目录
1. 摘要
2. JVM 简单介绍
3. 线程私有的有哪些?
4. 线程共享的有哪些?
5. JVM 栈中程序是如何操作数据的?
6. 内存泄露是什么意思?
7. 堆内存的分配规则
8. 垃圾回收算法
8.1 垃圾回收机制简单概括
8.2 标记清理算法
8.3 标记整理算法
8.4 复制算法
8.5 新生代的GC
8.6 哪些对象会存放在老年代?
8.7 老年代的GC
1. 摘要
Java 虚拟机的底层设计其实是非常复杂的,本篇主要针对JVM的内存模型以及垃圾回收机制做一个简单概括和介绍,明白它各种方法是如何运行的,数据在哪里存放的,以及垃圾回收都有哪些算法是如何使用的。
2. JVM 简单介绍
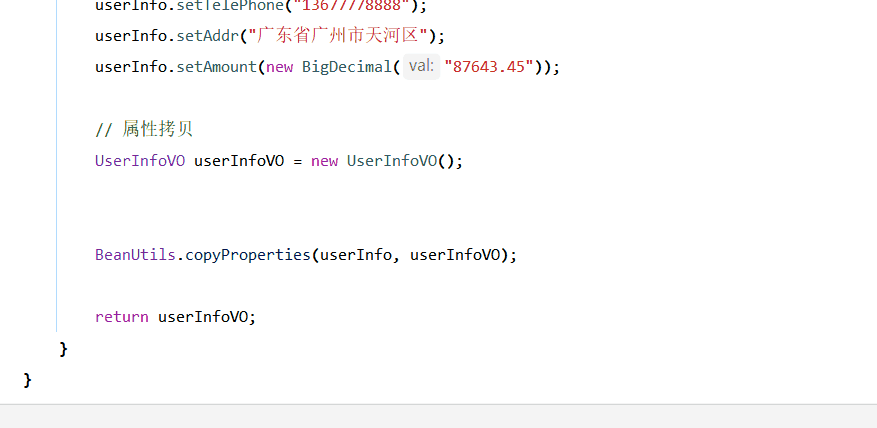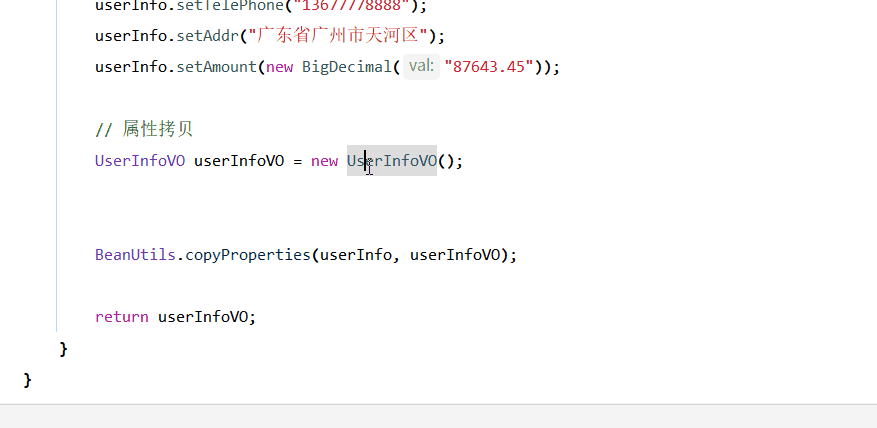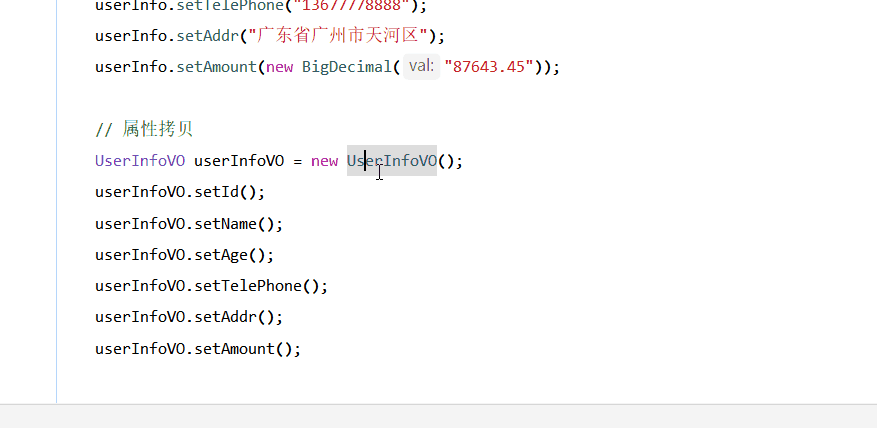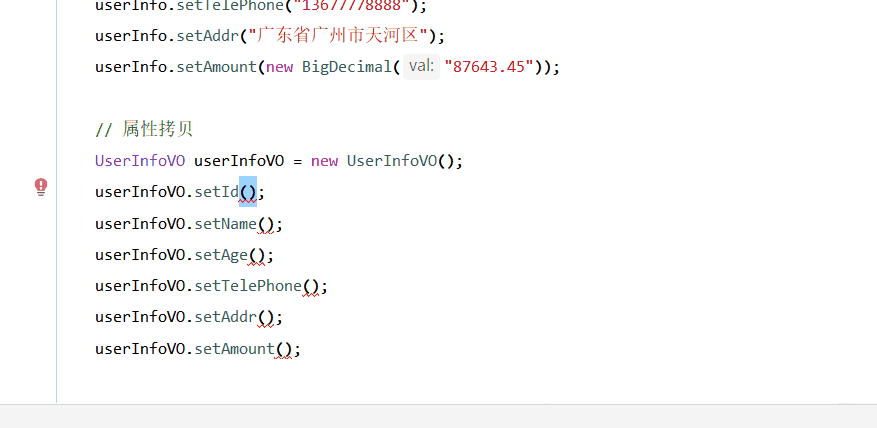
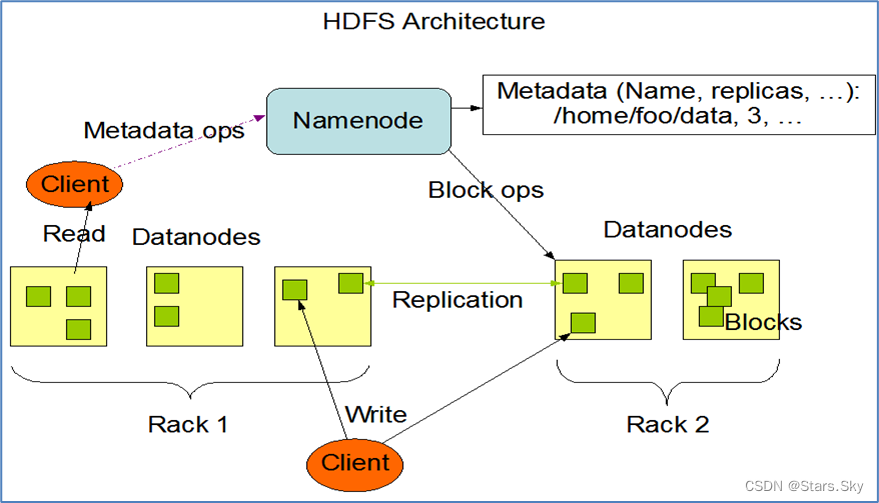
Java 虚拟机是运行在内存中的,当我们的虚拟机拿到了自己可支配的内存之后,它会对这些内存做分配,大致分为五个区域,分别为 栈(JVM栈),堆,本地方法栈,程序计数器,方法区(在JDK8之后改名加元空间)。如下图所示

JVM栈:运行当前程序的地方,我们定义的方法都是在JVM栈中跑起来的,存储一些临时变量(局部变量),基本数据类型;
堆:Java 虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象(引用数据类型)实例都在这里分配内存;
本地方法栈:主要存储 native 本地方法运行时的栈区,用于管理本地方法的调用,里面并没有我们写的代码逻辑,其由native修饰,由 C 语言实现;
程序计数器:指向当前程序运行的位置,它是一块很小的内存空间,主要用来记录各个线程执行的字节码的地址,例如,分支、循环、线程恢复等都依赖于计数器;
方法区:存储 static 静态方法,类信息,类加载器等一些全局数据信息;
3. 线程私有的有哪些?
在上述五部分之中,JVM栈,本地方法栈,程序计数器这三个是每个线程私有的,每个线程都会开辟自己的内存空间,并将内存空间分为以上三部分。这三个也可以统称为栈,所以有些人说JVM内存主要分为栈,堆,方法区就是这样来理解的。
4. 线程共享的有哪些?
堆中存放的是对象,方法区存放的是静态变量和静态方法,这些都是全局共享的,所以堆和方法区是所有线程共享的两块区域。例如 map 数组对象,就存放在堆中,所以在高并发场景下,堆中的对象从内存的角度来看是线程不安全的,因为可能有多个线程同时去操作一个 map 数组对象;而JVM栈中的数组则是线程安全的,因为私有不共享。
或许会有人会觉得,我们的对象在JVM栈中不是也存在吗?这样不是很矛盾吗?
其实这个是没有问题的,因为在JVM栈中,我们的对象实际存储的是堆中对象的内存地址,程序实际操作对象时,程序会根据存储的内存地址去对中获取到相应的对象进行操作。
5. JVM 栈中程序是如何操作数据的?
刚才我说道,我们自己编写的程序是运行在JVM栈中的,而且程序中的方法有可能方法调用其他的方法,层层循环。
举个例子,我们在程序中定义了一个方法A,方法A中定义了 int 变量 x = 10,又调用了方法 B,方法B定义了一个 int 变量 b = 20,又调用了方法C。那么在JVM栈中,它的执行顺序就是
(1)方法A进栈执行;
(2)程序向下执行,发现 int 变量 a = 10 ,然后 a 进栈;
(3)程序继续向下执行,发现调用了方法B,方法B进栈;
(4)继续执行,发现定义了 int 变量 b = 20 ,然后 b 进栈;
(5)继续执行,方法C进栈;
(6)方法C执行完毕,C出栈,清除运行所申请的内存空间;
(7)方法B执行完毕,int 变量 b = 20 先出栈,后方法B出栈,清除运行所申请的内存空间;
(8)方法A执行完毕,in 变量 a = 10先出栈,后方法A出栈,清楚运行所申请的内存空间;
上面举的例子没有涉及引用数据类型,但道理都是一样的,唯一不同的点就是,如果程序中操作修改了引用数据类型相关属性,那么程序在运行时会根据内存地址去堆中修改相应的对象的属性。当方法执行完毕,方法出栈,由于对象存在于堆中,所以程序对堆中对象做的修改被保存了下来,堆中的对象并未因为程序执行完毕出栈而消亡,而是一直存在于堆中。
6. 内存泄露是什么意思?
现在我们已经知道了,程序中创建和操作的对象都是存放在堆中的,那么就会导致内存泄漏,什么意思呢?
很简单,我们的程序在JVM栈中运行的过程中,可能会在堆中创建对象,甚至创建很多对象,但是当我们的程序结束后,对象并不会被回收,而是一直在堆中存在,因为程序不能确定是否有其他的方法会继续操作使用当前对象,而且有可能当前对象不止被一个方法引用,所以不能删除,这也是为什么对象是共享的原因之一。
但是也有一些对象可能只在一个方法中有用到,方法结束我们也不能将它删除,它就会一直在堆中存在,变成了没有用的垃圾对象,随着程序不断的运行,垃圾对象越来越多,我们的内存就会逐渐被垃圾对象占满,当我们再想创建新的对象的时候,已经没有足够的内存,就会出现内存溢出。而这些垃圾对象一直占用着我们的JVM内存无法被清理这一现象,我们就称之为内存泄漏。
为了防止内存泄漏,JVM页就有了垃圾回收机制,底层会利用复杂的算法和机制将没有引用的垃圾对象从堆中清除,释放内存,垃圾回收机制下面我会详细说到,这里先提一嘴。
7. 堆内存的分配规则
堆中的对象也不是胡乱存放的。从上面的那幅图中也能看出,在堆的内部,它也是将堆内存进行的分配,这里主要分为老年代和新生代。
在新生代中,它又分为了E区,S0区,S1区。我们新创建的对象,通常会存放在E区,新创建的对象就好比是新出生的婴儿,要放在婴儿房中一样,在这里就是把对象放在E区,创建的对象也都是挨在一起的;
S0区和S1区是为了配合E区做垃圾回收而创建的;
老年代区,就好比是老人,已经活很久了,在程序中指代多次垃圾回收机制都未被清除的对象,多次都未被清除说明该对象很可能会长期存在,所以直接从新生代移入老年代;除了存放多了垃圾回收都未清除的对象,一些大对象也会存放在老年代中。
8. 垃圾回收算法
8.1 垃圾回收机制简单概括
堆中虽然存放了很多对象,有些对象还是垃圾对象,随着垃圾越来越多,我们的内存就会越来越少,导致我们的程序出现故障,这种情况一定是不能出现的,所以也就有了垃圾回收机制。它会利用不同的算法得出哪些对象需要被删除,哪些对象需要被保留。
垃圾回收机制是为了将那些没有引用的对象全部清除,对于那些JVM栈中有直接或间接引用的对象,本地方法站中有直接或间接引用的对象,以及方法区(元空间中)有直接或间接引用的对象,都是不能被回收清除的。
此外,JVM内存模型中的垃圾回收机制远比我下面要说的复杂一些。
8.2 标记清理算法
标记-清理算法就是通过特定的算法计算出那些没有引用已经是垃圾的对象,对它们做标记,然后将它们全部清除。
但这种做法有一个缺点,就是容易产生内存碎片,什么意思呢?
刚才我说到了,在新生代创建的对象,一般都是挨在一起的,如果我们隔一两个清除一个对象,那么清除完对象之后得到的内存都是碎片化的,可以理解吧,就是内存不连贯。例如我清理垃圾对象得到了1K的内存,隔了一两个对象又清理出了1K的内存,现在我要创建一个2K大小的对象,是无法创建成功的,因为这两个1K的内存空间不连贯,我们也无法将这个2K的对象拆分成两份分开存储。而清楚垃圾对象之后得到了内存空间无法被合理利用,就产生了内存碎片。
8.3 标记整理算法
由于标记-清理算法会产生内存碎片,所以就有了另外一种算法,标记-整理算法。
也很好理解,就是我们在经过标记-清理算法清楚垃圾之后,将所有的对象前部往前移动,填补上被清除掉的垃圾对象的内存位置,腾出更多更大的内存空间。
但这种清理方法也有一种缺点,就是代价太大了,我们每清除一次垃圾对象,很多保存下来的对象的位置都要进行反复的变化和移动,对于内存开销太大了。
8.4 复制算法
标记-整理算法和标记-清理算法都有他们的缺点,所以又有了另外一种垃圾回收算法——复制算法。它的原理是将内存一分为2,将其中一半用来存放对象,另一半先暂时不存,当存储对象的那一半内存快要满的时候,我们对那些要删除的对象做标记,然后将不需要删除的对象挨个复制到另一半内存中去,这样既避免了内存碎片的问题,又不需要因为对象的移动而造成巨大的内存开销。
但这个复制算法也有它自身的缺点,就是我刚开始提到的,它需要将内存一分为2,如果想和原来保持不变,那么我们就需要二倍的内存,对内存要求较高。
8.5 新生代的GC
在上面堆内存的分配规则中我们提到了,堆内存主要分为新生代和老年代。而新生代又具体分为E区,S0区,S1区。
当我们程序中在进行 new 对象这一操作时,实际上是在E区创建的对象。当E区对象快要把内存占满了之后,就会触发新生代区域的GC。
这里的新生代区域使用的是复制算法,程序会对需要删除的对象做标记,第一次会将不需要删除的对象紧凑的从E区复制到S0区,将E区和S2区的对象全部删除;第二次GC,会把S0区和E区的有用对象复制到S1区,然后将E区和S0区的对象全部删除;第三次GC,会重复上面的过程,将S1区和E区的对象复制到S0区;如此反复S1区和S2区交替工作。
这里还有一个点注意一下,E区,S0区,S1区他们三个的内存占比是8:1:1,因为对象具有朝生夕死的特点,通常创建使用之后就没有作用了。所以初始创建时E区空间会留的大一些,而幸存的对象会很少,S也是幸存(survive)的首字母,所以S0区和S1区占比就会比较小。
8.6 哪些对象会存放在老年代?
除去了新生代,堆内存还有另外一个较大的内存空间,就是老年代,一个对象从新生代进入到老年代,有以下三种可能的情况,一个对象每经过一次GC,年龄就会增加1。
(1)在JVM虚拟机中,如果一个对象在新生代经过15次GC垃圾回收都没有被删除,那么就会把该对象从新生代直接转移到老年代,因为15次GC都没有删除该对象,说明该对象可能会长期存在,没必要留在新生代反复参与GC,否则太消耗资源;但是这个阈值的年龄也可以通过JVM的参数自行设置,默认是15次
(2)还有就是如果一个对象占用的内存较大,比如说一个容量 2000000(二百万) 大小的 Map 数组,也会直接存放在老年代,因为对象过大,在参与新生代的复制算法时会非常消耗系统资源,也需要直接放到老年代;
(3)除了上面说到的两种情况,还有一种更为复杂的情况。S区中,年龄从 1 到 n 的对象大小之和超过 S区的 50% 时,新生代中年龄大于等于 n 的对象将进入老年代;此外,50%这个参数也是可以手动设置的,默认是50%。
这里要注意一点,这个 n 的值并不是固定的,而且是一个随机的值哦,它只要满足从小到大累加计算就可以了,所以 n 值是不确定的!
在《深入理解java虚拟机》这本书中是这样说的:"如果在Survivor空间中相同年龄所有对象大小的总和大于 Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到-XX: MaxTenuringThreshold中要求的年龄。"
8.7 老年代的GC
刚才我说到了新生代区域的GC,当然在老年代中,也是有GC这么一个过程的。新生代使用的GC算法是复制算法,而老年代则是使用的标记清理算法或标记整理算法;
这样有一点需要注意,老年代的GC过程通常会伴随新生代一同进行,也叫 FullGC,在进行GC的期间,Java程序会暂停,全力的来进行垃圾回收。这里的话垃圾收集器就比较多了,但它们采用的算法大多都是上面所列出的三种垃圾收集算法,