目录
1. JVM 运行时数据区
2. Java 内存模型
最近在牛客上看到这样一个帖子,大概就是在面试中呢,被面试官问到了 Java 内存模型,面试的这位小伙呢,也是掌握了 JVM 内存布局的相关知识,但是不知道面试官问的 Java 内存模型到底是什么,实际上呢,面试官就是想问它 JVM 内存布局 ? 但是这二者又是两个完全不同的东西,这直接给小伙干懵了..

为了迎合面试官,我们不得不搞清楚二者的一个区别 >>
1. JVM 运行时数据区
在了解 JVM 运行时数据区之前,咱们可以先简单了解一下 JVM 是怎么运行的。
它的大体执行流程如下:
- IDEA 将我们写的代码转为字节码文件(.class 文件),再通过类加载器(classLoader)把字节码文件加载到内存中的运行数据区(Runtime Data Area);
- 再通过 JVM 自身的执行引擎将字节码翻译成机器码(0/1 指令),然后交给 CPU 执行。
- 执行过程中,还需要调用本地方法接口,本地方法库,一起实现程序的运行。
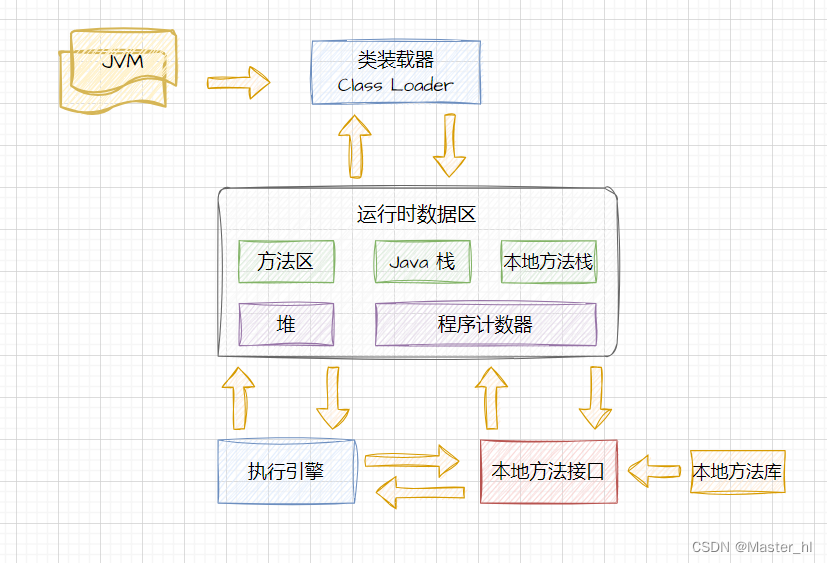
从上图来看,JVM 主要是通过类加载器、运行时数据区、执行引擎、本地库接口 4 个部分来执行Java 程序的。
上述的 JVM 运行时数据区,也叫做 JVM 内存模型,,或者 JVM 内存布局 >>
《Java 虚拟机规范》中 将 JVM(hotspot) 内存模型划分为以下 5 个部分:
1. 程序计数器:用于存储当前线程执行的字节码指令的地址,保证线程恢复执行时能够继续从上次执行到的位置继续执行。
2. Java 虚拟机栈:用于存储 Java 代码中的方法调用和局部变量(不管类型是啥,只要是方法内部定义的变量都叫局部变量),方法调用和返回的时候,虚拟机栈用于保存方法的调用帧。
3. 本地方法栈:与虚拟机栈几乎一模一样,只不过本地方法栈用于存储 C++ 的 Native 方法调用和本地方法的局部变量。
4. 堆:JVM 中最大的一块内存区域,用于存储数组和对象的实例。
5. 方法区:用于存储类的元数据,包括类的结构、属性、方法、静态变量、常量池等。

像方法区,Java 虚拟机栈,程序计数器等区域,在 IDEA 中都能体现出来:

所以程序计数器、Java 虚拟机栈为什么是线程私有的,就能一清二楚了:
- 程序计数器记录的是当前线程执行到哪个地方了,别的线程共享也没有用;
- Java 虚拟机栈存储的是方法调用、局部变量(临时的数据),别的线程不调用我的方法,共享也没有用。
2. Java 内存模型
Java 内存模型指的是 Java Memory Model,而不是 JVM 内存布局,这里千万不能搞混 >>
Java 内存模型是用来定义线程和内存间的操作规范,是为了解决多线程正确执行的问题的。Java 内存模型规范的定义确保了多线程程序的可见性、有序性和原子性,从而保证了线程间的正确交互和数据一致性。
对于内存可见性、指令重排序所带来的线程安全问题,可以看我的这篇文章:
https://blog.csdn.net/xaiobit_hl/article/details/125959309
Java 内存模型的主要内容:
1. 主内存:所有线程共享的内存区域(包含对象的字段、方法、运行时常量池等数据);
2. 工作内存:每个线程有自己的工作内存,用于存储主内存的副本数据,线程只能操作工作内存中的数据;
3. 内存间交互操作:线程通过读写操作与主内存进行交互:读操作将数据从主内存复制到工作内存,写操作将修改后的数据刷新到主内存;
4. 原子性:保证基本数据类型的读写操作具有原子性,避免线程安全问题;
5. 可见性:确保一个线程对共享变量的修改,对其他线程可见,避免内存可见性问题;
6. 有序性:保证程序的执行顺序按照一定的规则进行,避免指令重排序问题。
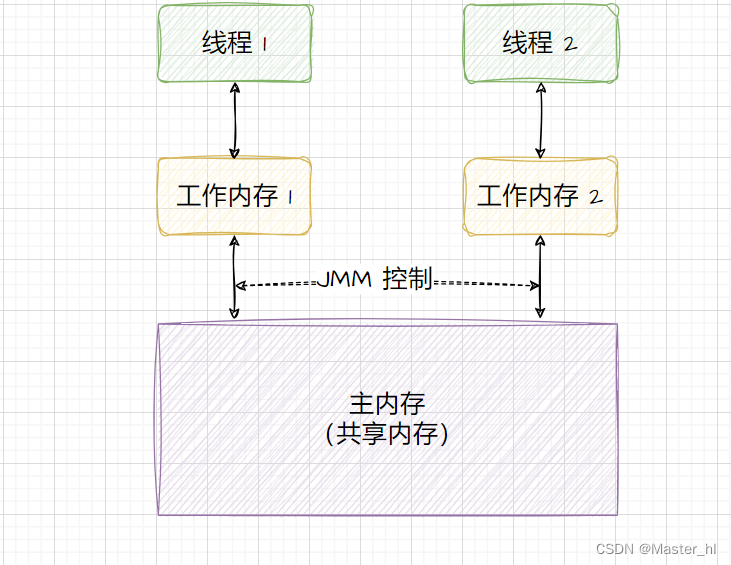
再回过头来看,为什么要有 Java 内存模型:
目的就是为了利用 CPU 资源(缓存)以及改变代码执行顺序从而提高程序执行速度,但是带来了数据一致性问题,所以需要 Java 内存模型。






![[SSM]MyBatisPlus进阶](https://img-blog.csdnimg.cn/d3f4e9a64e524355b01631969df07a2f.png)