😺欢迎来到我的博客, 记得点赞👍+收藏⭐️+留言✍️🐱
🐉做为一个怪兽,我的目标是少消灭一个奥特曼🐉
📖希望我写的博客对你有所帮助,如有不足,请指正📖
chatgpt 是否能够代替程序猿?
~~非常明确,太抬举chatgpt 了!!!
~~chatgpt屌 !但是是相比于之前的"人工智能",之前的"人工智能"其实是"人工智障",全靠同行衬托!!但是和正常的人类比,还是相差甚远的
~~chatgpt 本质上是大号搜索引擎(相当于谷歌,百度,bing 这些东西)升级版
~~它的功能是检索,是基于现有的知识,而程序猿做的很多工作,是创造,从无到有的根据问题/场景创造出东西(产品)
找工作的节奏~时间窗口
- 找实习 => 大三上学期 + 大三下学期3-4月份
(大三可以替换成研二)(但是正常的研究生基本没法出去实习.正常老板是不会放人)
拿到的是实习offer.至于能否转正留用,签劳动合同,看表现~~[不稳]
- 提前批 => 大三下学期7-8月份
一般是比较好的公司
拿到的是正式offer.(先签订三方协议,毕业了入职报道,签订劳动合同)~~[稳]
- 秋招 => 大四上学期9,10,11月份⭐️⭐️⭐️
绝大部分同学都是在这个时间点进行找工作,所有公司齐出动招聘的黄金时机.
拿到的是正式offer.(先签订三方协议,毕业了入职报道,签订劳动合同)~~[稳]
经历了秋招,绝大部分同学都有工作了.当然还有一部分同学还没找到~~
- 春招 => 大四下学期,年后到3,4月份
可以理解成补招.(秋招有些公司没招够人,再招招)
公司数量和质量都是远远不如秋招的.
春招的机会是秋招的十分之一.这样理解是不为过的~
~~如果春招了还没找到工作,基本凉了(跟失业差不多.就算不失业,基本难以进入互联网行业了)
~~当错过春招之后,就失去了最大的筹码 => 应届生身份!!!
~~从此之后,只能走社招 => 互联网公司社招都是要求工作经验的
~~由于没有工作经验,又不是应届生,基本很难进入互联网公司了,就算进互联网,也一定是最底层最差的公司(只能外包了)
“外包”:一类专门给别的公司干苦力的公司~~(没有技术壁垒,也没有自己产品的…)
存在一些公司,offer是点击就送的.
富士康,富士通,美林,道通,比亚迪,…
面试大概就是随便聊聊,也不问技术~~
(技术岗)6k,7k左右~~
select
- 全列查询
select * from 表名;
- 指定列查询
select 列名,列名 from 表名;
- 表达式查询
select 表达式 from 表名;
- 带别名的查询
select 表达式 as 别名 from 表名;
- 去重查询
select distinct 列名/表达式 from 表名;
- 排序查询
select 列名 from 表名 order by 列名[desc], 列名[desc];
- 条件查询
select 列名 from 表名 where 条件;~~通过一组关系运算符和逻辑运算符描述.符合条件的结果保留,不符合的就pass
NULL 的查询:is [not] null
NULL / null ~~sql中不区分大小写的.表示表格里的这一项是空着的
null 和其他数值进行运算,结果还是null
null 结果在条件中,相当于 false 了.
null = null 结果还是 null => false
<=>使用这个比较相等运算,就可以处理null的比较!!
null <=> null => true
复习一下
分页查询: limit
很多地方都能见到
一共这么多数据,全都显式出来,一方面,用户看不过来,另一方面对于系统压力也比较大
limit限制查询结果是几个~~
语法:
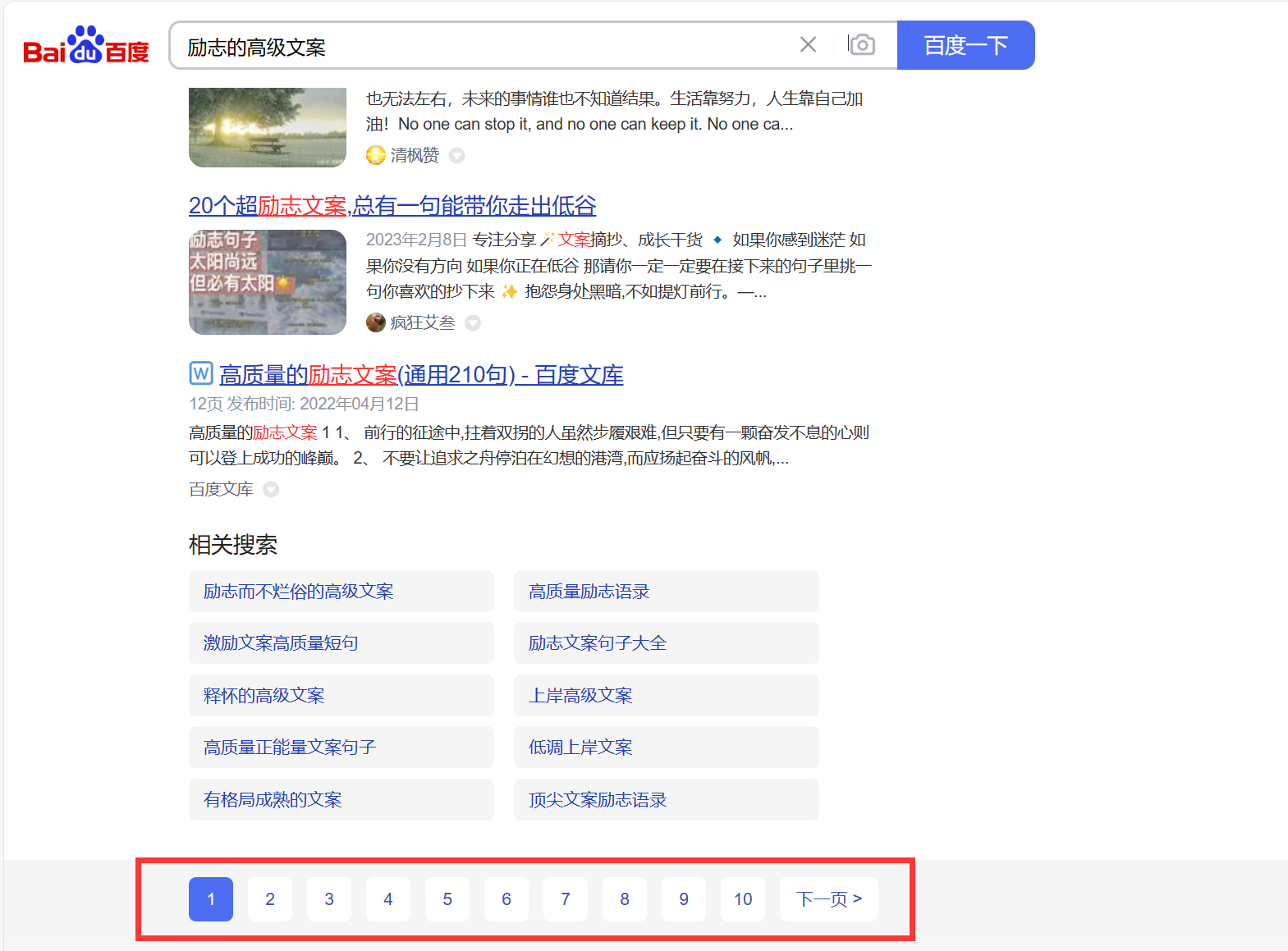
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
select ... from 表名 [where ...] [order by ...] limit n;
-- 从 s 开始,筛选 n 条结果
select ... from 表名 [where ...] [order by ...] limit s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
select ... from 表名 [where ...] [order by ...] limit n offset s;
limit 3 offset 6; 等价于limit 6, 3; (不太推荐这么写)
update
update 表名 set 列名=值, 列名=值 .... where 条件;
update exam_result set math = 80 where name = '孙悟空’;
update exam_result set math = 60, chinese = 70 where name = '曹孟德’;
update exam_result set math = math + 30 order by chinese + math + English asc limit 3;
不写任何条件,修改就是针对所有行进行的!!
update exam_result set chinese = chinese / 2;
update操作非常危险!!
撤回不了
测试只能测试个大概.有可能你的bug是一个小概率触发的情况
delete
delete删除记录(行)
delete from 表名 where 条件;
order by / limit…
delete from exam_result where name like '孙%';
把条件匹配出来的结果,都删掉了!!!
delete from exam_result;
不写where 也没有limit就是全部了!!!
这个操作基本相当于删表(drop table)
delete from表还在,里面的数据没了.drop table表和数据都没了.
truncate也能清空表的内容,和delete from差不多.delete from是一条一条删,删的慢.truncate,直接一下就删没了…
如果某个sql语句执行时间很长,随时可以按ctrl + c取消
insert into 表名…
select from 表名…
update 表名…
delete from 表名…
关键字和表名之间,使用的这个介词不一样!!!~~这其实是一个比较糟糕的设计!!
接口设计风格的不一致性~~会提升使用成本,提升出错概率
C++这里做的更好.C++标准库里面统一都是使用 size()
std::array新式数组,都是符合上述的规范要求的~~
不仅仅是 size,各种操作,都是统一风格~~
数据库约束
约束,就是数据库针对里面的数据能写啥,给出的一组““检验规则”
这样的约束,可以是程序猿人工来保证,也可以是程序自动保证。
在程序猿里,谈到人,就意味着“不靠谱"(和计算机相比)
计算机的存储能力,远远超过人脑的,纪律性,也是远远超过人脑的
约束,就是为了提高效率,提高准确性,让数据库这个软件集成的一个针对数据校验的功能
约束类型
-
NOT NULL => 当前内容不为空,必填项
-
UNIQUE => 让列的值是唯一的(不和别的行重复) ~~如学号,手机号,身份证号
-
DEFAULT => 列没被赋值时的默认值
-
PRIMARY KEY => 主键 ,与NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
-
FOREIGN KEY => 外键=>保证一个表中的数据匹配另一个表中的值的参照完整性。
-
CHECK => 在mysql5版本中,不支持~~写了不会报错,但是没有实际效果,这个可以不学
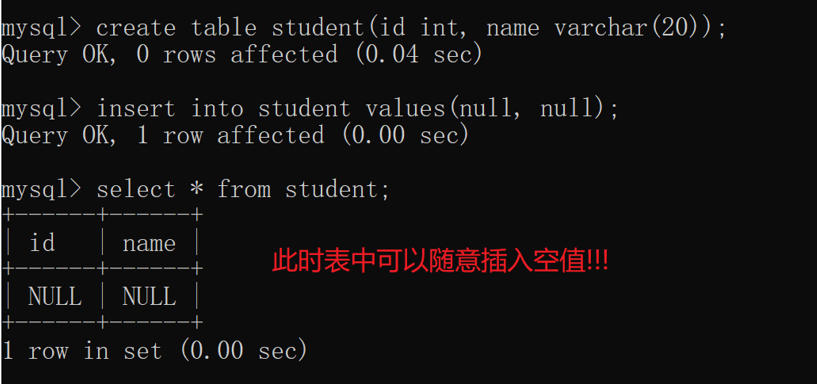
给一个现有的表加约束,也可以
~~比较麻烦, 使用alter table语句,不过用起来麻烦(支持的功能多),很少会使用
1.not null
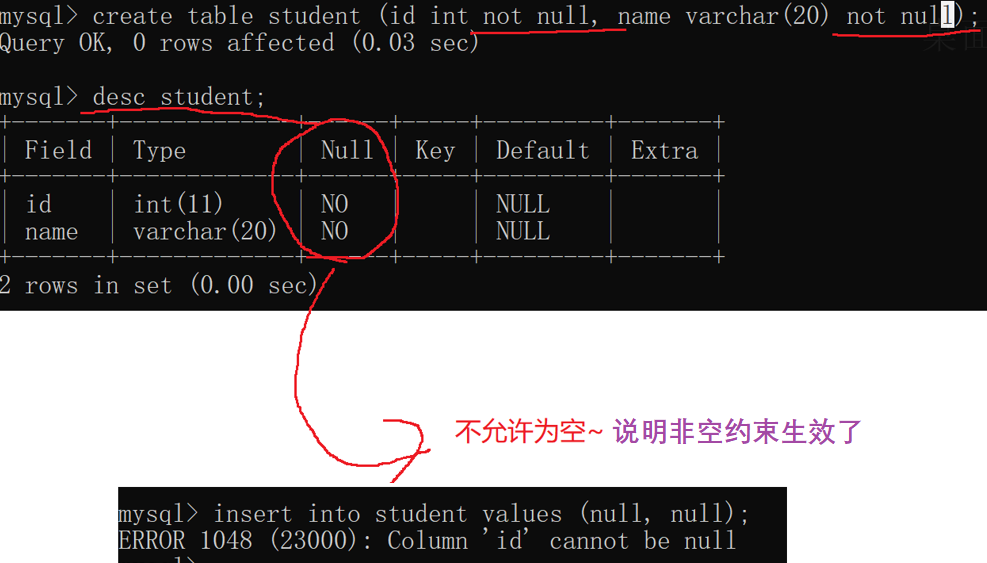
2.unique
插入/修改数据的时候,会先查询,先看看数据是否已经存在.如果不存在,就能够插入/修改成功.如果存在,则插入/修改失败!!
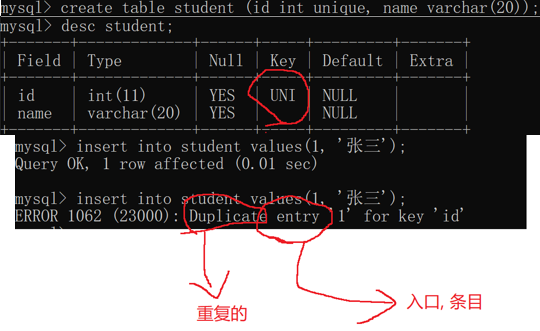
Map 的每个键值对,就相当于一个条目entry
数据库怎么知道的1存在?其实是在插入之前先查询了下~~(只不过查询操作,咱们感知不到) => 因此,这里是多了个查找数据的成本.
本质上是 程序运行效率 VS 程序猿开发效率
开发效率高了,加班就少了…开发效率低,干活干的慢,就得加班.从老板角度看,提高运行效率,节省的是买机器的成本(少数),提高开发效率,节省的是雇佣程序猿的成本(占大头)
Java之所以能够火起来,很大程度就是Java比CPP 开发效率更高(运行效率降低了)Python,PHP,Go也是在追求开发效率,而没过多关注运行效率
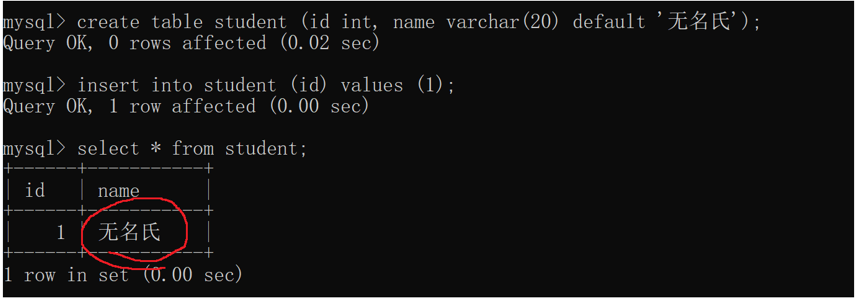
3.default
default~~设置默认值
默认值是在insert 指定列插入的时候,其他未被指定到的列就是按照默认值来填充~~
4.primary key
主键,一条记录 在表中的"身份标识" ~~手机号码,身份证号码,学号…
也是要求唯一.并且不能为空~~
主键 = unique + not null
mysql要求一个表里,只能有一个主键
~~创建主键的时候,可以使用一个列作为主键
~~也可以使用多个列作为主键(复合主键),很少见,可以不学
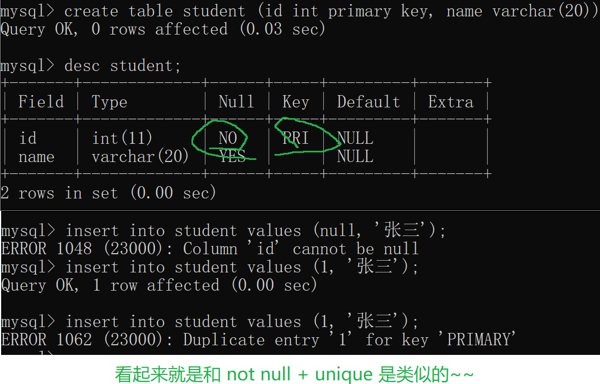
提问:如何给这个记录安排一个主键呢?
mysqI 自身只是能够检查是否重复.设置的时候还是靠我们自己来设置,此处,有很多办法.mysqI提供了一个简单粗暴的做法,自增主键~~ 由MySQL自动分配,分到到的是一个唯一值
常配搭自增长auto_increment来使用,换句话说,使用auto_increment的当前这一列就是自增主键
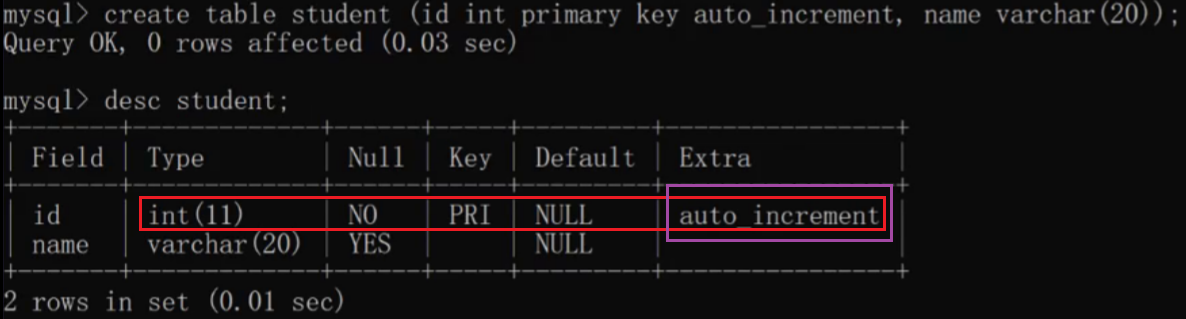
给自增主键插入数据的时候,可以手动指定一个值,也可以让 mysql自己分配.如果让mysql自己分配,就在insert语句的时候,把id设为null 即可了!
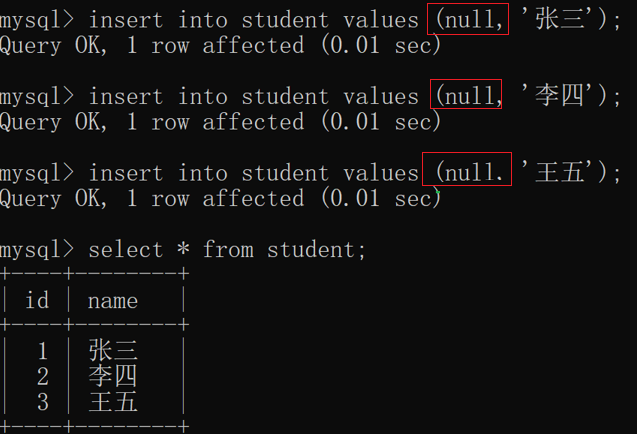
本质:mysql 给每个表维护了一个全局变量.每次分配一个id,就全局变量自增.下次分配接着上次的继续分配…
当前自增主键,就只需要用一个变量,记录序号的最大值就行了.每次都在这个基础上+1就好.
常配搭自增长auto_increment来使用,换句话说,使用auto_increment的当前这一列就是自增主键