前言
有位朋友需要收集公司微信公众号的文章的留言,但苦于微信公众平台没有提供留言的
API,所以朋友需要在每一篇文章下面去手动复制粘贴,朋友觉得很麻烦,于是来找到我!遂有此文。
下一篇,将结合uiautomation,实现全自动化收集微信公众号留言
值得注意的是:借助mitmproxy,我们可以拦截感兴趣的流量,但在这里充其量就是节省了我们手动复制的麻烦,mitmproxy在这里的角色就是拷贝忍者。
知识点📖📖
关于mitmproxy,还需要安装配置。参考下面链接:
https://frica.blog.csdn.net/article/details/108932591
本文主要使用的是 mitmproxy,关于它的使用,可以
- 看官方文档:https://docs.mitmproxy.org/stable/
- 看我录制的视频:https://www.bilibili.com/video/BV1UC4y1t7EL
实现
本文的重点在于定位到留言的流量(即留言的数据包
打开 charles 抓包工具,看看留言的流量,因为比较简单,一眼就找到了对应流量包。
现在知道了留言的流量包,复制它的URL,接下来使用mitmproxy去拦截它,然后再做保存就可以了。
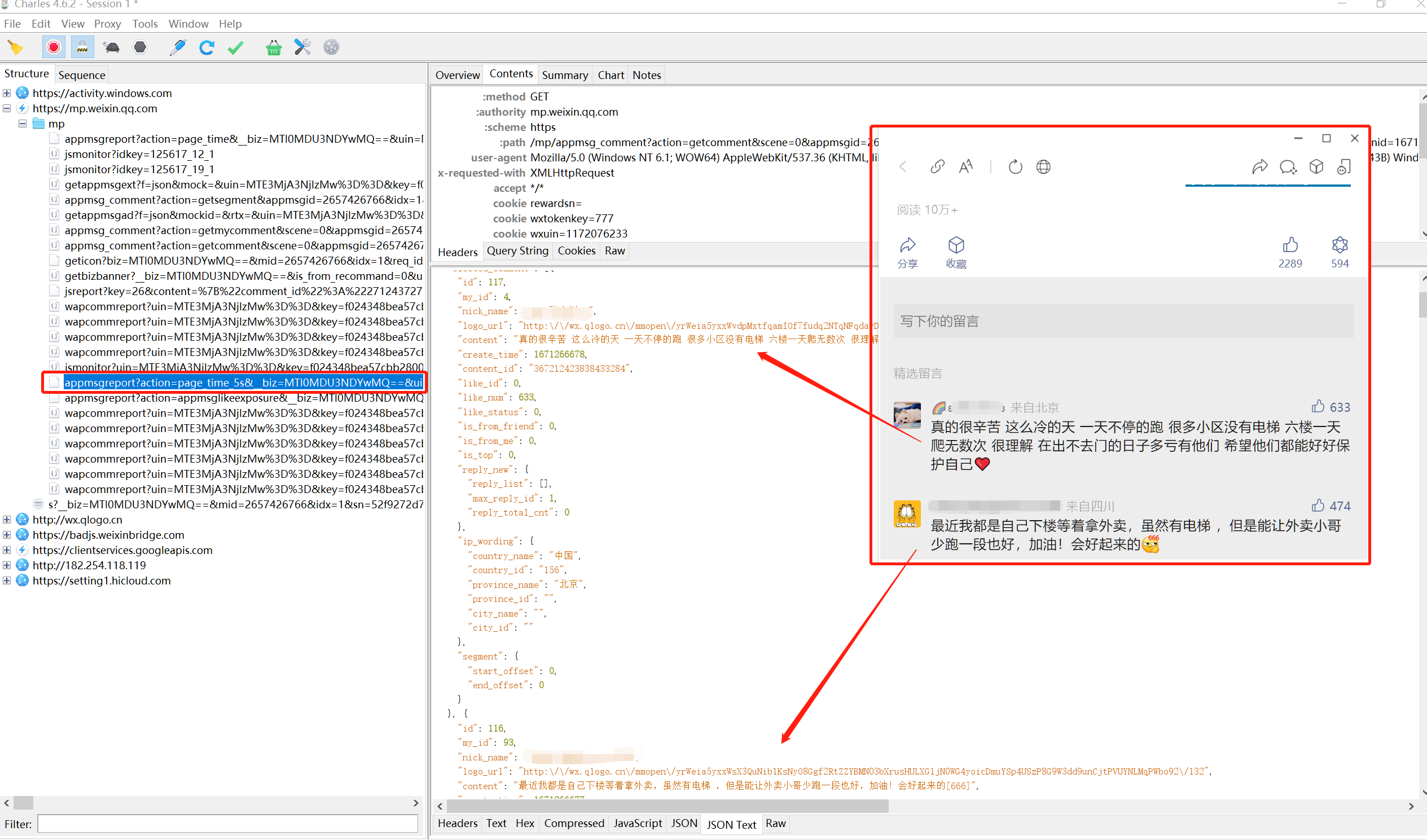
现在去 chatGPT 问问强大的它,代码该怎么写。
mitmproxy监听微信公众号留言的代码
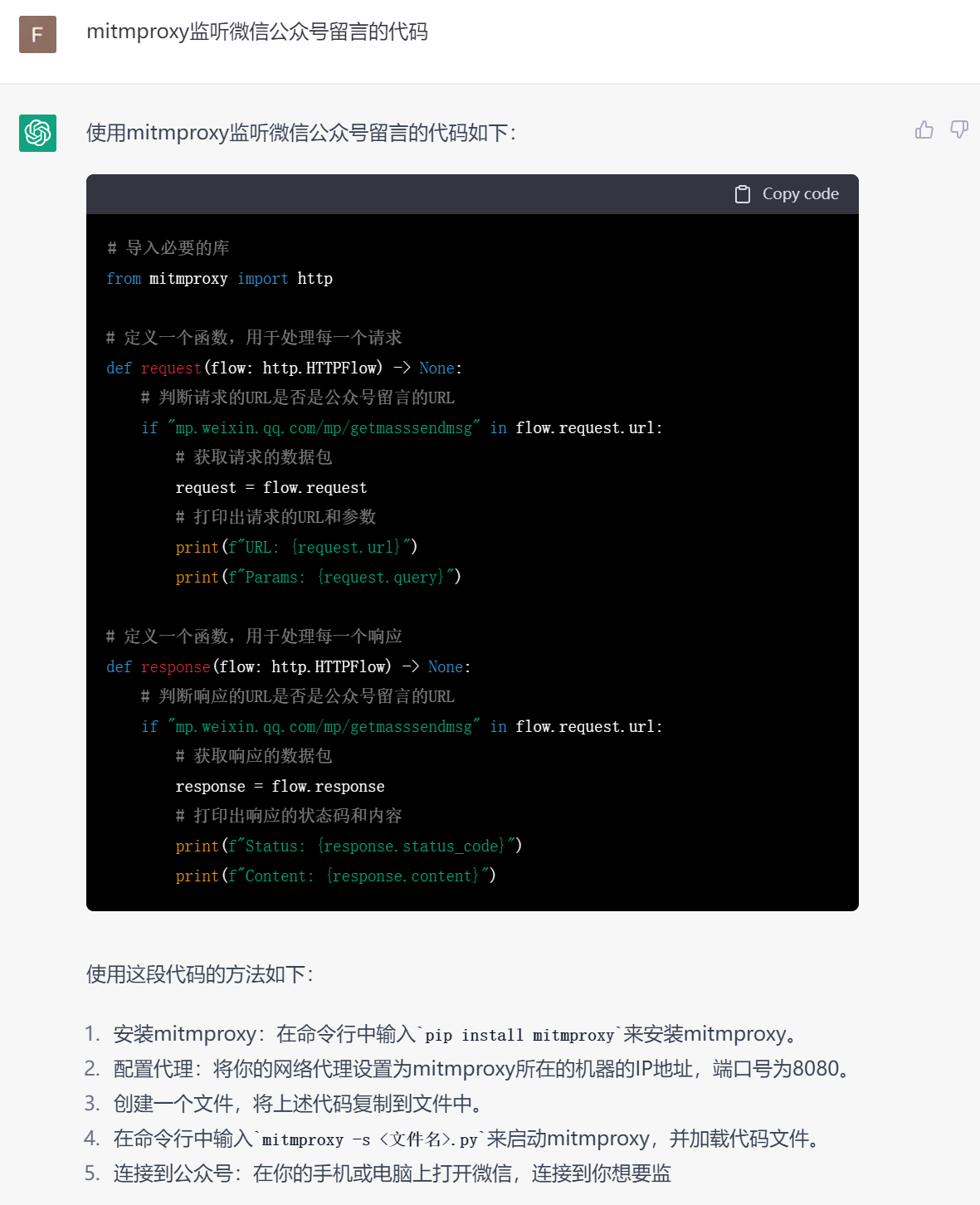
看到上图,强大的chatGPT连代码都给我们写出来了。
我们关心的是响应,所以取上面的response函数,然后替换里面的URL即可,如下所示:
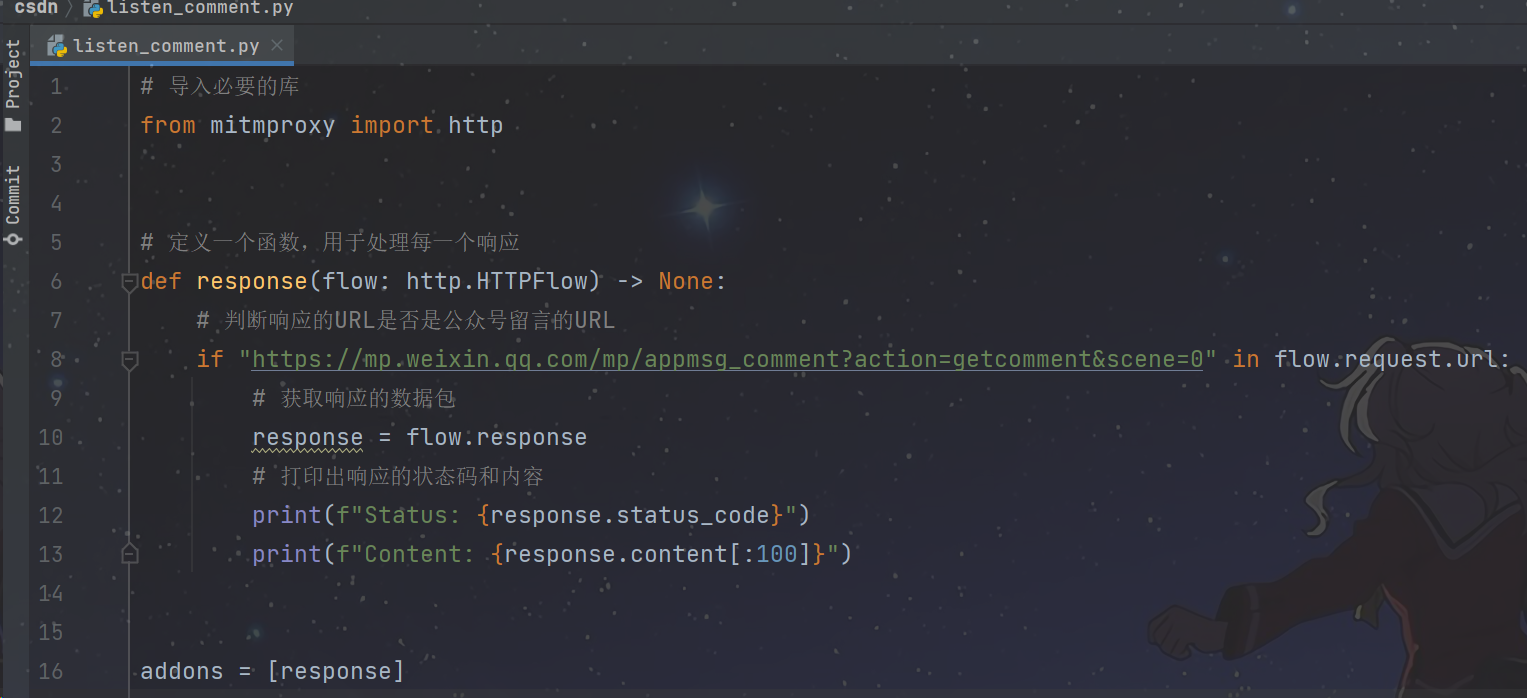
然后在控制台窗口运行它(记得打开电脑代理:
- 参数不做解释
mitmdump -s listen_comment.py -q
可以看到以下内容,拦截成功。那接下来的工作就只剩下数据解析了。
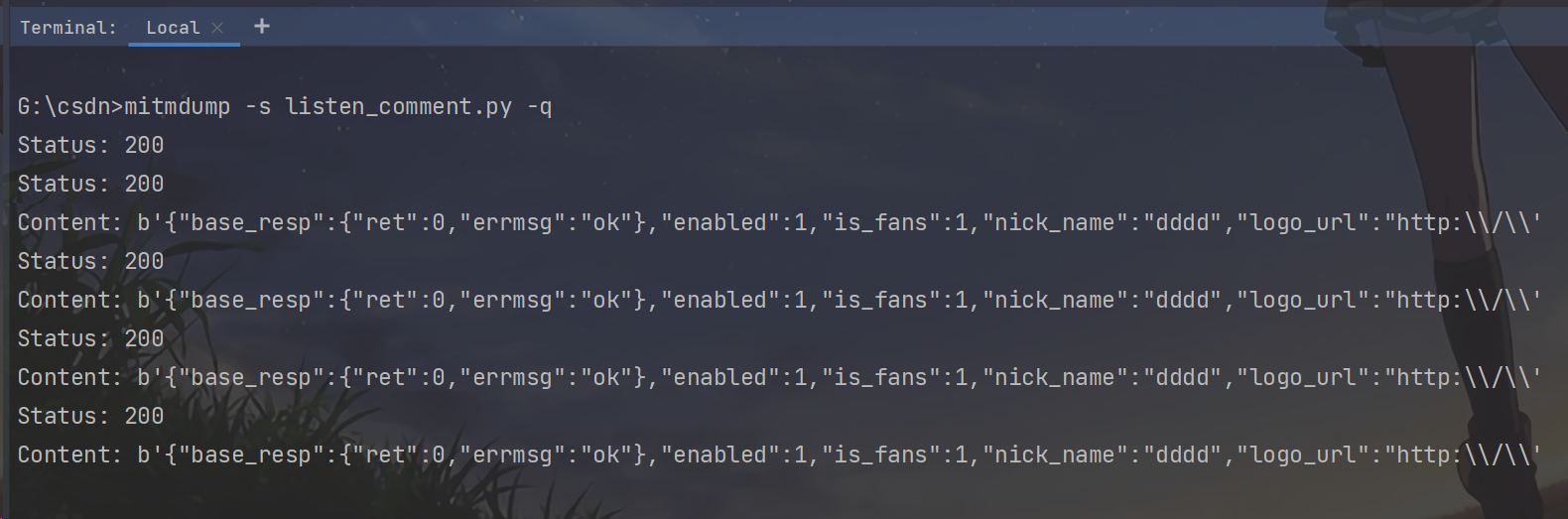
代码的解析很简单,这里就不再做介绍了。
代码
下面的代码还没能保存数据!还需调用一下
parse函数噢!!!
在命令行窗口输入:mitmdump -s listen_comment.py -q,即可运行本程序
# listen_comment.py
# 导入必要的库
from mitmproxy import http
# 定义一个函数,用于处理每一个响应
def response(flow: http.HTTPFlow) -> None:
# 判断响应的URL是否是公众号留言的URL
if "https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0" in flow.request.url:
# 获取响应的数据包
response = flow.response
# 打印出响应的状态码和内容
print(f"Status: {response.status_code}")
print(f"Content: {response.content}")
print(parse(data=response.text))
def parse(data: str):
"""解析留言流量包"""
_data = defaultdict(list)
try:
for item in json.loads(data)['elected_comment']:
_data['nick_name'].append(item['nick_name'])
_data['content'].append(item['content'])
_data['like_num'].append(item['like_num'])
_data['province_name'].append(item['ip_wording']['province_name'])
except (KeyError, json.decoder.JSONDecodeError):
...
finally:
return _data
addons = [response]
后话
本次分享到这里结束了,
善于利用工具,就可以实现包括但不限于本文之类的操作啦!
see you~🐱🏍🐱🏍





![[ 数据结构 -- 手撕排序算法第四篇 ] 选择排序](https://img-blog.csdnimg.cn/53493c3c617f4152878ee3f340778dcd.png)




![[附源码]Node.js计算机毕业设计好又多百货商业广场有限公司自助收银操作系统Express](https://img-blog.csdnimg.cn/5d07da9c80ff4760955906f34e223e86.png)