当我们尝试那些开箱即用的GPU服务时,很快意识到在经济高效地利用GPU运行推荐模型服务之前需要对其优化。我们首先使用分析工具来分析在模型推理过程中发生了什么,在仔细观察分析结果时,我们注意到时间线上有大量的小CUDA Kernel在执行。
这是推荐系统模型的预期行为,其中数百个特征在模型后期阶段进行特征拼接之前需要单独处理。然而,对于大量的小算子,启动CUDA Kernel带来的开销比计算开销还要昂贵。与训练时的batchsize相比,模型服务时的batchsize相对更小,进而加剧了这一问题。

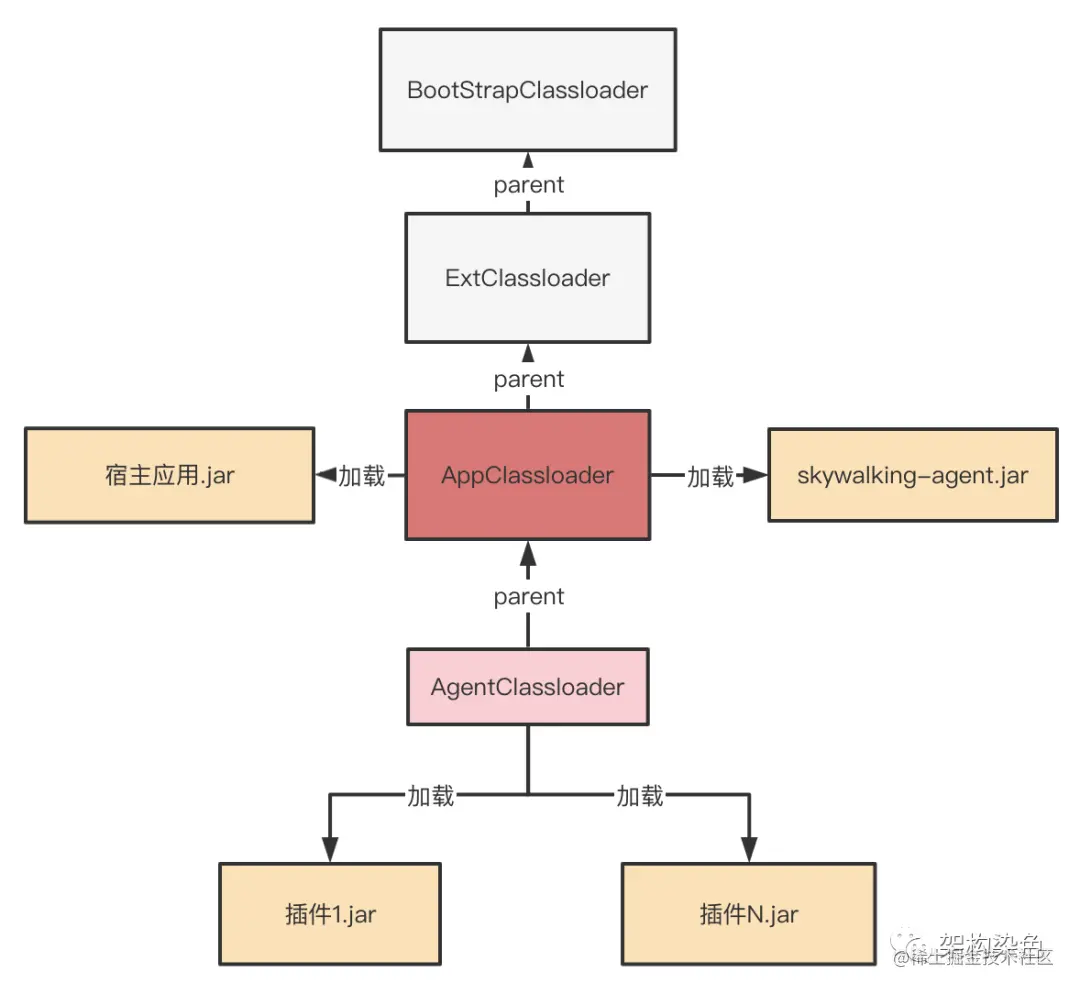
上图分别是模型优化前和优化后的分析结果。CUDA Kernel时间线(用红框突出显示)表明,Kernel的启动开销(蓝色块之间的间隙)显著减少,因此GPU得到了更好得利用,它将大部分时间花费在Kernel执行中。
cuCollections
我们采取的第一个方法是找出减少小op数量的机会。我们寻找常被使用的模型组件,并尽可能对其优化。其中一个例子是Embedding的查表模块,它包含两个计算步骤:原始ID到索引的查找,索引到Embedding的查找。由于我们有大量特征,这两步操作会被重复数百次。通过使用cuCollections (https://github.com/NVIDIA/cuCollections) 以支持GPU上原始ID的哈希表,并实现了自定义的Embedding查找模块以合并多个查找操作,我们显著地减少了op的数量。在执行一些优化后,马上看到了更优的性能表现。
cuda graph
GPU 架构的性能随着每一代的更新而不断提高。 现代 GPU 每个操作(如kernel运行或内存复制)所花费的时间现在以微秒为单位。 但是,将每个操作提交给 GPU 也会产生一些开销——也是微秒级的。实际的应用程序中经常要执行大量的 GPU 操作:典型模式涉及许多迭代(或时间步),每个步骤中有多个操作。 如果这些操作中的每一个都单独提交到 GPU 启动并独立计算,那么提交启动开销汇总在一起可能导致明显的整体性能下降。CUDA Graphs 将整个计算流程定义为一个图而不是单个操作的列表。 最后通过提供一种由单个 CPU 操作来启动图上的多个 GPU 操作的方式减少kernel提交启动开销,进而解决上述问题。
CUDA Graph允许我们将模型推理过程捕捉为静态图,而不是单独调度。它可以让整个计算作为一个单元进行执行,而不产生任何Kernel启动开销。我们支持将CUDA Graph作为模型服务的一个新后端。一开始加载模型时,模型服务执行一次模型推理以构建图实例,该实例可以针对实时流量重复执行。
CUDA Graph自身的一些限制给我们的模型服务带来了额外的复杂性。其中最大的限制是CUDA Graph要求所有Tensor都具有静态形状和布局,这对动态大小批次和不规则的变长Tensor带来了挑战。然而,我们相信为了获得更好性能进行的权衡是值得的,并且我们可以将输入Tensor补齐到精心挑选的静态形状。

![[附源码]Python计算机毕业设计Django汽配管理系统](https://img-blog.csdnimg.cn/70fb56155b7d42febb9f80bfb0e2c510.png)