
读高性能MySQL(第4版)笔记04_操作系统和硬件优化
news2026/2/13 20:25:44
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/987148.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
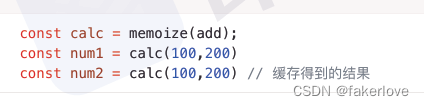
JavaScipt中如何实现函数缓存?函数缓存有哪些场景?
1、函数缓存是什么? 函数缓存就是将函数运行的结果进行缓存。本质上就是用空间(缓存存储)换时间(计算过程) 常用于缓存数据计算结果和缓存对象。 缓存只是一个临时的数据存储,它保存数据,以便将…

异步编程 - 09 Spring框架中的异步执行_@Async注解异步执行原理源码解析
文章目录 概述小结好文推荐 概述
在Spring中调用线程将在调用含有Async注释的方法时立即返回,Spring是如何做到的呢?其实是其对标注Async注解的类做了代理,比如下面的类Async-AnnotationExample。
public class AsyncAnnotationExample {As…

Qt 5.15集成Crypto++ 8.8.0(MSVC 2019)笔记
一、背景 笔者已介绍过在Qt 5.15.x中使用MinGW(8.10版本)编译并集成Crypto 8.8.0。 但是该编译出来的库(.a和.dll)不适用MSVC(2019版本)构建环境,需要重新编译(.lib或和.dll…
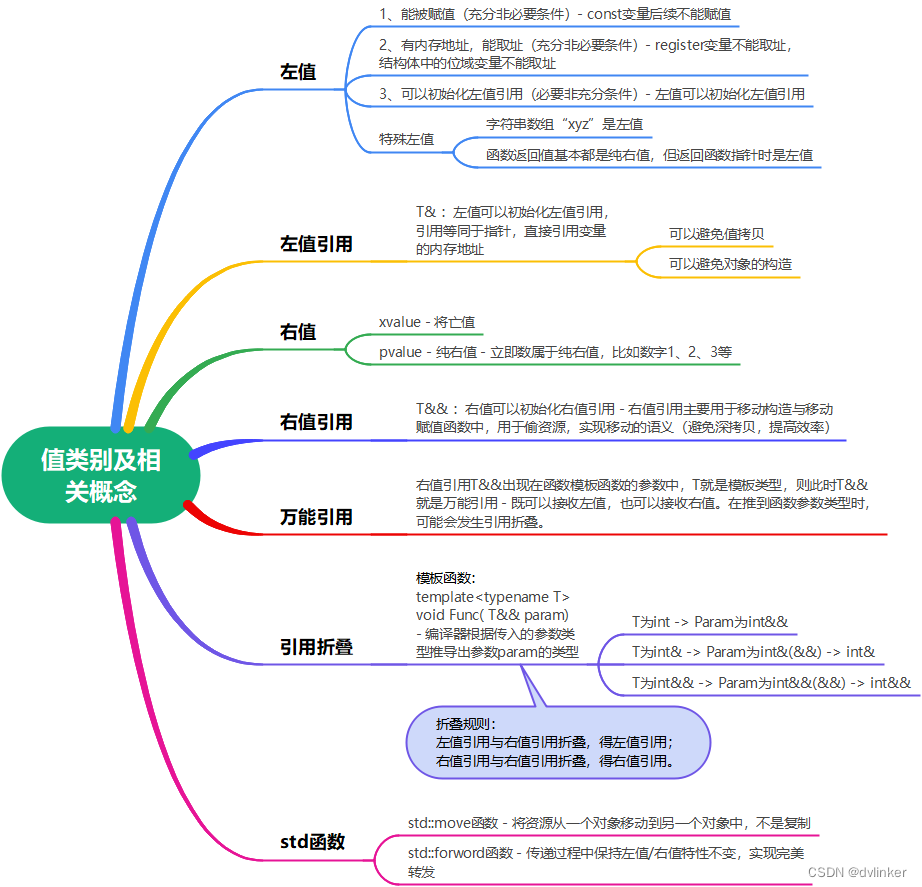
C++11新特性② | 左值、左值引用、右值与右值引用
目录
1、引言
2、值类别及相关概念
3、左值、右值
4、左值引用、右值引用
5、移动语义
5.1、为什么需要移动语义
5.2、移动语义定义
5.3、转移构造函数
5.4、转移赋值函数
6、标准库函数 std::move
7、完美转发 std::forward VC常用功能开发汇总(专栏文章…

Mybatis 使用typeHandler自定义类型转换
之前我们介绍了使用Mybatis完成数据的增删改查操作;本篇我们介绍使用Mybatis提供的typeHandler自定义类型转换。
如果您对Mybatis的增删改查操作不太了解,可以参考:
Mybatis 查询数据https://blog.csdn.net/m1729339749/article/details/13…
explain 实战-----查看hive sql执行计划
目录 1.join/left join/full join 语句会过滤关联字段 null 的值吗?
(1)join
(2) left join /full join
2.group by 分组语句会进行排序吗? 1.join/left join/full join 语句会过滤关联字段 null 的值吗…

Qt 5.15编译(MinGW)及集成Crypto++ 8.8.0笔记
一、背景 为使用AES加密库(AES/CBC加解密),选用Crypto 库(官网)。 最新Crypto C库依次为:8.8.0版本(2023-6-25)、8.7.0(2022-8-7)和8.6.0(202…

绘图系统三:支持散点图、极坐标和子图绘制
文章目录 新增散点图绘制绑定与回调极坐标功能子图绘制功能源代码 📈一 三维绘图系统📈二 多图绘制系统
新增散点图绘制
同一坐标系中绘制多个图像是很常见的需求,比如数据拟合的时候,用散点图表示原始数据,用曲线图…
vue3 webpack打包流程及安装 (1)
npm run build 也可以打包 如果没有特殊需求 可以使用 效果其实是差不多的 ---------------------------------------------------------------------------------------------------------------------------------
webpack网址 : 起步 | webpack 中文文档 (docsc…

记录docker 部署nessus
1、开启容器
docker run -itd --nameramisec_nessus -p 8834:8834 ramisec/nessus
2、登录 :注意是https
https://ip8843
3、修改admin密码
#进入容器
docker exec -it ramisec_nessus /bin/bash#列出用户名
/opt/nessus/sbin/nessuscli lsuser#修改密码&a…

(html+CSS)垂直居中
line-height
设置文字行高等于父元素的高度
vertical-align
用于设置一个元素的垂直对齐方式,但是它只针对于行内元素或者行内块元素有效。
属性值说明baseline默认,元素放置在父元素的基线上top把元素的顶端与行中最高元素的顶端对齐middle把此元素…

递归算法学习——黄金矿工,不同路径III
目录
编辑
一,黄金矿工
1.题意
2.题目分析
3.题目接口
4.解题思路及代码
二,不同路径III
1.题意
2.解释
3.题目接口 4.解题思路及代码 一,黄金矿工
1.题意 你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源…

YMatrix 5.0 与天翼云完成产品兼容性认证
近日,北京四维纵横数据技术有限公司与天翼云宣布完成产品兼容性认证。经过双方严格的测试验证,超融合数据库 YMatrix 5.0 与天翼云兼容性良好,可基于天翼云稳定运行。 数据库系统作为基础软件的核心,自主可控势在必行。在此背景下…

项目(智慧教室)第一部分:cubemx配置,工程文件的移植,触摸屏的检测,项目bug说明
第一章:需求与配置
一。项目需求 二。实现外设控制 注意: 先配置引脚,再配置外设。否则会出现一些不可预料的问题 1.时钟,串口,灯,蜂鸣器配置
(1)RCC配置为外部时钟,修…

Android 开发小贴士
Android 开发小贴士
Unable to merge dex
原因: 1. 包引用重复 2. 方法数超限 3. 或者几个库之间有重复代码块(特别是在整理module时容易犯)
解决: 1. app的build.gradle中
// 1. 添加配置
defaultConfig {......multiDexEnabled true
}// 2. 清除缓…
pico学习进程记录已经开发项目
Pico pin脚定义 Pico 运行准备
下载uf2文件 https://pico.org.cn/ (注意运行micropython的文件和运行c/c的不一样) 装载uf2文件:按住pico的按键,然后通过micro usb连接电脑(注意:如果用的线材,…

菜鸟教程《Python 3 教程》笔记(19):错误与异常
菜鸟教程《Python 3 教程》笔记(19) 19 错误和异常19.1 assert(断言)19.2 异常处理19.2.1 try/except19.2.2 try/except...else19.2.3 try-finally 语句 19.3 抛出异常19.4 用户自定义异常19.5 清理行为19.5.1 定义清理行为19.5.2…

生信分析Python实战练习 6 | 视频24
开源生信 Python教程 生信专用简明 Python 文字和视频教程 源码在:https://github.com/Tong-Chen/Bioinfo_course_python 目录 背景介绍 编程开篇为什么学习Python如何安装Python如何运行Python命令和脚本使用什么编辑器写Python脚本Python程序事例Python基本语法 数…

HTTP代理协议原理分析
HTTP代理协议是一种常见的网络协议,它可以在网络中传递HTTP协议的请求和响应。本文将介绍HTTP代理协议的分析和原理,包括HTTP代理的工作流程、HTTP代理的请求和响应格式、HTTP代理的优缺点等方面。 一、HTTP代理的工作流程 HTTP代理的工作流程如下&#…
OmniGraffle Pro for Mac 中文正式版(附注册码) 苹果电脑 思维导图软件
OmniGraffle Pro是OmniGraffle的高级版本,它提供了更多的功能和工具,可以帮助用户创建更为复杂和高级的图表和流程图。OmniGraffle Pro支持自定义形状、图形、线条和箭头等,可以让用户创建出更加精细的图表。此外,OmniGraffle Pro…