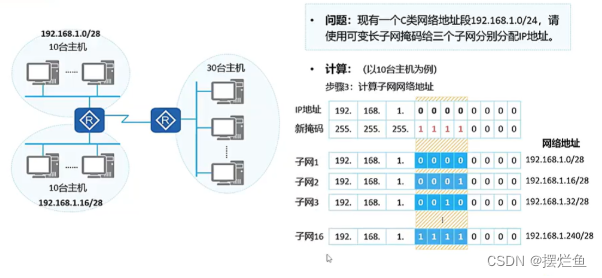
PandaGPT 是一种通用的指令跟踪模型,可以看到和听到。实验表明,PandaGPT 可以执行复杂的任务,例如生成详细的图像描述、编写受视频启发的故事以及回答有关音频的问题。更有趣的是,PandaGPT 可以同时接受多模态输入并自然地组合它们的语义。例如,PandaGPT 可以连接对象在照片中的外观以及它们在音频中的声音。为此,PandaGPT 结合了 ImageBind 的多模式编码器和 Vicuna 的大型语言模型。值得注意的是,尽管 PandaGPT 在六种模式(文本、图像/视频、音频、深度、热和 IMU)中展示了令人印象深刻的跨模式功能,但它仅使用对齐的图像-文本对进行训练,感谢 ImageBind 提供的共享嵌入空间。我们希望 PandaGPT 成为构建 AGI 的第一步,它可以像我们人类一样整体感知和理解不同模式的输入。
github:GitHub - yxuansu/PandaGPT: PandaGPT: One Model To Instruction-Follow Them All
1、搭建环境
conda create -n pandagpt python=3.9
conda activate pandagpt创建虚拟环境pandagpt,python3.9,激活环境
git clone https://github.com/yxuansu/PandaGPT.git
cd /content/drive/MyDrive/PandaGPT
pip install -r requirements.txt
pip install torch==1.13.1+cu117 -f https://download.pytorch.org/whl/torch/
pip install gradio mdtex2html下载PandaGPT源码,安装依赖包。
2、下载模型
curl -L https://dl.fbaipublicfiles.com/imagebind/imagebind_huge.pth -o /content/drive/MyDrive/imagebind_ckpt/_huge.pth
准备ImageBind Checkpoint,保存为/content/drive/MyDrive/imagebind_ckpt/_huge.pth
准备Vicuna Checkpoint,保存为/content/drive/MyDrive/vicuna_ckpt/7b_v0/vicuna-7b-v0,详见
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0_Spielberg_1的博客-CSDN博客
pip install huggingface_hub
from huggingface_hub import snapshot_download
save_dir="/content/drive/MyDrive/pandagpt_ckpt/7b"
repo_id="openllmplayground/pandagpt_7b_max_len_1024"
snapshot_download(repo_id=repo_id,local_dir=save_dir, local_dir_use_symlinks=False)
下载PandaGPT权重,保存到/content/drive/MyDrive/pandagpt_ckpt/7b
还可以从huggingface网站下载模型等。
三、部署演示
cd /content/drive/MyDrive/PandaGPT/code
进入PandaGPT目录,打开/PandaGPT/code/web_demo.py文件,

传入的imagebind_ckpt_path、vicuna_ckpt_path模型路径修改成你的目录
delta_ckpt_path修改为pandagpt权重路径,最后是.pt文件

最后一行,share参数改为True,这样就可以分享链接,在网页上打开了
终于可以运行啦
cd /content/drive/MyDrive/PandaGPT/code
CUDA_VISIBLE_DEVICES=0 python web_demo.py我们看一下效果,打开链接,看到页面有四个框,依次上传图片、音频、视频、热力图,
文件上传到模型受网络影响,图片可能要等待几秒,音频和视频要更长一点,有文件上传完成提示就更好了(期待大神更新)。
在[input]框中输入想要的提问,点击[submit],等到推理出结果,在[chatbot]中对给出回答

传入一张猫咪,提问:“这是什么颜色” 回答:灰色和白色

上传一段雷声,提问:这是什么声音

上传汉堡图片,提问:举两个生产商
总结:总的来看,pandagpt使用文本和图像对进行训练,能够实现跨模态的输入的,生成文本,还是很让人欣喜的,感谢分享,期待大神继续完善。
遇到的问题:
ImportError: LlamaTokenizer requires the SentencePiece library but it was not found in your environment. Checkout the instructions on the installation page of its repo: https://github.com/google/sentencepiece# installation and follow the ones
that match your environment. Please note that you may need to restart your runtime after installation.
pip install Sentencepiece
/mnt/PandaGPT/code/web_demo.py:154: GradioUnusedKwargWarning: You have unused kwarg parameters in Blocks, please remove them: {'scale': 4}
with gr.Blocks(scale=4) as demo:
/mnt/PandaGPT/code/web_demo.py:157: GradioUnusedKwargWarning: You have unused kwarg parameters in Row, please remove them: {'scale': 4}
with gr.Row(scale=4):
/mnt/PandaGPT/code/web_demo.py:163: GradioUnusedKwargWarning: You have unused kwarg parameters in Video, please remove them: {'type': 'file'}
video_path = gr.Video(type='file', label="Video")
/mnt/PandaGPT/code/web_demo.py:167: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
chatbot = gr.Chatbot().style(height=300)
/mnt/PandaGPT/code/web_demo.py:171: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(container=False)
/mnt/PandaGPT/code/web_demo.py:173: GradioUnusedKwargWarning: You have unused kwarg parameters in Row, please remove them: {'scale': 1}
with gr.Row(scale=1):
/mnt/PandaGPT/code/web_demo.py:175: GradioUnusedKwargWarning: You have unused kwarg parameters in Row, please remove them: {'scale': 1}
with gr.Row(scale=1):
Running on local URL: http://0.0.0.0:24000To create a public link, set `share=True` in `launch()`.
Error: no DISPLAY environment variable specified
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 0; 23.70 GiB total capacity; 7.16 GiB already allocated; 12.69 MiB free; 7.22 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
查看显卡显存被占用,杀掉占用进程
Ubuntu下跑Aplaca报错:torch.cuda.0utofMemoryError: CUDA out of memory.解决办法(查看CUDA占用情况&清除GPU缓存)_李卓璐的博客-CSDN博客
FileNotFoundError: [Errno 2] No such file or directory: 'ffprobe'
pip install ffmpeg感谢:
FileNotFoundError: [Errno 2] 没有这样的文件或目录: 'ffprobe': 'ffprobe' | 那些遇到过的问题
python - FileNotFoundError: No such file or directory: 'ffprobe' FileNotFoundError: No such file or directory: 'ffmpeg' - Stack Overflow
python - FileNotFoundError: [Errno 2] No such file or directory: 'ffprobe': 'ffprobe' - Stack Overflow
Our pilot experiments show that 我们的实验显示
reason over 推理 reasons over the user's input 对用户的输入进行推理
a set of 一套
understanding/reasoning 理解/推理
knowledeg-grouding description 基于知识的描述
multi-turn conversation 多轮对话
general-purpose 多用途,多功能
pilot experiments 中试试验,发布之前的实验
perform complex tasks 执行复杂实验
image description generation 生成图像描述
writing stories inspired by videos 创作受视频启发故事
answering questions about audios 回答关于音频的问题
take multimodal input simultaneously 同时接收多种模式的输入