PGInfo存在于PG的整个生命周期中,其在对象数据的写入、数据恢复、PG Peering过程中均发挥重要的作用。本章试图研究pg info在整个PG生命周期中的变化过程,从而对PG及PGInfo有一个更深入的理解。
class PG : DoutPrefixProvider {
public:
// pg state
pg_info_t info;
};
class ReplicatedPG : public PG, public PGBackend::Listener {
public:
const pg_info_t &get_info() const {
return info;
}
};
class PGBackend {
public:
Listener *parent;
Listener *get_parent() const { return parent; }
PGBackend(Listener *l, ObjectStore *store, coll_t coll, ObjectStore::CollectionHandle &ch) :
store(store),
coll(coll),
ch(ch),
parent(l) {}
const pg_info_t &get_info() { return get_parent()->get_info(); }
};从上面的代码可知,ReplicatedPG以及PGBackend中使用到的PGInfo均为PG::info。
1. pginfo相关数据结构
1.1 pg_info_t数据结构
pg_info_t数据结构定义在osd/osd_types.h头文件中,如下:
/**
* pg_info_t - summary of PG statistics.
*
* some notes:
* - last_complete implies we have all objects that existed as of that
* stamp, OR a newer object, OR have already applied a later delete.
* - if last_complete >= log.bottom, then we know pg contents thru log.head.
* otherwise, we have no idea what the pg is supposed to contain.
*/
struct pg_info_t {
spg_t pgid;
eversion_t last_update; ///< last object version applied to store.
eversion_t last_complete; ///< last version pg was complete through.
epoch_t last_epoch_started; ///< last epoch at which this pg started on this osd
version_t last_user_version; ///< last user object version applied to store
eversion_t log_tail; ///< oldest log entry.
hobject_t last_backfill; ///< objects >= this and < last_complete may be missing
bool last_backfill_bitwise; ///< true if last_backfill reflects a bitwise (vs nibblewise) sort
interval_set<snapid_t> purged_snaps;
pg_stat_t stats;
pg_history_t history;
pg_hit_set_history_t hit_set;
};下面我们分别介绍一下各字段:
1.1.1 pgid
pgid用于保存当前PG的pgid信息。
1.1.2 last_update
//src/include/types.h
// NOTE: these must match ceph_fs.h typedefs
typedef uint64_t ceph_tid_t; // transaction id
typedef uint64_t version_t;
typedef __u32 epoch_t; // map epoch (32bits -> 13 epochs/second for 10 years)
//osd/osd_types.h
class eversion_t {
public:
version_t version;
epoch_t epoch;
__u32 __pad;
};last_update表示PG内最近一次更新的对象版本,还没有在所有OSD上更新完成。在last_update与last_complete之间的操作表示该操作已经在部分OSD上完成,但是还没有全部完成。
下面我们来看一下pginfo.last_update在ceph整个运行过程中的更新操作:
1) PG数据写入阶段增加log entry
eversion_t get_next_version() const {
eversion_t at_version(get_osdmap()->get_epoch(),pg_log.get_head().version+1);
assert(at_version > info.last_update);
assert(at_version > pg_log.get_head());
return at_version;
}
void ReplicatedPG::execute_ctx(OpContext *ctx)
{
// version
ctx->at_version = get_next_version();
ctx->mtime = m->get_mtime();
}
void ReplicatedPG::finish_ctx(OpContext *ctx, int log_op_type, bool maintain_ssc,
bool scrub_ok)
{
...
// append to log
ctx->log.push_back(pg_log_entry_t(log_op_type, soid, ctx->at_version,
ctx->obs->oi.version,
ctx->user_at_version, ctx->reqid,
ctx->mtime));
}
void PG::add_log_entry(const pg_log_entry_t& e)
{
// raise last_complete only if we were previously up to date
if (info.last_complete == info.last_update)
info.last_complete = e.version;
// raise last_update.
assert(e.version > info.last_update);
info.last_update = e.version;
// raise user_version, if it increased (it may have not get bumped
// by all logged updates)
if (e.user_version > info.last_user_version)
info.last_user_version = e.user_version;
// log mutation
pg_log.add(e);
dout(10) << "add_log_entry " << e << dendl;
}从上面可以看到,在PG数据写入阶段,将pg_log_entry_t添加进pg_log时,会将info.last_update更新为ctx->at_version。
Question: pg_log.add(e)是将该pg_log_entry添加到内存中的,万一系统重启,内存中的pg_log_entry丢失怎么办?
Answer: 即使系统重启,内存中的pg_log_entry丢失其实也是没有问题的。系统重启之后,首先会读取日志,然后再进行peering操作,从而使3个副本重新达成一致。
2) 进入activate阶段更新本地保存的peer.last_update
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
// if primary..
if (is_primary()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == pg_whoami) continue;
pg_shard_t peer = *i;
pg_info_t& pi = peer_info[peer];
...
/*
* cover case where peer sort order was different and
* last_backfill cannot be interpreted
*/
bool force_restart_backfill =!pi.last_backfill.is_max() && pi.last_backfill_bitwise != get_sort_bitwise();
if (pi.last_update == info.last_update && !force_restart_backfill) {
//已经追上权威
}else if (pg_log.get_tail() > pi.last_update || pi.last_backfill == hobject_t() ||
force_restart_backfill ||(backfill_targets.count(*i) && pi.last_backfill.is_max())){
/* ^ This last case covers a situation where a replica is not contiguous
* with the auth_log, but is contiguous with this replica. Reshuffling
* the active set to handle this would be tricky, so instead we just go
* ahead and backfill it anyway. This is probably preferrable in any
* case since the replica in question would have to be significantly
* behind.
*/
// backfill(日志不重叠,采用backfill方式来进行恢复)
pi.last_update = info.last_update;
pi.last_complete = info.last_update;
pi.set_last_backfill(hobject_t(), get_sort_bitwise());
pi.last_epoch_started = info.last_epoch_started;
pi.history = info.history;
pi.hit_set = info.hit_set;
pi.stats.stats.clear();
}else{
//catch up(具有日志重叠,直接采用pglog进行恢复)
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), info);
// send new stuff to append to replicas log
//(拷贝pg_log中last_update之后的日志到m中)
m->log.copy_after(pg_log.get_log(), pi.last_update);
}
// peer now has(此处认为peer完成,因此更新本地pi.last_update)
pi.last_update = info.last_update;
}
}
}从上面的代码可以,当PG primary进入activate阶段,表示副本之间已经达成一致,此时对于PG primary来说,可以更新本地保存的peer.last_update为权威的last_update。
3)PG分裂时设置info.last_update
void PG::split_into(pg_t child_pgid, PG *child, unsigned split_bits)
{
...
pg_log.split_into(child_pgid, split_bits, &(child->pg_log));
child->info.last_complete = info.last_complete;
info.last_update = pg_log.get_head();
child->info.last_update = child->pg_log.get_head();
...
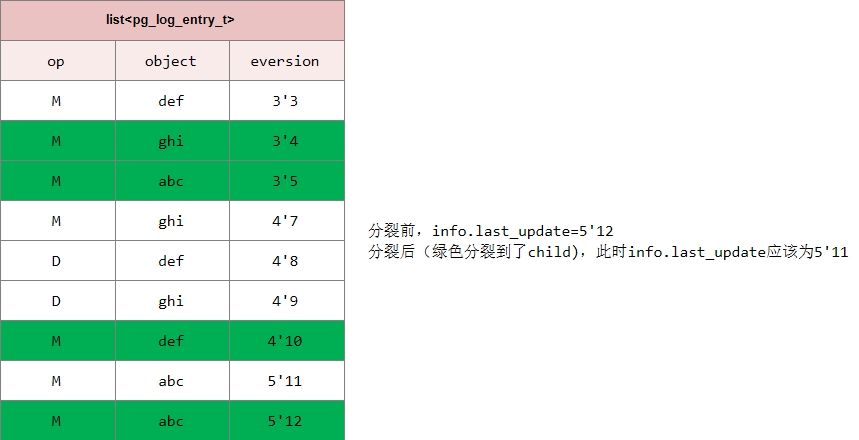
}在PG分裂时,肯定已经完成了peering操作,此时info.last_update必定等于pg_log.get_head,既然如此为何代码中还要在重新设置一遍呢?这是因为在PG分裂时,pg_log也要进行分裂,原来的head有可能被分裂到了child中了,因此这里需要重新设置当前PG的last_update。如下图所示:
4)恢复丢失的pglog时,更新info.last_update
void PG::append_log_entries_update_missing(const list<pg_log_entry_t> &entries, ObjectStore::Transaction &t)
{
assert(!entries.empty());
assert(entries.begin()->version > info.last_update);
PGLogEntryHandler rollbacker;
pg_log.append_new_log_entries(
info.last_backfill,
info.last_backfill_bitwise,
entries,
&rollbacker);
rollbacker.apply(this, &t);
info.last_update = pg_log.get_head();
if (pg_log.get_missing().num_missing() == 0) {
// advance last_complete since nothing else is missing!
info.last_complete = info.last_update;
}
info.stats.stats_invalid = true;
dirty_info = true;
write_if_dirty(t);
}从上面可以看到,在调用完成pg_log.append_new_log_entries()之后,会对info.last_update进行更新。下面我们来看一下在什么情况下会调用该函数:
- merge_new_log_entries()日志合并
void ReplicatedPG::submit_log_entries(
const list<pg_log_entry_t> &entries,
ObcLockManager &&manager,
boost::optional<std::function<void(void)> > &&on_complete)
{
...
ObjectStore::Transaction t;
eversion_t old_last_update = info.last_update;
merge_new_log_entries(entries, t);
...
}
void PG::merge_new_log_entries(const list<pg_log_entry_t> &entries,ObjectStore::Transaction &t)
{
...
append_log_entries_update_missing(entries, t);
...
}- do_update_log_missing()更新丢失日志
void ReplicatedPG::do_request(
OpRequestRef& op,
ThreadPool::TPHandle &handle)
{
...
switch (op->get_req()->get_type()) {
case MSG_OSD_PG_UPDATE_LOG_MISSING:
do_update_log_missing(op);
break;
}
}
void ReplicatedPG::do_update_log_missing(OpRequestRef &op)
{
...
ObjectStore::Transaction t;
append_log_entries_update_missing(m->entries, t);
...
}5) peering过程中处理副本日志,形成权威日志的过程中更新oinfo的last_update
void PGLog::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, const pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from) const
{
...
if (lu < oinfo.last_update) {
dout(10) << " peer osd." << from << " last_update now " << lu << dendl;
oinfo.last_update = lu;
}
}6) 处理有分歧日志时
boost::statechart::result PG::RecoveryState::Stray::react(const MInfoRec& infoevt)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "got info from osd." << infoevt.from << " " << infoevt.info << dendl;
if (pg->info.last_update > infoevt.info.last_update) {
// rewind divergent log entries
ObjectStore::Transaction* t = context<RecoveryMachine>().get_cur_transaction();
pg->rewind_divergent_log(*t, infoevt.info.last_update);
pg->info.stats = infoevt.info.stats;
pg->info.hit_set = infoevt.info.hit_set;
}
assert(infoevt.info.last_update == pg->info.last_update);
assert(pg->pg_log.get_head() == pg->info.last_update);
post_event(Activate(infoevt.info.last_epoch_started));
return transit<ReplicaActive>();
}
void PG::rewind_divergent_log(ObjectStore::Transaction& t, eversion_t newhead)
{
PGLogEntryHandler rollbacker;
pg_log.rewind_divergent_log(t, newhead, info, &rollbacker, dirty_info, dirty_big_info);
rollbacker.apply(this, &t);
}
/**
* rewind divergent entries at the head of the log
*
* This rewinds entries off the head of our log that are divergent.
* This is used by replicas during activation.
*
* @param t transaction
* @param newhead new head to rewind to
*/
void PGLog::rewind_divergent_log(ObjectStore::Transaction& t, eversion_t newhead,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
info.last_update = newhead;
}从上面可以看到,对于PG的非primary副本在进行peering过程中,会调用rewind_divergent_log()来回退分歧的日志,从而更新pginfo.last_update;
7)合并权威日志过程中
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
info.last_update = log.head = olog.head;
}8) issue_repop()更新本地保存的peerinfo
void ReplicatedPG::issue_repop(RepGather *repop, OpContext *ctx)
{
if (ctx->at_version > eversion_t()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == get_primary()) continue;
pg_info_t &pinfo = peer_info[*i];
// keep peer_info up to date
if (pinfo.last_complete == pinfo.last_update)
pinfo.last_complete = ctx->at_version;
pinfo.last_update = ctx->at_version;
}
}
}上面代码在PG写入流程中调用,直接更新本地保存的peerinfo的last_update;
9) 标记object丢失时,更新当前pginfo的last_update
/* Mark an object as lost
*/
ObjectContextRef ReplicatedPG::mark_object_lost(ObjectStore::Transaction *t,
const hobject_t &oid, eversion_t version,
utime_t mtime, int what)
{
// Add log entry
++info.last_update.version;
pg_log_entry_t e(what, oid, info.last_update, version, 0, osd_reqid_t(), mtime);
pg_log.add(e);
...
}总结
last_update永远指向当前PG副本的最新日志版本。只要日志发生了改变(如对象数据修改、pglog合并等)都可能会引起last_update的修改。
1.1.2 last_complete
在last_complete之前的版本都已经在所有OSD上完成更新(只表示内存更新已经完成)。
下面我们来看一下pginfo.last_complete在ceph整个运行过程中的更新操作:
1) PG初始化时,更新info.last_complete
void PG::init(
int role,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
const pg_history_t& history,
pg_interval_map_t& pi,
bool backfill,
ObjectStore::Transaction *t)
{
...
if (backfill) {
dout(10) << __func__ << ": Setting backfill" << dendl;
info.set_last_backfill(hobject_t(), get_sort_bitwise());
info.last_complete = info.last_update;
pg_log.mark_log_for_rewrite();
}
...
}从上面代码可知,当需要进行backfill时,会直接将info.last_complete更新为info.last_update。
2)PG数据写入过程中,如果上次已经更新到最新,则将info.last_complete更新为e.version
void PG::add_log_entry(const pg_log_entry_t& e)
{
// raise last_complete only if we were previously up to date
if (info.last_complete == info.last_update)
info.last_complete = e.version;
...
}3) peering完成,调用activate()激活PG时更新last_complete
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
// init complete pointer
if (missing.num_missing() == 0) {
dout(10) << "activate - no missing, moving last_complete " << info.last_complete << " -> " << info.last_update << dendl;
info.last_complete = info.last_update;
pg_log.reset_recovery_pointers();
} else {
dout(10) << "activate - not complete, " << missing << dendl;
pg_log.activate_not_complete(info);
}
...
}从上面我们可以看到,peering完成调用activate()激活PG时,如果missing为空,那么可以将info.last_complete直接更新为info.last_update。
4) 进入activate阶段更新本地保存的peer.last_complete
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
// if primary..
if (is_primary()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == pg_whoami) continue;
pg_shard_t peer = *i;
pg_info_t& pi = peer_info[peer];
...
/*
* cover case where peer sort order was different and
* last_backfill cannot be interpreted
*/
bool force_restart_backfill =!pi.last_backfill.is_max() && pi.last_backfill_bitwise != get_sort_bitwise();
if (pi.last_update == info.last_update && !force_restart_backfill) {
//已经追上权威
}else if (pg_log.get_tail() > pi.last_update || pi.last_backfill == hobject_t() ||
force_restart_backfill ||(backfill_targets.count(*i) && pi.last_backfill.is_max())){
/* ^ This last case covers a situation where a replica is not contiguous
* with the auth_log, but is contiguous with this replica. Reshuffling
* the active set to handle this would be tricky, so instead we just go
* ahead and backfill it anyway. This is probably preferrable in any
* case since the replica in question would have to be significantly
* behind.
*/
// backfill(日志不重叠,采用backfill方式来进行恢复)
pi.last_update = info.last_update;
pi.last_complete = info.last_update;
pi.set_last_backfill(hobject_t(), get_sort_bitwise());
pi.last_epoch_started = info.last_epoch_started;
pi.history = info.history;
pi.hit_set = info.hit_set;
pi.stats.stats.clear();
...
pm.clear();
}else{
//catch up(具有日志重叠,直接采用pglog进行恢复)
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), info);
// send new stuff to append to replicas log
//(拷贝pg_log中last_update之后的日志到m中)
m->log.copy_after(pg_log.get_log(), pi.last_update);
}
// peer now has(此处认为peer完成,因此更新本地pi.last_update)
pi.last_update = info.last_update;
// update our missing
if (pm.num_missing() == 0) {
pi.last_complete = pi.last_update;
dout(10) << "activate peer osd." << peer << " " << pi << " uptodate" << dendl;
} else {
dout(10) << "activate peer osd." << peer << " " << pi << " missing " << pm << dendl;
}
}
}
}从上面的代码可以,当PG primary进入activate阶段,表示副本之间已经达成一致,此时对于PG primary来说,如果确定peer并没有missing对象,则可以更新本地保存的peer.last_complete为peer.last_update。
5) PG进行分裂时,更新对应的last_complete
void PG::split_into(pg_t child_pgid, PG *child, unsigned split_bits)
{
...
// Log
pg_log.split_into(child_pgid, split_bits, &(child->pg_log));
child->info.last_complete = info.last_complete;
info.last_update = pg_log.get_head();
child->info.last_update = child->pg_log.get_head();
child->info.last_user_version = info.last_user_version;
info.log_tail = pg_log.get_tail();
child->info.log_tail = child->pg_log.get_tail();
if (info.last_complete < pg_log.get_tail())
info.last_complete = pg_log.get_tail();
if (child->info.last_complete < child->pg_log.get_tail())
child->info.last_complete = child->pg_log.get_tail();
...
}6) peering过程中,当缺失的日志补齐,更新info.last_complete
void PG::append_log_entries_update_missing(
const list<pg_log_entry_t> &entries,
ObjectStore::Transaction &t)
{
if (pg_log.get_missing().num_missing() == 0) {
// advance last_complete since nothing else is missing!
info.last_complete = info.last_update;
}
}7) peering过程中,形成权威日志上更新oinfo.last_complete
void PGLog::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, const pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from) const
{
...
if (omissing.have_missing()) {
eversion_t first_missing = omissing.missing[omissing.rmissing.begin()->second].need;
oinfo.last_complete = eversion_t();
list<pg_log_entry_t>::const_iterator i = olog.log.begin();
for (;i != olog.log.end();++i) {
if (i->version < first_missing)
oinfo.last_complete = i->version;
else
break;
}
} else {
oinfo.last_complete = oinfo.last_update;
}
...
}从上面我们可以看到,在处理副本日志时,如果pg missing不为空,则从权威pg log中找出该PG副本第一个丢失的日志,那么oinfo.last_complete就是对应前一条日志的版本; 否则(即pg missing为空),oinfo.last_complete就是oinfo.last_update。
8) peering过程中,rewind分歧日志时,可能需要回滚last_complete
boost::statechart::result PG::RecoveryState::Stray::react(const MInfoRec& infoevt)
{
...
if (pg->info.last_update > infoevt.info.last_update) {
...
pg->rewind_divergent_log(*t, infoevt.info.last_update);
}
...
}
/**
* rewind divergent entries at the head of the log
*
* This rewinds entries off the head of our log that are divergent.
* This is used by replicas during activation.
*
* @param t transaction
* @param newhead new head to rewind to
*/
void PGLog::rewind_divergent_log(ObjectStore::Transaction& t, eversion_t newhead,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
...
log.head = newhead;
info.last_update = newhead;
if (info.last_complete > newhead)
info.last_complete = newhead;
...
}9) recover恢复阶段,提升info.last_complete
void recover_got(hobject_t oid, eversion_t v, pg_info_t &info) {
if (missing.is_missing(oid, v)) {
missing.got(oid, v);
// raise last_complete?
if (missing.missing.empty()) {
log.complete_to = log.log.end();
info.last_complete = info.last_update;
}
while (log.complete_to != log.log.end()) {
if (missing.missing[missing.rmissing.begin()->second].need <= log.complete_to->version)
break;
if (info.last_complete < log.complete_to->version)
info.last_complete = log.complete_to->version;
++log.complete_to;
}
}
if (log.can_rollback_to < v)
log.can_rollback_to = v;
}10) 进入uncomplete状态时,更新info.last_complete
void activate_not_complete(pg_info_t &info) {
log.complete_to = log.log.begin();
while (log.complete_to->version < missing.missing[missing.rmissing.begin()->second].need)
++log.complete_to;
assert(log.complete_to != log.log.end());
if (log.complete_to == log.log.begin()) {
info.last_complete = eversion_t();
} else {
--log.complete_to;
info.last_complete = log.complete_to->version;
++log.complete_to;
}
log.last_requested = 0;
}11) issue_repop()更新本地保存的peerinfo
void ReplicatedPG::issue_repop(RepGather *repop, OpContext *ctx)
{
if (ctx->at_version > eversion_t()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == get_primary()) continue;
pg_info_t &pinfo = peer_info[*i];
// keep peer_info up to date
if (pinfo.last_complete == pinfo.last_update)
pinfo.last_complete = ctx->at_version;
pinfo.last_update = ctx->at_version;
}
}
}上面代码在PG写入流程中调用,直接更新本地保存的peerinfo的last_complete;
12) recovery阶段,当没有Object missing,更新info.last_complete
bool ReplicatedPG::start_recovery_ops(
int max, ThreadPool::TPHandle &handle,
int *ops_started)
{
...
if (num_missing == 0) {
info.last_complete = info.last_update;
}
...
}总结
通过上面,我们发现pginfo.last_complete的确切含义似乎不是很好理解,下面我们再来看一下代码中对该字段的注释:
/**
* pg_info_t - summary of PG statistics.
*
* some notes:
* - last_complete implies we have all objects that existed as of that
* stamp, OR a newer object, OR have already applied a later delete.
* - if last_complete >= log.bottom, then we know pg contents thru log.head.
* otherwise, we have no idea what the pg is supposed to contain.
*/
struct pg_info_t {
eversion_t last_complete; ///< last version pg was complete through.
};“last version pg was complete through”翻译成中文为:上一版PG已经完成。那么是否可以理解为:在last_complete之前的版本都在所有OSD上更新完成,而对于last_complete本身则是不确定的。
1.1.4 last_epoch_started
last_epoch_started表示指定PG在本OSD上启动时的epoch值。我们先来看一下doc/dev/osd_internals/last_epoch_started对该字段的描述:
info.last_epoch_started records an activation epoch e for interval i
such that all writes commited in i or earlier are reflected in the
local info/log and no writes after i are reflected in the local
info/log. Since no committed write is ever divergent, even if we
get an authoritative log/info with an older info.last_epoch_started,
we can leave our info.last_epoch_started alone since no writes could
have commited in any intervening interval (See PG::proc_master_log).
info.history.last_epoch_started records a lower bound on the most
recent interval in which the pg as a whole went active and accepted
writes. On a particular osd, it is also an upper bound on the
activation epoch of intervals in which writes in the local pg log
occurred (we update it before accepting writes). Because all
committed writes are committed by all acting set osds, any
non-divergent writes ensure that history.last_epoch_started was
recorded by all acting set members in the interval. Once peering has
queried one osd from each interval back to some seen
history.last_epoch_started, it follows that no interval after the max
history.last_epoch_started can have reported writes as committed
(since we record it before recording client writes in an interval).
Thus, the minimum last_update across all infos with
info.last_epoch_started >= MAX(history.last_epoch_started) must be an
upper bound on writes reported as committed to the client.
We update info.last_epoch_started with the intial activation message,
but we only update history.last_epoch_started after the new
info.last_epoch_started is persisted (possibly along with the first
write). This ensures that we do not require an osd with the most
recent info.last_epoch_started until all acting set osds have recorded
it.
In find_best_info, we do include info.last_epoch_started values when
calculating the max_last_epoch_started_found because we want to avoid
designating a log entry divergent which in a prior interval would have
been non-divergent since it might have been used to serve a read. In
activate(), we use the peer's last_epoch_started value as a bound on
how far back divergent log entries can be found.
However, in a case like
.. code:: none
calc_acting osd.0 1.4e( v 473'302 (292'200,473'302] local-les=473 n=4 ec=5 les/c 473/473 556/556/556
calc_acting osd.1 1.4e( v 473'302 (293'202,473'302] lb 0//0//-1 local-les=477 n=0 ec=5 les/c 473/473 556/556/556
calc_acting osd.4 1.4e( v 473'302 (120'121,473'302] local-les=473 n=4 ec=5 les/c 473/473 556/556/556
calc_acting osd.5 1.4e( empty local-les=0 n=0 ec=5 les/c 473/473 556/556/556
since osd.1 is the only one which recorded info.les=477 while 4,0
which were the acting set in that interval did not (4 restarted and 0
did not get the message in time) the pg is marked incomplete when
either 4 or 0 would have been valid choices. To avoid this, we do not
consider info.les for incomplete peers when calculating
min_last_epoch_started_found. It would not have been in the acting
set, so we must have another osd from that interval anyway (if
maybe_went_rw). If that osd does not remember that info.les, then we
cannot have served reads.从上面的描述中我们知道,info.last_epoch_started记录的是在一个interval内该PG activation时候的epoch值,即该interval的第一个epoch值。由于在一个interval内,PG的所有副本OSD将不会发生任何变动,因此在该interval及之前所提交的写操作均会反应到local info/log中。因为所有已提交的写操作均不会出现分歧,因此即使我们获取到last_epoch_started值更为老旧的权威info/log信息,我们也仍然可以保持info.last_epoch_started的独立性(即:当我们获取到的权威info/log的last_epoch_started小于当前info.last_epoch_started时,我们不必对当前info.last_epoch_started进行修改)。
info.history.last_epoch_started记录的是PG最近一次整体进入active状态并开始接受写操作时的下边界epoch值。对于一个特定的OSD,info.history.last_epoch_started记录的intervals中PG activation时epoch的上边界值。因为所有committed writes都被提交到了acting set中的所有OSD副本,任何非歧义性的写操作都会确保info.history.last_epoch_started被acting set中的所有副本所记录。因此,在peering中向一个OSD查询info.history.last_epoch_started到某一个interval之间的信息时,并不会将max(info.history.last_epoch_started)之后interval的写操作报告为committed。因此,在PG各副本info.last_epoch_started >= MAX(history.last_epoch_started)的info中,last_update的最小值即为已成功提交的写操作的上边界。 如下图所示:

我们会在首次接收到activation消息的时候就更新info.last_epoch_started,但是只有在新的info.last_epoch_started被持久化之后我们才会更新history.last_epoch_started。这就确保了在acting set中的所有OSD都成功记录info.last_epoch_started之前,我们并不需要获取OSD上最新的info.last_epoch_started。
下面我们来看一下其在PG整个生命周期中的更新操作:
1) 处理权威日志时,更新pginfo.last_epoch_started
void PG::proc_master_log(
ObjectStore::Transaction& t, pg_info_t &oinfo,
pg_log_t &olog, pg_missing_t& omissing, pg_shard_t from)
{
// See doc/dev/osd_internals/last_epoch_started
if (oinfo.last_epoch_started > info.last_epoch_started) {
info.last_epoch_started = oinfo.last_epoch_started;
dirty_info = true;
}
}可以看到,这里是从权威pginfo以及本地pginfo中选出一个较大的last_epoch_started作为info.last_epoch_started。
2)PG::activate()激活时更新
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
if (is_primary()) {
// only update primary last_epoch_started if we will go active
if (acting.size() >= pool.info.min_size) {
assert(cct->_conf->osd_find_best_info_ignore_history_les || info.last_epoch_started <= activation_epoch);
info.last_epoch_started = activation_epoch;
}
} else if (is_acting(pg_whoami)) {
/* update last_epoch_started on acting replica to whatever the primary sent
* unless it's smaller (could happen if we are going peered rather than
* active, see doc/dev/osd_internals/last_epoch_started.rst) */
*
if (info.last_epoch_started < activation_epoch)
info.last_epoch_started = activation_epoch;
}
...
}从上面可以看出,对于PG Primary来说,直接将激活时的activation_epoch设置为info.last_epoch_started,即在activate完成新一轮的last_epoch_started的设置;对于PG replicas而言,则当收到primary发送的activation_epoch较大时,更新其last_epoch_started值。
3) PG::activate()更新本地保存的peerinfo.last_epoch_started
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
// if primary..
if (is_primary()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == pg_whoami) continue;
pg_shard_t peer = *i;
pg_info_t& pi = peer_info[peer];
...
/*
* cover case where peer sort order was different and
* last_backfill cannot be interpreted
*/
bool force_restart_backfill =!pi.last_backfill.is_max() && pi.last_backfill_bitwise != get_sort_bitwise();
if (pi.last_update == info.last_update && !force_restart_backfill) {
//已经追上权威
}else if (pg_log.get_tail() > pi.last_update || pi.last_backfill == hobject_t() ||
force_restart_backfill ||(backfill_targets.count(*i) && pi.last_backfill.is_max())){
/* ^ This last case covers a situation where a replica is not contiguous
* with the auth_log, but is contiguous with this replica. Reshuffling
* the active set to handle this would be tricky, so instead we just go
* ahead and backfill it anyway. This is probably preferrable in any
* case since the replica in question would have to be significantly
* behind.
*/
// backfill(日志不重叠,采用backfill方式来进行恢复)
pi.last_update = info.last_update;
pi.last_complete = info.last_update;
pi.set_last_backfill(hobject_t(), get_sort_bitwise());
pi.last_epoch_started = info.last_epoch_started;
pi.history = info.history;
pi.hit_set = info.hit_set;
pi.stats.stats.clear();
...
pm.clear();
}else{
//catch up(具有日志重叠,直接采用pglog进行恢复)
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), info);
// send new stuff to append to replicas log
//(拷贝pg_log中last_update之后的日志到m中)
m->log.copy_after(pg_log.get_log(), pi.last_update);
}
....
}
}
}4) Replicas激活完成,调用_activate_committed()通知primary
void PG::_activate_committed(epoch_t epoch, epoch_t activation_epoch)
{
lock();
if (pg_has_reset_since(epoch)) {
...
}else if (is_primary()) {
...
}else {
dout(10) << "_activate_committed " << epoch << " telling primary" << dendl;
MOSDPGInfo *m = new MOSDPGInfo(epoch);
pg_notify_t i = pg_notify_t(
get_primary().shard, pg_whoami.shard,
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
info);
i.info.history.last_epoch_started = activation_epoch;
...
}
...
}上面发送pg_notify_t消息,将info.history.last_epoch_started设置为了activation_epoch。
5)PG分裂设置child的last_epoch_started
void PG::split_into(pg_t child_pgid, PG *child, unsigned split_bits)
{
...
child->info.last_epoch_started = info.last_epoch_started;
}6) PG replica写数据时,更新history.last_epoch_started
void PG::append_log(
const vector<pg_log_entry_t>& logv,
eversion_t trim_to,
eversion_t trim_rollback_to,
ObjectStore::Transaction &t,
bool transaction_applied)
{
...
/* The primary has sent an info updating the history, but it may not
* have arrived yet. We want to make sure that we cannot remember this
* write without remembering that it happened in an interval which went
* active in epoch history.last_epoch_started.
*/
if (info.last_epoch_started != info.history.last_epoch_started) {
info.history.last_epoch_started = info.last_epoch_started;
}
...
}7) share pginfo时,更新本地保存的peerinfo.last_epoch_started
// the part that actually finalizes a scrub
void PG::scrub_finish()
{
...
if (is_active() && is_primary()) {
share_pg_info();
}
}
void PG::share_pg_info()
{
dout(10) << "share_pg_info" << dendl;
// share new pg_info_t with replicas
assert(!actingbackfill.empty());
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == pg_whoami) continue;
pg_shard_t peer = *i;
if (peer_info.count(peer)) {
peer_info[peer].last_epoch_started = info.last_epoch_started;
peer_info[peer].history.merge(info.history);
}
MOSDPGInfo *m = new MOSDPGInfo(get_osdmap()->get_epoch());
m->pg_list.push_back(
make_pair(
pg_notify_t(
peer.shard, pg_whoami.shard,
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
info),
pg_interval_map_t()));
osd->send_message_osd_cluster(peer.osd, m, get_osdmap()->get_epoch());
}
}上面的代码中,当scrub完成时,PG Primary就会更新本地保存的peer_info信息,并将其发送到对应的副本以更新对应副本上的pginfo信息。
8)当所有副本被激活时,更新info.history.last_epoch_started
boost::statechart::result PG::RecoveryState::Active::react(const AllReplicasActivated &evt)
{
PG *pg = context< RecoveryMachine >().pg;
all_replicas_activated = true;
pg->state_clear(PG_STATE_ACTIVATING);
pg->state_clear(PG_STATE_CREATING);
if (pg->acting.size() >= pg->pool.info.min_size) {
pg->state_set(PG_STATE_ACTIVE);
} else {
pg->state_set(PG_STATE_PEERED);
}
// info.last_epoch_started is set during activate()
pg->info.history.last_epoch_started = pg->info.last_epoch_started;
pg->dirty_info = true;
pg->share_pg_info();
pg->publish_stats_to_osd();
pg->check_local();
// waiters
if (pg->flushes_in_progress == 0) {
pg->requeue_ops(pg->waiting_for_peered);
}
pg->on_activate();
return discard_event();
}从上面的代码中,我们看到当peering完成,所有的副本完成激活时,会将info.last_epoch_started赋值给history.last_epoch_started。
9)pginfo初始化时,将last_epoch_started置为0
pg_info_t()
: last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }
// cppcheck-suppress noExplicitConstructor
pg_info_t(spg_t p)
: pgid(p),
last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }1.1.4 last_user_version
用于记录用户所更新对象的最大版本号。
下面我们来看一下其在PG整个生命周期中的更新操作:
1) last_user_version初始化
pg_info_t()
: last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }
// cppcheck-suppress noExplicitConstructor
pg_info_t(spg_t p)
: pgid(p),
last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }在PGInfo初始化时,将last_user_version均初始化为0值。
2) PG分裂时,从父PG中拷贝info.last_user_version的值
void PG::split_into(pg_t child_pgid, PG *child, unsigned split_bits)
{
...
child->info.last_user_version = info.last_user_version;
...
}3) 数据更新操作,添加log entry时更新last_user_version
void PG::add_log_entry(const pg_log_entry_t& e)
{
// raise last_complete only if we were previously up to date
if (info.last_complete == info.last_update)
info.last_complete = e.version;
// raise last_update.
assert(e.version > info.last_update);
info.last_update = e.version;
// raise user_version, if it increased (it may have not get bumped
// by all logged updates)
if (e.user_version > info.last_user_version)
info.last_user_version = e.user_version;
// log mutation
pg_log.add(e);
dout(10) << "add_log_entry " << e << dendl;
}4)merge_log时更新info.last_user_version
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
...
info.last_user_version = oinfo.last_user_version;
...
}5) finish_ctx()更新last_user_version
void ReplicatedPG::finish_ctx(OpContext *ctx, int log_op_type, bool maintain_ssc,
bool scrub_ok)
{
...
// finish and log the op.
if (ctx->user_modify) {
// update the user_version for any modify ops, except for the watch op
ctx->user_at_version = MAX(info.last_user_version, ctx->new_obs.oi.user_version) + 1;
/* In order for new clients and old clients to interoperate properly
* when exchanging versions, we need to lower bound the user_version
* (which our new clients pay proper attention to)
* by the at_version (which is all the old clients can ever see). */
if (ctx->at_version.version > ctx->user_at_version)
ctx->user_at_version = ctx->at_version.version;
ctx->new_obs.oi.user_version = ctx->user_at_version;
}
...
}1.1.5 log_tail
log_tail指向pg log最老的那条记录。下面我们来看其在整个PG生命周期中的变化:
1) PG分裂时,生成新的log_tail
void PG::split_into(pg_t child_pgid, PG *child, unsigned split_bits)
{
...
info.log_tail = pg_log.get_tail();
child->info.log_tail = child->pg_log.get_tail();
...
}PG分裂时,日志也会进行分裂。
2) trim日志时,log_tail移动
void PGLog::trim(
LogEntryHandler *handler,
eversion_t trim_to,
pg_info_t &info)
{
// trim?
if (trim_to > log.tail) {
/* If we are trimming, we must be complete up to trim_to, time
* to throw out any divergent_priors
*/
if (!divergent_priors.empty()) {
dirty_divergent_priors = true;
}
divergent_priors.clear();
// We shouldn't be trimming the log past last_complete
assert(trim_to <= info.last_complete);
dout(10) << "trim " << log << " to " << trim_to << dendl;
log.trim(handler, trim_to, &trimmed);
info.log_tail = log.tail;
}
}3) merge_log时,更新info.log_tail
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
...
bool changed = false;
// extend on tail?
// this is just filling in history. it does not affect our
// missing set, as that should already be consistent with our
// current log.
if (olog.tail < log.tail) {
dout(10) << "merge_log extending tail to " << olog.tail << dendl;
list<pg_log_entry_t>::iterator from = olog.log.begin();
list<pg_log_entry_t>::iterator to;
eversion_t last;
for (to = from;to != olog.log.end();++to) {
if (to->version > log.tail)
break;
log.index(*to);
dout(15) << *to << dendl;
last = to->version;
}
mark_dirty_to(last);
// splice into our log.
log.log.splice(log.log.begin(),
olog.log, from, to);
info.log_tail = log.tail = olog.tail;
changed = true;
}
...
}4) 读取PGlog时,更新log.tail
void PG::read_state(ObjectStore *store, bufferlist &bl)
{
int r = read_info(store, pg_id, coll, bl, info, past_intervals,info_struct_v);
assert(r >= 0);
if (g_conf->osd_hack_prune_past_intervals) {
_simplify_past_intervals(past_intervals);
}
ostringstream oss;
pg_log.read_log(store,
coll,
info_struct_v < 8 ? coll_t::meta() : coll,
ghobject_t(info_struct_v < 8 ? OSD::make_pg_log_oid(pg_id) : pgmeta_oid),
info, oss, cct->_conf->osd_ignore_stale_divergent_priors);
>
if (oss.tellp())
osd->clog->error() << oss.rdbuf();
// log any weirdness
log_weirdness();
}
void read_log(ObjectStore *store, coll_t pg_coll,
coll_t log_coll, ghobject_t log_oid,
const pg_info_t &info, ostringstream &oss,
bool tolerate_divergent_missing_log) {
return read_log(
store, pg_coll, log_coll, log_oid, info, divergent_priors,
log, missing, oss, tolerate_divergent_missing_log,
this,
(pg_log_debug ? &log_keys_debug : 0));
}
void PGLog::read_log(ObjectStore *store, coll_t pg_coll,
coll_t log_coll,
ghobject_t log_oid,
const pg_info_t &info,
map<eversion_t, hobject_t> &divergent_priors,
IndexedLog &log,
pg_missing_t &missing,
ostringstream &oss,
bool tolerate_divergent_missing_log,
const DoutPrefixProvider *dpp,
set<string> *log_keys_debug)
{
...
// legacy?
struct stat st;
int r = store->stat(log_coll, log_oid, &st);
assert(r == 0);
assert(st.st_size == 0);
log.tail = info.log_tail;
...
}1.1.6 last_backfill
last_backfill用于记录上一次backfill到的位置,处于[last_backfill, last_complete)之间的对象可能处于missing状态。下面我们来看一下本字段在PG整个生命周期里的变化。
1) PGinfo初始化时设置last_backfill
pg_info_t()
: last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }
// cppcheck-suppress noExplicitConstructor
pg_info_t(spg_t p)
: pgid(p),
last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }初始化时,还不知道有哪些对象缺失,因此直接设置为hobject_t::get_max()。
2)activate()时根据权威日志计算出所要backfill的对象列表
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
// if primary..
if (is_primary()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == pg_whoami) continue;
pg_shard_t peer = *i;
pg_info_t& pi = peer_info[peer];
...
/*
* cover case where peer sort order was different and
* last_backfill cannot be interpreted
*/
bool force_restart_backfill =!pi.last_backfill.is_max() && pi.last_backfill_bitwise != get_sort_bitwise();
if (pi.last_update == info.last_update && !force_restart_backfill) {
//已经追上权威
}else if (pg_log.get_tail() > pi.last_update || pi.last_backfill == hobject_t() ||
force_restart_backfill ||(backfill_targets.count(*i) && pi.last_backfill.is_max())){
/* ^ This last case covers a situation where a replica is not contiguous
* with the auth_log, but is contiguous with this replica. Reshuffling
* the active set to handle this would be tricky, so instead we just go
* ahead and backfill it anyway. This is probably preferrable in any
* case since the replica in question would have to be significantly
* behind.
*/
// backfill(日志不重叠,采用backfill方式来进行恢复)
pi.last_update = info.last_update;
pi.last_complete = info.last_update;
pi.set_last_backfill(hobject_t(), get_sort_bitwise());
pi.last_epoch_started = info.last_epoch_started;
pi.history = info.history;
pi.hit_set = info.hit_set;
pi.stats.stats.clear();
...
pm.clear();
}else{
//catch up(具有日志重叠,直接采用pglog进行恢复)
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), info);
// send new stuff to append to replicas log
//(拷贝pg_log中last_update之后的日志到m中)
m->log.copy_after(pg_log.get_log(), pi.last_update);
}
....
}
}
}3) PG分裂时,计算出child的last_backfill
void PG::split_into(pg_t child_pgid, PG *child, unsigned split_bits)
{
...
if (info.last_backfill.is_max()) {
child->info.set_last_backfill(hobject_t::get_max(),info.last_backfill_bitwise);
} else {
// restart backfill on parent and child to be safe. we could
// probably do better in the bitwise sort case, but it's more
// fragile (there may be special work to do on backfill completion
// in the future).
info.set_last_backfill(hobject_t(), info.last_backfill_bitwise);
child->info.set_last_backfill(hobject_t(), info.last_backfill_bitwise);
}
...
}如果父PG没有需要backfill的对象,那么自然child pg也是没有,直接设置为hobject_t::get_max()即可;如果父PG有需要backfill的对象,那么则将父PG及子PG的last_backfill均设置为hobject_t(),重新开始进行backfill操作。
4) PG初始化时,根据backfill标志设置last_backfill
void PG::init(
int role,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
const pg_history_t& history,
pg_interval_map_t& pi,
bool backfill,
ObjectStore::Transaction *t)
{
...
if (backfill) {
dout(10) << __func__ << ": Setting backfill" << dendl;
info.set_last_backfill(hobject_t(), get_sort_bitwise());
info.last_complete = info.last_update;
pg_log.mark_log_for_rewrite();
}
...
}5) 收到MOSDPGBackfill消息时设置last_backfill
void ReplicatedPG::do_backfill(OpRequestRef op)
{
...
switch (m->op) {
...
case MOSDPGBackfill::OP_BACKFILL_PROGRESS:
{
assert(cct->_conf->osd_kill_backfill_at != 2);
info.set_last_backfill(m->last_backfill, get_sort_bitwise());
if (m->compat_stat_sum) {
info.stats.stats = m->stats.stats; // Previously, we only sent sum
} else {
info.stats = m->stats;
}
ObjectStore::Transaction t;
dirty_info = true;
write_if_dirty(t);
int tr = osd->store->queue_transaction(osr.get(), std::move(t), NULL);
assert(tr == 0);
}
break;
...
}
...6) on_removal时设置last_backfill
void ReplicatedPG::on_removal(ObjectStore::Transaction *t)
{
dout(10) << "on_removal" << dendl;
// adjust info to backfill
info.set_last_backfill(hobject_t(), true);
dirty_info = true;
// clear log
PGLogEntryHandler rollbacker;
pg_log.clear_can_rollback_to(&rollbacker);
rollbacker.apply(this, t);
write_if_dirty(*t);
if (!deleting)
on_shutdown();
}7) recover_backfill()时设置last_backfill
/**
* recover_backfill
*
* Invariants:
*
* backfilled: fully pushed to replica or present in replica's missing set (both
* our copy and theirs).
*
* All objects on a backfill_target in
* [MIN,peer_backfill_info[backfill_target].begin) are either
* not present or backfilled (all removed objects have been removed).
* There may be PG objects in this interval yet to be backfilled.
*
* All objects in PG in [MIN,backfill_info.begin) have been backfilled to all
* backfill_targets. There may be objects on backfill_target(s) yet to be deleted.
*
* For a backfill target, all objects < MIN(peer_backfill_info[target].begin,
* backfill_info.begin) in PG are backfilled. No deleted objects in this
* interval remain on the backfill target.
*
* For a backfill target, all objects <= peer_info[target].last_backfill
* have been backfilled to target
*
* There *MAY* be objects between last_backfill_started and
* MIN(peer_backfill_info[*].begin, backfill_info.begin) in the event that client
* io created objects since the last scan. For this reason, we call
* update_range() again before continuing backfill.
*/
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
// If new_last_backfill == MAX, then we will send OP_BACKFILL_FINISH to
// all the backfill targets. Otherwise, we will move last_backfill up on
// those targets need it and send OP_BACKFILL_PROGRESS to them.
for (set<pg_shard_t>::iterator i = backfill_targets.begin();i != backfill_targets.end();++i) {
pg_shard_t bt = *i;
pg_info_t& pinfo = peer_info[bt];
if (cmp(new_last_backfill, pinfo.last_backfill, get_sort_bitwise()) > 0) {
pinfo.set_last_backfill(new_last_backfill, get_sort_bitwise());
epoch_t e = get_osdmap()->get_epoch();
MOSDPGBackfill *m = NULL;
...
}
}
...
}1.2 pg_stat_t数据结构
pg_stat_t数据结构用于保存当前PG的状态信息,其定义在osd/osd_types.h头文件中:
/** pg_stat
* aggregate stats for a single PG.
*/
struct pg_stat_t {
/**************************************************************************
* WARNING: be sure to update the operator== when adding/removing fields! *
**************************************************************************/
eversion_t version;
version_t reported_seq; // sequence number
epoch_t reported_epoch; // epoch of this report
__u32 state;
utime_t last_fresh; // last reported
utime_t last_change; // new state != previous state
utime_t last_active; // state & PG_STATE_ACTIVE
utime_t last_peered; // state & PG_STATE_ACTIVE || state & PG_STATE_PEERED
utime_t last_clean; // state & PG_STATE_CLEAN
utime_t last_unstale; // (state & PG_STATE_STALE) == 0
utime_t last_undegraded; // (state & PG_STATE_DEGRADED) == 0
utime_t last_fullsized; // (state & PG_STATE_UNDERSIZED) == 0
eversion_t log_start; // (log_start,version]
eversion_t ondisk_log_start; // there may be more on disk
epoch_t created;
epoch_t last_epoch_clean;
pg_t parent;
__u32 parent_split_bits;
eversion_t last_scrub;
eversion_t last_deep_scrub;
utime_t last_scrub_stamp;
utime_t last_deep_scrub_stamp;
utime_t last_clean_scrub_stamp;
object_stat_collection_t stats;
int64_t log_size;
int64_t ondisk_log_size; // >= active_log_size
vector<int32_t> up, acting;
epoch_t mapping_epoch;
vector<int32_t> blocked_by; ///< osds on which the pg is blocked
utime_t last_became_active;
utime_t last_became_peered;
/// up, acting primaries
int32_t up_primary;
int32_t acting_primary;
bool stats_invalid:1;
/// true if num_objects_dirty is not accurate (because it was not
/// maintained starting from pool creation)
bool dirty_stats_invalid:1;
bool omap_stats_invalid:1;
bool hitset_stats_invalid:1;
bool hitset_bytes_stats_invalid:1;
bool pin_stats_invalid:1;
};3) pg_history_t数据结构
pg_history_t用于保存PG最近的peering/mapping历史记录,其定义在osd/osd_types.h头文件中:
/**
* pg_history_t - information about recent pg peering/mapping history
*
* This is aggressively shared between OSDs to bound the amount of past
* history they need to worry about.
*/
struct pg_history_t {
epoch_t epoch_created; // epoch in which PG was created
epoch_t last_epoch_started; // lower bound on last epoch started (anywhere, not necessarily locally)
epoch_t last_epoch_clean; // lower bound on last epoch the PG was completely clean.
epoch_t last_epoch_split; // as parent
epoch_t last_epoch_marked_full; // pool or cluster
/**
* In the event of a map discontinuity, same_*_since may reflect the first
* map the osd has seen in the new map sequence rather than the actual start
* of the interval. This is ok since a discontinuity at epoch e means there
* must have been a clean interval between e and now and that we cannot be
* in the active set during the interval containing e.
*/
epoch_t same_up_since; // same acting set since
epoch_t same_interval_since; // same acting AND up set since
epoch_t same_primary_since; // same primary at least back through this epoch.
eversion_t last_scrub;
eversion_t last_deep_scrub;
utime_t last_scrub_stamp;
utime_t last_deep_scrub_stamp;
utime_t last_clean_scrub_stamp;
};2. PG info信息的初始化
1)PG构造函数中初始化pginfo
PG::PG(OSDService *o, OSDMapRef curmap,const PGPool &_pool, spg_t p)
: info(p){
}
pg_info_t(spg_t p)
: pgid(p),
last_epoch_started(0), last_user_version(0),
last_backfill(hobject_t::get_max()),
last_backfill_bitwise(false)
{ }从上面我们可以看到,在PG的构造函数中设置了pg_info_t.pgid;将last_epoch_started初始化为0;将last_user_version初始化为0;将last_backfill设置为hobject_t::get_max(),表示没有需要backfill的对象;将last_backfill_bitwise设置为false。