Tomcat架构设计&源码剖析
Tomcat 架构设计
Tomcat的功能(需求)
浏览器发给服务端的是一个 HTTP 格式的请求,HTTP 服务器收到这个请求后,需要调用服务端程序来处理,所谓的服务端程序就是你写的 Java 类,一般来说不同的请求需要由不同的 Java 类来处理。
那么问题来了,HTTP 服务器怎么知道要调用哪个 Java 类的哪个方法呢?

- HTTP 服务器直接调用具体业务类,它们是紧耦合的。
解决:HTTP 服务器不直接调用业务类,而是把请求交给容器来处理,容器通过 Servlet 接口调用业务类。因此 Servlet 接口和 Servlet 容器的出现,达到了 HTTP 服务器与业务类解耦的目的。

Tomcat两个非常重要的功能(身份)
- Http服务器功能:Socket通信(TCP/IP)、解析Http报文
- Servlet容器功能:有很多Servlet(自带系统级Servlet+自定义Servlet),Servlet处理具体的业务逻辑
Tomcat的架构(设计实现)
1. 需求
1 Tomcat的需求是要实现 2 个核心功能:
- 处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
- 加载和管理 Servlet,以及具体处理 Request 请求。
2. Tomcat架构设计
基于Tomcat需求,所以 Tomcat 设计了两个核心组件连接器(Connector)和容器(Container)来分别做这两件事情。
连接器负责对外交流,容器负责内部处理。
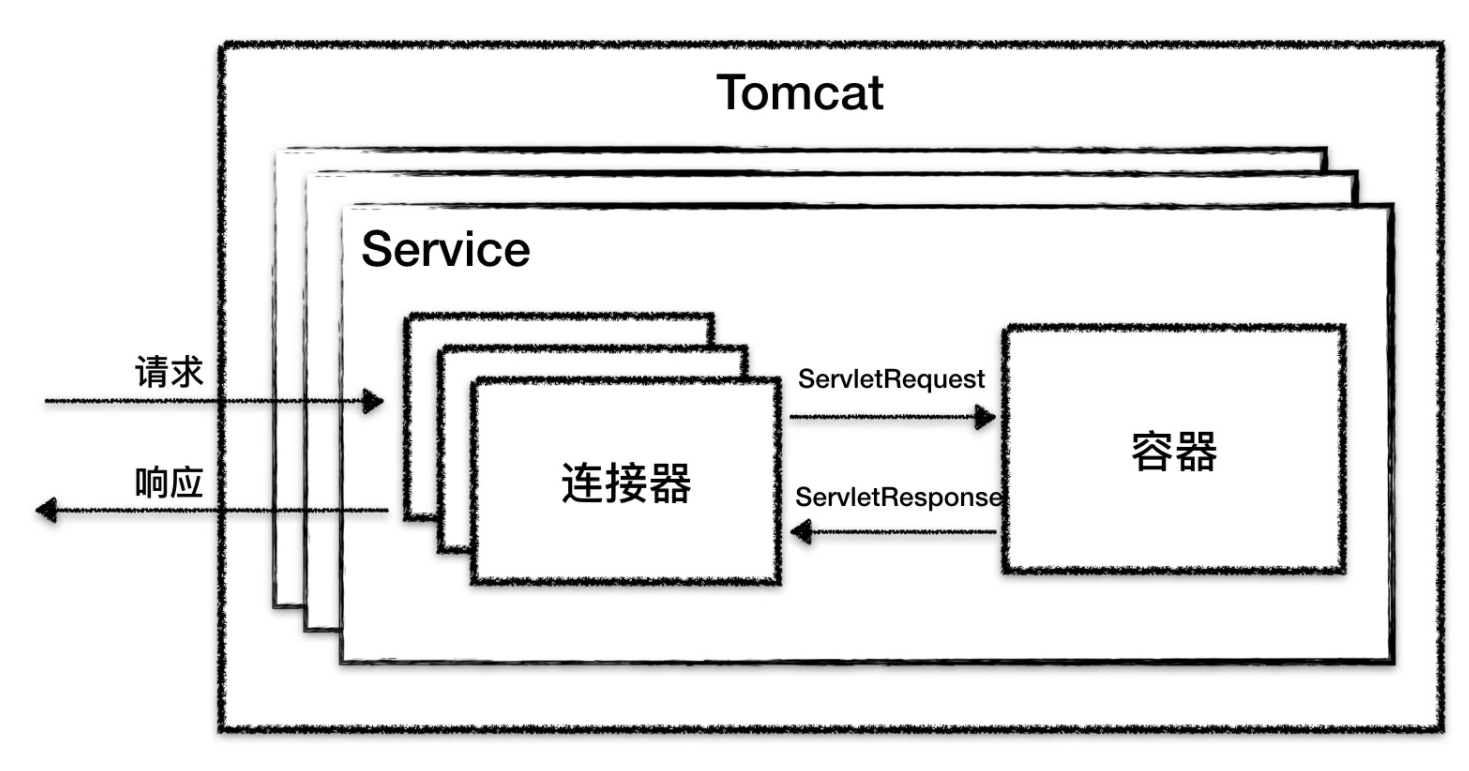
Tomcat中一个容器可能对接多个连接器,每一个连接器都对应某种协议某种IO模型,Tomcat将多个连接器和单个容器组成一个service组件,一个tomcat中可能存在多个Service组件
- Connector:将不同协议不同IO模型的请求转换为标准的标准的 ServletRequest 对象交给容器处理。
- Container:Container本质上是一个Servlet容器,负责servelt的加载和管理,处理请求ServletRequest,并返回标准的 ServletResponse 对象给连接器。
3. 连接器是如何设计的?
3.1 铺垫:支持协议&IO模型
铺垫:Tomcat 是支持多种 I/O 模型和应用层协议的
Tomcat 支持的 I/O 模型有:
- NIO:非阻塞 I/O,采用 Java NIO 类库实现
- NIO.2:异步 I/O,采用 JDK 7 最新的 NIO.2 类库实现
- APR:采用 Apache 可移植运行库实现,是 C/C++ 编写的本地库
Tomcat 支持的应用层协议有:
- HTTP/1.1:这是大部分 Web 应用采用的访问协议
- AJP:用于和 Web 服务器集成(如 Apache)
- HTTP/2:HTTP 2.0 大幅度的提升了 Web 性能
3.2 连接器架构分析
Tomcat 为了实现支持多种 I/O 模型和应用层协议,一个容器可能对接多个连接器,就好比一个房间有多个门。但是单独的连接器或者容器都不能对外提供服务,需要把它们组装起来才能工作,组装后这个整体叫作 Service 组件。这里请注意,Service 本身没有做什么重要的事情,只是在连接器和容器外面多包了一层,把它们组装在一起。Tomcat 内可能有多个 Service,这样的设计也是出于灵活性的考虑。通过在 Tomcat 中配置多个 Service,可以实现通过不同的端口号来访问同一台机器上部署的不同应用。
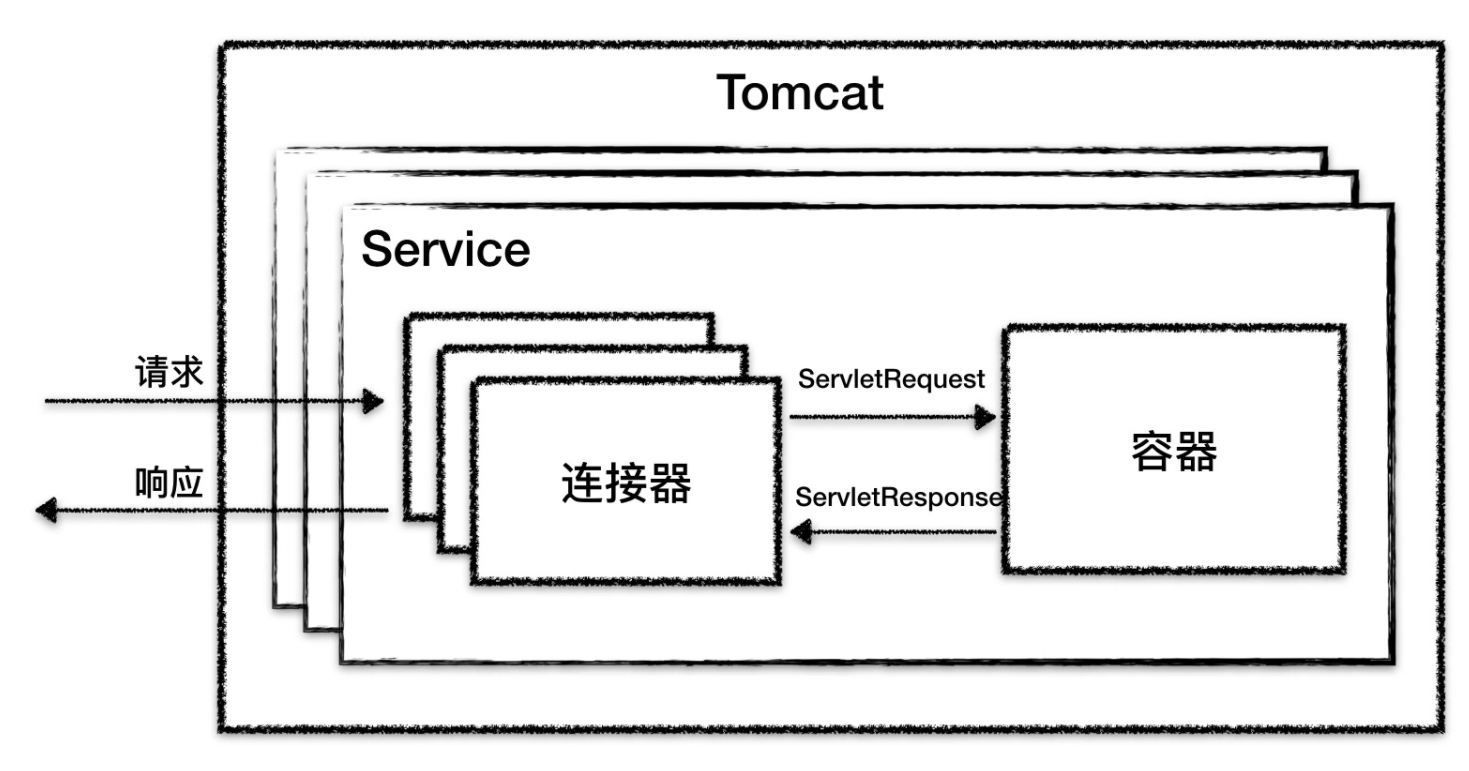
从图上可以看到,最顶层是 Server,这里的 Server 指的就是一个 Tomcat 实例。一个 Server 中有一个或者多个 Service,一个 Service 中有多个连接器和一个容器。连接器与容器之间通过标准的 ServletRequest 和 ServletResponse 通信。
3.3 核心功能
连接器对 Servlet 容器屏蔽了协议及 I/O 模型等的区别,无论是 HTTP 还是 AJP,在容器中获取到的都是一个标准的 ServletRequest 对象。我们可以把连接器的功能需求进一步细化,比如:
- 监听网络端口。
- 接受网络连接请求。读取网络请求字节流。
- 根据具体应用层协议(HTTP/AJP)解析字节流,生成统一的 Tomcat Request 对象。
- 将 Tomcat Request 对象转成标准的 ServletRequest。
- 调用 Servlet 容器,得到 ServletResponse。
- 将 ServletResponse 转成 Tomcat Response 对象。
- 将 Tomcat Response 转成网络字节流。
- 将响应字节流写回给浏览器。
3.4 通用架构设计
需求列清楚后,我们要考虑的下一个问题是,连接器应该有哪些子模块?优秀的模块化设计应该考虑高内聚、低耦合。
- 高内聚是指相关度比较高的功能要尽可能集中,不要分散。
- 低耦合是指两个相关的模块要尽可能减少依赖的部分和降低依赖的程度,不要让两个模块产生强依赖。
通过分析连接器的详细功能列表,发现连接器需要完成 3 个高内聚的功能:
- 网络通信
- 应用层协议解析
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化
因此 Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 Endpoint、Processor 和 Adapter。
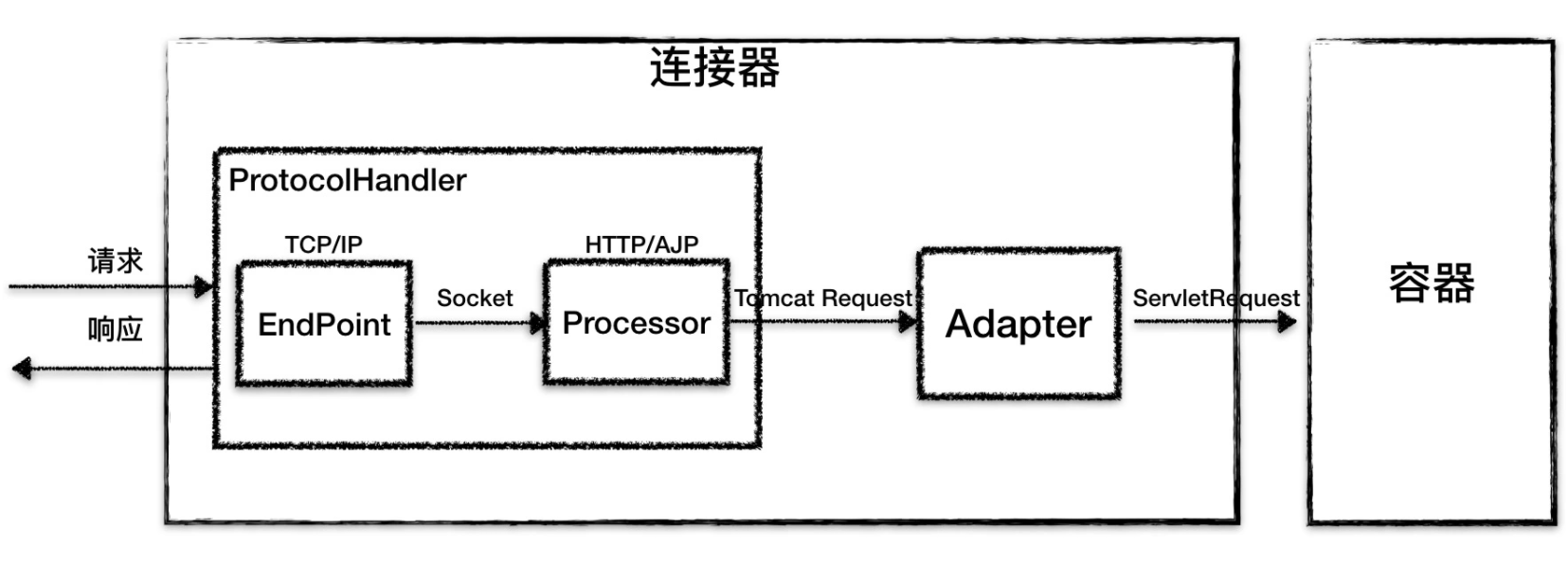
由于 I/O 模型和应用层协议可以自由组合,比如 NIO + HTTP 或者 NIO.2 + AJP。Tomcat 的设计者将网络通信和应用层协议解析放在一起考虑,设计了一个叫 ProtocolHandler 的接口来封装这两种变化点
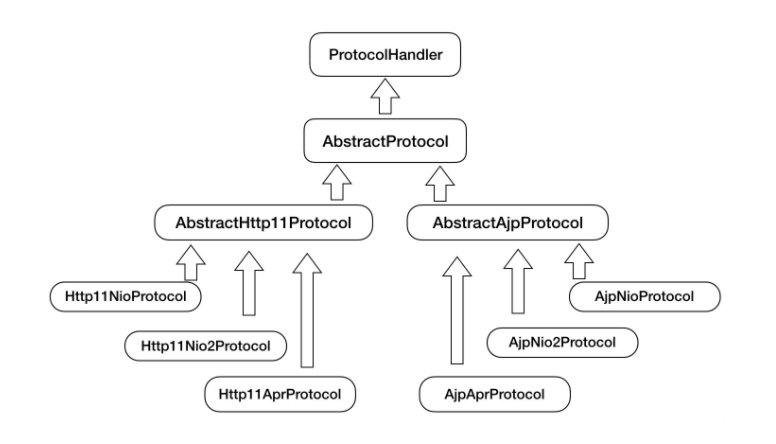
通过图清晰地看到它们的继承和层次关系,这样设计的目的是尽量将稳定的部分放到抽象基类,同时每一种 I/O 模型和协议的组合都有相应的具体实现类,我们在使用时可以自由选择。
3.5 ProtocolHandler 组件
现在知道,连接器用 ProtocolHandler 来处理网络连接和应用层协议,包含了 2 个重要部件:Endpoint 和 Processor,下面来详细介绍它们的工作原理
3.5.1 EndPoint组件
Endpoint 翻译过来是"通信端点",主要负责网络通信,这其中就包括,监听客户端连接创建于客户端连接的Socket,并负责连接Socket 接收和发送处理器。因此Endpoint是对传输层的抽象,是用来实现 TCP/IP 协议的。
EndPoint类结构图
EndPoint用基类用抽象类AbstractEndpoint来表示,对于不同的Linux IO模型通过使用不同子类来实现。
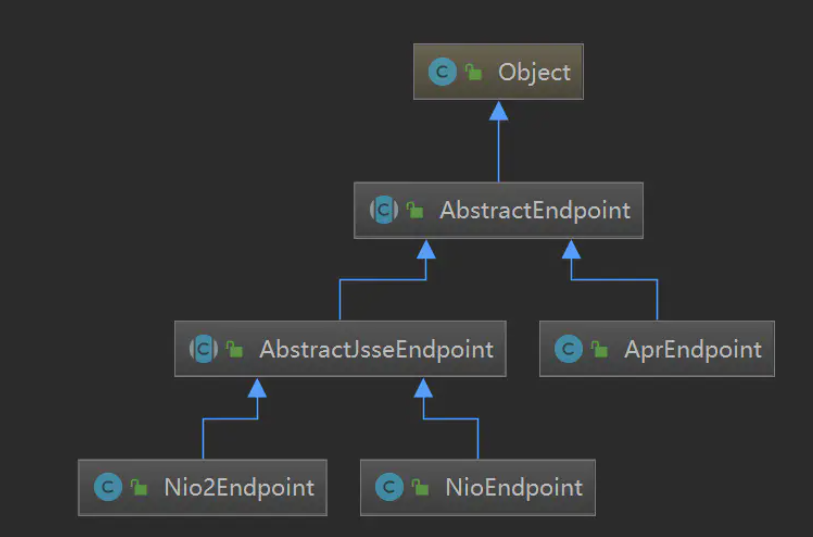
Endpoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 AbstractEndpoint 的具体子类,比如在 NioEndpoint 和 Nio2Endpoint 中,有两个重要的子组件:Acceptor 和 SocketProcessor。
其中 Acceptor 用于监听 Socket 连接请求。SocketProcessor 用于处理接收到的 Socket 请求,它实现 Runnable 接口,在 run 方法里调用协议处理组件 Processor 进行处理。为了提高处理能力,SocketProcessor 被提交到线程池来执行。而这个线程池叫作执行器(Executor)
3.5.2 Processor组件
Processor:翻译过来是"处理器",主要负责根据具体应用层协议(HTTP/AJP)读取字节流解析成 Tomcat Request 和 Response,因此Processor是对应用层的抽象,是用来实现 HTTP/AJP 协议的。
Processor类结构图
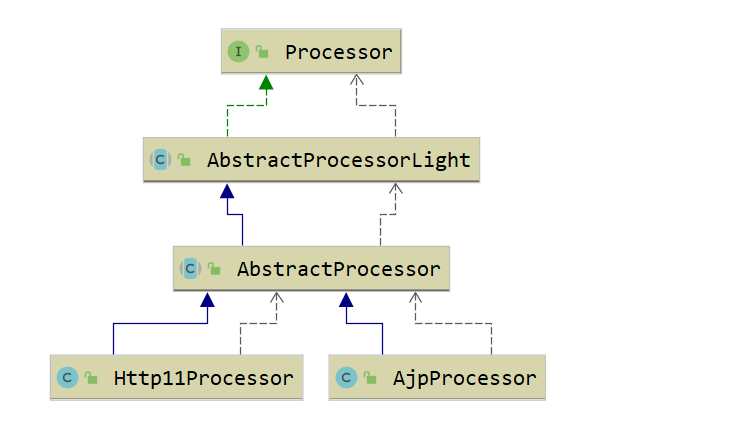
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AjpProcessor、Http11Processor 等,这些具体实现类实现了特定协议的解析方法和请求处理方式
3.5.3 Adapter组件
由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat 定义了自己的 Request 类来“存放”这些请求信息。ProtocolHandler 接口负责解析请求并生成 Tomcat Request/Response类。但是这个 Request/Response 对象不是标准的 ServletRequest/ServletResponse,也就意味着,不能用Tomcat Request/Response 作为参数来调用容器。
Tomcat 设计者的解决方案是引入 CoyoteAdapter,这是适配器模式的经典运用,负责将Tomcat Request/Response 与 ServletRequest/ServletResponse 的相互转化,实现连接器(Connector)和容器(Container)的解耦。
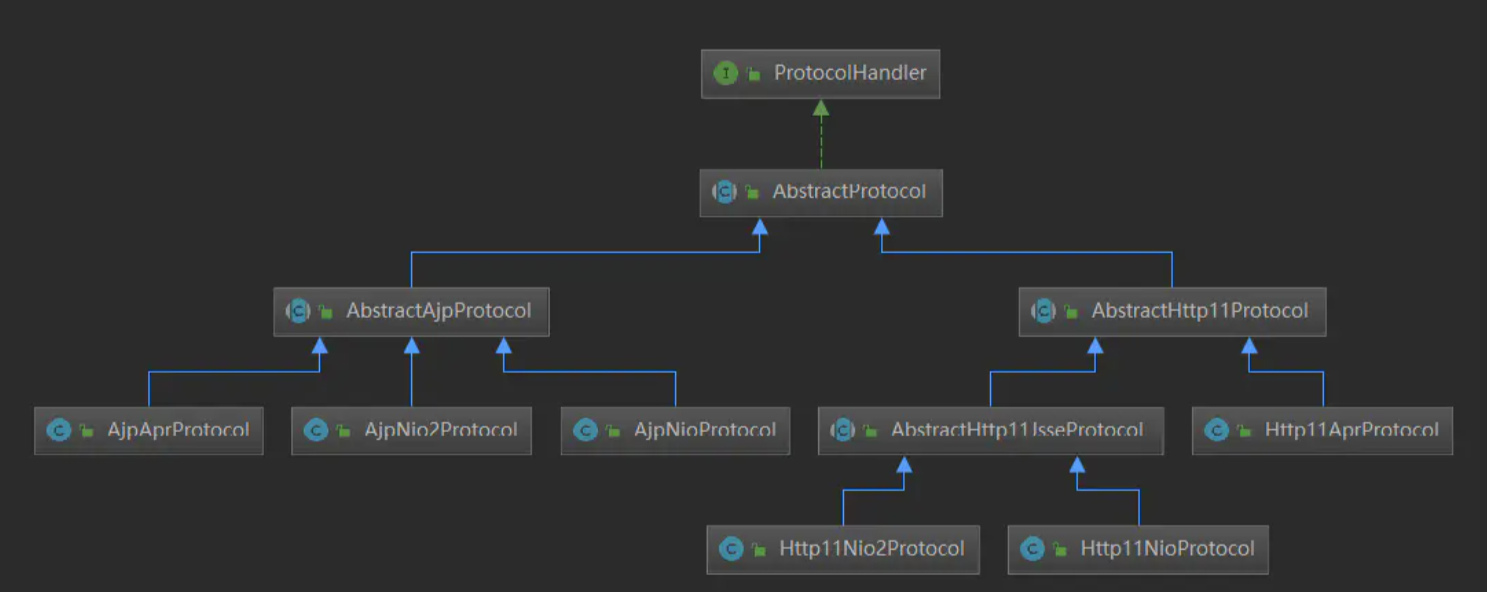
3.5.4 ProtocolHandler组件
ProtocolHandler组件EndPoint组件,Processor组件合并在一起表示协议处理器。用来处理tomcat支持多种IO模型和多种协议的组件。
ProtocolHandler类图
4. Connector处理流程
我们再来看看连接器的组件图:
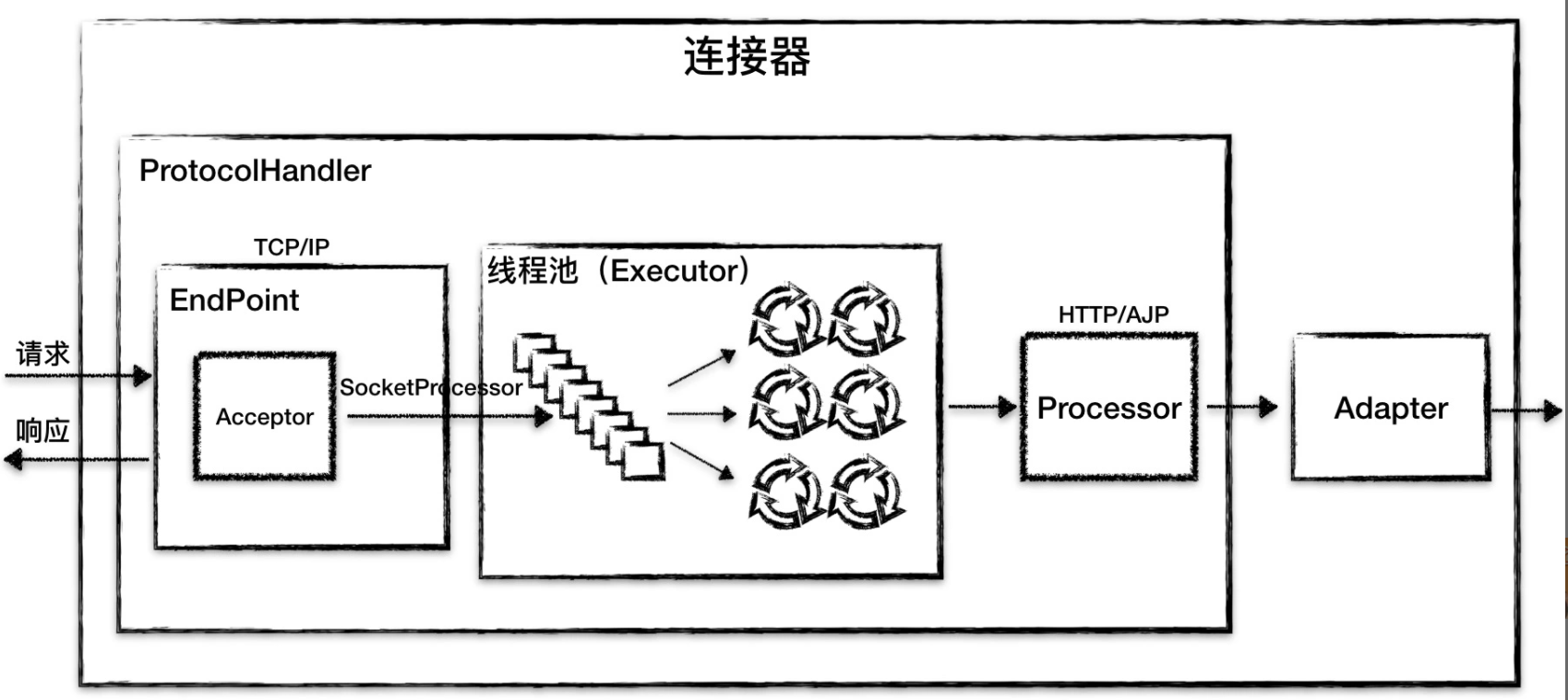
- Endpoint内部Acceptor组件用于监听Socket 连接请求,当发送客户端连接到服务端Acceptor组件负责与客户端建立连接创建Socket,每当连接客户端发起请求,Endpoint会创建一个SocketProcessor对象SocketProcessor 用于处理接收到的 Socket 请求,它实现 Runnable 接口,在 run 方法里调用协议处理组件 Processor 进行处理。为了提高处理能力,SocketProcessor 被提交到线程池来执行。而这个线程池叫作执行器(Executor)
- Processor 接收来自 Endpoint 的 Socket,读取字节流解析成 Tomcat Request 和 Response 对象,接着会调用 Adapter 的 Service 方法。并通过 Adapter 将其提交到容器处理
- 连接器调用 CoyoteAdapter 的 sevice 方法,传入的是 Tomcat Request 对象,CoyoteAdapter 负责将 Tomcat Request 转成 ServletRequest,再调用容器的 service 方法。
5. 容器的本质
Tomcat 有两个核心组件:连接器和容器
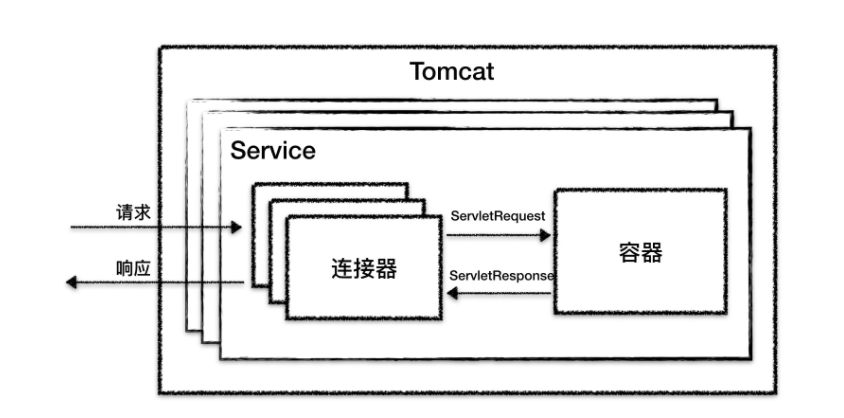
容器,顾名思义就是用来装载东西的器具,在 Tomcat 里,容器就是用来装载 Servlet 的。那 Tomcat 的 Servlet 容器是如何设计的呢?
Container本质上是一个Servlet容器,负责servelt的加载和管理,处理请求ServletRequest,并返回标准的 ServletResponse 对象给连接器。
6. 容器工作流程
当客户请求某个资源时,HTTP 服务器会用一个 ServletRequest 对象把客户的请求信息封装起来,然后调用 Servlet 容器的 service 方法,Servlet 容器拿到请求后,根据请求的 URL 和 Servlet 的映射关系,找到相应的 Servlet,如果 Servlet 还没有被加载,就用反射机制创建这个 Servlet,并调用 Servlet 的 init 方法来完成初始化,接着调用 Servlet 的 service 方法来处理请求,把 ServletResponse 对象返回给 HTTP 服务器,HTTP 服务器会把响应发送给客户端

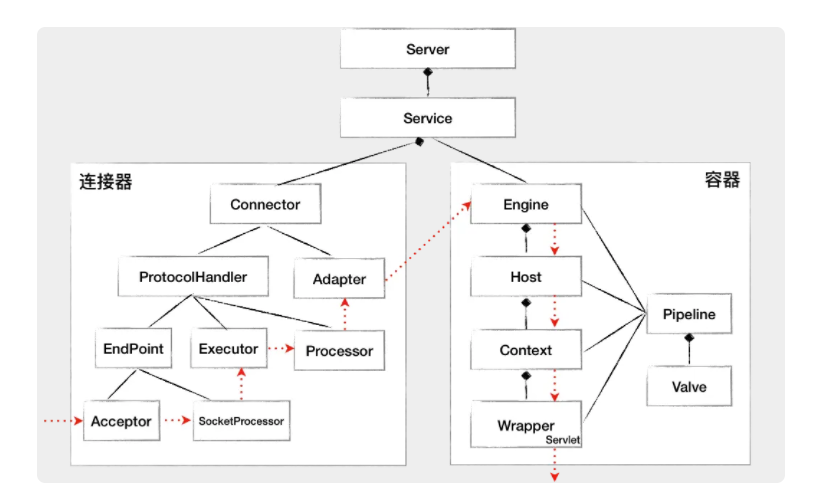
7. 容器层次结构
Tomcat 设计了 4 种容器组件,分别是 Engine、Host、Context 和 Wrapper。这 4 种容器不是平行关系,而是父子关系。
如图:
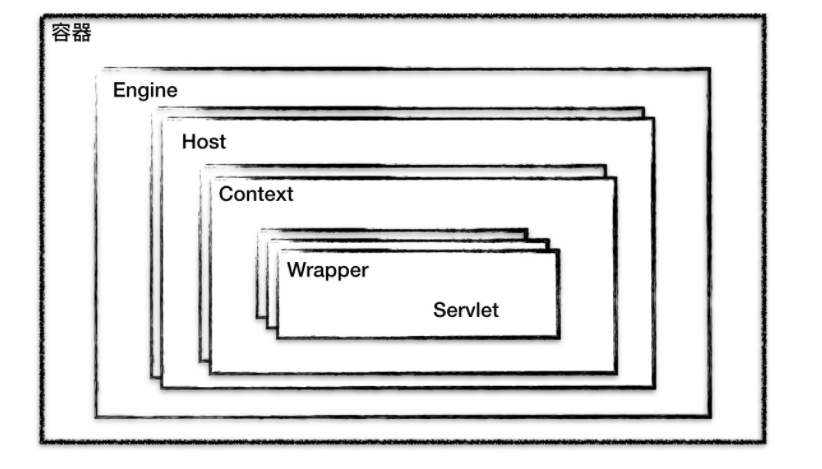
- Wrapper:表示一个 Servlet
- Context:表示一个 Web 应用程序,一个 Web 应用程序中可能会有多个 Servlet
- Host:表示的是一个虚拟主机,或者说一个站点,可以给 Tomcat 配置多个虚拟主机地址,而一个虚拟主机下可以部署多个 Web 应用程序
- Engine:表示引擎,用来管理多个虚拟站点,一个 Service 最多只能有一个 Engine。
可以再通过 Tomcat 的server.xml配置文件来加深对 Tomcat 容器的理解。Tomcat 采用了组件化的设计,它的构成组件都是可配置的,其中最外层的是 Server,其他组件按照一定的格式要求配置在这个顶层容器中。

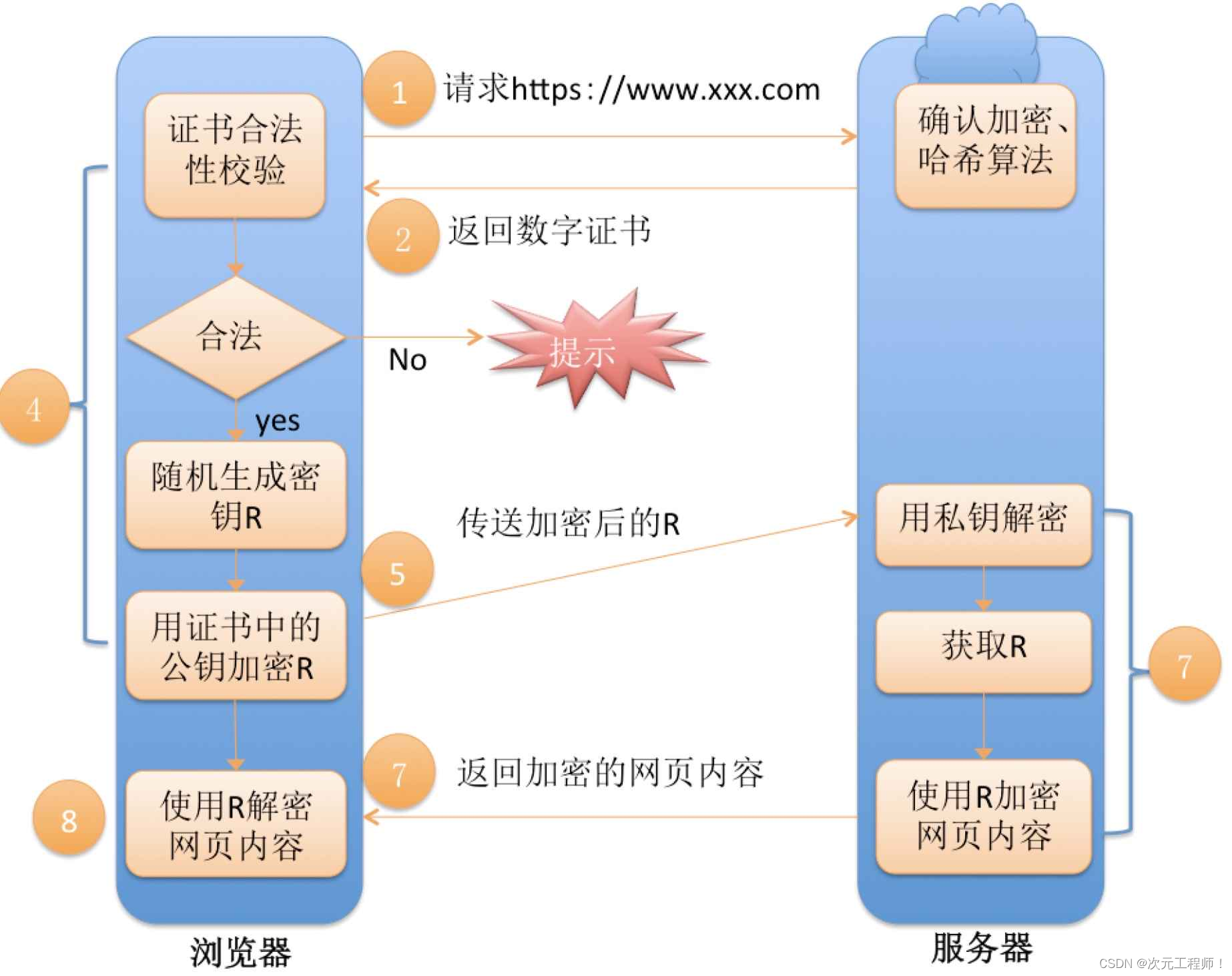
假如有用户访问一个 URL,比如图中的http://user.shopping.com:8080/order/buy,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?
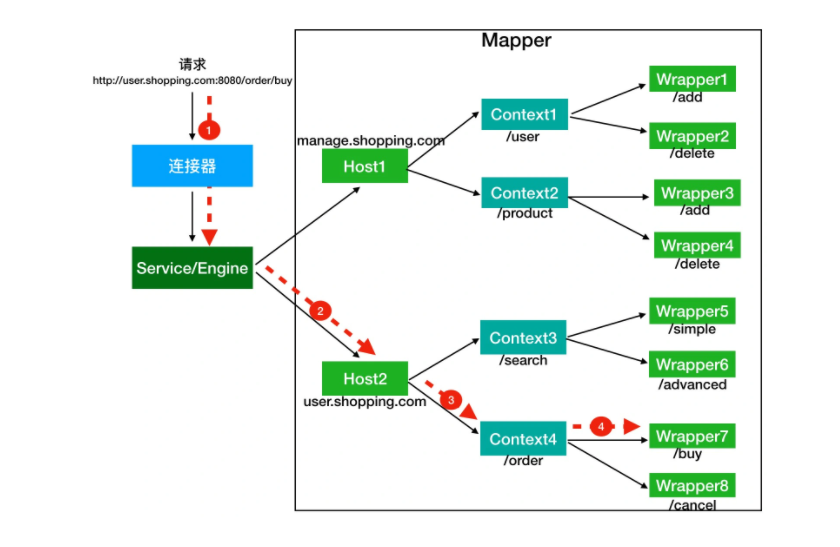
首先,根据协议和端口号选定 Service 和 Engine。
我们知道 Tomcat 的每个连接器都监听不同的端口,比如 Tomcat 默认的 HTTP 连接器监听 8080 端口、默认的 AJP 连接器监听 8009 端口。上面例子中的 URL 访问的是 8080 端口,因此这个请求会被 HTTP 连接器接收,而一个连接器是属于一个 Service 组件的,这样 Service 组件就确定了。我们还知道一个 Service 组件里除了有多个连接器,还有一个容器组件,具体来说就是一个 Engine 容器,因此 Service 确定了也就意味着 Engine 也确定了。
然后,根据域名选定 Host。
Service 和 Engine 确定后,Mapper 组件通过 URL 中的域名去查找相应的 Host 容器,比如例子中的 URL 访问的域名是user.shopping.com,因此 Mapper 会找到 Host2 这个容器。
之后,根据 URL 路径找到 Context 组件。
Host 确定以后,Mapper 根据 URL 的路径来匹配相应的 Web 应用的路径,比如例子中访问的是/order,因此找到了 Context4 这个 Context 容器。
最后,根据 URL 路径找到 Wrapper(Servlet)。
Context 确定后,Mapper 再根据web.xml中配置的 Servlet 映射路径来找到具体的 Wrapper 和 Servlet。
8. 组件类图
问题:Tomcat 是怎么管理这些容器组件?
Container容器中定义了Container 接口用来描述Container容器中所有的组件,不同的子组件分别定义了不同子接口做描述。容器组件之间具有父子关系。
public interface Container extends Lifecycle {
public void setName(String name);
public Container getParent();
public void setParent(Container container);
public void addChild(Container child);
public void removeChild(Container child);
public Container findChild(String name);
}
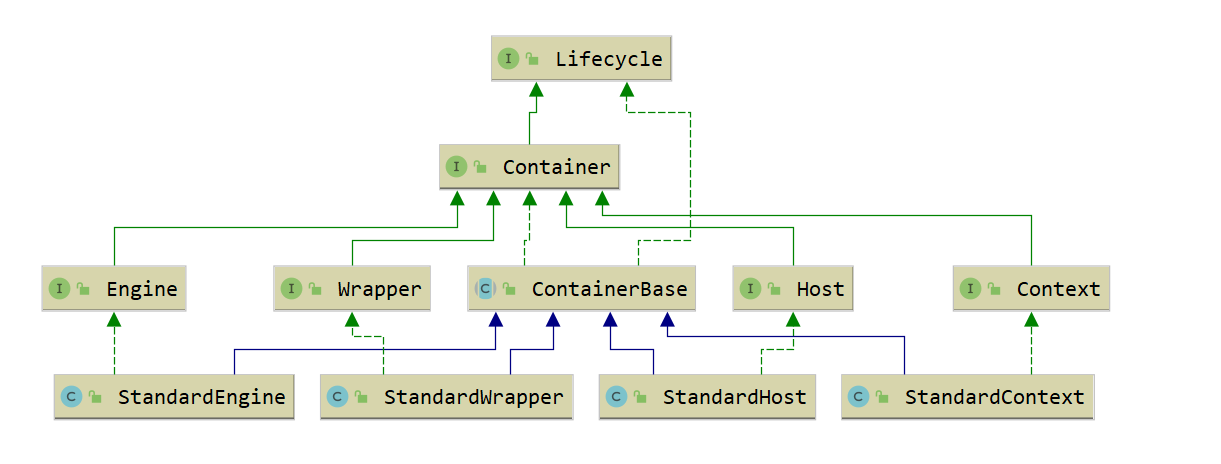
从接口看到了 getParent、setParent、addChild 和 removeChild 等方法。可能还注意到 Container 接口扩展了 Lifecycle 接口,Lifecycle 接口用来统一管理各组件的生命周期
9. 套娃式架构设计的好处
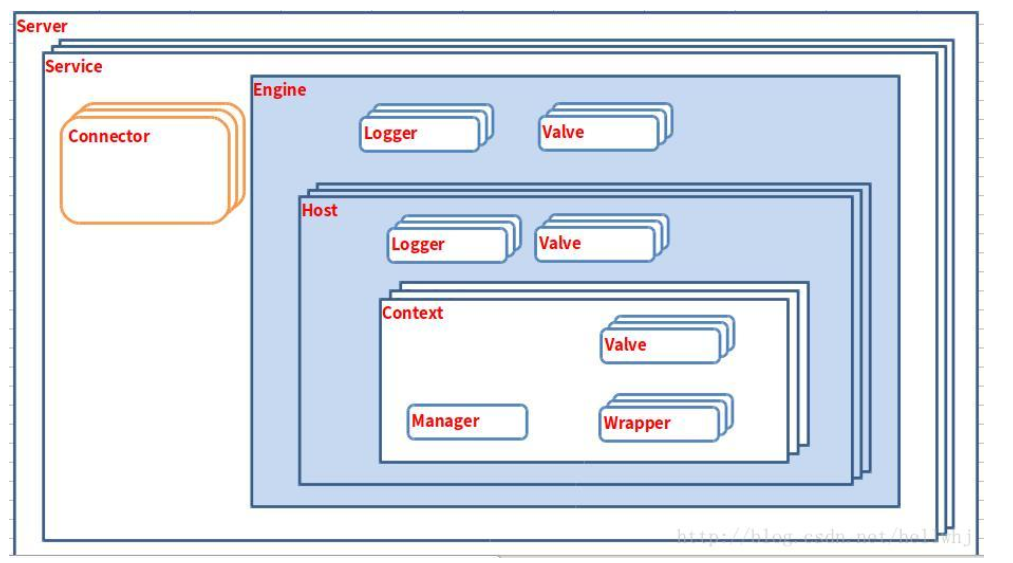
- 一层套一层的方式,其实组件关系还是很清晰的,也便于后期组件生命周期管理
- tomcat这种架构设计正好和xml配置文件中标签的包含方式对应上,那么后续在解读xml以及封装对象的过程中就容易对应
- 便于子容器继承父容器的一些配置
Tomcat源码环境构建
1.Apache Tomcat源码下载
下载地址:https://tomcat.apache.org/download-80.cgi
2.解压apache-tomcat-8.5.73-src.zip

3.apache-tomcat-8.5.73-src目录下添加pom文件
因为下载下来的源码包没有pom文件,为了编译并以maven项目运行,需要手动构建一下pom文件
pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.tomcat</groupId>
<artifactId>apache-tomcat-8.5.73-src</artifactId>
<name>Tomcat8.5</name>
<version>8.5</version>
<build>
<!--指定源目录-->
<finalName>Tomcat8.5</finalName>
<sourceDirectory>java</sourceDirectory>
<resources>
<resource>
<directory>java</directory>
</resource>
</resources>
<plugins>
<!--引入编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<!--tomcat 依赖的基础包-->
<dependencies>
<dependency>
<groupId>org.easymock</groupId>
<artifactId>easymock</artifactId>
<version>3.4</version>
</dependency>
<dependency>
<groupId>ant</groupId>
<artifactId>ant</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>wsdl4j</groupId>
<artifactId>wsdl4j</artifactId>
<version>1.6.2</version>
</dependency>
<dependency>
<groupId>javax.xml</groupId>
<artifactId>jaxrpc</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>org.eclipse.jdt.core.compiler</groupId>
<artifactId>ecj</artifactId>
<version>4.5.1</version>
</dependency>
</dependencies>
</project>
4.创建catalina-home目录

将bin、conf、webapps目录复制到catalina-home目录中:
其余文件夹手动进行创建:
5.导入IDEA
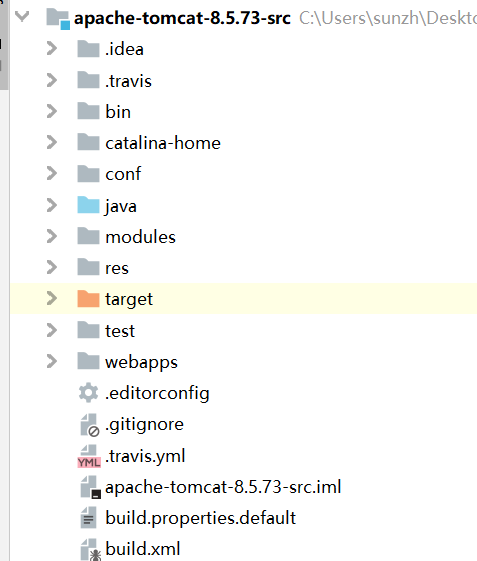
新建application 设置main类和vm参数
Main class: org.apache.catalina.startup.Bootstrap
VM options: 配置自己的catalina-home目录
打开ContextConfig 添加一行代码
//初始化JSP解析引擎
context.addServletContainerInitializer(new JasperInitializer(),null);

6.启动执行【常见错误解决】

报错:
程序包sun.rmi.registry不存在
解决:
将JmxRemoteLifecycleListener类 全部注释,再次启动
Tomcat如何实现一键式启停?
Tomcat里面有各种各样的组件,每个组件各司其职,组件之间又相互协作共同完成web服务器这样的工程。
组件的层次关系:
上面这张图描述了组件之间的静态关系,如果想让一个系统能够对外提供服务,我们需要创建、组装并启动这些组件;在服务停止的时候,我们还需要释放资源,销毁这些组件,因此这是一个动态的过程。也就是说,Tomcat 需要动态地管理这些组件的生命周期。
组件关系:
先来看看组件之间的关系。如果你仔细分析过这些组件,可以发现它们具有两层关系。
- 第一层关系是组件有大有小,大组件管理小组件,比如 Server 管理 Service,Service 又管理连接器和容器。
- 第二层关系是组件有外有内,外层组件控制内层组件,比如连接器是外层组件,负责对外交流,外层组件调用内层组件完成业务功能。也就是说,请求的处理过程是由外层组件来驱动的。
这两层关系决定了系统在创建组件时应该遵循一定的顺序。
- 第一个原则是先创建子组件,再创建父组件,子组件需要被“注入”到父组件中。
- 第二个原则是先创建内层组件,再创建外层组件,内层组件需要被“注入”到外层组件
因此,最直观的做法就是将图上所有的组件按照先小后大、先内后外的顺序创建出来,然后组装在一起。不知道注意到没有,这个思路其实很有问题!因为这样不仅会造成代码逻辑混乱和组件遗漏,而且也不利于后期的功能扩展。为了解决这个问题,我们希望找到一种通用的、统一的方法来管理组件的生命周期,就像汽车“一键启动”那样的效果。
思考:如何统一管理组件的创建、初始化、启动、停止和销毁?
一键式启停:Lifecycle 接口
Lifecycle 接口里应该定义这么几个方法:init、start、stop 和 destroy,每个具体的组件去实现这些方法。
Lifecycle 接口:
public interface Lifecycle {
....
// 初始化方法
public void init() throws LifecycleException;
// 启动方法
public void start() throws LifecycleException;
// 停止方法,和start对应
public void stop() throws LifecycleException;
// 销毁方法,和init对应
public void destroy() throws LifecycleException;
// 获取生命周期状态
public LifecycleState getState();
// 获取字符串类型的生命周期状态
public String getStateName();
}
在这样的设计中,在父组件的 init 方法里需要创建子组件并调用子组件的 init 方法。同样,在父组件的 start 方法里也需要调用子组件的 start 方法,因此调用者可以无差别的调用各组件的 init 方法和 start 方法,这就是组合模式的使用,并且只要调用最顶层组件,也就是 Server 组件的 init 和 start 方法,整个 Tomcat 就被启动起来了
重用性:LifecycleBase 抽象基类
有了接口,我们就要用类去实现接口。一般来说实现类不止一个,不同的类在实现接口时往往会有一些相同的逻辑,如果让各个子类都去实现一遍,就会有重复代码。那子类如何重用这部分逻辑呢?其实就是定义一个基类来实现共同的逻辑,然后让各个子类去继承它,就达到了重用的目的。
而基类中往往会定义一些抽象方法,所谓的抽象方法就是说基类不会去实现这些方法,而是调用这些方法来实现骨架逻辑。抽象方法是留给各个子类去实现的,并且子类必须实现,否则无法实例化。
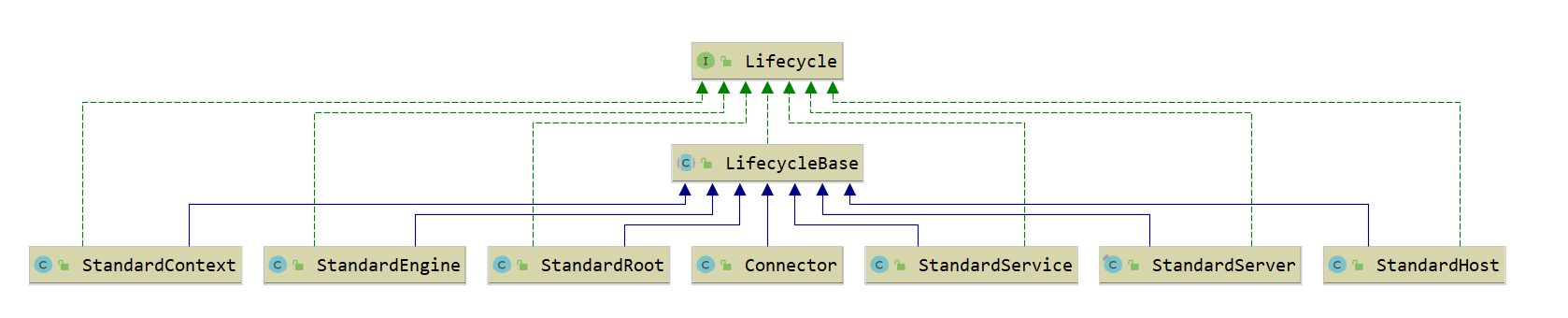
Tomcat 定义一个基类 LifecycleBase 来实现 Lifecycle 接口,把一些公共的逻辑放到基类中去,比如生命状态的转变与维护、生命事件的触发以及监听器的添加和删除等,而子类就负责实现自己的初始化、启动和停止等方法
@Override
public final synchronized void init() throws LifecycleException {
//1. 状态检查
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try {
//2.触发INITIALIZING事件的监听器
setStateInternal(LifecycleState.INITIALIZING, null, false);
//3.调用具体子类的初始化方法
initInternal();
//4. 触发INITIALIZED事件的监听器
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
...
}
}
源码剖析-Tomcat启动流程
启动总流程图
使用Tomcat时,通过 Tomcat 的/bin目录下的脚本startup.sh来启动 Tomcat,那执行了这个脚本后发生了什么呢?
流程图:
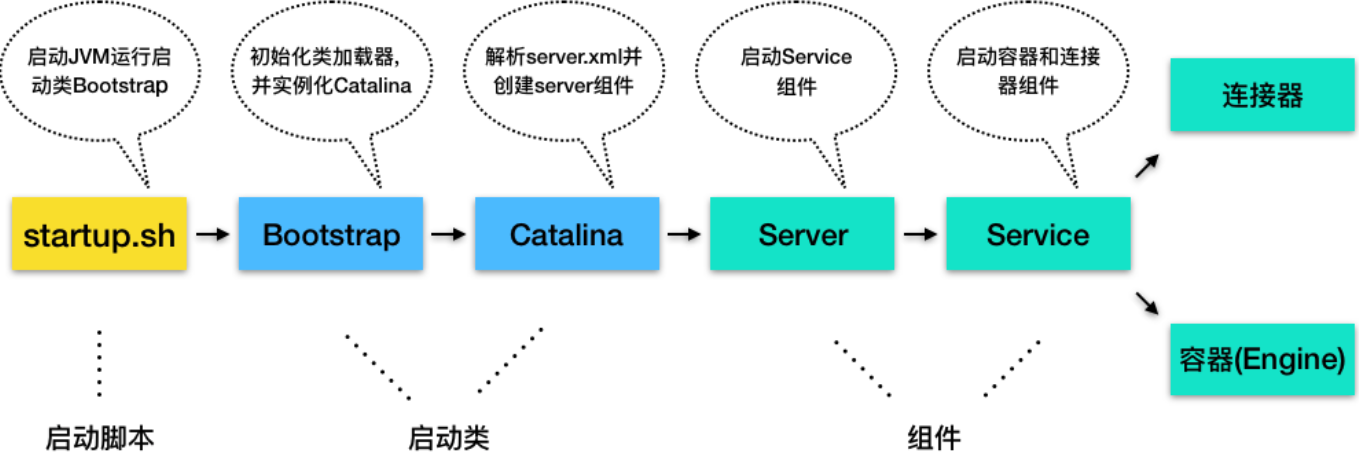
1.Tomcat 本质上是一个 Java 程序,因此startup.sh脚本会启动一个 JVM 来运行 Tomcat 的启动类 Bootstrap
2.Bootstrap 的主要任务是初始化 Tomcat 的类加载器,并且创建 Catalina
3.Catalina 是一个启动类,它通过解析server.xml、创建相应的组件,并调用 Server 的 start 方法
4.Server 组件的职责就是管理 Service 组件,它会负责调用 Service 的 start 方法
5.Service 组件的职责就是管理连接器和顶层容器 Engine,因此它会调用连接器和 Engine 的 start 方法。
这样 Tomcat 的启动就算完成了
(1)启动流程细节
startup.sh --> catalina.sh start --> java xxxx.jar org.apache.catalina.startup.Bootstrap(main) start(参数)
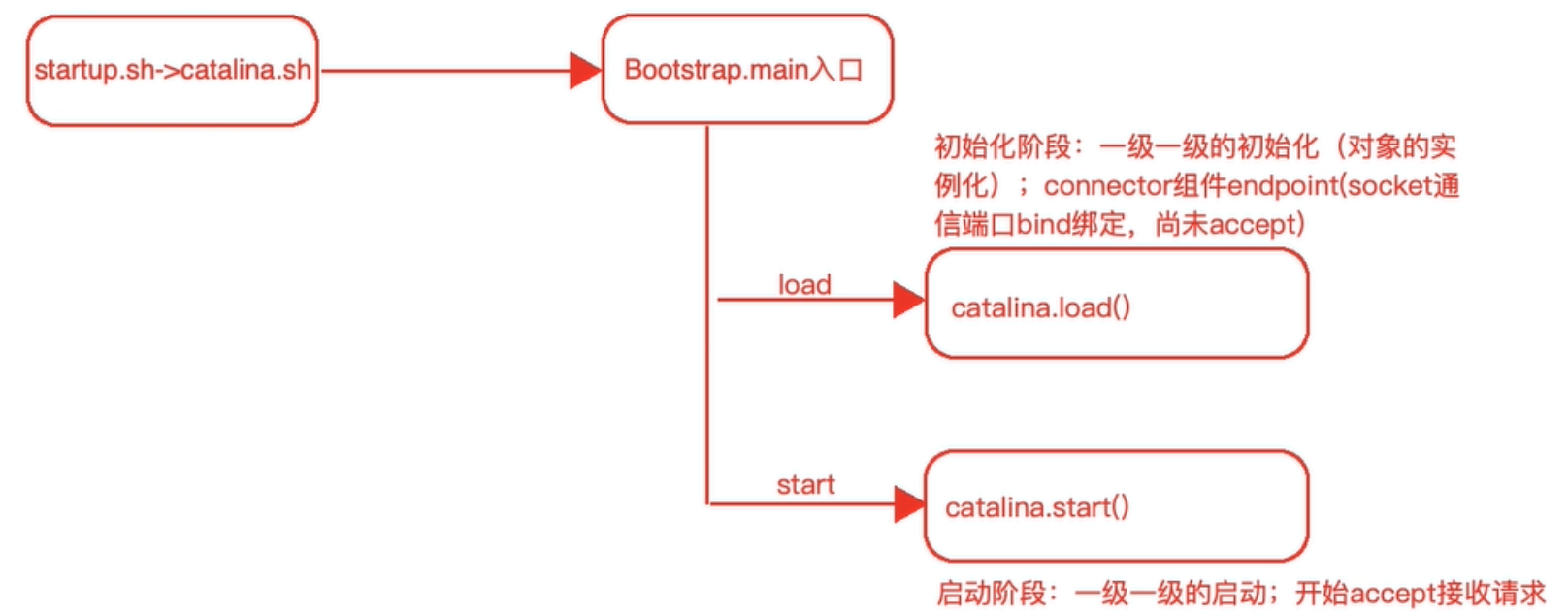
tips:
Bootstrap.init
Catalina.load
Catalina.start
Bootstrap#init();
1、初始化类加载器
2、加载catalina类,并且实例化
3、反射调用Catalina的setParentClassLoader方法
4、实例 赋值
//1、初始化类加载器
//2、加载catalina类,并且实例化
//3、反射调用Catalina的setParentClassLoader方法
//4、实例 赋值
public void init() throws Exception {
// 1. 初始化Tomcat类加载器(3个类加载器)
initClassLoaders();
Thread.currentThread().setContextClassLoader(catalinaLoader);
SecurityClassLoad.securityClassLoad(catalinaLoader);
// Load our startup class and call its process() method
if (log.isDebugEnabled())
log.debug("Loading startup class");
// 2. 实例化Catalina实例
Class<?> startupClass = catalinaLoader.loadClass("org.apache.catalina.startup.Catalina");
Object startupInstance = startupClass.getConstructor().newInstance();
// Set the shared extensions class loader
if (log.isDebugEnabled())
log.debug("Setting startup class properties");
String methodName = "setParentClassLoader";
Class<?> paramTypes[] = new Class[1];
paramTypes[0] = Class.forName("java.lang.ClassLoader");
Object paramValues[] = new Object[1];
paramValues[0] = sharedLoader;
// 3. 反射调用Catalina的setParentClassLoader方法,将sharedLoader设置为Catalina的parentClassLoader成员变量
Method method =
startupInstance.getClass().getMethod(methodName, paramTypes);
method.invoke(startupInstance, paramValues);
//4、将catalina实例赋值
catalinaDaemon = startupInstance;
}
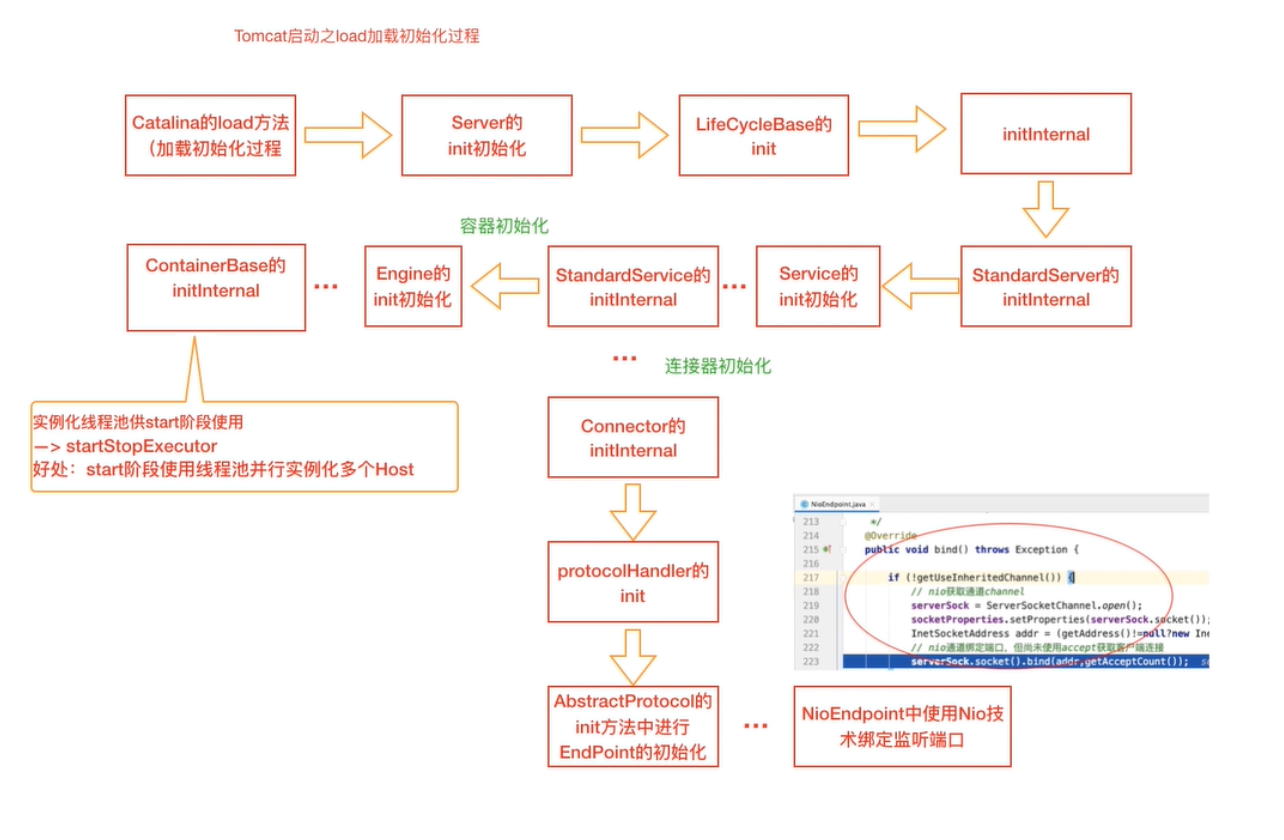
Catalina#load();
tips
org.apache.catalina.startup.Bootstrap#main中的load方法
调用的是catalina中的方法
1)load初始化流程
模板模式:
每个节点自己完成的任务后,会接着调用子节点(如果有的话)的同样的方法,引起链式反应。
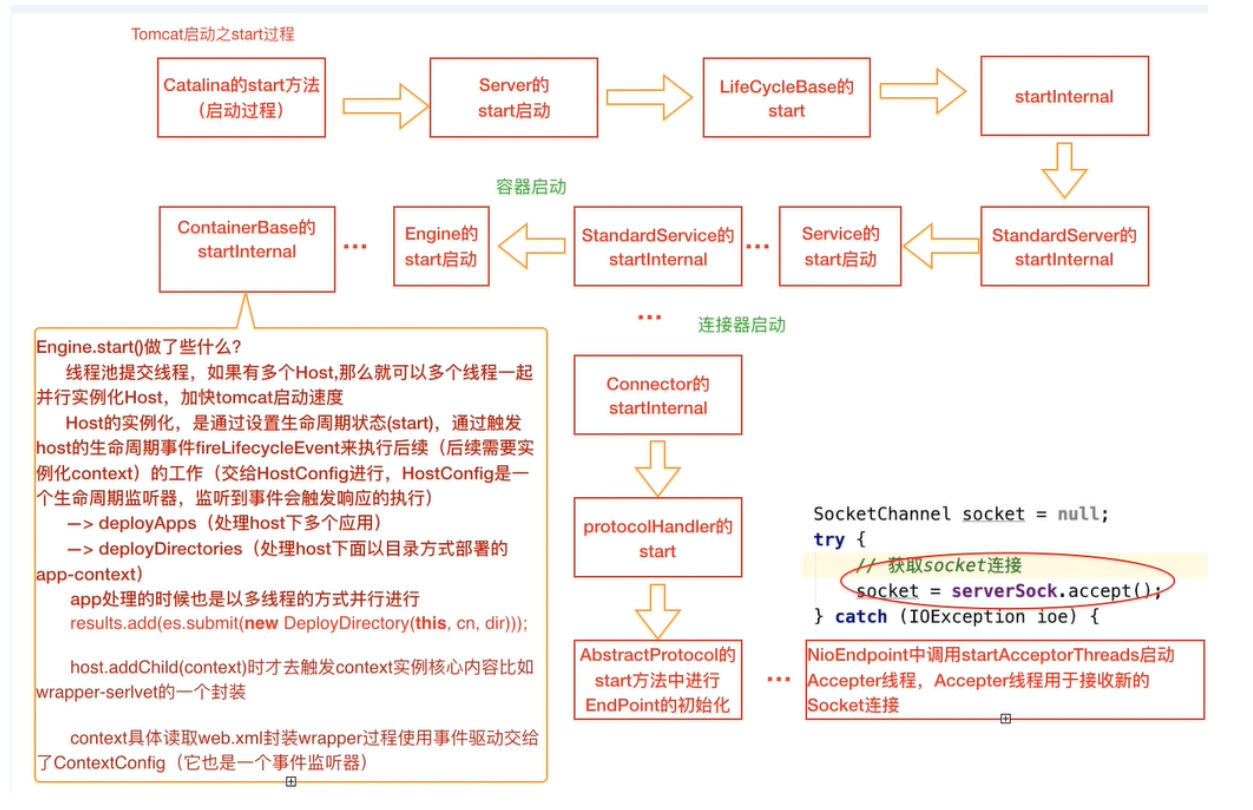
Catalina#start();
流程图
与load过程很相似
流程分析-Servlet请求处理链路追踪
问题:设计了这么多层次的容器,Tomcat 是怎么确定请求是由哪个 Wrapper 容器里的 Servlet 来处理的呢?答案是,Tomcat 是用 Mapper 组件来完成这个任务的。
Mapper 组件的功能就是将用户请求的 URL 定位到一个 Servlet,它的工作原理是:Mapper 组件里保存了 Web 应用的配置信息,其实就是容器组件与访问路径的映射关系,比如 Host 容器里配置的域名、Context 容器里的 Web 应用路径,以及 Wrapper 容器里 Servlet 映射的路径,你可以想象这些配置信息就是一个多层次的 Map。
当一个请求到来时,Mapper 组件通过解析请求 URL 里的域名和路径,再到自己保存的 Map 里去查找,就能定位到一个 Servlet。请你注意,一个请求 URL 最后只会定位到一个 Wrapper 容器,也就是一个 Servlet。
例子:
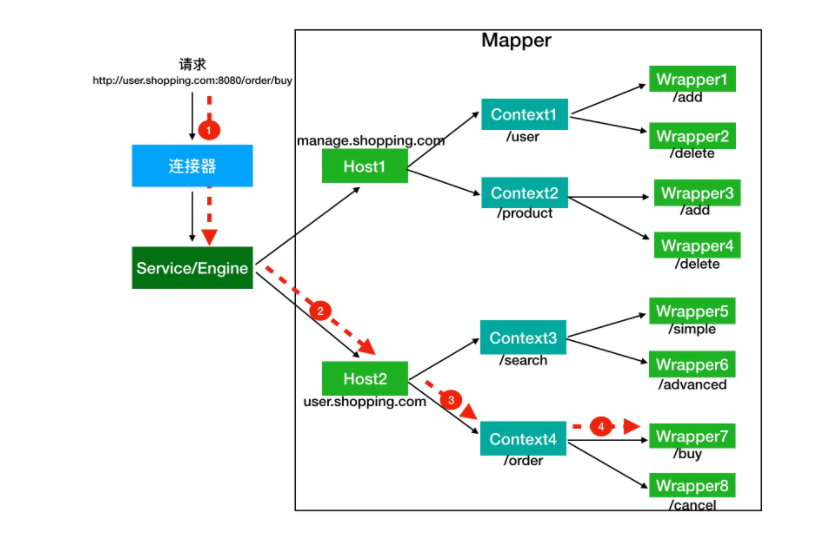
假如有用户访问一个 URL,比如图中的http://user.shopping.com:8080/order/buy,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?
首先,根据协议和端口号选定 Service 和 Engine。
我们知道 Tomcat 的每个连接器都监听不同的端口,比如 Tomcat 默认的 HTTP 连接器监听 8080 端口、默认的 AJP 连接器监听 8009 端口。上面例子中的 URL 访问的是 8080 端口,因此这个请求会被 HTTP 连接器接收,而一个连接器是属于一个 Service 组件的,这样 Service 组件就确定了。我们还知道一个 Service 组件里除了有多个连接器,还有一个容器组件,具体来说就是一个 Engine 容器,因此 Service 确定了也就意味着 Engine 也确定了。
然后,根据域名选定 Host。
Service 和 Engine 确定后,Mapper 组件通过 URL 中的域名去查找相应的 Host 容器,比如例子中的 URL 访问的域名是user.shopping.com,因此 Mapper 会找到 Host2 这个容器。
之后,根据 URL 路径找到 Context 组件。
Host 确定以后,Mapper 根据 URL 的路径来匹配相应的 Web 应用的路径,比如例子中访问的是/order,因此找到了 Context4 这个 Context 容器。
最后,根据 URL 路径找到 Wrapper(Servlet)。
Context 确定后,Mapper 再根据web.xml中配置的 Servlet 映射路径来找到具体的 Wrapper 和 Servlet。
我们知道容器组件最重要的功能是处理请求,最先拿到请求的是 Engine 容器,Engine 容器对请求做一些处理后,会把请求传给自己子容器 Host 继续处理,依次类推,最后这个请求会传给 Wrapper 容器,Wrapper 会调用最终的 Servlet 来处理。那么这个调用过程具体是怎么实现的呢?答案是使用 Pipeline-Valve 管道。
Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。Valve 表示一个处理点,比如权限认证和记录日志。如果还不太理解的话,可以来看看 Valve 和 Pipeline 接口中的关键方法
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void invoke(Request request, Response response)
}
由于 Valve 是一个处理点,因此 invoke 方法就是来处理请求的。注意到 Valve 中有 getNext 和 setNext 方法,因此我们大概可以猜到有一个链表将 Valve 链起来了。请你继续看 Pipeline 接口:
public interface Pipeline extends Contained {
public void addValve(Valve valve);
public Valve getBasic();
public void setBasic(Valve valve);
public Valve getFirst();
}
没错,Pipeline 中有 addValve 方法。Pipeline 中维护了 Valve 链表,Valve 可以插入到 Pipeline 中,对请求做某些处理。我们还发现 Pipeline 中没有 invoke 方法,因为整个调用链的触发是 Valve 来完成的,Valve 完成自己的处理后,调用getNext.invoke来触发下一个 Valve 调用。
每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。但是,不同容器的 Pipeline 是怎么链式触发的呢,比如 Engine 中 Pipeline 需要调用下层容器 Host 中的 Pipeline
这是因为 Pipeline 中还有个 getBasic 方法。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。还是通过一张图来解释。
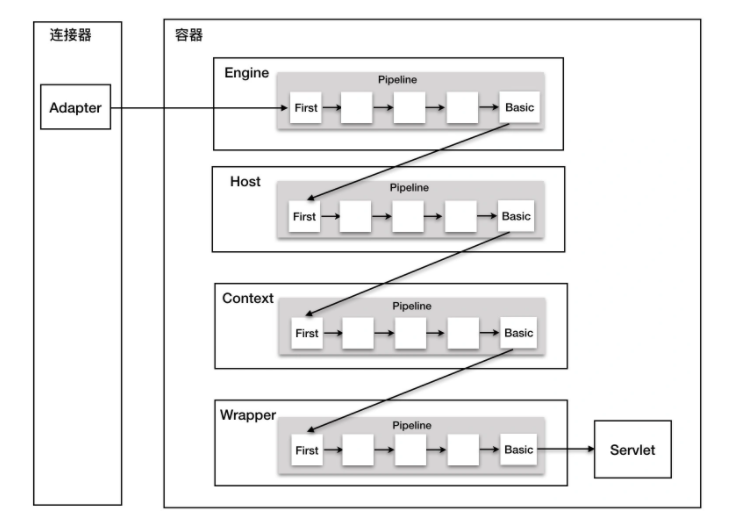
每一个容器组件都有一个 Pipeline,而 Pipeline 中有一个基础阀(Basic Valve),而 Engine 容器的基础阀定义如下:
final class StandardEngineValve extends ValveBase {
public final void invoke(Request request, Response response)
throws IOException, ServletException {
//拿到请求中的Host容器
Host host = request.getHost();
if (host == null) {
return;
}
// 调用Host容器中的Pipeline中的第一个Valve
host.getPipeline().getFirst().invoke(request, response);
}
}
这个基础阀实现非常简单,就是把请求转发到 Host 容器。问题是处理请求的 Host 容器对象是从请求中拿到的,请求对象中怎么会有 Host 容器呢?这是因为请求到达 Engine 容器中之前,Mapper 组件已经对请求进行了路由处理,Mapper 组件通过请求的 URL 定位了相应的容器,并且把容器对象保存到了请求对象中。