文章目录
- RDD
- RDD特点
- 核心属性
- 执行原理
- RDD创建
- RDD并行度与分区
- 内存数据的分区
- 文件数据的并行度和分区
- RDD转换算子
- Value类型
- map
- mapPartitions
- mapPartitionsWithIndex
- flatMap
- glom(获取分区数组)
- groupBy
- filter
- distinct
- coalesce(缩小/扩大分区)
- repartition(扩大分区)
- sortBy
- sample
- 双 Value 类型
- Key - Value 类型
- partitionBy(重分区)
- mapValues
- reduceByKey
- groupByKey(分组)
- aggregateByKey(分区内+外聚合)
- foldByKey(分区内+外简化聚合)
- combineByKey(分区内+外 初始值转换聚合)
- join
- leftOuterJoin
- cogroup
- sortByKey
- 经典案例
- RDD行动算子
- collect
- reduce
- aggregate
- fold
- countByKey/Value
- foreach
- save
- RDD序列化
- 介绍
- 案例
- 解决办法
- kryo序列化机制
- RDD依赖关系
- 依赖关系
- 窄依赖
- 宽依赖
- RDD 阶段划分
- RDD 任务划分
- RDD持久化
- 缓存持久化
- RDD的checkpoint机制
- cache、persist、checkpoint三者区别
- RDD分区器
- RDD文件读取和保存
- RDD累加器
- RDD广播变量
RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
RDD特点
-
弹性:
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
-
分布式:数据存储在大数据集群不同节点上
-
数据集:RDD 封装了计算逻辑,并不保存数据
-
数据抽象:RDD 是一个抽象类,需要子类具体实现
-
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
-
可分区、并行计算
核心属性
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
-
分区列表:RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * * The partitions in this array must satisfy the following property: * `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }` */ protected def getPartitions: Array[Partition] -
分区计算函数:Spark 在计算时,是使用分区函数对每一个分区进行计算。
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T] -
RDD 之间的依赖关系:RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps
如上图,建立的就是这每一个RDD之间的关系。
-
分区器(可选):当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
/** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None -
首选位置(可选):计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
(1)启动 Yarn 集群环境
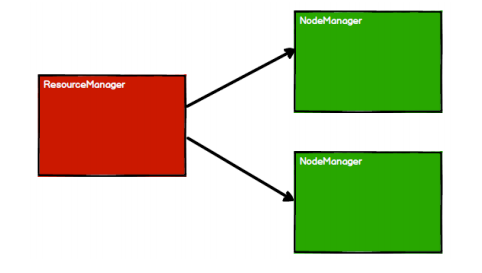
(2)Spark 通过申请资源创建调度节点和计算节点
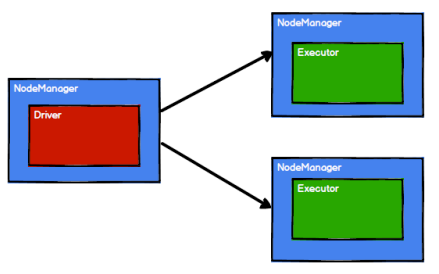
(3)Spark 框架根据需求将计算逻辑根据分区划分成不同的任务

(4)调度节点将任务根据计算节点状态发送到对应的计算节点进行计算(task会考虑优先分配给文本所在的executor)

从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算,接下来我们就一起看看 Spark 框架中 RDD 是具体是如何进行数据处理的。
RDD创建
在 Spark 中创建 RDD 的创建方式可以分为四种:
(1)从集合(内存)中创建 RDD
从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD:
val sparkConf =
new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val rdd1 = sparkContext.parallelize(
List(1,2,3,4)
)
val rdd2 = sparkContext.makeRDD(
List(1,2,3,4)
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sparkContext.stop()
从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
(2)从外部存储(文件)创建 RDD
由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集,比如 HDFS、HBase 等。
def main(args: Array[String]): Unit = {
// Todo 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// Todo 创建RDD: 从文件中创建RDD,将文件中的数据作为处理的数据源
// Todo 1. 绝对路径
val rdd: RDD[String] = sc.textFile("D:\\spark-learn\\datas\\1.txt")
// Todo 2. 相对路径: 以当前环境的根路径为基准 Project
val rdd: RDD[String] = sc.textFile("datas/1.txt")
// Todo 3. 目录,读取所有文件
val rdd: RDD[String] = sc.textFile("datas")
// Todo 4. path路径还可以使用通配符 *
val rdd: RDD[String] = sc.textFile("datas/1*.txt")
// Todo 5. path还可以是分布式存储系统路径:HDFS
val rdd: RDD[String] = sc.textFile("hdfs://hadoop131:9000/b.txt")
// 按行打印文件内容
rdd.collect().foreach(println)
// Todo 关闭环境
sc.stop()
}
- textFile: 以行为单位来读取数据,读取的数据都是字符串
- wholeTextFiles: 读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容,即
(path, content)
/*
(file:/D:/spark-learn/datas/1.txt,hello world hello spark)
(file:/D:/spark-learn/datas/2.txt,hello world hello spark)
*/
val rdd: RDD[(String, String)] = sc.wholeTextFiles("datas")
(3)从其他RDD创建
主要是通过一个 RDD 运算完后,再产生新的 RDD。详情请参考后续章节
(4)直接创建RDD(new)
使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。
RDD并行度与分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
比如一个Job,被切分为10个子任务,CPU核数有8个,那么并行度最大为8,绝不是10
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = {
parallelize(seq, numSlices)
}
调用例子:
val rdd = sc.makeRDD(List(1,2,3,4))
val rdd = sc.makeRDD(List(1,2,3,4),2)
makeRDD方法可以传递第二个参数,这个参数表示分区的数量,makeRDD是可以选择性的传入numSlices。如果不传递,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度),也就是scheduler.conf.getInt(“spark.default.parallelism”, totalCores),spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism,如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数。
可以自行配置如下:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
sparkConf.set("spark.default.parallelism", "5")
val sc = new SparkContext(sparkConf)
内存数据的分区
读取内存数据时,数据可以按照并行度的设定进行数据的分区操作,数据分区规则的 Spark 核心源码如下:
//length = 集合长度 numSlices = 分区个数
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
看下几个例子:
// 【1,2】,【3,4】
//val rdd = sc.makeRDD(List(1,2,3,4), 2)
// 【1】,【2】,【3,4】
//val rdd = sc.makeRDD(List(1,2,3,4), 3)
// 【1】,【2,3】,【4,5】
val rdd = sc.makeRDD(List(1,2,3,4,5), 3)
分析一下:
以List(1,2,3,4,5),分区个数=3为例,length=5, numSlices=3
i => [start, end) 该区间最终取左闭右开
0 => [0, 1) = 0
1 => [1, 3) = 1,2
2 => [3, 5) = 3,4
文件数据的并行度和分区
读取文件:
/**
* path:路径
* minPartitions:最小分区数量,默认值为defaultMinPartitions = math.min(defaultParallelism, 2)
* 其中,defaultParallelism为默认并行度,该参数在2.2节中详细说过,= local[n]默认为n,local[*]为核心数
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions)
Spark读取文件进行分区,底层其实使用的就是Hadoop的切片方式,简单来说分为三个步骤:
//1. 计算文件的总字节个数
long totalSize = compute(...)
//2. 计算每个分区的目标大小
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
//3. 计算分区个数
totalNum = totalSize / goalSize; //如果余数较大,totalNum++
实例1:不传分区数量
val rdd: RDD[String] = sc.textFile("datas/1.txt")
// 最小分区数量 minPartitions = math.min(defaultParallelism, 2) = 2
// 1. 假设总字节大小 totalSize = 24(byte)
// 2. 每个分区的目标大小 goalSize = totalSize / 2 = 12 (byte)
// 3. 最终分区数量 24 / 12 = 2 (可以整除)
实例2:传入分区数量
val rdd1 = sc.textFile("datas/3.txt", 2)
// 最小分区数量minPartitions = num = 2
// 1. totalSize = 7(byte)
// 2. goalSize = totalSize / num = 7 / 2 = 3(byte)
// 3. 最终分区数量: 7 / 3 = 2...1 (不小于1.1倍) + 1 = 3
// 解释:如果余数足够小,为了防止小文件产生,只分为一个分区;如果余数较大,单独成为一个分区
所以无论是默认还是传入,minPartitions 都不代表最终的分区数量,它代表最小分区数量,为计算切片大小、最终分区数量提供依据。
看下分区规则:
准备文件datas/3.txt,其中@@是换行符,占两个字节,故该文件共7个字节。
a@@
b@@
c
指定最小分区个数为2,实际会产生3个分区:
val rdd = sc.textFile("datas/3.txt", 2)
// 产生三个分区,内容分别为【a b】、【c】、【】
为什么没有将三个数字均匀分配到三个分区呢?接下来介绍Spark读取文件数据的分区规则:
(1)数据 以行为单位 进行读取
spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系。不存在一行只读部分,这一行要么不读,要么读整行。
(2)数据读取时,先以偏移量为单位,偏移量不会被重复读取
偏移量:按字节数量进行编号
a@@ => 012
b@@ => 345
c => 6
(3)数据分区的偏移量范围的计算
totalSize = 7(byte) goalSize = totalSize / num = 7 / 2 = 3(byte)
最终分区数量: 7 / 3 = 2(...1) + 1 = 3
所以,该RDD一共产生3个分区,分别为0,1,2
分区i => 逻辑偏移量范围 [left, right], left = (i-1)*goalSize, right = left + curSize
其中,分区0、1的curSize=3,分区2的curSize=1,由分区数量的计算步骤可得
然后,根据逻辑偏移量范围 [left, right],将涉及的行进行读取,不存在一行只读取部分
另外,偏移量不会被重复读取,跳至未读的偏移量
最终的结果为
分区 逻辑偏移范围 内容
0 => [0, 3] 0-3涉及前两行 => a b
1 => [3, 6] 3-5已读取,只读取6 => c
2 => [6, 7] 6已读取 =>
另一个例子:
内容 偏移量
abcdefg@@ => 012345678
hi@@ => 9101112
j => 13
totalSize = 14(byte)
goalSize = 14 / 2 = 7 (byte)
最终分区数量:14 / 7 = 2
分区 逻辑偏移量范围 内容
0 [0, 7] => abcdefg 会将8号字节读取(以行为单位)
1 [7, 14] => hij 字节7-8已读,读取9-14,会读两行
RDD转换算子
RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型。
Value类型
map
def map(f: T => U): RDD[U]
说明:将RDD中类型为T的元素,一对一地映射为类型为U的元素,这里的转换可以是类型的转换,也可以是值的转换。
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 值的转换 ==> List(2, 4, 6, 8)
val mapRDD: RDD[Int] = rdd.map( _ * 2 )
mapRDD.collect().foreach(println)
// 类型的转换 ==> List("1", "2", "3", "4")
val mapRDD1: RDD[String] = rdd.map( _ + "" )
mapRDD1.collect().foreach(println)
技巧:当map转换复杂的数据类型时,通过 模式匹配 简洁表达
tuple类型的转换:
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("d", 4)))
val mapRdd: RDD[String] = rdd.map(
(tuple: (String, Int)) => {
tuple._1 + tuple._2 // "a1","b2"...
}
)
val mapRdd1: RDD[String] = rdd.map { //最外层是 { }
case (str, num) => {
str + num
}
}
还要注意下map操作是串行的,其和主线程是并行运行的:
val rdd = sc.makeRDD(List(1,2,3,4),2)
val mapRDD = rdd.map(
num => {
println(">>>>>>>> " + num)
num
}
)
val mapRDD1 = mapRDD.map(
num => {
println("######" + num)
num
}
)
输出结果:
>>>>>>>> 3
>>>>>>>> 1
######1
######3
>>>>>>>> 4
>>>>>>>> 2
######2
######4
mapPartitions
def mapPartitions(
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
说明:将待处理的数据 以分区为单位 发送到计算节点进行处理,输入参数为RDD中每一个分区的迭代器。参数二preservesPartitioning是否保留父RDD的分区信息。
示例:获取每个数据分区的最大值:
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
// 传入 f: Iterator => Iterator
val mpRDD: RDD[Int] = rdd.mapPartitions(
iterator => {
List(iterator.max).iterator
}
)
mpRDD.collect().foreach(println)
output:
2
4
思考:map 和 mapPartitions 的区别?
-
数据处理角度 Map 算子是读一个record计算一个record,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作,会先将分区内的全部数据加载到内存中,然后执行逻辑。
-
功能的角度 Map 算子主要目的将数据源中的数据进行转换,不会减少或增多数据,映射前后维度不变。 MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,可以增加或减少数据。
-
性能的角度 Map 算子因为类似于串行操作,所以性能比较低,而 mapPartitions 算子类似于批处理,所以性能较高。
但是 mapPartitions 算子会将整个分区的数据加载到内存进行引用,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用MapPartitions。
思考:mapPartitions 使用场景?
如果在映射过程中需要频繁创建额外的对象,mapPartitions 可以使 RDD中各个分区可以共享同一个对象以提高性能。
思考:如何理解Map 算子类似于串行,而mapPartitions 算子是以分区为单位进行批处理操作呢?
- map
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 1) //单个分区
val mapRDD1: RDD[Int] = rdd.map(
num => {
println(">>>>>>>> " + num)
num
}
)
val mapRDD2: RDD[Int] = mapRDD1.map(
num => {
println("-------- " + num)
num
}
)
mapRDD2.collect()
output:
>>>>>>>> 1
-------- 1
>>>>>>>> 2
-------- 2
>>>>>>>> 3
-------- 3
>>>>>>>> 4
-------- 4
当分区个数为1时,只有当前面一个record全部的逻辑执行完毕后,才会执行下一个数据(串行)。分区内数据的执行是有序的。
当分区格式为2时,不同分区之间是并行执行的,无先后顺序;而同一分区内的数据,满足有序性,逐个执行(串行)。
- mapPartitions
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 传入 f: Iterator => Iterator
val mpRDD: RDD[Int] = rdd.mapPartitions(
// iterator代表一个分区的迭代器
iterator => {
println(">>>>>>>>>>")
iterator.map(_ * 2) //一次性加载整个分区,然后对该分区进行map转换,类似于批处理
}
)
mpRDD.collect()
output:
">>>>>>>>>>"
">>>>>>>>>>"
mapPartitionsWithIndex
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
说明:将待处理的数据 以分区为单位 发送到计算节点进行处理,在处理时同时可以获取当前分区索引。
示例:获取第二个数据分区的数据
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5), 3)
//分区结果 ==> 【1】,【2,3】,【4,5】
//获取第2个分区的数据
val mpiRDD = rdd.mapPartitionsWithIndex(
(index, iterator) => {
if (index == 1) {
iterator
} else {
Nil.iterator
}
}
)
mpiRDD.collect().foreach(println)// 【2,3】
flatMap
def flatMap(f: T => TraversableOnce[U]): RDD[U]
说明:将RDD中的每一个元素进行一对多转换,然后扁平化
强调:f: T => TraversableOnce[U]的返回值必须是可遍历集合,不能是标量。
// 先映射后打散,只需传入映射逻辑
val rdd1: RDD[String] = sc.makeRDD(List("hello spark", "hello scala"))
// "hello spark" ==> Array["hello", "spark"] ==> "hello", "spark"
val flatRDD1: RDD[String] = rdd1.flatMap(
s => s.split(" ")
)
flatRDD1.collect().foreach(println)
// hello
// spark
// hello
// scala
示例:将 List(List(1,2),3,List(4,5)) 进行扁平化操作
val rdd: RDD[Any] = sc.makeRDD(List(
List(1, 2), 3, List(4, 5)
))
// List中元素类型不同,需模式匹配
val flatRDD = rdd.flatMap{
case list: List[_] => list
case a: Int => List(a)
}
flatRDD.collect().foreach(println) // 1 2 3 4 5
glom(获取分区数组)
def glom(): RDD[Array[T]]
说明:将 同一个分区 的数据直接转换为相同类型的内存数组进行处理,分区不变,每个分区只有一个数组元素。
示例: 计算所有分区最大值求和(分区内取最大值,分区间求和)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5), 2)
// 【1,2】,【3,4,5】
// List(1,2,3,4) => RDD(Array(1,2), Array(3,4,5))
val glomRDD: RDD[Array[Int]] = rdd.glom()
// Array(1,2) -> 2; Array(3,4,5) -> 5
val maxRDD: RDD[Int] = glomRDD.map(
arr => arr.max
)
// RDD(2, 5) => 归约(相加)
val res: Int = maxRDD.reduce(_ + _)
println(res) // res = 7
- 补充:使用行动算子
aggregate一步实现
val res: Int = rdd.aggregate(0)(math.max(_, _), _ + _)
- 思考:如何理解分区不变性?
// 将RDD保存到目录下,以观察分区情况
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
rdd.saveAsTextFile("output1")
val mapRDD: RDD[Int] = rdd.map(_ * 2)
mapRDD.saveAsTextFile("output2")
/*
原始rdd的每条record会有分区号,经过map操作后,依然在相同的分区中
output1 part-00000 1 2
part-00001 3 4
output2 part-00000 2 4
part-00001 6 8
*/
与分区不变性相对立的是shuffle,下面介绍的算子groupBy涉及到shuffle过程。
groupBy
def groupBy
(f: T => K): RDD[(K, Iterable[T])]
说明:
/**
* groupBy(f: T => K ) 将数据源中的元素映射到key上
* T是数据源元素的类型,K为任意类型
*
* groupBy将数据源中的每一个数据进行f映射,根据返回的分组key进行分组
* 相同的key值的数据会放置在一个可迭代的集合中,即Iterable()中
*/
示例1:按奇偶分组
val intRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
// 按奇偶分组
val groupRDD1: RDD[(Int, Iterable[Int])] = intRdd.groupBy(
(num: Int) => {
num % 2
}
)
groupRDD1.collect().foreach(println)
// (0,CompactBuffer(2, 4, 6))
// (1,CompactBuffer(1, 3, 5))
示例2:按单词首字母分组
val strRdd: RDD[String] = sc.makeRDD(List("Hello", "Spark", "Scala", "Hadoop"), 2)
//按首字母分组
val groupRDD2: RDD[(Char, Iterable[String])] = strRdd.groupBy(
word => word.charAt(0)
)
groupRDD2.collect().foreach(println)
// (H,CompactBuffer(Hello, Hadoop))
// (S,CompactBuffer(Spark, Scala))
Q:分组和分区有什么关系?
A:分组后,一个组的数据会在一个分区中,但是并不是说一个分区中只有一个组,一句话:分组和分区没有必然的关系。
val intRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
// 原集合分区
intRdd.saveAsTextFile("output1")
val groupRDD: RDD[(Int, Iterable[Int])] = intRdd.groupBy(
(num: Int) => {
num % 2
}
)
// 分组后
groupRDD.saveAsTextFile("output2")
结果:
output1: part-00000 1 2 3
part-00001 4 5 6
output2: part-00000 (0,CompactBuffer(2, 4, 6))
part-00001 (1,CompactBuffer(1, 3, 5))

filter
def filter(f: T => Boolean): RDD[T]
说明:将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃(返回True的保留,False丢弃)
示例:过滤,只保留偶数
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
val filterRdd: RDD[Int] = rdd.filter(num => num % 2 == 0)
filterRdd.collect().foreach(println) // 2 4 6
当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,即数据倾斜。
val rdd: RDD[Int] = sc.makeRDD(List(2, 4, 6, 8, 1, 3, 5, 8), 2)
val filterRdd: RDD[Int] = rdd.filter(num => num % 2 == 0)
// 原分区: 【2,4,6,8】 【1,3,5,8】
// 过滤分区不变:【2,4,6,8】 【8】 <== 不同分区的数据不均衡
distinct
def distinct(): RDD[T]
def distinct(numPartitions: Int): RDD[T]
说明:将数据集中重复的数据去重
/**
* 空参 distinct() 调用的实际是 distinct(partitions.length)
* 其中,distinct(numPartitions: Int) 去重原理为
* map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
*/
示例:去重
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 4))
rdd.distinct()
.collect().foreach(println) // 1 2 3 4
coalesce(缩小/扩大分区)
def coalesce(numPartitions: Int,
shuffle: Boolean = false): RDD[T]
说明:根据数据量增减分区,用于大数据集过滤后,提高小数据集的执行效率。
当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩分区,减少分区的个数,减小任务调度成本。
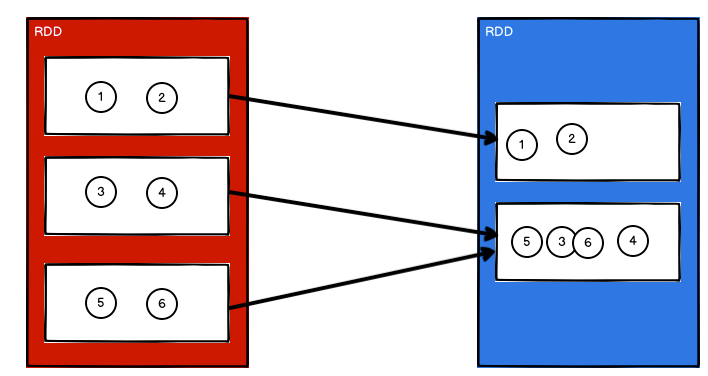
(1)缩小分区(N > M)且 N 和 M 相差不多的两种形式
/*
1. coalesce方法默认情况下不会将分区的数据打乱重新组合
例如元素3和4原本同一分区,那么缩减后仍会处于同一分区(窄依赖)
这种情况下的缩减分区可能会导致数据倾斜
*/
val rdd = sc.makeRDD(List(1,2,3,4,5,6), 3)
val newRDD: RDD[Int] = rdd.coalesce(2)
newRDD.saveAsTextFile("output")
// 产生两个分区:分别为【1,2】、【3,4,5,6】
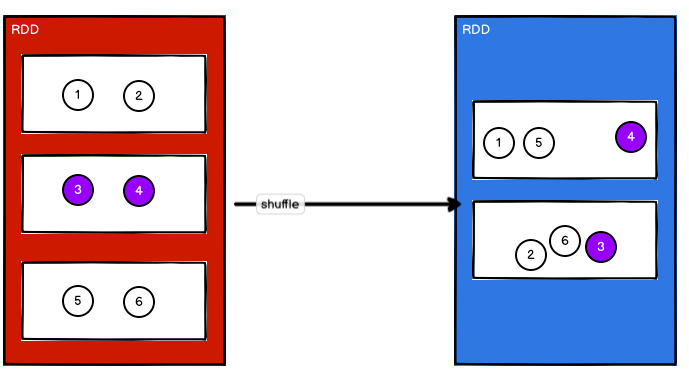
// 2. 如果想要让数据均衡,可以进行shuffle处理,第二个参数为True(宽依赖)
val newRDD: RDD[Int] = rdd.coalesce(2, true)
newRDD.saveAsTextFile("output")
(2)扩大分区(N < M)
扩大分区个数,如果不进行shuffle操作,是没有意义的,无法改变RDD分区数目:
val rdd = sc.makeRDD(List(1,2,3,4,5,6), 2)
val newRDD: RDD[Int] = rdd.coalesce(3, shuffle = true)
spark提供了一个简化的操作repartition,专门用于扩大分区, 底层代码调用的就是coalesce,而且采用shuffle。
repartition(扩大分区)
def repartition(numPartitions: Int): RDD[T] = coalesce(numPartitions, shuffle = true)
示例:
val rdd = sc.makeRDD(List(1,2,3,4,5,6), 2)
rdd.repartition(3)
.saveAsTextFile("output")
// 【1,6】 【2,5】 【3,4】
- 思考:coalesce 和 repartition 区别?
coalesce 和 repartition 本质是相同的,后者底层代码调用的就是coalesce,且一定要经过shuffle。
习惯上减少分区使用coalesce, 扩大分区使用repartition 。
sortBy
def sortBy(
f: T => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length): RDD[T]
说明:该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列,第二个参数为False为降序。
默认排序前后 RDD 的分区数一致,中间存在 shuffle 的过程。
示例1:
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 6, 5, 4, 3), 2)
val newRDD: RDD[Int] = rdd.sortBy(num=>num)
newRDD.saveAsTextFile("output")
// 两个分区为 【1,2,3】 【4,5,6】,所以经历了shuffle
示例2:
val rdd = sc.makeRDD(List(("1", 1), ("11", 2), ("2", 3)), 2)
// 按元组的第一个元素,降序
val sortRDD: RDD[(String, Int)] = rdd.sortBy(t => t._1, false)
sortRDD.collect().foreach(println) // ("2",3) ("11",2) ("1",1)
sample
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
说明:根据指定的规则从数据集中抽取数据
抽样函数的作用:对发生数据倾斜的分区数据集,进行多次抽样,从样本中分析数据的分布。
(1)不放回
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
/* 抽取数据不放回(伯努利算法)
具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
第一个参数:抽取的数据是否放回,false:不放回
第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
第三个参数:随机数种子,种子相同随机结果也是相同的,不传递的话默认值为当前系统时间
*/
println(rdd.sample(
false,
0.3
).collect().mkString(","))
// 7,8,9
(2)放回
/* 抽取数据放回(泊松算法)
第一个参数:抽取的数据是否放回,true:放回
第二个参数:表示数据源中的每条数据被抽取的可能次数
第三个参数:随机数种子
*/
println(rdd.sample(
true,
2
).collect().mkString(","))
// 1,1,2,2,4,6,6,6,6,6,7,8,8,9,10
双 Value 类型
方法签名:
// 交集
def intersection(other: RDD[T]): RDD[T]
// 并集
def union(other: RDD[T]): RDD[T]
// 差集
def subtract(other: RDD[T]): RDD[T]
// 拉链,形成元组
def zip(other: RDD[U]): RDD[(T, U)]
示例:
val rdd1: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val rdd2: RDD[Int] = sc.makeRDD(List(3,4,5,6))
// 交集 : 【3,4】,会去重
val rdd3: RDD[Int] = rdd1.intersection(rdd2)
println(rdd3.collect().mkString(","))
// 并集 : 【1,2,3,4,3,4,5,6】,不会去重
val rdd4: RDD[Int] = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))
// 差集 : 【1,2】
val rdd5: RDD[Int] = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))
// 拉链 : (1,3),(2,4),(3,5),(4,6)
val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2)
println(rdd6.collect().mkString(","))
特点:
- 交集、并集 和 差集要求两个数据源数据类型一致
- 拉链操作:两个数据源的类型可以不一致
val rdd7 = sc.makeRDD(List("a","b","c","d"))
val rdd8 = rdd1.zip(rdd7)
println(rdd8.collect().mkString(","))
// (1,a),(2,b),(3,c),(4,d)
- 拉链操作:两个RDD要求分区数量要保持一致,分区中数据量保持一致
val rdd1 = sc.makeRDD(List(1,2,3,4),2)
val rdd2 = sc.makeRDD(List(3,4,5,6),3)
// val rdd3: RDD[(Int, Int)] = rdd1.zip(rdd2) 分区数量不一致,异常
val rdd4 = sc.makeRDD(List(3,4,5,6,7,8), 2)
// val rdd5: RDD[(Int, Int)] = rdd1.zip(rdd5) 分区中数据量不一致,异常
注:scala语法中,两个集合zip操作,不要求元素个数相同。
Q:是否存在shuffle?
A:一般情况下,intersection和subtract都会有shuffle过程;而union是窄依赖(RangeDependency ),不存在shuffle,如下图所示:
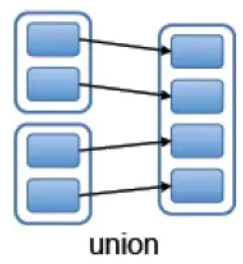
Key - Value 类型
Value 类型 与 Key - Value 类型区别在于,前者更为广泛,单值RDD[U]与键值RDD[(K,V)]都适用;后者只适用于RDD[(K,V)]。
partitionBy(重分区)
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
说明:将数据 基于 key 按照指定 Partitioner 重分区。Spark 默认的分区器是 HashPartitioner。
按照指定的分区器,对Key进行计算得到新的分区号,从而对数据重新分区。
val rdd: RDD[(Int, String)] = sc.makeRDD(
Array((1,"aaa"),(2,"bbb"),(3,"ccc"), (4,"ddd")),
2)
/* HashPartitioner(2) 传入分区数为2,也可以与原分区数不同 */
val value: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2))
value.saveAsTextFile("output")
// Key 按照哈希分区器划定分区,【(1,"aaa"),(3,"ccc")】 【(2,"bbb"),(4,"ddd")】
-
补充:
partitionBy()是PairRDDFunctions类中的方法,那么RDD为何可以调用呢?/* 因为存在 隐式转换(二次编译),RDD => PairRDDFunctions */ abstract class RDD {...} object RDD{ implicit def rddToPairRDDFunctions(rdd: RDD) = new PairRDDFunctions(rdd) ... } -
思考:如果重分区的分区器和当前 RDD 的分区器一样怎么办?
/* 当【分区器类别 + 分区数量】相同时,就不会创建新的RDD,返回当前RDD 二者有任一不同,将创建新的RDD返回 */ val value: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2)) val value1: RDD[(Int, String)] = value.partitionBy(new HashPartitioner(2)) println(value1 == value) // true -
思考:Spark 还有其他分区器吗?
常见的有 HashPartitioner、RangePartitioner
-
思考:如果想按照自己的方法进行数据分区怎么办?
自定义分区器,继承 Partitioner
mapValues
def mapValues(f: V => U): RDD[(K, U)]
说明:针对KV类型的映射map,当K不变,只对V进行映射时,可采用mapValues简化
示例:wordCount
val rdd = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val flatRdd: RDD[String] = rdd.flatMap(_.split(" "))
val groupRdd: RDD[(String, Iterable[String])] = flatRdd.groupBy(str => str)
// 使用map,(k1,V1) -> (k2,v2)
val value: RDD[(String, Int)] = groupRdd.map{
case (a, b) => {
(a, b.size)
}
}
// 使用mapValues,(K,V) -> (K,U)
val value: RDD[(String, Int)] = groupRdd.mapValues(
iter => iter.size
)
outout:
// (Spark,1)
// (Hello,2)
// (Scala,1)
reduceByKey
// 泛型为[K, V],V代表value的类型
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
说明:相同的key的数据进行value的聚合操作(两两聚合),传入的func表示两个val的聚合逻辑。如果key的数据只有一个,是不会参与运算的,直接返回。
示例:wordCount
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// 【1,2,3】-> 【3,3】 -> 【6】
val value: RDD[(String, Int)] = rdd.reduceByKey(
(x: Int, y: Int) => {
x + y
}
)
value.collect().foreach(println)
// (a,6)
// (b,4)
groupByKey(分组)
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
说明:将数据源的数据按照key ,对 value 进行分组
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// groupByKey : 针对[K,V]类型,将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组
// 元组中的第一个元素就是key,元组中的第二个元素就是相同key的value的集合
val groupRDD1: RDD[(String, Iterable[Int])] = rdd.groupByKey()
groupRDD1.collect().foreach(println)
// (a,CompactBuffer(1, 2, 3))
// (b,CompactBuffer(4))
println(groupRDD1.partitioner)
// Some(org.apache.spark.HashPartitioner@8) 默认使用哈希分区器,8个分区
- groupByKey 与 groupBy的区别?
| groupByKey | groupBy | |
|---|---|---|
| 适用集合类型 | 必须是RDD[(K, V)] | 任意RDD[T] |
| 分组逻辑 | 按照Key分组 | 自定义f:T->key,需传入 |
| 返回值 | k ->Iterable(v1, v2, ...) | k -> Iterable(T1, T2, ...) |
- reduceByKey 和 groupByKey 的区别?
- 从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
- 从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合,只能使用 groupByKey。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wdmhC68i-1671283531682)(http://image.codekiller.top/img/spark/image-20221028165544351.png")

reduceByKey针对分区内与分区间,计算规则是相同的。如果分区内与分区间的计算规则不同,可以使用aggregateByKey。
aggregateByKey(分区内+外聚合)
def aggregateByKey(zeroValue: U)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
说明:将数据根据 不同的规则 进行分区内计算和分区间计算
/**
* aggregateByKey存在函数柯里化,有两个参数列表
* 第一个参数列表,需要传递一个参数,表示为初始值(只用于分区内计算)
* 用于当碰见key第一个value时,与它进行分区内计算
* 第二个参数列表需要传递2个参数
* 参数1表示分区内计算规则
* 参数2表示分区间计算规则
*/
示例:取出每个分区内相同 key 的最大值然后分区间相加
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),2)
rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect().foreach(println)
//(b,8)
//(a,8)

初始值zeroValue的选取是重要的,如果给的值不合适,将会是不同的结果:
rdd.aggregateByKey(5)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect().foreach(println)
//(b,10)
//(a,11)

aggregateByKey中初始值的类型与原本值的类型 可以不同,而最终的返回数据结果应该和初始值的类型保持一致,重温一下方法签名:
// 键值对的泛型[K, V],输出为[K, U]
def aggregateByKey(zeroValue: U)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
示例:获取相同key的数据的平均值
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),2)
// 获取相同key的数据的平均值 => (a, 3),(b, 4)
val newRDD : RDD[(String, (Int, Int))] = rdd.aggregateByKey( (0,0) )(
// (Tuple, Int) => Tuple
// a: t=(0,0),v=1 => (1,1) => t=(1,1),v=2 => (3,2)
( t, v ) => {
(t._1 + v, t._2 + 1)
},
// (Tuple, Tuple) => Tuple
// a: t1=(3,2),t2=(6,1) => (9,3)
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
// 对[K,V]做映射时,若K保持不动,仅对V做映射,可使用mapValues(f: V => U)
val resultRDD: RDD[(String, Int)] = newRDD.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRDD.collect().foreach(println) // (a, 3) (b, 4)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aNBZj5Tk-1671283531683)(http://image.codekiller.top/img/spark/image-20221028171138143.png")
foldByKey(分区内+外简化聚合)
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
说明:当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
示例:
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),2)
// 二者等价: 结果为 (b,12),(a,9)
rdd.aggregateByKey(0)(_+_, _+_)
rdd.foldByKey(0)(_+_)
注:值得注意的是,foldByKey保持键值对的泛型不变((k,v)->(k,v)),而aggregateByKey可能会改变输出的值类型((k,v)->(k,u))。
- 问题:当分区内计算规则和分区间计算规则相同时,foldByKey和reduceByKey都能实现,二者有什么区别呢?
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
相同点:不会改变键值对类型(K,V)->(K,V),针对相同的Key,对Value做两两聚合操作
不同点:reduceByKey没有初始值,如果key的数据只有一个,是不会参与运算的,直接返回;而foldByKey要给定初始值,如果key的数据只有一个,就会与初始值进行计算。
combineByKey(分区内+外 初始值转换聚合)
def combineByKey(
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
说明:它是对aggregateByKey的另一种实现,它不直接给定初始值,而是将相同key的第一个数据进行结构的转换,作为初始值。
/**
* combineByKey : 方法需要三个参数
* 1. createCombiner:将相同key的第一个数据进行结构的转换,实现操作
* 2. mergeValue:分区内的计算规则
* 3. mergeCombiners:分区间的计算规则
*/
示例:获取相同key的数据的平均值
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),2)
//注:因为第一个参数返回值类型是动态的,所以计算规则需加上泛型限定
val newRDD : RDD[(String, (Int, Int))] = rdd.combineByKey(
t => (t, 1), //"a": 1 => (1, 1)形成初始值
( t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val resultRDD: RDD[(String, Int)] = newRDD.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRDD.collect().foreach(println) // (a, 4) (b, 4)
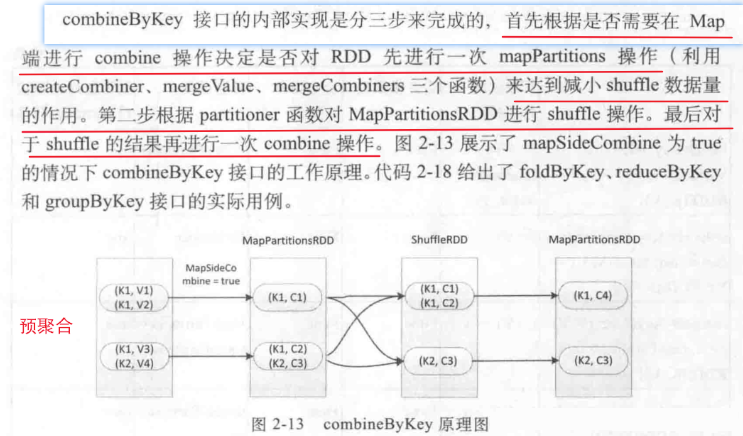
执行流程(初始值 -> 分区内 -> 分区间)如图所示:

-
groupByKey、reduceByKey、foldByKey、aggregateByKey这四种算子,最终都归结为对combineByKey 的调用。
-
combineByKey 共有五个参数如下:

-
值得注意的是:groupByKey的参数
mapSideCombine=false,不会在map端进行combine操作,其余四种算子该参数为mapSideCombine=true。 -
归约算子的内部实现:
| 转换操作 | 生成RDD的类型 |
|---|---|
| combineByKey (reduceByKey、foldByKey、aggregateByKey) | MapParitionsRDD(预聚合)-> ShuffledRDD -> MapParitionsRDD |
| groupByKey | ShuffledRDD -> MapParitionsRDD |
其中, ShuffledRDD 进行 reduce(通过 aggregate + mapPartitions() 操作来实现)得到 MapPartitionsRDD。
- 对比:reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别?
| 初始值 | 相同的Key第一个值 | 分区内&分区间的计算规则 | |
|---|---|---|---|
| reduceByKey | 无 | 相同 key 的第一个数据不进行任何计算 | 计算规则相同 |
| foldByKey | 给定 | 相同 key 的第一个数据和初始值进行分区内计算 | 计算规则相同 |
| aggregateByKey | 给定 | 相同 key 的第一个数据和初始值进行分区内计算 | 计算规则可以不同 |
| combineByKey | 无 | 相同 key 的第一个数据结构转换,作为初始值 | 计算规则可以不同 |
重要相同点:四个算子均具有“预聚合”功能,即在shuffle落盘之前,在内存中先聚合数据,再写入磁盘,减少数据落盘量
示例:实现wordCount
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),2)
//实现wordCount的四种方式:(b,12)、(a,9)
rdd.reduceByKey(_+_)
rdd.aggregateByKey(0)(_+_, _+_)
rdd.foldByKey(0)(_+_)
rdd.combineByKey(v=>v, (v1: Int, v2) => v1+v2, (v1: Int, v2: Int)=> v1+v2)
join
def join(other: RDD[(K, W)]): RDD[(K, (V, W))]
说明:在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的 RDD
val rdd1 = sc.makeRDD(List( ("a", 1), ("b", 2), ("c", 3) ))
val rdd2 = sc.makeRDD(List( ("a", 4), ("a", 5), ("c", 6) ))
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
//(a,(1,5))
//(a,(1,4))
//(c,(3,6))
如果两个数据源中key没有匹配上,那么数据不会出现在结果中(内连接,取交集);
如果两个数据源中key有多个相同的,会逐个匹配,可能会出现笛卡尔乘积,且会发生shuffle,故不推荐使用。
leftOuterJoin
def leftOuterJoin(other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
说明:类似于左外连接,保留主表的所有数据,从表数据会由Option封装。
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5)))
val leftRDD: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
//(a,(1,Some(4)))
//(b,(2,Some(5)))
//(c,(3,None))
相应的,还有右外连接rightOuterJoin。
cogroup
def cogroup(other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
说明:在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的 RDD
val rdd1 = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5),("c", 6),("c", 7)))
val value: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
// (a,(CompactBuffer(1, 2),CompactBuffer(4)))
// (b,(CompactBuffer(3),CompactBuffer(5)))
// (c,(CompactBuffer(),CompactBuffer(6, 7)))
它的Join的区别在于:Join返回的是两侧RDD公共的Key,而cogroup可以返回仅一侧出现的Key,类似于全外连接。
join等连接操作的底层,使用的是cogroup实现,Join内部机制如图:
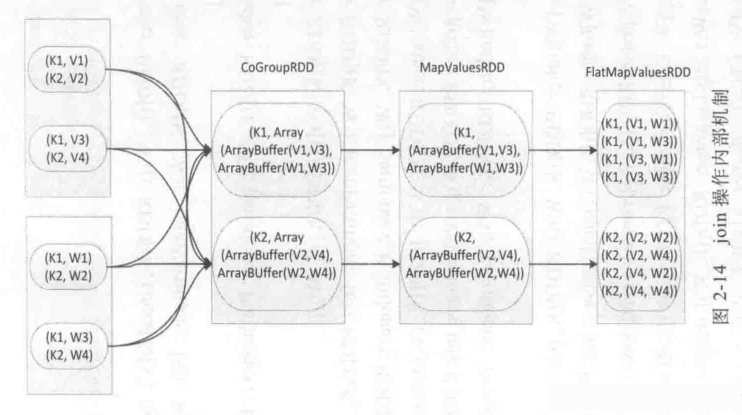
sortByKey
def sortByKey(ascending: Boolean = true,
numPartitions: Int = self.partitions.length): RDD[(K, V)]
说明:在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 特质,返回一个按照 key 进行排序的(K, V)
val dataRDD1 = sc.makeRDD(List(("a",3),("b",2),("c",1)))
val sortRdd1: RDD[(String, Int)] = dataRDD1.sortByKey()
// 按Key升序 (a,3),(b,2),(c,1)
val sortRdd2: RDD[(String, Int)] = dataRDD1.sortByKey(false)
// 按Key降序 (c,1),(b,2),(a,3)
经典案例
数据准备:
agent.log [时间戳,省份,城市,用户,广告],中间字段使用空格分隔。
功能实现:统计出 每一个省份 每个广告被点击数量排行的 Top3
分析:
① 提取有效数据:通过map只保留有效数据,比如省份,广告,减少数据传输量
② 建立有效键Key:省份与广告均为分组关键词,应将元组(省份,广告)作为Key
③ 归约: ( ( 省份,广告 ), 1 ) => ( ( 省份,广告 ), sum )
④ 结构转换:为了查询每一个省份的TOP,做转换 ( ( 省份,广告 ), sum ) => ( 省份, ( 广告, sum ) )
⑤ 分组:按照省份进行分组,每个省份对应多干个( 广告, sum )
⑥ 排序:对sum降序排序,取前三

// 1. 获取原始数据:时间戳,省份,城市,用户,广告
val rdd: RDD[String] = sc.textFile("data/agent.log")
// 2. 将原始数据进行结构的转换。方便统计
// 时间戳,省份,城市,用户,广告
// =>
// ( ( 省份,广告 ), 1 )
val mapRDD: RDD[((String, String), Int)] = rdd.map(
line => {
val words: Array[String] = line.split(" ")j
}
)
// 3. 将转换结构后的数据,进行分组聚合
// ( ( 省份,广告 ), 1 ) => ( ( 省份,广告 ), sum )
val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_ + _)
// 4. 将聚合的结果进行结构的转换
// ( ( 省份,广告 ), sum ) => ( 省份, ( 广告, sum ) )
val mapRdd1: RDD[(String, (String, Int))] = reduceRDD.map {
case ((prv, ad), sum) => {
(prv, (ad, sum))
}
/*
case (tuple, cnt) => {
(tuple._1, (tuple._2, cnt))
}*/
}
// 5. 将转换结构后的数据根据省份进行分组
// ( 省份, 【( 广告A, sumA ),( 广告B, sumB )】 )
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRdd1.groupByKey()
// 6. 将分组后的数据组内排序(降序),取前3名
val resultRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
// 7. 采集数据打印在控制台
resultRDD.collect().foreach(println)
RDD行动算子
如何理解行动算子?
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 转换算子:将旧的RDD封装为新的RDD,形成transform chain,不会执行任何Job
val mapRdd: RDD[Int] = rdd.map(_ * 2)
// 行动算子:其实就是触发作业(Job)执行的方法,返回值不再是RDD
mapRdd.collect()
collect()等行动算子在底层调用环境对象的runJob方法,会创建ActiveJob,并提交执行。
如果只有转换算子,而没有行动算子,那么Job不会执行,只是功能上的封装拓展。
转换算子将功能不断封装,最终由行动算子执行Job,这比封装一次执行一次,更加高效。
还有一个重要特点,转换算子的返回值是RDD,行动算子的返回值是scala集合或标量。
collect
def collect(): Array[T]
说明:会将不同分区的数据按照分区顺序采集到Driver端内存中,形成数组
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val arr: Array[Int] = rdd.collect()
println(arr.mkString(","))
//1,2,3,4 ==> 保持顺序
- 其他:
val rdd = sc.makeRDD(List(4,2,3,1))
// count : 数据源中数据的个数
val cnt: Long = rdd.count()
// first : 获取数据源中数据的第一个元素
val first: Int = rdd.first()
// take : 返回一个由 RDD 的前 n 个元素组成的数组 Array(4, 2, 3)
val ints: Array[Int] = rdd.take(3)
// takeOrdered : 返回该 RDD 排序后的前 n 个元素组成的数组 Array(1, 2, 3)
val ints1: Array[Int] = rdd.takeOrdered(3)
// top: 与takeOrdered正好反序
val ints2: Array[Int] = rdd.top(3)
// Array(4, 3, 2)
以count为例,说明action算子执行的流程:
- 每个 task 统计每个 partition 里 records 的个数,比如 partition 0 里含有 5 个 records,partition 1 里含有 10 个 records 等 。
- task 执行完后,driver 收集每个 task 的执行结果,然后进行 sum()。
总结:分区内计算(并行),分区间汇总(Driver)
reduce
def reduce(f: (T, T) => T): T
说明:对 RDD 中的元素进行二元计算,分区内与分区间计算规则相同。
// 单值类型 f:(Int, Int) => Int
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val reduceRDD: Int = rdd.reduce((x, y) => x + y)
// 10
// KV类型: f:((string,Int), (string,Int)) => (string,Int)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("hello", 2), ("hello", 3)))
val reduceRDD1: (String, Int) = rdd1.reduce(
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
// ("hello", 5)
aggregate
def aggregate(zeroValue: U)
(seqOp: (U, T) => U, combOp: (U, U) => U): U
说明:分区的数据通过初始值先和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val res: Int = rdd.aggregate(0)(_ + _, _ + _)
//res = 10
val res1: Int = rdd.aggregate(10)(_ + _, _ + _)
//分区内:13 和 17;分区间 13 + 17 + 10 = 40,故 res = 40
- 区别:
aggregateByKey : 初始值只会参与分区内计算;仅适用于 KV 类型
aggregate : 初始值会参与分区内计算,并且和参与分区间计算;可使用任意类型
fold
def fold(zeroValue: T)(op: (T, T) => T): T
说明:当分区内与分区间的计算规则相同时,它是aggregate 的简化版操作
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val result = rdd.aggregate(0)(_+_, _+_)
val result1 = rdd.fold(0)(_+_)
//res=10
countByKey/Value
def countByKey(): Map[K, Long]
说明:统计每种 key 的个数
// 针对KV类型,计算每个Key出现的个数(并不是聚合!)
val rdd = sc.makeRDD(List(
("a", 1),("a", 2),("a", 3),("b",2)
))
val countKeyRdd: collection.Map[String, Long] = rdd.countByKey()
println(countKeyRdd) // Map(a -> 3, b -> 1)
补充:countByValue
// 任意类型的集合
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val countValRdd: collection.Map[Int, Long] = rdd.countByValue()
println(countValRdd)
// Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1)
foreach
def foreach(f: T => Unit): Unit
说明:分布式遍历 RDD 中的每一个元素,调用指定函数
val rdd = sc.makeRDD(List(1,2,3,4), 2)
// 先collect(),在Driver端内存 循环遍历
rdd.collect().foreach(println)
1
2
3
4
val rdd = sc.makeRDD(List(1,2,3,4), 2)
// rdd.foreach 其实是Executor端内存数据打印(分布式打印)
rdd.foreach(println)
3
1
4
2
图解:

类似的,行动算子 foreachPartition(f: Iterator[T] => Unit) 针对RDD的每个分区执行一次。
save
将数据保存到不同格式的文件中
val rdd = sc.makeRDD(List(("a", 1),("a", 2),("a", 3)))
// 保存成 Text 文件(最常用)
rdd.saveAsTextFile("output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
//保存成 Sequencefile 文件,该方法要求数据的格式必须为K-V类型
rdd.saveAsSequenceFile("output2")
该方法可以用来查看分区结果:
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
rdd.saveAsTextFile("output")

RDD序列化
介绍
Spark是基于JVM运行的进行,其序列化必然遵守Java的序列化规则。
序列化就是指将一个对象转化为二进制的byte流(注意,不是bit流),然后以文件的方式进行保存或通过网络传输,等待被反序列化读取出来。序列化常被用于数据存取和通信过程中。
对于java应用实现序列化一般方法:
- class实现序列化操作是让class 实现Serializable接口,但实现该接口不保证该class一定可以序列化,因为序列化必须保证该class引用的所有属性可以序列化。
- 这里需要明白,static和transient修饰的变量不会被序列化,这也是解决序列化问题的方法之一,让不能序列化的引用用static和transient来修饰。(static修饰的是类的状态,而不是对象状态,所以不存在序列化问题。transient修饰的变量,是不会被序列化到文件中,在被反序列化后,transient变量的值被设为初始值,如int是0,对象是null)
- 此外还可以实现readObject()方法和writeObject()方法来自定义实现序列化。
Spark的transformation操作为什么需要序列化?
Spark是分布式执行引擎,其核心抽象是弹性分布式数据集RDD,其代表了分布在不同节点的数据。Spark的计算是在executor上分布式执行的,故用户开发的关于RDD的map,flatMap,reduceByKey等transformation 操作(闭包)有如下执行过程:
- 代码中对象在driver本地序列化
- 对象序列化后传输到远程executor节点
- 远程executor节点反序列化对象
- 最终远程节点执行
故对象在执行中需要序列化通过网络传输,则必须经过序列化过程。
在spark中4个地方用到了序列化:
- 算子中用到了driver定义的外部变量的时候;
- 将自定义的类型作为RDD的泛型类型,所有的自定义类型对象都会进行序列化;
- 使用可序列化的持久化策略的时候。比如:MEMORY_ONLY_SER,spark会将RDD中每个分区都序列化成一个大的字节数组。
- shuffle的时候
任何分布式系统中,序列化都扮演着一个很重要的角色。如果使用的序列化技术操作很慢,或者序列化之后数据量还是很大的话,那么会严重影响分布式系统的性能。
案例
下面看看一个案例:
object Spark01_RDD_Serial {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
val search = new Search("h")
//search.getMatch1(rdd).collect().foreach(println)
search.getMatch2(rdd).collect().foreach(println)
sc.stop()
}
// 查询对象
// 类的构造参数其实是类的属性, 构造参数需要进行闭包检测,其实就等同于类进行闭包检测
class Search(query:String){
def isMatch(s: String): Boolean = {
s.contains(this.query)
}
// 函数序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
val s = query
rdd.filter(x => x.contains(s))
}
}
}
算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。
如果不进行序列化直接运行程序会发现报错: Task not serializable。
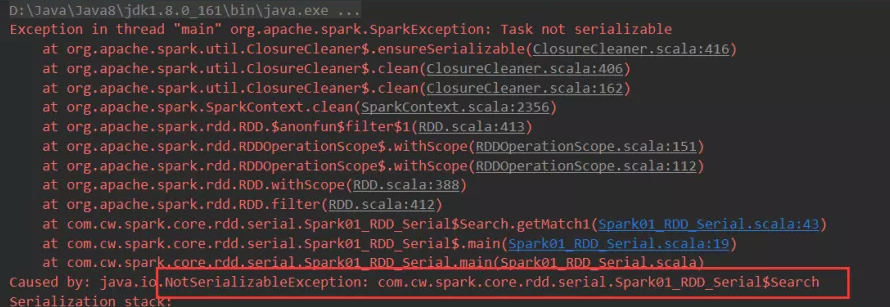
将上述代码从scala反编译为java可以看到:
- 类的构造参数其实是类的属性,构造参数需要进行闭包检测,其实就等同于类进行闭包检测,闭包概念见Spark中的闭包和闭包检测
- 在getMatch1方法中所调用的方法isMatch()是定义在Search这个类中的,实际上调用的是this.isMatch(),this表示Searcher这个类的对象,程序在运行过程中需要将Searcher对象序列化以后传递到Executor端。
- 在getMatch2方法中所调用的方法query是定义在Searcher这个类中的字段,实际上调用的是this.query,this表示Searcher这个类的对象,程序在运行过程中需要将Search对象序列化以后传递到Executor端。
public static class Search {
private final String query;
public boolean isMatch(final String s) {
return s.contains(this.query);
}
public RDD getMatch1(final RDD rdd) {
return rdd.filter((s) -> {
return BoxesRunTime.boxToBoolean($anonfun$getMatch1$1(this, s));
});
}
public RDD getMatch2(final RDD rdd) {
return rdd.filter((x) -> {
return BoxesRunTime.boxToBoolean($anonfun$getMatch2$1(this, x));
});
}
解决办法
(1)类继承scala.Serializable
class Search(query: String) extends Serializable{
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
(2)使用case class修饰类
case class Search(query: String) {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
样例类就是使用 case 关键字修饰的类,样例类默认是实现了序列化接口的
我们将上述scala代码反编译为java就可以很清晰看到样例类底层默认实现了Serializable接口,所以使用case修饰类即可让类序列化
public static class Search implements Product, Serializable {
private final String query;
public String query() {
return this.query;
}
public boolean isMatch(final String s) {
return s.contains(this.query());
}
public RDD getMatch1(final RDD rdd) {
return rdd.filter((s) -> {
return BoxesRunTime.boxToBoolean($anonfun$getMatch1$1(this, s));
});
}
public RDD getMatch2(final RDD rdd) {
return rdd.filter((x) -> {
return BoxesRunTime.boxToBoolean($anonfun$getMatch2$1(this, x));
});
}
}
(3)传递局部变量而不是属性,将类变量query赋值给局部变量
当Executor内需要的是一个属性时,可以使用局部变量接收这个属性值,传递局部变量而不是属性,将类变量query赋值给局部变量,修改getMatch2为
def getMatch2(rdd: RDD[String]): RDD[String] = {
val q = query// 在Driver端,q为字符串类型,可以序列化,传给executor时不会出错
rdd.filter(x => x.contains(q))
}
kryo序列化机制
spark使用的默认序列化机制是java提供的序列化机制,即基于ObjectInputStream和 ObjectOutputStream的序列化机制。
这种序列化机制使用起来便捷,只要你的类实现了Serializable接口,那么都是可以序列化的。而且Java序列化机制是提供了自定义序列化支持的,只要你实现Externalizable接口即可实现自己的更高性能的序列化算法。但是这种方式的性能并不是很高,序列化的速度也相对较慢,并且序列化之后数据量也是比较大,占用较多的内存空间。
除了默认使用的序列化机制以外,spark还提供了另一种序列化机制,Kryo序列化机制。
这种序列化机制比java的序列化机制更快,并且序列化之后的数据占用空间更少,通常比java序列化小10倍。那么Kryo序列化机制为什么不是默认机制?原因是即使有些类实现了Seriralizable接口它也不一定能进行序列化,而且如果你想实现某些类的序列化,需要在spark程序中进行注册。
Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
| 类别 | 优点 | 缺点 | 备注 |
|---|---|---|---|
| java native serialization | 兼容性好、和scala更好融合 | 序列化性能较低、占用内存空间大(一般是Kryo Serialization 的10倍) | 默认的serializer |
| Kryo Serialization | 序列化速度快、占用空间小(即更紧凑) | 不支持所有的Serializable类型、且需要用户注册要进行序列化的类class | shuffle的数据量较大或者较为频繁时建议使用 |
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。
package com.cw.spark.core.rdd.serial
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object serializable_Kryo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer",
"org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类(非必须,但是强烈建议做)
// 虽说该步不是必须要做的(不做Kryo仍然能够工作),但是如果不注册的话,
// Kryo会存储自定义类中用到的所有对象的类名全路径,这将会导致耗费大量内存。
.registerKryoClasses(Array(classOf[Searcher]))
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark",
"spark", "hahah"), 2)
val searcher = new Searcher("hello")
val result: RDD[String] = searcher.getMatchedRDD1(rdd)
result.collect.foreach(println)
}
}
case class Searcher(val query: String) {
def isMatch(s: String) = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]) = {
rdd.filter(isMatch)
}
def getMatchedRDD2(rdd: RDD[String]) = {
val q = query
rdd.filter(_.contains(q))
}
}
RDD依赖关系
依赖关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
依赖关系,其实就是两个相邻 RDD 之间的关系
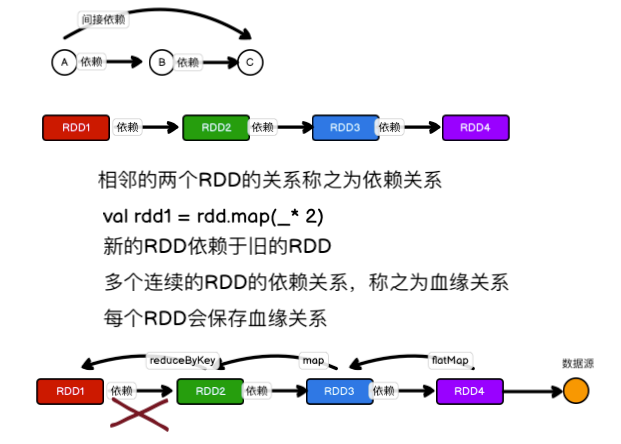
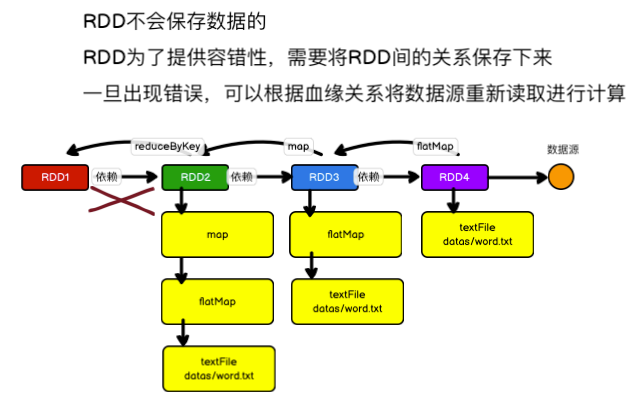
RDD其实不存储真是的数据,只存储数据的获取的方法,以及分区的方法,还有就是数据的类型。
- 初代RDD: 处于血统的顶层,存储的是任务所需的数据的分区信息,还有单个分区数据读取的方法,没有依赖的RDD, 因为它就是依赖的开始。
- 子代RDD: 处于血统的下层, 存储的东西就是 初代RDD到底干了什么才会产生自己,还有就是初代RDD的引用。现在我们基本了解了RDD里面到底存储了些什么东西,那么问题就来了,到底读取数据发生在什么时候。直接开门见山的说, 数据读取是发生在运行的Task中,也就是说,数据是在任务分发的executor上运行的时候读取的,上源码:
窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-46uGoplt-1671283650948)(http://image.codekiller.top/img/spark/image-20221029185918338.png" width="70%)]
宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]

RDD 阶段划分
- DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段
- 当RDD中存在shuffle依赖时,阶段会自动增加1个
- 阶段的数量=shuffle依赖的数量+1
- ResultStage只有1个,最后需要执行的阶段
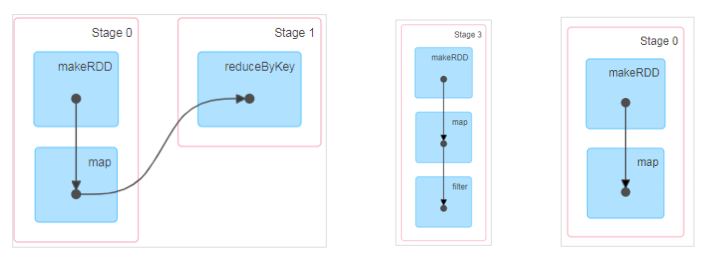
- 最后一个shuffle之前的所有变换的Stage叫ShuffleMapStage,对应的task是shuffleMapTask;
- 最后一个shuffle之后操作的Stage叫ResultStage,它是最后一个Stage。它对应的task是ResultTask。
为什么要划分stage?
- 对于窄依赖,partition的转换处理在一个Stage中完成计算;
- 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算;
- 由于划分完stage之后,在同一个stage中只有窄依赖,没有宽依赖,可以实现流水线计算,stage中的每一个分区对应一个task,在同一个stage中就有很多可以并行运行的task, 而且同一个task在一个stage中可以在同一个executor中执行。
如何划分stage?
划分stage的依据就是宽依赖
- 首先根据rdd的算子操作顺序生成DAG有向无环图,接下里从最后一个rdd往前推,创建一个新的stage,把该rdd加入到该stage中,它是最后一个stage。
- 在往前推的过程中运行遇到了窄依赖就把该rdd加入到本stage中,如果遇到了宽依赖,就从宽依赖切开,那么最后一个stage也就结束了。
- 重新创建一个新的stage,按照第二个步骤继续往前推,一直到最开始的rdd,整个划分stage也就结束了
stage与stage之间的关系
划分完stage之后,每一个stage中有很多可以并行运行的task,后期把每一个stage中的task封装在一个taskSet集合中,最后把一个一个的taskSet集合提交到worker节点上的executor进程中运行。
rdd与rdd之间存在依赖关系,stage与stage之前也存在依赖关系,前面stage中的task先运行,运行完成了再运行后面stage中的task,也就是说后面stage中的task输入数据是前面stage中task的输出结果数据。

try {
// New stage creation may throw an exception if, for example, jobs are run on
a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
……
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
……
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage]
= {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
……
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
} }
parents
}
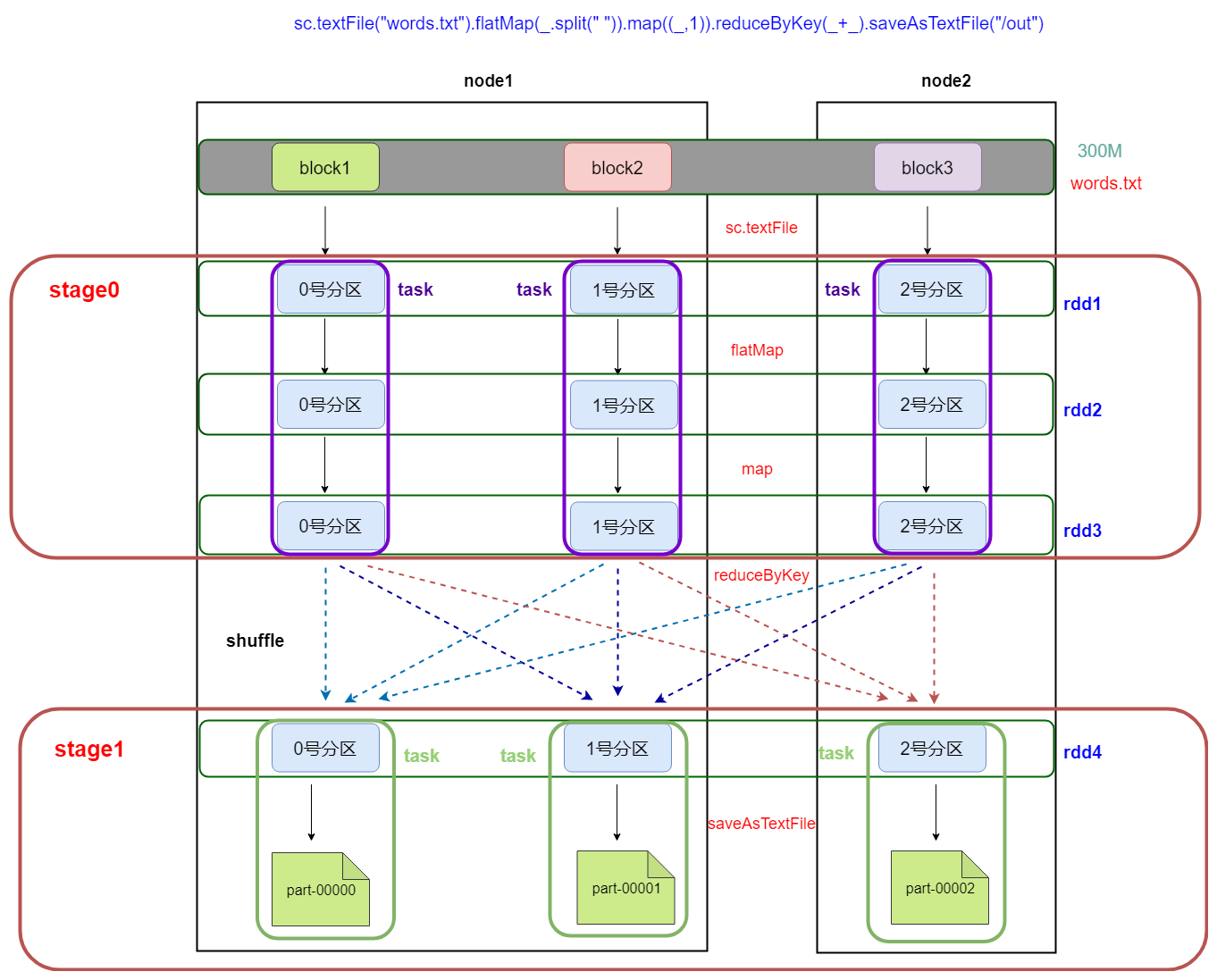
RDD 任务划分
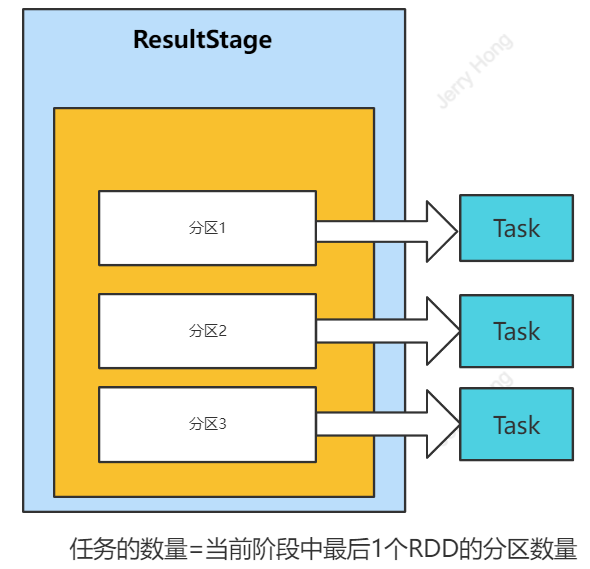
RDD 任务切分中间分为:Application、Job、Stage 和 Task:
- Application:初始化一个 SparkContext 即生成一个 Application;
- Job:一个 Action 算子就会生成一个 Job;
- Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
- Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
- 最后一个shuffle之前的所有变换的Stage叫ShuffleMapStage,对应的task是shuffleMapTask;
- 最后一个shuffle之后操作的Stage叫ResultStage,它是最后一个Stage。它对应的task是ResultTask。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties,
Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
……
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
……
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions) }
RDD持久化
缓存持久化
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
// cache 操作会增加血缘关系,不改变原有的血缘关系
println(wordToOneRdd.toDebugString)
// 数据缓存。
wordToOneRdd.cache()
// 可以更改存储级别
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
Spark 提供了 persist 和 cache 两个持久化函数,其中 cache 将 RDD 持久化到内存中,而 persist 则支持多种存储级别。
persist RDD 存储级别:
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算。 |
| MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取。 |
| MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
| MEMORY_AND_DSK_SER | 同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象。 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上。 |
| MEMORY_ONLY_2 | |
| MEMORY_AND_DISK_2 | 如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。 |
并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
通过过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部 Partition。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
(1)如何选择RDD持久化策略?
Spark 提供的多种持久化级别,主要是为了在 CPU 和内存消耗之间进行取舍。下面是一些通用的持久化级别的选择建议:
- 优先使用 MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
- 如果MEMORY_ONLY策略,无法存储的下所有数据的话,那么使用MEMORY_ONLY_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化。
- 如果需要进行快速的失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
- 能不使用DISK相关的策略,就不用使用,有的时候,从磁盘读取数据,还不如重新计算一次。
(2)什么时候设置缓存?
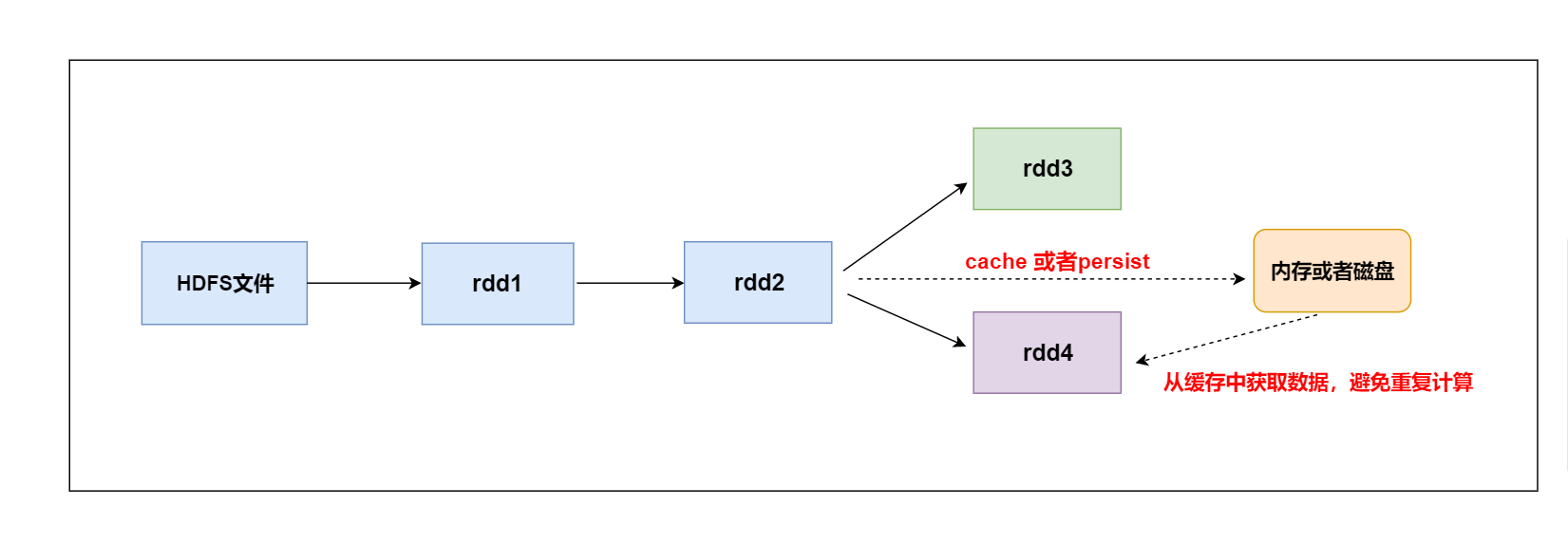
-
某个rdd的数据后期被使用了多次

如上图所示的计算逻辑:
- 当第一次使用rdd2做相应的算子操作得到rdd3的时候,就会从rdd1开始计算,先读取HDFS上的文件,然后对rdd1 做对应的算子操作得到rdd2,再由rdd2计算之后得到rdd3。同样为了计算得到rdd4,前面的逻辑会被重新计算。
- 默认情况下多次对一个rdd执行算子操作, rdd都会对这个rdd及之前的父rdd全部重新计算一次。 这种情况在实际开发代码的时候会经常遇到,但是我们一定要避免一个rdd重复计算多次,否则会导致性能急剧降低。
总结:可以把多次使用到的rdd,也就是公共rdd进行持久化,避免后续需要,再次重新计算,提升效率。
-
为了获取得到一个rdd的结果数据,经过了大量的算子操作或者是计算逻辑比较复杂
val rdd2=rdd1.flatMap(函数).map(函数).reduceByKey(函数).xxx.xxx.xxx.xxx.xxx
(3)清除缓存数据
- 自动清除:一个application应用程序结束之后,对应的缓存数据也就自动清除;
- 手动清除:调用rdd的unpersist方法。
RDD的checkpoint机制
除了 cache 和 persist 之外,Spark 还提供了另外一种持久化:checkpoint, 它能将 RDD 写入分布式文件系统,提供类似于数据库快照的功能。
它是提供了一种相对而言更加可靠的数据持久化方式。它是把数据保存在分布式文件系统,比如HDFS上。这里就是利用了HDFS高可用性,高容错性(多副本)来最大程度保证数据的安全性。
// 设置检查点路径
sc.setCheckpointDir("./checkpoint1")
// 创建一个 RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input/1.txt")
// 业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
} }
// 增加缓存,避免再重新跑一个 job 做 checkpoint
wordToOneRdd.cache()
// 数据检查点:针对 wordToOneRdd 做检查点计算
wordToOneRdd.checkpoint()
// 触发执行逻辑
wordToOneRdd.collect().foreach(println)
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
cache、persist、checkpoint三者区别
(1)cache和persis
- cache默认数据缓存在内存中
- persist可以把数据保存在内存或者磁盘中
- 后续要触发 cache 和 persist 持久化操作,需要有一个action操作
- 它不会开启其他新的任务,一个action操作就对应一个job
- 它不会改变rdd的依赖关系
- 程序运行完成后对应的缓存数据就自动消失,Spark 自动管理(创建和回收)cache 和 persist 持久化的数据
(2)checkpoint
- 可以把数据持久化写入到hdfs上
- 后续要触发checkpoint持久化操作,需要有一个action操作,后续会开启新的job执行checkpoint操作
- 它会改变rdd的依赖关系,后续数据丢失了不能够在通过血统进行数据的恢复,避免血统过长导致序列化开销增大
- 程序运行完成后对应的checkpoint数据就不会消失,checkpoint持久化的数据需要有由户自己管理
sc.setCheckpointDir("/checkpoint")
val rdd1=sc.textFile("/words.txt")
val rdd2=rdd1.cache
rdd2.checkpoint
val rdd3=rdd2.flatMap(_.split(" "))
rdd3.collect
checkpoint操作要执行需要有一个action操作,一个action操作对应后续的一个job。该job执行完成之后,它会再次单独开启另外一个job来执行 rdd1.checkpoint操作。
对checkpoint在使用的时候进行优化,在调用checkpoint操作之前,可以先来做一个cache操作,缓存对应rdd的结果数据,后续就可以直接从cache中获取到rdd的数据写入到指定checkpoint目录中。
RDD分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
- 只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
- 每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
(1) Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余
默认分区器,聚合算子如果没有指定分区器,使用默认分区器对shuffle后的rdd进行分区
分区方式:partition = key.hashCode () % numPartitions
弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致**某几个分区拥有rdd的所有数据,**容易产生数据倾斜。
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be
negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
(2)Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
范围分区器,排序内部默认使用这个分区器。将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。
原理:通过水塘抽样算法确定边界数组,再根据key来获取所在的分区索引
- 水塘抽样算法:保证每个数据被抽到的概率是相等的
- 边界数组:必须有序,数组的长度由分区数来定,即长度=分区数-1。如:[10,20,30] 决定4个分区的数据
class RangePartitioner[K : Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner {
// We allow partitions = 0, which happens when sorting an empty RDD under the
default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found
$partitions.")
private var ordering = implicitly[Ordering[K]]
// An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
...
}
def numPartitions: Int = rangeBounds.length + 1
private var binarySearch: ((Array[K], K) => Int) =
CollectionsUtils.makeBinarySearch[K]
def getPartition(key: Any): Int = {
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <= 128) {
// If we have less than 128 partitions naive search
while (partition < rangeBounds.length && ordering.gt(k,
rangeBounds(partition))) {
partition += 1
}
} else {
// Determine which binary search method to use only once.
partition = binarySearch(rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition < 0) {
partition = -partition-1
}
if (partition > rangeBounds.length) {
partition = rangeBounds.length
}
}
if (ascending) {
partition
} else {
rangeBounds.length - partition
}
}
override def equals(other: Any): Boolean = other match {
...
}
override def hashCode(): Int = {
...
}
@throws(classOf[IOException])
private def writeObject(out: ObjectOutputStream): Unit =
Utils.tryOrIOException {
...
}
@throws(classOf[IOException])
private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException
{
...
} }
(3)自定义分区器
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List(
("nba", "xxxxxxxxx"),
("cba", "xxxxxxxxx"),
("wnba", "xxxxxxxxx"),
("nba", "xxxxxxxxx"),
),3)
val partRDD: RDD[(String, String)] = rdd.partitionBy( new MyPartitioner )
partRDD.saveAsTextFile("output")
sc.stop()
}
/**
* 自定义分区器
* 1. 继承Partitioner
* 2. 重写方法
*/
class MyPartitioner extends Partitioner{
// 分区数量
override def numPartitions: Int = 3
// 根据数据的key值返回数据所在的分区索引(从0开始)
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case "wnba" => 1
case _ => 2
}
}
}
RDD文件读取和保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统:
- 文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
- 文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
(1)text文件
// 读取输入文件
val inputRDD: RDD[String] = sc.textFile("input/1.txt")
// 保存数据
inputRDD.saveAsTextFile("output")
(2)sequence 文件
SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对而设计的一种平面文件(Flat File)。在 SparkContext 中,可以调用 sequenceFile[keyClass, valueClass](path)。
// 保存数据为 SequenceFile
dataRDD.saveAsSequenceFile("output")
// 读取 SequenceFile 文件
sc.sequenceFile[Int,Int]("output").collect().foreach(println)
(3)object 对象文件
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。可以通过 objectFile[T: ClassTag](path)函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
// 保存数据
dataRDD.saveAsObjectFile("output")
// 读取数据
sc.objectFile[Int]("output").collect().foreach(println)
RDD累加器
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。

(1)系统累加器
package Acc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_Acc {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Acc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 获取系统累加器,Spark默认就提供了简单数据聚合的累加器
// 声明累加器
var sumAcc = sc.longAccumulator("sum"); //用的是可变变量
// 累加器的类型有整型longAccumulator、浮点类型doubleAccumulator、
rdd.foreach(
num => {
sumAcc.add(num) // 使用累加器
}
)
// 获取累加器的值
println("sum = " + sumAcc.value)
//少加:转换算子中调用了累加器,如果没有行动算子的话,那么累加器不会执行
//多加:转换算子中调用了累加器,如果多次出现行动算子,那么累加器会多次执行
//一般情况下,累加器会放在行动算子中操作
val mapRdd: RDD[Int] = rdd.map(
num => {
sumAcc.add(num) // 使用累加器
num
}
)
println("输出值="+sumAcc.value) //输出10
mapRdd.collect()
println(sumAcc.value) //输出20
mapRdd.collect()
println(sumAcc.value) //输出30
}
}
(2)自定义累加器
package Acc
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Spark04_Acc_WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Acc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val rdd = sc.makeRDD(List("hello", "spark", "hello", "scala"))
//累加器:WordCount
/*
* 1、自定义:创建累加器对象
* 2、向Spark进行注册
* 3、使用累加器
* 4、获取累加器累加的结果
*/
//1、自定义:创建累加器对象
val wcAcc = new MyAccumulator()
//2、向Spark进行注册
sc.register(wcAcc, "wordCountAcc")
rdd.foreach(
num => {
wcAcc.add(num) // 3、使用累加器
}
)
// 4、获取累加器的累加结果
println("sum = " + wcAcc.value)
sc.stop()
}
/*
* 自定义数据累加器:WordCount
* 1、继承AccumulatorV2,定义泛型
* IN:累加器输入的数据类型String
* OUT:累加器返回的数据类型 mutable.Map[String,Long]
*
* 2、重写方法
* */
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
private var wcMap = mutable.Map[String, Long]()
//判断是否初始状态
override def isZero: Boolean = {
wcMap.isEmpty
}
// 复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
override def reset(): Unit = {
wcMap.clear()
}
//获取累加器需要计算的值
override def add(word: String): Unit = {
// 查询 map 中是否存在相同的单词
// 如果有相同的单词,那么单词的数量加 1
// 如果没有相同的单词,那么在 map 中增加这个单词
val newCnt = wcMap.getOrElse(word, 0l) + 1 //+1代表当前出现的1次
wcMap.update(word, newCnt)
}
//Driver端合并多个累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = this.wcMap
val map2 = other.value
map2.foreach {
case (word, count) => {
val newCount: Long = map1.getOrElse(word, 0L) + count
map1.update(word, newCount)
}
}
}
//获取累加器的累加结果
override def value: mutable.Map[String, Long] = {
wcMap
}
}
}
RDD广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
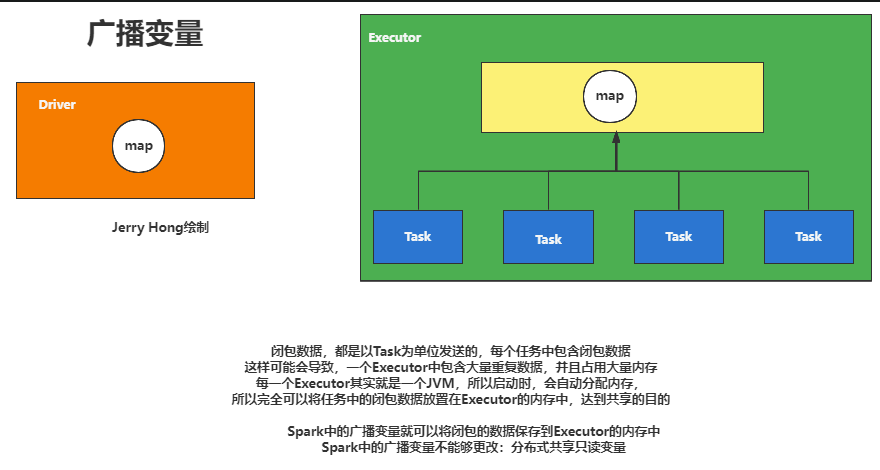
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Spark05_Bc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Acc").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 5), ("b", 6), ("c", 7)))
val joinrdd = rdd1.join(rdd2)
joinrdd.collect().foreach(println)
//若数据量很大时,join会导致数据量几何增长,并且影响shuffle的性能,不推荐使用
println("=============================")
//使用广播变量的方式
//封装广播变量
val mp = mutable.Map(("a", 5), ("b", 6), ("c", 7))
val bc = sc.broadcast(mp)
rdd1.map {
case (w, c) => {
//访问广播变量
val d = bc.value.getOrElse(w, 0)
(w, (c, d))
}
}.collect().foreach(println)
}
}