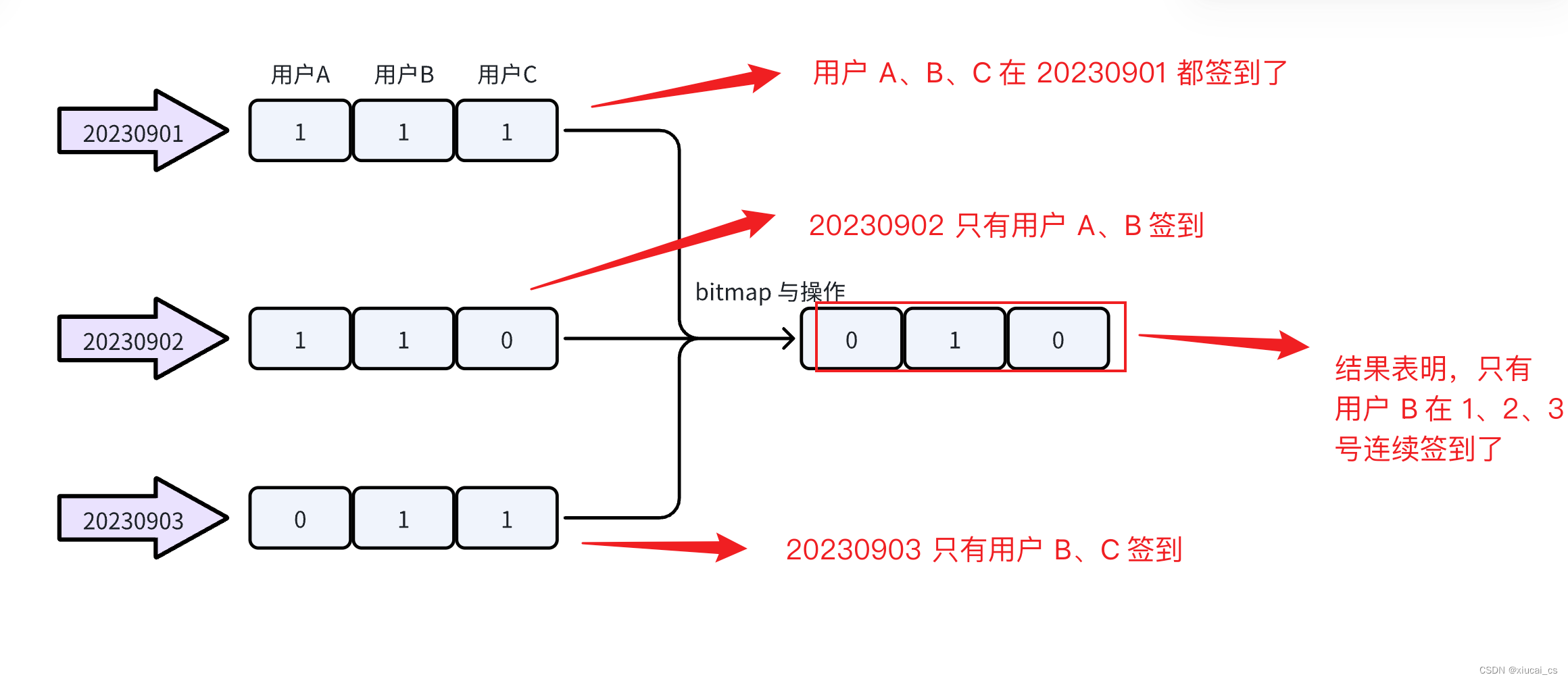
本篇文章为 LeetCode 哈希模块的刷题笔记,仅供参考。
哈希表是一种使用哈希函数组织数据,以支持快速插入和搜索的数据结构。哈希表通过哈希函数通过将任意类型的数据映射到固定大小的数据,以实现快速查找和存储数据。C++ 中的无序容器 unordered_map、unordered_set、unordered_multimap、unordered_multiset 都使用了哈希表作为底层结构,可以在 O(1) 的时间复杂度内完成插入、删除和查找操作。
其实哈希表可以由数组枚举所有值来代替其功能,但有时会因取值数量太过庞大而导致不必要的时间和空间的浪费,如【Leetcode554.砖墙】。当键为定长数据类型且数量有限时,也可以直接使用数组存储键值,可以省去哈希的过程,如【Leetcode438.找到字符串中所有字母异位词】。
目录
- 一. 基础哈希
- Leetcode1.两数之和
- Leetcode290.单词规律
- Leetcode594.最长和谐子序列
- 二. 哈希常见处理
- Leetcode17.电话号码的字母组合
- Leetcode49.字母异位词分组
- Leetcode438.找到字符串中所有字母异位词
- Leetcode454.四数相加 II
- Leetcode554.砖墙
- 三. 哈希与其他模块结合
- Leetcode3.无重复字符的最长子串
- Leetcode560.和为 K 的子数组
- Leetcode763.划分字母区间
一. 基础哈希
Leetcode1.两数之和
Leetcode1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104
-109 <= nums[i] <= 109
-109 <= target <= 109
只会存在一个有效答案
经典的哈希使用场景,使用 unordered_map 存储元素出现的下标即可。需要注意 map 的 int 型默认值是 0,因此 哈希表存储下标时需要从 1 计数:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> mp;
for(int i=0;i<nums.size();i++){
if(mp[target-nums[i]]>0) return {mp[target-nums[i]]-1,i};
mp[nums[i]]=i+1;
}
return {-1,-1};
}
};
Leetcode290.单词规律
Leetcode290.单词规律
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
输入: pattern = “abba”, s = “dog cat cat dog”
输出: true
示例 2:
输入:pattern = “abba”, s = “dog cat cat fish”
输出: false
示例 3:
输入: pattern = “aaaa”, s = “dog cat cat dog”
输出: false
提示:
1 <= pattern.length <= 300
pattern 只包含小写英文字母
1 <= s.length <= 3000
s 只包含小写英文字母和 ’ ’
s 不包含 任何前导或尾随对空格
s 中每个单词都被 单个空格 分隔
像本题这种一一对应的问题,直接使用两个哈希表存储字符和字符串之间的映射。字符串的哈希表中检索元素没有 0 作比较,用 迭代器 + find 函数遍历哈希表 即可:
class Solution {
public:
bool wordPattern(string pattern, string s) {
// s分割字符串
vector<string> v;
int ptr=0;
for(int i=0;i<s.size();i++){
if(s[i]==' '){
v.push_back(s.substr(ptr,i-ptr));
ptr=i+1;
}
}
v.push_back(s.substr(ptr));
// 寻找单词规律
if(pattern.size()!=v.size()) return false;
// char->string
unordered_map<char,string> mp1;
for(int i=0;i<v.size();i++){
unordered_map<char,string>::iterator it1=mp1.find(pattern[i]);
if(it1!=mp1.end() && mp1[pattern[i]]!=v[i]) return false;
mp1[pattern[i]]=v[i];
}
// string->char
unordered_map<string,char> mp2;
for(int i=0;i<v.size();i++){
unordered_map<string,char>::iterator it2=mp2.find(v[i]);
if(it2!=mp2.end() && mp2[v[i]]!=pattern[i]) return false;
mp2[v[i]]=pattern[i];
}
return true;
}
};
Leetcode594.最长和谐子序列
Leetcode594.最长和谐子序列
和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。
现在,给你一个整数数组 nums ,请你在所有可能的子序列中找到最长的和谐子序列的长度。
数组的子序列是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素、且不改变其余元素的顺序而得到。
示例 1:
输入:nums = [1,3,2,2,5,2,3,7]
输出:5
解释:最长的和谐子序列是 [3,2,2,2,3]
示例 2:
输入:nums = [1,2,3,4]
输出:2
示例 3:
输入:nums = [1,1,1,1]
输出:0
提示:
1 <= nums.length <= 2 * 104
-109 <= nums[i] <= 109
哈希表有一个必须注意的地方:第一题中,直接使用了 [] 操作符索引哈希表可以快速返回键的值,但该操作会带来一个后果(参考 Default value of static std::unordered_map):当键不存在时,[] 操作会在哈希表中插入该键值对,值为默认值! 比如本题如果写成 [] 访问:
class Solution {
public:
int findLHS(vector<int>& nums) {
unordered_map<int,int> mp;
for(int i=0;i<nums.size();i++) mp[nums[i]]++;
unordered_map<int,int>::iterator it;
int ans=0;
for(it=mp.begin();it!=mp.end();it++){
if(mp[it->first+1]>0) ans=max(ans,it->second+mp[it->first+1]);
}
return ans;
}
};
[] 操作会在迭代器遍历哈希表的过程中,对哈希表进行插入操作,这在迭代器遍历中属于大忌! 虽然 mp[it->first+1] 键不存在时,插入的值是 0,但当迭代器访问到 first+1 时,mp[it->first+2] 的键有可能会存在,从而导致 ans 值的错误更新。因此 尽量使用 find 函数判断键是否存在:
class Solution {
public:
int findLHS(vector<int>& nums) {
unordered_map<int,int> mp;
for(int i=0;i<nums.size();i++) mp[nums[i]]++;
unordered_map<int,int>::iterator it;
int ans=0;
for(it=mp.begin();it!=mp.end();it++){
if(mp.find(it->first+1)!=mp.end()) ans=max(ans,it->second+mp[it->first+1]);
}
return ans;
}
};
二. 哈希常见处理
Leetcode17.电话号码的字母组合
Leetcode17.电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例 1:
输入:digits = “23”
输出:[“ad”,“ae”,“af”,“bd”,“be”,“bf”,“cd”,“ce”,“cf”]
示例 2:
输入:digits = “”
输出:[]
示例 3:
输入:digits = “2”
输出:[“a”,“b”,“c”]
提示:
0 <= digits.length <= 4
digits[i] 是范围 [‘2’, ‘9’] 的一个数字。

原本想用 unordered_multimap 存储数字到字符的映射,但为了方便起见,简化为 unordered_map 存储,每个键值对的值表示多个可能对应的字符,即使用字符串 表示数字的映射。
整个枚举过程相当于一颗多叉树,每一层对应 digits 字符串的一位。在遍历 digits 的每一位时,将前一层的 ans 的所有元素末尾加上当前层可能对应的字符即可,使用辅助数组 tmp 进行缓存,每次只需将 ans 中元素全部放入 tmp 后清空,然后遍历 tmp 的每个元素增加一个字符后再放入 ans 即可:
class Solution {
public:
vector<string> letterCombinations(string digits) {
if(digits.size()==0) return {};
unordered_map<char, string> mp{
{'2', "abc"},
{'3', "def"},
{'4', "ghi"},
{'5', "jkl"},
{'6', "mno"},
{'7', "pqrs"},
{'8', "tuv"},
{'9', "wxyz"}
};
vector<string> ans(1,"");
for(int i=0;i<digits.size();i++){
vector<string> tmp(ans.begin(),ans.end());
ans.clear();
string s=mp[digits[i]];
for(int j=0;j<s.size();j++){
char c=s[j];
for(int k=0;k<tmp.size();k++){
ans.push_back(tmp[k]+string(1,c));
}
}
}
return ans;
}
};

Leetcode49.字母异位词分组
Leetcode49.字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
提示:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] 仅包含小写字母
为了统一字母异位词的映射,在哈希表映射前将 每个字符串排序,键映射后相同的放在一个数组里:
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,int> mp; // 递增字符串->ans下标
vector<vector<string>> ans;
for(int i=0;i<strs.size();i++){
string tmp=strs[i];
sort(tmp.begin(),tmp.end());
if(mp[tmp]==0){
mp[tmp]=ans.size()+1;
vector<string> v(1,strs[i]);
ans.push_back(v);
}else{
ans[mp[tmp]-1].push_back(strs[i]);
}
}
return ans;
}
};

Leetcode438.找到字符串中所有字母异位词
Leetcode438.找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
输入: s = “cbaebabacd”, p = “abc”
输出: [0,6]
解释:
起始索引等于 0 的子串是 “cba”, 它是 “abc” 的异位词。
起始索引等于 6 的子串是 “bac”, 它是 “abc” 的异位词。
示例 2:
输入: s = “abab”, p = “ab”
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 “ab”, 它是 “ab” 的异位词。
起始索引等于 1 的子串是 “ba”, 它是 “ab” 的异位词。
起始索引等于 2 的子串是 “ab”, 它是 “ab” 的异位词。
提示:
1 <= s.length, p.length <= 3 * 104
s 和 p 仅包含小写字母
法一:可以用【Leetcode49.字母异位词分组】中的思路,对 s[left…right] 进行排序,然后和 p 比较即可。但字符串的比较过程也较为耗时,因此不予采纳。
法二:用长度为 p.length() 的滑动窗口截取 s 中与 p 等长的字符串,使用哈希表统计该字符串中各字母出现频次,与 s 中各字母出现频次比较即可。因为字母数量有限,因此比较 s[left…right] 和 p 中的字母频次并不费时。
需要注意的是,不能直接使用等号比较哈希表是否相等,因为对于某个字母先加后减的情况,哈希表中会将其数量记为 0,但这与没出现过该元素的哈希表比较时不会认为是相同的:
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int m=s.length();
int n=p.length();
if(m<n) return {};
// p的字符分布
unordered_map<char,int> mp_p;
for(int i=0;i<n;i++){
mp_p[p[i]]++;
}
// s[left...right]的字符分布
int left=0,right=n-1;
unordered_map<char,int> mp_s;
for(int i=0;i<n;i++){
mp_s[s[i]]++;
}
// 滑动窗口搜索s
vector<int> ans;
while(right<m){
// 比较 mp_p和 mp_s时不能直接划等号
// if(mp_p==mp_s) ans.push_back(left);
bool flag=true;
for(auto it=mp_s.begin();it!=mp_s.end();it++){
if(it->second!=mp_p[it->first]) flag=false;
}
if(flag) ans.push_back(left);
mp_s[s[left]]--;
left++;
right++;
mp_s[s[right]]++;
}
return ans;
}
};

法三:当 键的数量有限且可以顺序搜索 时,直接使用数组存储键值对,可以省去哈希的过程。本体中涉及的键只有 26 个字母,因此比较计算过程会很高效:
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int m=s.length();
int n=p.length();
if(m<n) return {};
// p的字符分布
vector<int> v_p(26);
for(int i=0;i<n;i++) v_p[p[i]-'a']++;
// s[left...right]的字符分布
int left=0,right=n-1;
vector<int> v_s(26);
for(int i=0;i<n;i++) v_s[s[i]-'a']++;
// 滑动窗口搜索s
vector<int> ans;
while(right<m){
if(v_s==v_p) ans.push_back(left);
v_s[s[left]-'a']--;
left++;
right++;
if(right<m) v_s[s[right]-'a']++;
}
return ans;
}
};

Leetcode454.四数相加 II
Leetcode454.四数相加 II
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < n
nums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
示例 1:
输入:nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2]
输出:2
解释:
两个元组如下:
- (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0
- (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
示例 2:
输入:nums1 = [0], nums2 = [0], nums3 = [0], nums4 = [0]
输出:1
提示:
n = nums1.length
n = nums2.length
n = nums3.length
n = nums4.length
1 <= n <= 200
-228 <= nums1[i], nums2[i], nums3[i], nums4[i] <= 228
直接暴力搜索的时间复杂度为 O(n4),显然不能够满足需要。其实本题就是
⌈
\lceil
⌈两数之和
⌋
\rfloor
⌋ 的变式,将四个数拆分成两组,使用两个哈希表 mp1 和 mp2,分别存储 nums1[i]+nums2[j] 和 nums3[i]+nums4[j] 值的数量,然后检索 mp1 和 mp2 中所有键的和为 0 的元素对应的值的乘积:
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
int n=nums1.size();
unordered_map<int,int> mp1;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
mp1[nums1[i]+nums2[j]]++;
}
}
unordered_map<int,int> mp2;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
mp2[nums3[i]+nums4[j]]++;
}
}
int ans=0;
unordered_map<int,int>::iterator it;
for(it=mp1.begin();it!=mp1.end();it++){
ans+=it->second * mp2[-it->first];
}
return ans;
}
};

Leetcode554.砖墙
Leetcode554.砖墙
你的面前有一堵矩形的、由 n 行砖块组成的砖墙。这些砖块高度相同(也就是一个单位高)但是宽度不同。每一行砖块的宽度之和相等。
你现在要画一条 自顶向下 的、穿过 最少 砖块的垂线。如果你画的线只是从砖块的边缘经过,就不算穿过这块砖。你不能沿着墙的两个垂直边缘之一画线,这样显然是没有穿过一块砖的。
给你一个二维数组 wall ,该数组包含这堵墙的相关信息。其中,wall[i] 是一个代表从左至右每块砖的宽度的数组。你需要找出怎样画才能使这条线 穿过的砖块数量最少 ,并且返回 穿过的砖块数量 。
示例 1:
输入:wall = [[1,2,2,1],[3,1,2],[1,3,2],[2,4],[3,1,2],[1,3,1,1]]
输出:2
示例 2:
输入:wall = [[1],[1],[1]]
输出:3
提示:
n == wall.length
1 <= n <= 104
1 <= wall[i].length <= 104
1 <= sum(wall[i].length) <= 2 * 104
对于每一行 i ,sum(wall[i]) 是相同的
1 <= wall[i][j] <= 231 - 1

法一:由于砖墙是一个矩形,所以对于任意一条垂线,其穿过的砖块数量加上从边缘经过的砖块数量之和是一个定值,即 wall.length。虽然我们不容易直接计算位于某一列的垂线穿过的砖块数量,因为这在砖块的中间,但 wall[i][j] 表示第 i 行位于第 sum(wall[i][0...j]) 列是 砖块的边缘,从这里经过的垂线不会增加垂线穿过的砖块数量。
于是,直接使用 bool 型数组标记每一行的每一列元素是否是砖块的边缘,然后遍历所有列寻找最少穿过的砖块数量即可:
class Solution {
public:
int leastBricks(vector<vector<int>>& wall) {
// 初始化
int m=wall.size();
int n=0;
for(int i=0;i<wall[0].size();i++) n+=wall[0][i];
vector<vector<bool>> matrix; // matrix[i][j]是否是砖块的边缘
vector<bool> tmp(n);
matrix.resize(m,tmp);
vector<int> v(n); // v[i]处是砖块的边缘的数量
// 计算matrix
for(int i=0;i<m;i++){
int cnt=-1;
for(int j=0;j<wall[i].size();j++){
cnt+=wall[i][j];
matrix[i][cnt]=1;
}
for(int k=0;k<n;k++) v[k]+=matrix[i][k];
}
// 计算最少穿过的砖块数量
int ans=m;
for(int i=0;i<n;i++){
if(m-v[i]!=0) ans=min(ans,m-v[i]);
}
return ans;
}
};
然而,直接使用数组进行存储不仅会大大消耗存储空间,还会增加相当的时间消耗:O(n * sum(wall[i].length))。因此,需要 使用哈希表替代数组 以提高运算速度。
法二:哈希表不需要存储 sum(wall[i].length) 个元素,只用记录 砖块的边缘 的数量即可:
class Solution {
public:
int leastBricks(vector<vector<int>>& wall) {
// 初始化
int m=wall.size();
unordered_map<int,int> mp;
// 计算mp
for(int i=0;i<m;i++){
int cnt=-1;
for(int j=0;j<wall[i].size()-1;j++){ // 只需要遍历到wall[i].size()-2,因为最后一列一定都是砖块的边缘
cnt+=wall[i][j];
mp[cnt]++;
}
}
// 计算最少穿过的砖块数量
int ans=m; // 最多是m
for(auto it=mp.begin();it!=mp.end();it++){
ans=min(ans,m-it->second);
}
return ans;
}
};

三. 哈希与其他模块结合
哈希表常与双指针、滑动窗口、前缀和等相结合。
Leetcode3.无重复字符的最长子串
Leetcode3.无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
提示:
0 <= s.length <= 5*104
s 由英文字母、数字、符号和空格组成
使用双指针 left 和 right 构造滑动窗口,初值赋为 0。right 指针遍历字符串,每次后移一格,检查 [left, right] 区间的字符串是否含有重复字符,如果有重复字符则 left 右移一格。整个过程 使用哈希表记录当前 s[left, right] 区间内的字符情况:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map<char,int> mp;
int left=0,right=0;
int n=s.size();
int ans=0;
while(right<n){
while(mp[s[right]]>0){
mp[s[left]]--;
left++;
}
ans=max(ans,right-left+1);
mp[s[right]]++;
right++;
}
return ans;
}
};

Leetcode560.和为 K 的子数组
Leetcode560.和为 K 的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的连续子数组的个数 。
示例 1:
输入:nums = [1,1,1], k = 2
输出:2
示例 2:
输入:nums = [1,2,3], k = 3
输出:2
提示:
1 <= nums.length <= 2 * 104
-1000 <= nums[i] <= 1000
-107 <= k <= 107
连续子数组问题,要么是双指针,要么是前缀和。本题因为元素存在负值,双指针搜索无法确定窗口位置,故而采用前缀和。
在计算了 nums 的前缀和 sums 后,遍历 sums 数组:若 sums[j] - sums[i] == k 且 j>i,则说明 nums[i+1...j] = k。原本使用哈希表存储 sums[i] -> i,但是 同一个前缀和可能对应多个 i,后来发现存储 i 并无用处,直接存储 sums[i] 的个数即可:
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int n=nums.size();
vector<int> sums(n+1); // 从1计数
for(int i=0;i<n;i++){
sums[i+1]=sums[i]+nums[i];
}
int ans=0;
unordered_map<int,int> mp; // sums[i]->cnt
mp[0]=1; // sums[0]出现了1次
for(int i=1;i<=n;i++){
if(mp[sums[i]-k]>0){
ans+=mp[sums[i]-k]; // 不一定只出现了1次
}
mp[sums[i]]++;
}
return ans;
}
};
Leetcode763.划分字母区间
Leetcode763.划分字母区间
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
输入:s = “ababcbacadefegdehijhklij”
输出:[9,7,8]
解释:
划分结果为 “ababcbaca”、“defegde”、“hijhklij” 。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 这样的划分是错误的,因为划分的片段数较少。
示例 2:
输入:s = “eccbbbbdec”
输出:[10]
提示:
1 <= s.length <= 500
s 仅由小写英文字母组成
本题的精髓是使用哈希表存储字母在字符串中最后出现的位置,然后使用双指针遍历字符串 s:如果当前字符是最后一次出现,即可更新 left 指针:
class Solution {
public:
vector<int> partitionLabels(string s) {
int n=s.size();
unordered_map<int,int> mp;
for(int i=0;i<n;i++) mp[s[i]]=i;
int left=0,right=0;
int maxend=0;
vector<int> ans;
while(right<n){
maxend=max(maxend,mp[s[right]]);
if(maxend==right){
ans.push_back(right-left+1);
left=right+1;
}
right++;
}
return ans;
}
};