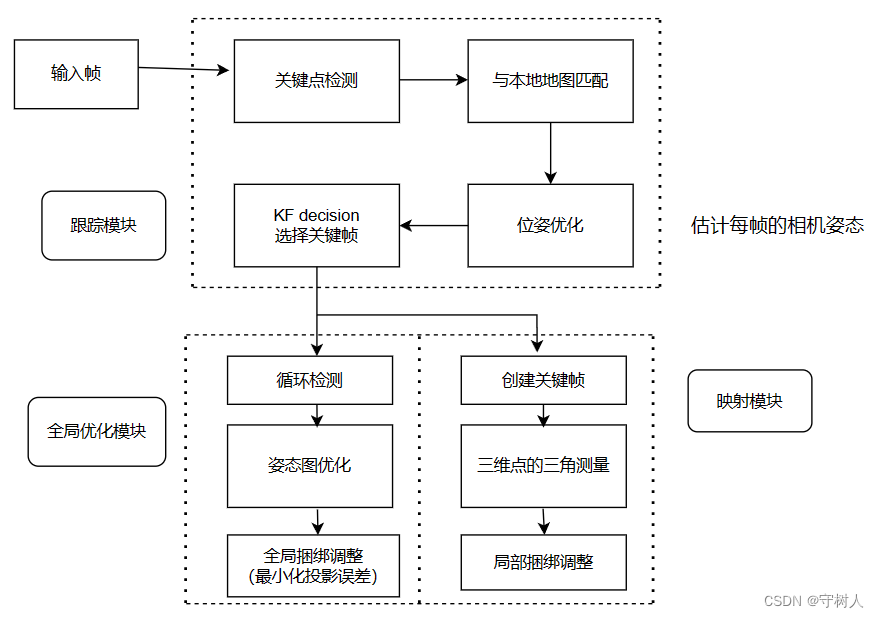
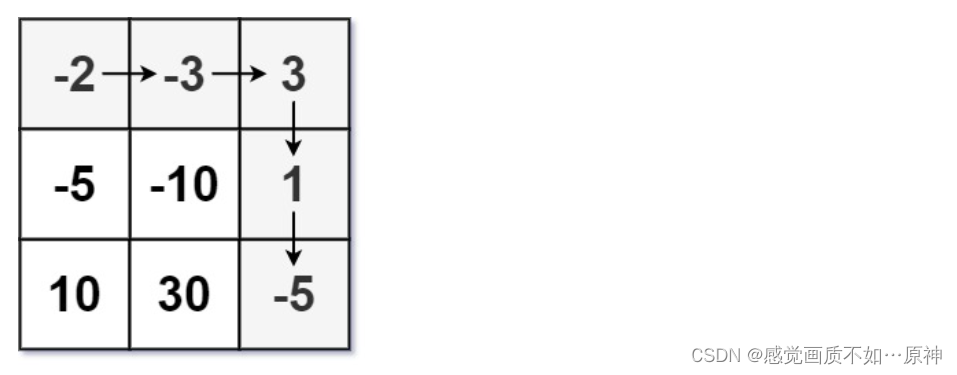
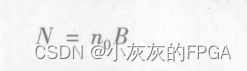1、前言
- 在机器学习过程中,我们经常需要对特征进行分类,例如:性别有男、女,国籍有中国、英国、美国等,种族有黄、白、黑。 但是分类器并不能直接对数据进行分类,所以我们需要先对数据进行处理。
- 如果要作为机器学习算法的输入,通常我们需要对特征进行数字化处理,例如:
- 性别:["男", "女"] => 0, 1
- 国籍:["中国", "英国", "美国"] => 0, 1, 2
- 种族:["黄", "白", "黑"] => 0, 1, 2
- 此时,某个样本的特征为["女", "美国", "白"],就可以用[1, 2, 1]来表示。
- 但这种特征处理方法并不能直接放入机器学习算法中,因为类别之间是无序的,所以需要进一步采用独热编码使其转化成有序且连续的数据。
2、定义
- 独热编码(One-Hot Encoding),又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。即只有一位是1,其余都是零值。
- 独热编码是利用0和1来表示一些参数,使用N位状态寄存器来对N个状态进行编码。
- 例如:
- 性别:["男", "女"]
- 男 => 10
- 女 => 01
- 国籍:["中国", "英国", "美国"]
- 中国 => 100
- 英国 => 010
- 美国 => 001
- 种族:["黄", "白", "黑"]
- 黄 => 100
- 白 => 010
- 黑 => 001
- 此时,某个样本的特征为["女", "美国", "白"],转换的结果就为:[0, 1, 0, 0, 1, 0, 1, 0]
- 性别:["男", "女"]
- 也就是说,将所有的特征排列在一起,有该特征即为1,没有该特征即为0。
3、作用
- One-hot编码是用于编码分类变量的技术,可以用于神经网络。对数据进行预处理去偏时,通常要确定2个相似个体特定特征之间的度量距离,One-hot编码能更加合理的计算特征之间的距离,从而达到去偏的效果。
- 也就是把特征之间距离的问题,转换为了计算向量之间距离的问题。
- 例如:
- 性别:["男", "女"]
- 男 => 10
- 女 => 01
- 国籍:["中国", "英国", "美国"]
- 中国 => 100
- 英国 => 010
- 美国 => 001
- 计算样本1:["女", "美国"]=[0, 1, 0, 0, 1],样本2:["男", "中国"]=[1, 0, 1, 0, 0]之间的距离。
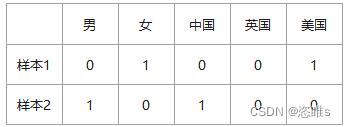
- 距离=
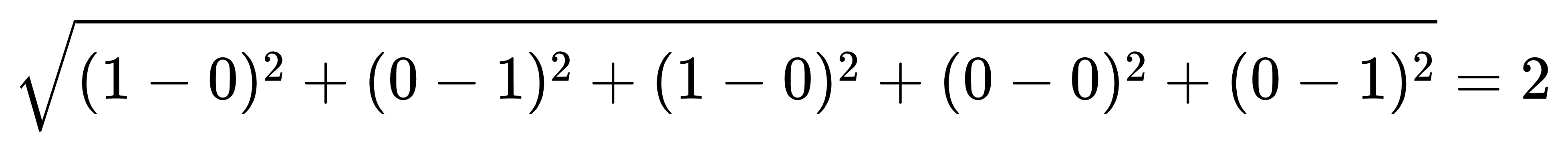
- 性别:["男", "女"]