前言
大家好,我是小哈~
本文节选自小哈写的《Mybatis Plus 教程》中的批量新增一节,旨在帮助大家如何在 Mybatis Plus 中,实现 MySQL 真实的批量新增,而不是伪批量新增。
最近,小哈在带小伙伴做 前后端分离项目,手摸手教学,后端 + 前端全栈开发,从 0 到 1 手敲,1v1 答疑,直到项目上线,后续上新更多项目 , 戳我加入
TIP : 教程发布在个站:犬小哈教程 www.quanxiaoha.com 上,欢迎围观。
什么是批量插入?优势在哪里?
先抛出一个问题:假设老板给你下了个任务,向数据库中添加 100 万条数据,并且不能耗时太久!
通常来说,我们向 MySQL 中新增一条记录,SQL 语句类似如下:
INSERT INTO `t_user` (`name`, `age`, `gender`) VALUES ('犬小哈0', 0, 1);如果你需要添加 100 万条数据,就需要多次执行此语句,这就意味着频繁地 IO 操作(网络 IO、磁盘 IO),并且每一次数据库执行 SQL 都需要进行解析、优化等操作,都会导致非常耗时。
幸运的是,MySQL 支持一条 SQL 语句可以批量插入多条记录,格式如下:
INSERT INTO `t_user` (`name`, `age`, `gender`) VALUES ('犬小哈0', 0, 1), ('犬小哈1', 0, 1), ('犬小哈3', 0, 1);和常规的 INSERT 语句不同的是,VALUES 支持多条记录,通过 , 逗号隔开。这样,可以实现一次性插入多条记录。
数据量不多的情况下,常规 INSERT 和批量插入性能差距不大,但是,一旦数量级上去后,执行耗时差距就拉开了,在后面我们会实测一下它们之间的耗时对比。
表与实体类
先创建一个测试表 t_user, 执行脚本如下:
DROP TABLE IF EXISTS user;
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男',
PRIMARY KEY (`id`)
) COMMENT = '用户表';再定义一个名为 User 实体类:
/**
* @author: 犬小哈
* @from: 公众号:小哈学Java, 网站:www.quanxiaoha.com
* @date: 2022-12-13 14:13
* @version: v1.0.0
* @description: TODO
**/
@Data
@TableName("t_user")
public class User {
/**
* 主键 ID, @TableId 注解定义字段为表的主键,type 表示主键类型,IdType.AUTO 表示随着数据库 ID 自增
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}TIP:
@Data是 Lombok 注解,偷懒用的,加上它即可免写繁杂的getXXX/setXXX相关方法,不了解的小伙伴可自行搜索一下如何使用。
Mybatis Plus 伪批量插入
在前面《新增数据》小节中,我们已经知道了 Mybatis Plus 内部封装的批量插入 savaBatch() 是个假的批量插入,示例代码如下:
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setName("犬小哈" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
// 批量插入
boolean isSuccess = userService.saveBatch(users);
System.out.println("isSuccess:" + isSuccess);通过打印实际执行 SQL , 我们发现还是一条一条的执行 INSERT:
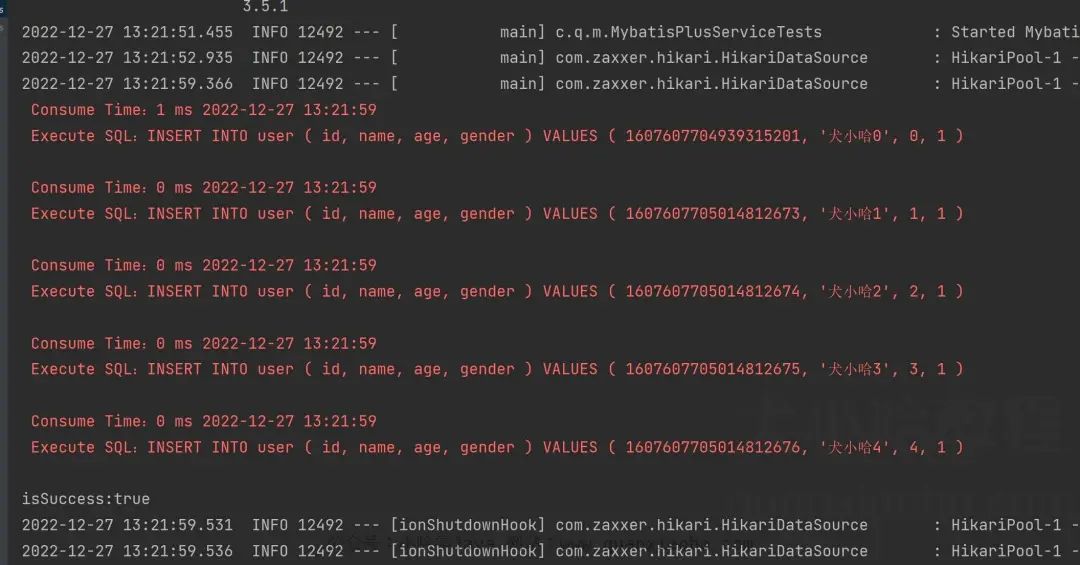
并且还带着大家看了内部实现的源码,这种方式比起自己 for 循环一条一条 INSERT 插入数据性能要更高,原因是在会话这块做了优化,虽然实际执行并不是真的批量插入。
利用 SQL 注入器实现真的批量插入
接下来,小哈就手把手带你通过 Mybatis Plus 框架的 SQL 注入器实现一个真的批量插入。
示例项目结构
先贴一张示例项目的结构:
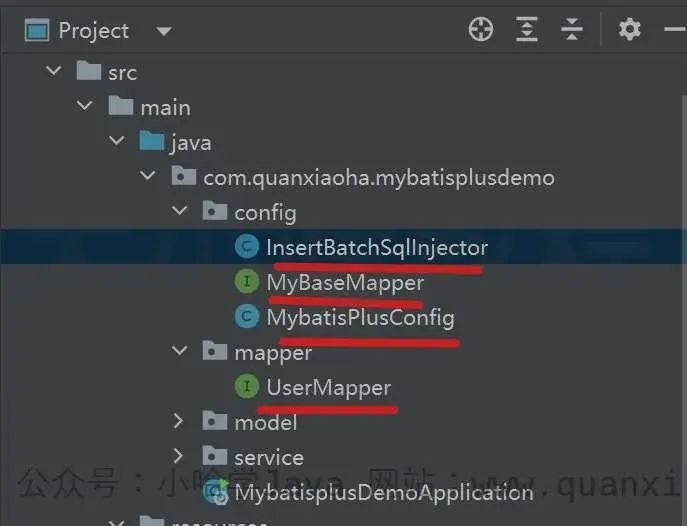
注意看我红线标注的部分,主要关注这 4 个类与接口。
新建批量插入 SQL 注入器
在工程 config 目录下创建一个 SQL 注入器 InsertBatchSqlInjector :
/**
* @author: 犬小哈
* @from: 公众号:小哈学Java, 网站:www.quanxiaoha.com
* @date: 2023-01-05 14:42
* @version: v1.0.0
* @description: 批量插入 SQL 注入器
**/
public class InsertBatchSqlInjector extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {
// super.getMethodList() 保留 Mybatis Plus 自带的方法
List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo);
// 添加自定义方法:批量插入,方法名为 insertBatchSomeColumn
methodList.add(new InsertBatchSomeColumn());
return methodList;
}
}说说 InsertBatchSomeColumn
InsertBatchSomeColumn 是 Mybatis Plus 内部提供的默认批量插入,只不过这个方法作者只在 MySQL 数据测试过,所以没有将它作为通用方法供外部调用,注意看注释:
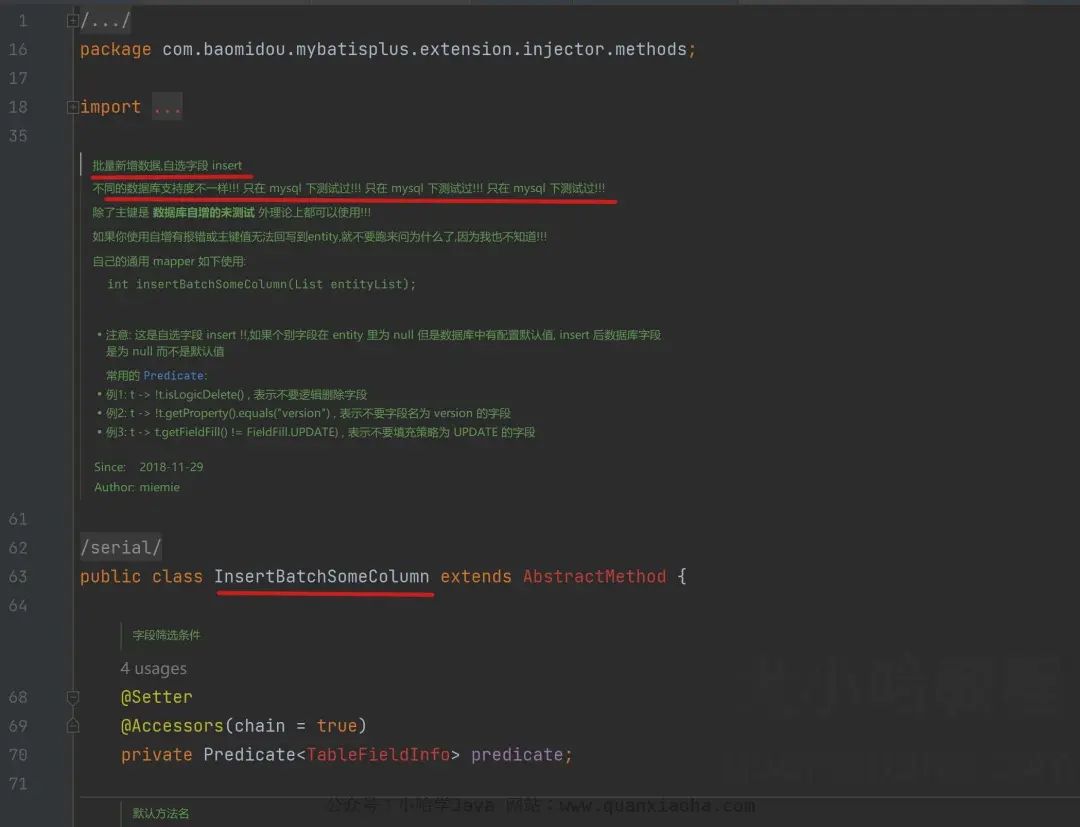
源码复制出来,如下:
/**
* 批量新增数据,自选字段 insert
* <p> 不同的数据库支持度不一样!!! 只在 mysql 下测试过!!! 只在 mysql 下测试过!!! 只在 mysql 下测试过!!! </p>
* <p> 除了主键是 <strong> 数据库自增的未测试 </strong> 外理论上都可以使用!!! </p>
* <p> 如果你使用自增有报错或主键值无法回写到entity,就不要跑来问为什么了,因为我也不知道!!! </p>
* <p>
* 自己的通用 mapper 如下使用:
* <pre>
* int insertBatchSomeColumn(List<T> entityList);
* </pre>
* </p>
*
* <li> 注意: 这是自选字段 insert !!,如果个别字段在 entity 里为 null 但是数据库中有配置默认值, insert 后数据库字段是为 null 而不是默认值 </li>
*
* <p>
* 常用的 {@link Predicate}:
* </p>
*
* <li> 例1: t -> !t.isLogicDelete() , 表示不要逻辑删除字段 </li>
* <li> 例2: t -> !t.getProperty().equals("version") , 表示不要字段名为 version 的字段 </li>
* <li> 例3: t -> t.getFieldFill() != FieldFill.UPDATE) , 表示不要填充策略为 UPDATE 的字段 </li>
*
* @author miemie
* @since 2018-11-29
*/
@SuppressWarnings("serial")
public class InsertBatchSomeColumn extends AbstractMethod {
/**
* 字段筛选条件
*/
@Setter
@Accessors(chain = true)
private Predicate<TableFieldInfo> predicate;
/**
* 默认方法名
*/
public InsertBatchSomeColumn() {
// 方法名
super("insertBatchSomeColumn");
}
/**
* 默认方法名
*
* @param predicate 字段筛选条件
*/
public InsertBatchSomeColumn(Predicate<TableFieldInfo> predicate) {
super("insertBatchSomeColumn");
this.predicate = predicate;
}
/**
* @param name 方法名
* @param predicate 字段筛选条件
* @since 3.5.0
*/
public InsertBatchSomeColumn(String name, Predicate<TableFieldInfo> predicate) {
super(name);
this.predicate = predicate;
}
@SuppressWarnings("Duplicates")
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
SqlMethod sqlMethod = SqlMethod.INSERT_ONE;
List<TableFieldInfo> fieldList = tableInfo.getFieldList();
String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true, false) +
this.filterTableFieldInfo(fieldList, predicate, TableFieldInfo::getInsertSqlColumn, EMPTY);
String columnScript = LEFT_BRACKET + insertSqlColumn.substring(0, insertSqlColumn.length() - 1) + RIGHT_BRACKET;
String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true, ENTITY_DOT, false) +
this.filterTableFieldInfo(fieldList, predicate, i -> i.getInsertSqlProperty(ENTITY_DOT), EMPTY);
insertSqlProperty = LEFT_BRACKET + insertSqlProperty.substring(0, insertSqlProperty.length() - 1) + RIGHT_BRACKET;
String valuesScript = SqlScriptUtils.convertForeach(insertSqlProperty, "list", null, ENTITY, COMMA);
String keyProperty = null;
String keyColumn = null;
// 表包含主键处理逻辑,如果不包含主键当普通字段处理
if (tableInfo.havePK()) {
if (tableInfo.getIdType() == IdType.AUTO) {
/* 自增主键 */
keyGenerator = Jdbc3KeyGenerator.INSTANCE;
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
} else {
if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(this.methodName, tableInfo, builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
}
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sql, modelClass);
return this.addInsertMappedStatement(mapperClass, modelClass, getMethod(sqlMethod), sqlSource, keyGenerator, keyProperty, keyColumn);
}
}配置 SQL 注入器
在 config 包下创建 MybatisPlusConfig 配置类:
/**
* @Author: 犬小哈
* @From: 公众号:小哈学Java, 网站:www.quanxiaoha.com
* @Date: 2022-12-15 18:29
* @Version: v1.0.0
* @Description: TODO
**/
@Configuration
@MapperScan("com.quanxiaoha.mybatisplusdemo.mapper")
public class MybatisPlusConfig {
/**
* 自定义批量插入 SQL 注入器
*/
@Bean
public InsertBatchSqlInjector insertBatchSqlInjector() {
return new InsertBatchSqlInjector();
}
}新建 MyBaseMapper
在 config 包下创建 MyBaseMapper 接口,让其继承自 Mybatis Plus 提供的 BaseMapper, 并定义批量插入方法:
/**
* @author: 犬小哈
* @from: 公众号:小哈学Java, 网站:www.quanxiaoha.com
* @date: 2022-12-13 14:13
* @version: v1.0.0
* @description: TODO
**/
public interface MyBaseMapper<T> extends BaseMapper<T> {
// 批量插入
int insertBatchSomeColumn(@Param("list") List<T> batchList);
}注意:方法名必须为
insertBatchSomeColumn, 和InsertBatchSomeColumn内部定义好的方法名保持一致。
新建 UserMapper
在 mapper 包下创建 UserMapper 接口,注意继承刚刚自定义的 MyBaseMapper, 而不是 BaseMapper :
/**
* @author: 犬小哈
* @from: 公众号:小哈学Java, 网站:www.quanxiaoha.com
* @date: 2022-12-13 14:13
* @version: v1.0.0
* @description: TODO
**/
public interface UserMapper extends MyBaseMapper<User> {
}测试批量插入
完成上面这些工作后,就可以使用 Mybatis Plus 提供的批量插入功能了。我们新建一个单元测试,并注入 UserMapper :
@Autowired
private UserMapper userMapper;单元测试如下:
@Test
void testInsertBatch() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 3; i++) {
User user = new User();
user.setName("犬小哈" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
userMapper.insertBatchSomeColumn(users);
}控制台实际执行 SQL 如下:
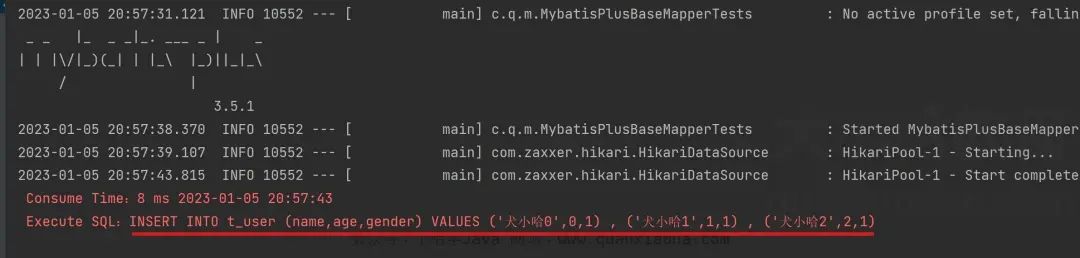
可以看到这次是真实的批量插入了,舒服了~
性能对比
我们来测试一下插入 105000 条数据,分别使用 for 循环插入数据、savaBatch() 伪批量插入、与真实批量插入三种模式,看看耗时差距多少。
小哈这里的机器配置如下:

for 循环插入
单元测试代码如下:
@Test
void testInsert1() {
// 总耗时:722963 ms, 约 12 分钟
long start = System.currentTimeMillis();
for (int i = 0; i < 105000; i++) {
User user = new User();
user.setName("犬小哈" + i);
user.setAge(i);
user.setGender(1);
userMapper.insert(user);
}
System.out.println(String.format("总耗时:%s ms", System.currentTimeMillis() - start));
}savaBatch() 伪批量插入
单元测试代码如下:
@Test
void testInsert2() {
// 总耗时:95864 ms, 约一分钟30秒左右
long start = System.currentTimeMillis();
List<User> users = new ArrayList<>();
for (int i = 0; i < 105000; i++) {
User user = new User();
user.setName("犬小哈" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
userService.saveBatch(users);
System.out.println(String.format("总耗时:%s ms", System.currentTimeMillis() - start));
}真实批量插入
注意,真实业务场景下,也不可能会将 10 万多条记录组装成一条 SQL 进行批量插入,因为数据库对执行 SQL 大小是有限制的(这个数值可以自行设置),还是需要分片插入,比如取 1000 条执行一次批量插入,单元测试代码如下:
@Test
void testInsertBatch1() {
// 总耗时:6320 ms, 约 6 秒
long start = System.currentTimeMillis();
List<User> users = new ArrayList<>();
for (int i = 0; i < 1006; i++) {
User user = new User();
user.setName("犬小哈" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
// 分片插入(每 1000 条执行一次批量插入)
int batchSize = 1000;
int total = users.size();
// 需要执行的次数
int insertTimes = total / batchSize;
// 最后一次执行需要提交的记录数(防止可能不足 1000 条)
int lastSize = batchSize;
if (total % batchSize != 0) {
insertTimes++;
lastSize = total%batchSize;
}
for (int j = 0; j < insertTimes; j++) {
if (insertTimes == j+1) {
batchSize = lastSize;
}
// 分片执行批量插入
userMapper.insertBatchSomeColumn(users.subList(j*batchSize, (j*batchSize+batchSize)));
}
System.out.println(String.format("总耗时:%s ms", System.currentTimeMillis() - start));
}耗时对比
| 方式 | 总耗时 |
|---|---|
for 循环插入 | 722963 ms, 约 12 分钟 |
savaBatch() 伪批量插入 | 95864 ms, 约一分钟30秒左右 |
| 真实批量插入 | 6320 ms, 约 6 秒 |
耗时对比非常直观,在大批量数据新增的场景下,批量插入性能最高。
结语
本小节中,我们学习了如何通过 Mybatis Plus 的 SQL 注入器实现真实的批量插入,同时最后还对比了三种不同方式插入 10 万多数据的耗时,很直观的看到在海量数据场景下,批量插入的性能是最强的。
👉 欢迎加入小哈的Java项目实战知识星球,手摸手带你做前后端分离项目,手摸手教学,后端 + 前端包办,从 0 到 1 手敲,1v1 答疑,直到项目上线,后续上新更多项目。

1. 前后端分离,开源的 Spring Boot + Vue 3.2 的博客,泰裤辣!

最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦






![[C++学习] 多进程通信共享内存](https://img-blog.csdnimg.cn/20750f310908451e9a1d50f1bad475c0.png#pic_center)