);
}
return this.httpServer.start(this.handlerAdapter);
}
如上代码IV所示,其调用了startHttpServer启动服务,然后返回了BlockingNetty Context对象,接着调用了startDaemonAwaitThread开启deamon线程同步等待服务终止,其代码如下:
private void startDaemonAwaitThread(BlockingNettyContext nettyContext) {
//启动线程
Thread awaitThread = new Thread("server") {
@Override
public void run() {
//同步阻塞服务停止
nettyContext.getContext().onClose().block();
}
};
//设置线程为demaon,并启动
awaitThread.setContextClassLoader(getClass().getClassLoader());
awaitThread.setDaemon(false);
awaitThread.start();
}
这里之所以开启线程来异步等待服务终止,是因为这样不会阻塞调用线程,如果调用线程被阻塞了,则整个SpringBoot应用就运行不起来了。
WebFlux一次服务调用流程
前面我们说了WebFlux服务启动流程,本节我们讲解一次服务调用流程,以controller PersonHandler中的getPerson方法调用流程为例。
当我们在浏览器敲入http://127.0.0.1:8080/getPerson时,会向WebFlux中的Netty服务器发起请求,服务器中的Boss监听线程会接收该请求,并在完成TCP三次握手后,把连接套接字通道注册到worker线程池的某个NioEventLoop中来处理,然后该NioEventLoop中对应的线程就会轮询该套接字上的读写事件并进行处理。下面我们来看其时序图,如下图所示。
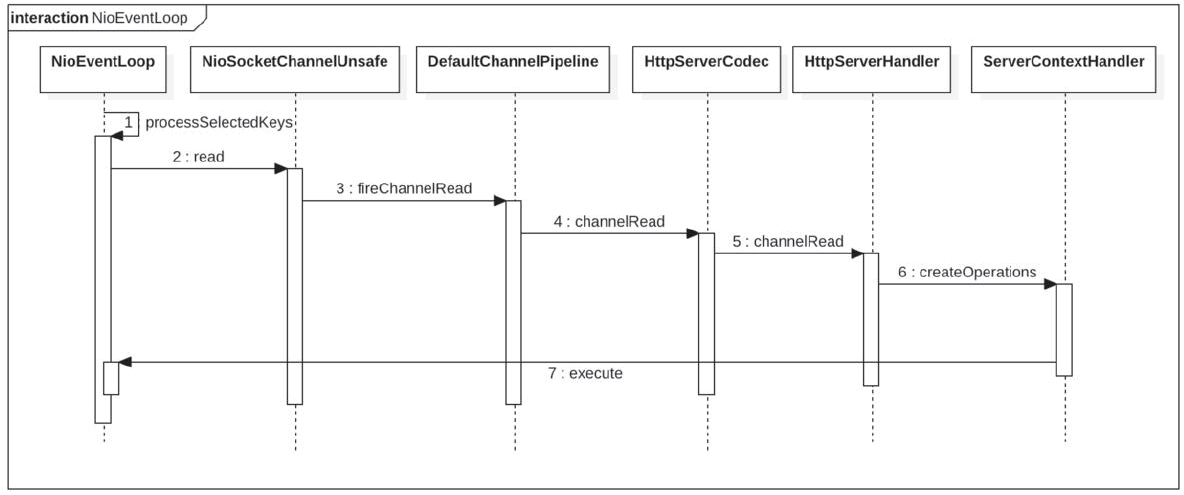
【WebFlux一次服务调用流程】
如图所示,当注册到worker线程池的NioEventLoop上的连接套接字有读事件后,会调用processSelectedKeys方法进行处理,然后把读取的数据通过与该通道对应的管道DefaultChannelPipeline传播到注册的事件处理器进行处理。这里处理器HttpServerCodec负责把二进制流解析为HTTP请求报文,然后传递到管道后面的处理器HttpServerHandler中,HttpServerHandler会调用ServerContextHandler的createOperations方法,通过代码“channel.eventLoop().execute(op::onHandlerStart);”把ChannelOperations的onHandlerStart方法作为任务提交到与当前通道对应的NioEventLoop管理的队列中。下面我们看NioEventLoop中的线程是如何执行该任务的。onHandlerStart代码如下:
protected void onHandlerStart() {
applyHandler();
}
protected final void applyHandler() {
try {
//1.调用适配器ReactorHttpHandlerAdapter的apply方法
Mono.fromDirect(handler.apply((INBOUND) this, (OUTBOUND) this))
.subscribe(this);
}
catch (Throwable t) {
channel.close();
}
}
如上述代码1所示,调用适配器ReactorHttpHandlerAdapter的apply方法来具体处理请求,其代码如下:
public Mono<Void> apply(HttpServerRequest request, HttpServerResponse response) {
ServerHttpRequest adaptedRequest;
ServerHttpResponse adaptedResponse;
try {
//2.创建与reactor对应的请求、响应对象
adaptedRequest = new ReactorServerHttpRequest(request, BUFFER_FACTORY);
adaptedResponse = new ReactorServerHttpResponse(response, BUFFER_FACTORY);
}
catch (URISyntaxException ex) {
...
response.status(HttpResponseStatus.BAD_REQUEST);
return Mono.empty();
}
...
//3. 这里httpHandler为ServerManager
return this.httpHandler.handle(adaptedRequest, adaptedResponse)
.doOnError(ex -> logger.warn("Handling completed with error: " + ex.getMessage()))
.doOnSuccess(aVoid -> logger.debug("Handling completed with success"));
}
然后我们看代码3所示的ServerManager的handle方法:
public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) {
//4.这里handler为HttpWebHandlerAdapter
return this.handler.handle(request, response);
}
接着调用HttpWebHandlerAdapter的handle方法,其代码如下:
public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) {
//5.创建服务交换对象
ServerWebExchange exchange = createExchange(request, response);
//6.这里getDelegate()为DispatcherHandler
return getDelegate().handle(exchange)
.onErrorResume(ex -> handleFailure(request, response, ex))
.then(Mono.defer(response::setComplete));
}
protected ServerWebExchange createExchange(ServerHttpRequest request, ServerHttpResponse response) {
return new DefaultServerWebExchange(request, response, this.sessionManager,
getCodecConfigurer(), getLocaleContextResolver(), this.applicationContext);
}
最后调用分派器DispatcherHandler的handle方法进行路由:
public Mono<Void> handle(ServerWebExchange exchange) {
...
if (this.handlerMappings == null) {
return Mono.error(HANDLER_NOT_FOUND_EXCEPTION);
}
//7.查找对应的controller进行处理
return Flux.fromIterable(this.handlerMappings)//7.1获取所有处理器映射
.concatMap(mapping -> mapping.getHandler(exchange))//7.2转换映射,获取处理器
.next()//7.3获取第一个元素
.switchIfEmpty(Mono.error(HANDLER_NOT_FOUND_EXCEPTION))//7.4不存在处理器
.flatMap(handler -> invokeHandler(exchange, handler))//7.5使用处理器进行处理
.flatMap(result -> handleResult(exchange, result));//7.6处理处理器处理的结果
}
上述代码使用所有请求处理器映射作为Flux流的数据源,查找与指定请求对应的处理器。
如果没有找到,则使用Mono.error(HANDLER_NOT_FOUND_EXCEPTION)创建一个错误信息作为元素;
如果找到了,则调用invokeHandler方法进行处理,处理完毕调用handleResult对结果进行处理。这里我们找到了与getPerson对应的处理器PersonHandler,则invokeHandler内会反射调用PersonHandler的getPerson方法进行执行,然后把结果交给handleResult写回响应对象。
WebFlux的适用场景
既然Spring 5中推出了WebFlux,那么我们做项目时到底选择使用Spring MVC还是WebFlux?
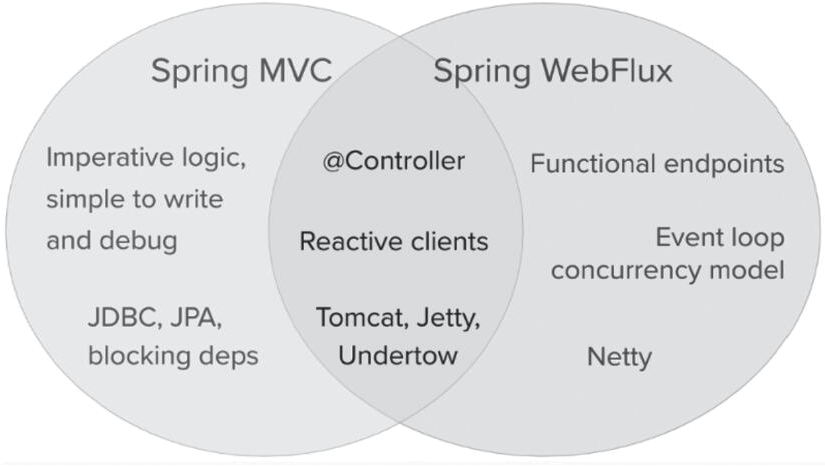
这是一个自然会想到的问题,但却是不合理的。因为两者的存在并不是矛盾的,利用两者可扩大我们开发时可用选项的范围。两者的设计是为了保持连续性和一致性,它们可以并排使用,每一方的反馈都有利于双方。下图所示显示了两者之间的关系、共同点以及各自的特性。
【WebFlux与Servlet对比】
建议
关于是选择Spring MVC还是WebFlux,Spring5官方文档给出了几点建议:
-
如果你的Spring MVC应用程序运行正常,则无须更改。命令式编程是编写、理解和调试代码的最简单方法。
-
如果你已使用非阻塞Web栈,则可以考虑使用WebFlux。因为Spring WebFlux提供与此相同的执行模型优势,并且提供了可用的服务器选择(Netty、Tomcat、Jetty、Undertow和Servlet 3.1+容器),还提供了可选择的编程模型(带注解的controller和函数式Web端点),以及可选择的反应库(Reactor、RxJava或其他)。
-
如果你对与Java 8 Lambdas或Kotlin一起使用的轻量级、功能性Web框架感兴趣,则可以使用Spring WebFlux函数式Web端点。对于较小的应用程序或具有较低复杂要求的微服务而言,这也是一个不错的选择,可以让你从更高的透明度和控制中受益。
-
在微服务架构中,你可以将应用程序与Spring MVC、Spring WebFlux控制器、Spring WebFlux函数式端点混合使用。在两个框架中支持相同的基于注解的编程模型,可以更轻松地重用知识,同时为正确的工作选择合适的工具。
-
评估应用程序的一种简单方法是检查其依赖性。如果你要使用阻塞持久性API(JPA,JDBC)或网络API,则Spring MVC至少是常见体系结构的最佳选择。从技术上讲,Reactor和RxJava都可以在单独的线程上执行阻塞调用,但是你无法充分利用非阻塞的Web技术栈。
-
如果你有一个调用远程服务的Spring MVC应用程序,则可尝试使用反应式WebClient。你可以直接从Spring MVC控制器方法返回反应式类型(Reactor、RxJava或其他)。每次调用的延迟或调用之间的相互依赖性越大,其益处就越大。Spring MVC控制器也可以调用其他反应式组件。
小结
Spring 5.0引入的新的异步非阻塞的WebFlux技术栈,其与Servlet技术栈是并行存在的。WebFlux从规范上支持异步处理,基于Reactor库天然支持反应式编程,并且其使用少量固定线程来实现系统可伸缩性