文章目录
- 一、文件读写操作
- 1、文件的打开方法—open 内建函数
- (1)基本语法
- (2)参数介绍
- 2、文件读操作
- (1)read 方法 —— 读取文件
- (2)文件指针
- (3)readline 方法 —— 按行读取
- 案例:读取大文件的正确姿势
- (4)readlines 方法
- 3、文件写操作
- (1)write 方法 —— 写文件
- (2)writelines 方法
- 案例 :writelines
- 4、with 子句
- 案例 :with
- 练习
- 版本一
- 版本二:优化
一、文件读写操作
在 Linux 系统中万物皆文件,所以我们不可避免的要和文件打交道,我们会常常对文件进行读和写的操作。例如:
cat /etc/password # 读文件
vim /etc/password # 读写文件
echo test > /tmp/abc.txt # 覆盖写文件
echo text >> /tmp/abc.txt # 追加写文件
而以上内容我们都是对文本文件进行读写,计算机中也存在对二进制文件的读写操作,那用 Python 如何实现呢?
1、文件的打开方法—open 内建函数
不管是读文件还是写文件,我们第一步都是要将文件打开。
作为打开文件之门的“钥匙”,内建函数 open() 提供了初始化输入/输出(I/O)操作的通用接口,成功打开文件后时候会返回一个文件对象,否则引发一个错误。
(1)基本语法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FhPn4usm-1653320533809)(day03.assets/image-20210810162704041.png)]
要以任何方式使用文件——哪怕仅仅是打印其内容,都得先打开打文件,这样才能访问它。
(2)参数介绍
**file_name:**表示我们要打开文件的路径
**mode:**以怎样的方式打开文件
| 文件模式 | 操 作 |
|---|---|
| r | 以读方式打开(文件不存在则报错) |
| w | 以写方式打开(文件存在则清空,不存在则创建) |
| a | 以追加模式打开 |
| b | 以二进制模式打开 |
**file_object:**文件操作对象,我们后续对文件的所有读写操作都需要通过这个对象,而不是直接操作文件中的数据。
2、文件读操作
要使用文本文件中的信息,首先需要将信息读取到内存中。为此,我们可以一次性读取文件的全部内容,也可以以每次一行的方式逐步读取。
(1)read 方法 —— 读取文件
open函数的第一个参数是要打开的文件名(文件名区分大小写)- 如果文件 存在,返回 文件操作对象
- 如果文件 不存在,会 抛出异常
read方法可以一次性 读入 并 返回 文件的 所有内容close方法负责 关闭文件- 如果 忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
- 注意:
read方法执行后,会把 文件指针 移动到 文件的末尾
# 1. 打开 - 文件名需要注意大小写
file = open("文件路径", "r")
# 2. 读取
text = file.read() # 一次性将文件中的内容全部读取出来
print(text) # 将读取到的内容打印再控制台上
# 3. 关闭
file.close()
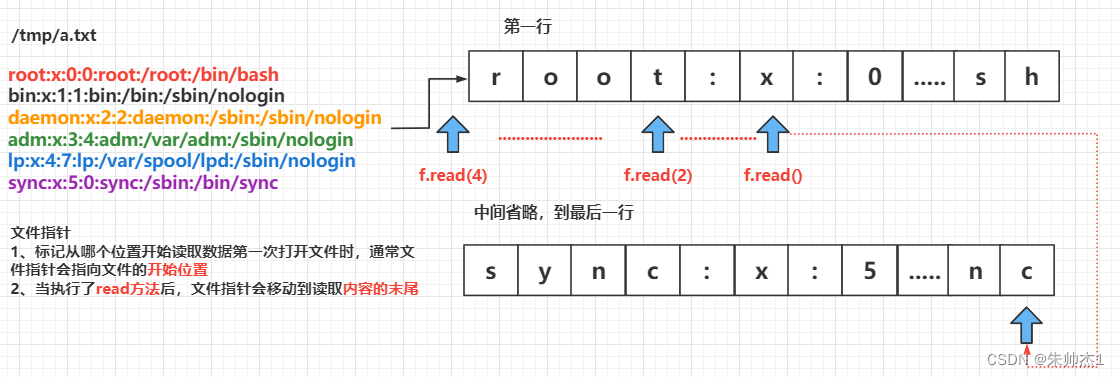
(2)文件指针
- 文件指针 标记 从哪个位置开始读取数据
- 第一次打开 文件时,通常 文件指针会指向文件的开始位置
- 当执行了
read方法后,文件指针 会移动到 读取内容的末尾- 默认情况下会移动到 文件末尾
- 重新打开文件时,文件指针 重新指向文件的最 开始位置
图例
 思考
思考
- 如果执行了一次
read方法,读取了所有内容,那么再次调用read方法,还能够获得到内容吗?
答案
- 不能,因为第一次读取之后,文件指针移动到了文件末尾,再次调用不会读取到任何的内容
(3)readline 方法 —— 按行读取
-
read方法默认会把文件的 所有内容 一次性读取到内存 -
如果文件太大,对内存的占用会非常严重
-
readline方法可以一次读取一行内容 -
方法执行后,会把 文件指针 移动到下一行,准备再次读取
案例:读取大文件的正确姿势
# 打开文件
file = open("文件路径", mode="r")
while True:
# 读取一行内容
text = file.readline()
# 判断是否读到内容
if len(text) == 0:
break
# 每读取一行的末尾已经有了一个 \n
print(text, end="")
# 关闭文件
file.close()
(4)readlines 方法
readlines() 方法读取所有(剩余的)行然后把它们作为一个 字符串列表 返回
图例

- 如果需要逐行处理文件,可以结合 for 循环迭代文件
- 迭代文件的方法与处理其他序列类型的数据类似
f = open("/tmp/passwd", mode="r")
for line in f: # 相当于 for line in f.readlines():
print(line, end=" ")
3、文件写操作
(1)write 方法 —— 写文件
- write() 内建方法功能与
read()和readline()相反- 它把含有 文本数据 或 二进制数据块 的字符串写入到文件中去
- 写入文件时,不会自动添加行结束标志,需要程序员手工输入,返回写入的字节数

(2)writelines 方法
- 和
readlines()一样,writelines()方法是针对 列表 的操作 - 它接受一个 字符串列表 作为参数,将他们写入文件
- 行结束符并不会被自动加入,所以如果需要的话,必须再调用 writelines() 前给每行结尾加上行结束符
案例 :writelines
f = open("./d.txt", mode="w")
f.writelines(['1st line.\n', '2nd line.\n','3rd line.\n'])
f.close()
图例:

4、with 子句
-
with语句 是用来简化代码的
-
在将打开文件的操作放在 with 语句中,代码块结束后,文件将自动关闭
-
读写文件的逻辑没有变化,变得只是 写法
案例 :with
with open('/tmp/passwd', mode="r") as f:
f.readline()
练习
# 模拟 cp 操作
# 1. 创建 cp.py 文件
# 2. 将 /usr/bin/ls "拷贝" 到/tmp 目录下
# 3. 不要修改原始文件
版本一
# 创建两个对象变量,f1为原文件;f2 为要写入数据的目标文件
# 因为是二进制文件,以字节的方式进行读写
f1 = open('/usr/bin/ls', mode='rb')
f2 = open('/tmp/list', mode='wb')
# 从用f1从原文件 /usr/bin/ls 中读取数据,并将数据存储在变量data中
# f2将变量data中的内容,写入到目标文件/tmp/list中
data = f1.read()
f2.write(data)
#关闭文件f1和文件f2
f1.close()
f2.close()
查看原文件和目标文件的md5值,是否相等
[root@localhost xxx]# md5sum /tmp/ls /tmp/list
版本二:优化
# 创建两个变量,src_fname 存储源文件路径;dst_fname 存储目标文件路径
src_fname = '/usr/bin/ls'
dst_fname = '/tmp/list2'
# 创建两个对象变量,src_fobj为打开原文件;src_fobj为打开目标文件
# 因为是二进制文件,以字节的方式进行读写
src_fobj = open(src_fname, mode='rb')
dst_fobj = open(dst_fname, mode='wb')
while 1: # 不确定读取次数,采用while循环
data = src_fobj.read(4096) # 每次从元文件中读取4k
if len(data) == 0: # data为0,代表指针指向末尾,数据读完
break # 退出整个while循环
else:
dst_fobj.write(data) # 将data数据写入list2文件中
src_fobj.close() # 关闭原文件/usr/bin/ls
dst_fobj.close() # 关闭目标文件 /tmp/lists