class ChatGLMModel(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
super().__init__(config)
if empty_init:
init_method = skip_init
else:
init_method = default_init
init_kwargs = {}
if device is not None:
init_kwargs["device"] = device
self.embedding = init_method(Embedding, config, **init_kwargs)
self.num_layers = config.num_layers
self.multi_query_group_num = config.multi_query_group_num
self.kv_channels = config.kv_channels
self.seq_length = config.seq_length
rotary_dim = (
config.hidden_size // config.num_attention_heads if config.kv_channels is None else config.kv_channels
)
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, original_impl=config.original_rope, device=device,
dtype=config.torch_dtype)
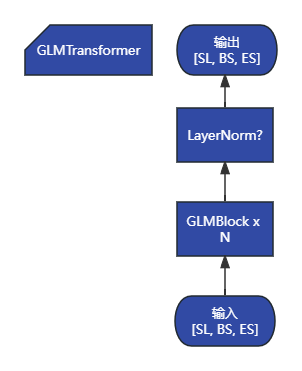
self.encoder = init_method(GLMTransformer, config, **init_kwargs)
self.output_layer = init_method(nn.Linear, config.hidden_size, config.padded_vocab_size, bias=False,
dtype=config.torch_dtype, **init_kwargs)
self.pre_seq_len = config.pre_seq_len
self.prefix_projection = config.prefix_projection
if self.pre_seq_len is not None:
for param in self.parameters():
param.requires_grad = False
self.prefix_tokens = torch.arange(self.pre_seq_len).long()
self.prefix_encoder = PrefixEncoder(config)
self.dropout = torch.nn.Dropout(0.1)
def get_input_embeddings(self):
return self.embedding.word_embeddings
def get_prompt(self, batch_size, device, dtype=torch.half):
prefix_tokens = self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device)
past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)
past_key_values = past_key_values.view(
batch_size,
self.pre_seq_len,
self.num_layers * 2,
self.multi_query_group_num,
self.kv_channels
)
past_key_values = self.dropout(past_key_values)
past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)
return past_key_values
def forward(
self,
input_ids,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.BoolTensor] = None,
full_attention_mask: Optional[torch.BoolTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, seq_length = input_ids.shape
if inputs_embeds is None:
inputs_embeds = self.embedding(input_ids)
if self.pre_seq_len is not None:
if past_key_values is None:
past_key_values = self.get_prompt(batch_size=batch_size, device=input_ids.device,
dtype=inputs_embeds.dtype)
if attention_mask is not None:
attention_mask = torch.cat([attention_mask.new_ones((batch_size, self.pre_seq_len)),
attention_mask], dim=-1)
if full_attention_mask is None:
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
if position_ids is not None:
rotary_pos_emb = rotary_pos_emb[position_ids]
else:
rotary_pos_emb = rotary_pos_emb[None, :seq_length]
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
inputs_embeds, full_attention_mask, rotary_pos_emb=rotary_pos_emb,
kv_caches=past_key_values, use_cache=use_cache, output_hidden_states=output_hidden_states
)
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
def quantize(self, weight_bit_width: int):
from .quantization import quantize
quantize(self.encoder, weight_bit_width)
return self