添加SE注意力机制
- 第一步 添加代码-SE类-models/common.py
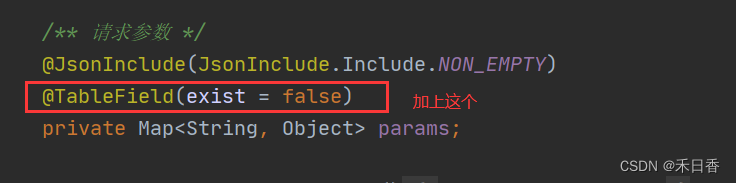
- 第二步 添加注意力关键词-models/yolo.py
- 第三步 创建配置文件-models/yolov5s_SE.yaml
- 第四步 修改读取配置-train.py
第一步 添加代码-SE类-models/common.py
进入models/common.py文件,这个文件里面包含了各个模块,包含了C3,SPP等,yolov5的训练代码也将会在这个文件里面读取模块的类来构建网络,因此我们选择在这里添加注意力机制的类。
将如下的代码,添加在common.py的最下面:
# SE
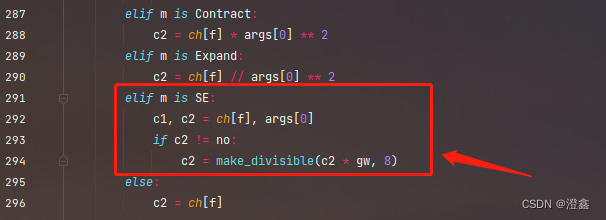
class SE(nn.Module): #SE注意力模块(通道注意力机制)
def __init__(self, c1, c2, ratio=16):
super(SE, self).__init__()
#c*1*1
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // ratio, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
第二步 添加注意力关键词-models/yolo.py

在这个位置添加注意力机制的关键词,这个函数的作用是读取yaml文件中的backbone与head关键词中的模块,因为要想我们一会添加在配置文件中的注意力模块能够顺利的加载到模型Model类的实例化对象中,我们需要加入SE关键词(可以自定义想要的名字,这个随意,不一定要是SE,但是要和后面我们加入的类名称一致)。
这里我们也可以用另外一种方式添加,如下所示:
两者方式二选一,存在一种即可。
第三步 创建配置文件-models/yolov5s_SE.yaml
在models下面创建一个新的配置文件,我这里以yolov5s为例,在里面加入注意力机制,并且我加入的是SE注意力机制,因此我命名为yolov5s_SE.yaml。复制一下路径下的yolov5s的配置文件进去,贴出我加入注意力机制之后的配置文件:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SE, [1024]],
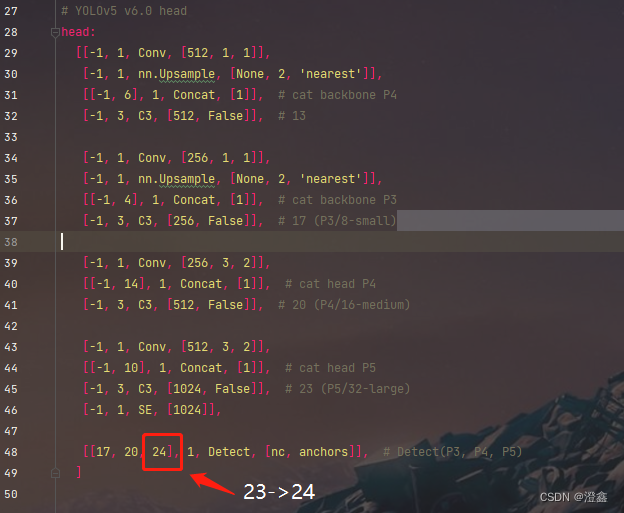
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
可以在backbone中添加注意力机制,也可以在head中添加,这里我将注意力机制加到了第三个检测头的最后一层(我在backbone中添加之后的训练效果并不好):
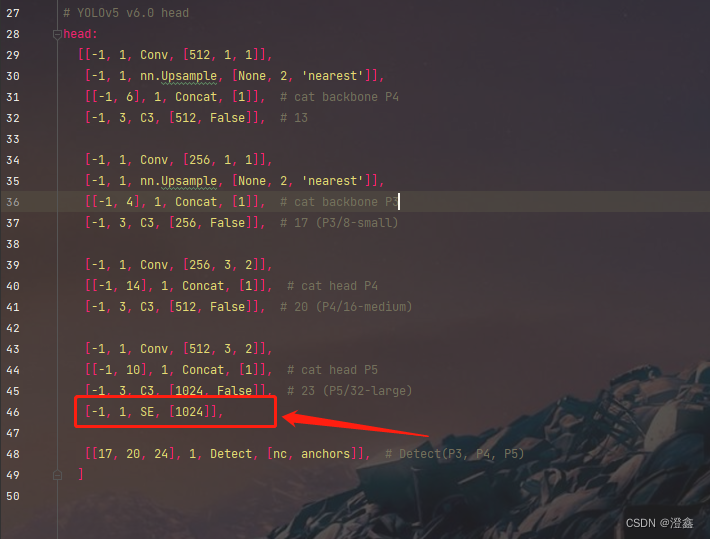
这里需要注意的一个细节是,添加了这一层之后,后面的层在调用时需要进行加1的操作,不然就彻底混乱了,因此我们需要将最后的detect中的第三个检测头的层数改一下:
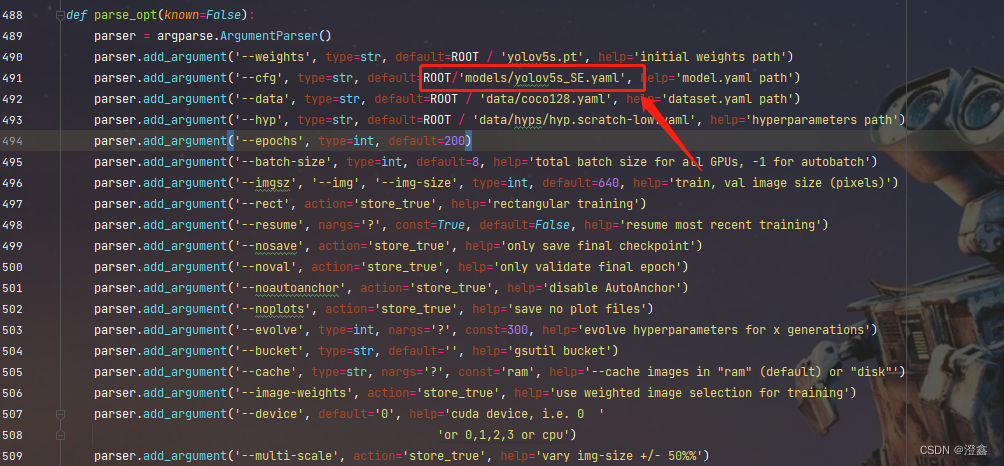
第四步 修改读取配置-train.py
将这里改成我们刚才创建的模型配置文件的路径:
然后点击训练即可,在输出日志中可以查看网络的结构,如果看到我们刚才添加的模块,说明添加成功了。