NoSQL数据库原理与应用综合项目——HBase篇
文章目录
- NoSQL数据库原理与应用综合项目——HBase篇
- 0、 写在前面
- 1、本地数据或HDFS数据导入到HBase
- 2、Hbase数据库表操作
- 2.1 Java API 连接HBase
- 2.2 查询数据
- 2.3 插入数据
- 2.4 修改数据
- 2.5 删除数据
- 3、Windows远程连接HBase
- 4、数据及源代码
- 5、总结

0、 写在前面
- Windos版本:
Windows10 - Linux版本:
Ubuntu Kylin 16.04 - JDK版本:
Java8 - Hadoop版本:
Hadoop-2.7.1 - HBase版本:
HBase-1.1.5 - Zookeepr版本:使用HBase自带的ZK
- Redis版本:
Redis-3.2.7 - MongoDB版本:
MongoDB-3.2.7 - Neo4j版本:
Neo4j-3.5.12 Community - IDE:
IDEA 2020.2.3 - IDE:
Pycharm 2021.1.3
1、本地数据或HDFS数据导入到HBase
- 代码:
创建一张Hbase新表
hbase(main):014:0> create 'tb_books', 'info'
hbase(main):015:0> describe 'tb_books'
Table tb_books is ENABLED
tb_books
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_E
NCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '6553
6', REPLICATION_SCOPE => '0'}
以JavaAPI方式从HDFS导入预处理后的数据到Hbase新建的表中,代码如下:
此处使用MR的方式将数据批量导入HBase
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class ImportHBaseFromHDFS {
private static int writeSize = 0;
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
// conf.set("hbase.zookeeper.quorum", "10.125.0.15:2181");
conf.set(TableOutputFormat.OUTPUT_TABLE, "tb_books");
// conf.set(TableOutputFormat.OUTPUT_TABLE, "books_tmp");
Job job = Job.getInstance(conf, ImportHBaseFromHDFS.class.getSimpleName());
TableMapReduceUtil.addDependencyJars(job);
job.setJarByClass(ImportHBaseFromHDFS.class);
job.setMapperClass(HdfsToHBaseMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
System.out.println("导入数据的id为:");
job.setReducerClass(HdfsToHBaseReducer.class);
FileInputFormat.addInputPath(job, new Path("hdfs://10.125.0.15:9000/books_cn/tb_book.txt"));
// FileInputFormat.addInputPath(job, new Path("hdfs://10.125.0.15:9000/books_cn/test.txt"));
job.setOutputFormatClass(TableOutputFormat.class);
job.waitForCompletion(true);
System.out.println();
System.out.println("成功往HBase导入" + writeSize + "条数据!");
}
public static class HdfsToHBaseMapper extends Mapper<Object, Text, Text, Text> {
private Text outk = new Text();
private Text outv = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] splits = value.toString().split("\t");
// System.out.println("id:" + splits[0]);
outk.set(splits[0]);
outv.set(splits[1] + "\t" + splits[2] + "\t" + splits[3] + "\t"
+ splits[4] + "\t" + splits[5] + "\t" + splits[6] + "\t" + splits[7] + "\t"
+ splits[8] + "\t" + splits[9]);
context.write(outk, outv);
}
}
public static class HdfsToHBaseReducer extends TableReducer<Text, Text, NullWritable> {
private boolean[] flag = new boolean[8];
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Put put = new Put(key.getBytes()); // rowkey
String idStr = key.toString();
String columnFamily = "info";
writeSize++;
if (idStr != null && !"NULL".equals(idStr)) {
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("id"), Bytes.toBytes(idStr));
if (idStr.startsWith("1")) {
System.out.print(idStr + " ");
} else if (idStr.startsWith("2")) {
if (!flag[0]) {
System.out.println();
flag[0] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("3")) {
if (!flag[1]) {
System.out.println();
flag[1] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("4")) {
if (!flag[2]) {
System.out.println();
flag[2] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("5")) {
if (!flag[3]) {
System.out.println();
flag[3] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("6")) {
if (!flag[4]) {
System.out.println();
flag[4] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("7")) {
if (!flag[5]) {
System.out.println();
flag[5] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("8")) {
if (!flag[6]) {
System.out.println();
flag[6] = true;
}
System.out.print(idStr + " ");
} else if (idStr.startsWith("9")) {
if (!flag[7]) {
System.out.println();
flag[7] = true;
}
System.out.print(idStr + " ");
} else {
System.out.println();
}
}
for (Text value : values) {
String[] line = value.toString().split("\t");
// TODO info,对应hbase列族名
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("name"), Bytes.toBytes(String.valueOf(line[1])));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("author"), Bytes.toBytes(String.valueOf(line[2])));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("price"), Bytes.toBytes(line[3]));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("discount"), Bytes.toBytes(String.valueOf(line[4])));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("pub_time"), Bytes.toBytes(line[5]));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("pricing"), Bytes.toBytes(line[6]));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("publisher"), Bytes.toBytes(String.valueOf(line[7])));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("crawler_time"), Bytes.toBytes(line[8]));
if ("".equals(idStr) || "".equals(line[1]) || "".equals(line[2]) || "".equals(line[3]) ||
"".equals(line[4]) || "".equals(line[5]) || "".equals(line[6]) || "".equals(line[7]) ||
"".equals(line[8])) {
System.out.println("-----------------" + idStr);
}
}
context.write(NullWritable.get(), put);
}
}
}
- 运行成功图示:
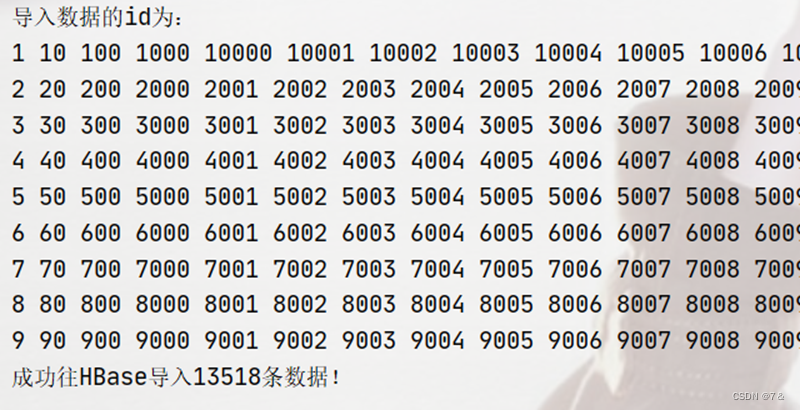
- 结果图:

2、Hbase数据库表操作
2.1 Java API 连接HBase
private static Configuration configuration;
private static Connection connection;
private static Admin admin;
private static String tableName = "tb_books";
/**
* TODO 建立连接
*/
public static void init() {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://10.125.0.15:9000/hbase");
// configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* TODO 关闭连接
*/
public static void close() {
try {
if (admin != null) {
admin.close();
}
if(null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
2.2 查询数据
- 查询数据条数
/**
* TODO 统计表的行数
* @param tableName
* @throws IOException
*/
public static void countRows(String tableName)throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
int num = 0;
for (Result result = scanner.next(); result != null; result = scanner.next()){
num++;
}
System.out.println("行数:"+ num);
scanner.close();
close();
}

- 扫描全表
/**
* TODO 扫描全表
* @param tableName
* @return
* @throws Exception
*/
public static ResultScanner getResultScann(String tableName) throws Exception {
init();
TableName name = TableName.valueOf(tableName);
ResultScanner scanner;
int size = 0;
if (admin.tableExists(name)) {
Table table = connection.getTable(name);
Scan scan = new Scan();
scanner = table.getScanner(scan);
for (Result result : scanner) {
showCell(result);
size++;
}
System.out.println("扫描全表数据大小:" + size + "条!");
} else {
scanner = null;
}
return scanner;
}


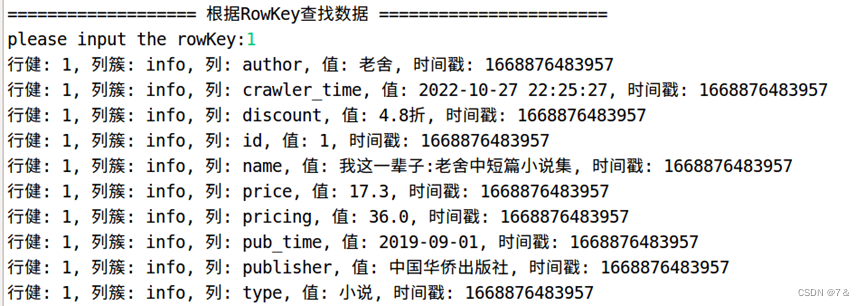
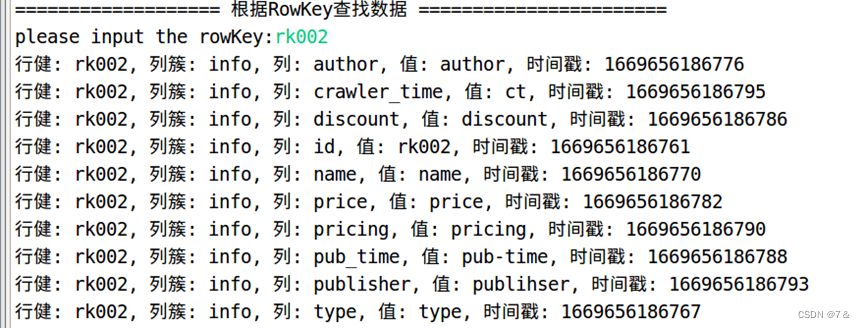
- 根据rowkey查询数据
/**
* TODO 根据行键查找数据
* @param tableName
* @param rowKey
* @throws IOException
*/
public static void getDataByRowKey(String tableName, String rowKey)throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
Result result = table.get(get);
// keyvalues={rk001/info:id/1669648973007/Put/vlen=5/seqid=0}
// keyvalues=NONE
// System.out.println(result.toString());
if (result != null) {
showCell(result);
}
if (result.toString().contains("NONE")) {
System.out.println("当前查找的RowKey:" + rowKey + "不存在数据!");
}
table.close();
close();
}
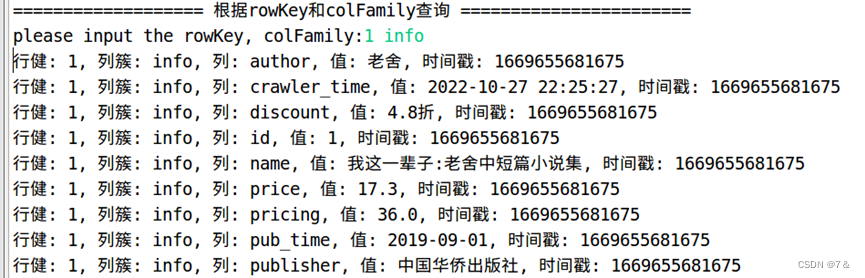
- 根据rowKey和colFamily查询
/**
* TODO 根据rowKey和colFamily查询
* @param tableName
* @param rowKey
* @param colFamily
* @throws IOException
*/
public static void scanColumn(String tableName, String rowKey, String colFamily) throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(colFamily));
scan.setStartRow(Bytes.toBytes(rowKey));
scan.setStopRow(Bytes.toBytes(rowKey));
ResultScanner scanner = table.getScanner(scan);
for (Result result = scanner.next(); result != null; result = scanner.next()) {
showCell(result);
}
table.close();
close();
}
- 查询具体某一列族的某一列的信息
/**
* TODO 根据具体某一列族的某一列查找数据
* @param tableName
* @param rowKey
* @param colFamily
* @param col
* @throws IOException
*/
public static void getData(String tableName, String rowKey, String colFamily, String col)throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(col));
Result result = table.get(get);
if (result != null) {
showCell(result);
}
if (result.toString().contains("NONE")) {
System.out.println("No Return!");
}
table.close();
close();
}

2.3 插入数据
- 插入具体一列数据
/**
* TODO 插入具体一列的值
* @param tableName
* @param rowKey
* @param colFamily
* @param col
* @param val
* @throws IOException
*/
public static void insertColumn(String tableName, String rowKey, String colFamily, String col, String val) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put data = new Put(rowKey.getBytes());
data.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(col), Bytes.toBytes(val));
table.put(data);
System.out.println("insert data successfully!");
table.close();
close();
}


- 插入一行数据
/**
* TODO 插入一行数据
* @param tableName
* @param row
* @param fields
* @param values
* @throws IOException
*/
public static void addRecord(String tableName, String row, String[] fields, String[] values) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
for (int i = 0; i != fields.length; i++) {
Put put = new Put(row.getBytes());
String[] cols = fields[i].split(":");
put.addColumn(cols[0].getBytes(), cols[1].getBytes(), values[i].getBytes());
table.put(put);
}
System.out.println("add record successfully!");
table.close();
close();
}

2.4 修改数据
- 修改指定列数据
/**
* TODO 修改表 tableName,行row,列column指定的单元格的数据。
* @param tableName
* @param row
* @param column
* @param val
* @throws IOException
*/
public static void modifyData(String tableName, String row, String column, String val) throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(row.getBytes());
String[] cols = column.split(":");
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(cols[0]));
int size = 0;
ResultScanner scanner = table.getScanner(scan);
if (scanner.next() == null) {
Get get = new Get(row.getBytes());
Result result = table.get(get);
if (result == null) {
System.out.println("当前修改的RowKey:" + row + "不存在!");
} else {
System.out.println("您要修改的列不存在!");
}
} else {
if (scanner.next() != null){
put.addColumn(cols[0].getBytes(), cols[1].getBytes(), val.getBytes());
table.put(put);
size++;
}
System.out.println("成功修改" + "列为" + column + "共" + size + "条!");
}
table.close();
close();
}

2.5 删除数据
- 删除一行数据
/**
* TODO 删除指定rowKey
* @param tableName
* @param rowKey
* @throws IOException
*/
public static void deleteRow(String tableName, String rowKey) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete data = new Delete(rowKey.getBytes());
table.delete(data);
System.out.println("delete rowKey " + rowKey + "'s" + " data successfully!");
table.close();
close();
}


- 删除指定列族的数据
/**
* TODO 删除colFamily
* @param tableName
* @param rowKey
* @param colFamily
* @throws IOException
*/
public static void deleteByCF(String tableName, String rowKey, String colFamily) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete data = new Delete(rowKey.getBytes());
data.addFamily(Bytes.toBytes(colFamily));
table.delete(data);
System.out.println("Deleted RowKey:[" + rowKey +",ColFamily:[" + colFamily + "]]'s " + " data successfully!");
table.close();
close();
}


3、Windows远程连接HBase
HBase的相关配置文件需要提前设置正确,同时在IDEA项目中的resources文件夹下需要加入Hadoop和Hbase的配置文件,包括以下几个:
- core-site.xml
- hbase-site.xml
- hdfs-site.xml
为了控制只输出error信息和结果信息,需要再新增一个log4j.properties
log4j.properties
log4j.rootLogger=stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/nosqldemo.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、数据及源代码
-
Github
-
Gitee
5、总结
将数据导入到HBase的方法有很多种,此处采用MapReduce的方式,将每条数据的id属性作为mapper端的key,其余属性字段作为value输出到reducer端,reducer端调用HBase的addColumn()方法新增每条数据,同时reducer端的value设置为NullWritable。
基本的增删改查操作,调用相关的API方法,注意细节,顺利完成并不难。
结束!








![[附源码]Nodejs计算机毕业设计基于框架的校园爱心公益平台的设计与实现Express(程序+LW)](https://img-blog.csdnimg.cn/9b5ccb157f3c40fbb08ffd43ef161acd.png)



![[附源码]Python计算机毕业设计Django网上鲜花购物系统](https://img-blog.csdnimg.cn/0ff85d01b3264e53a9ecc8c8a6ccb693.png)

